?论文详解
一.和Ripple对比:
? ? ? ? 如 RippleNet 同样存在一定的问题:首先其降低了关系 R 的重要性,其直接的?![]() 的计算方式难以捕捉关系带来的信息;其次,随着整个 ripple 的范围的扩大,此时加入模型训练的实体会大幅增多,带来巨大的计算负担和冗余。
的计算方式难以捕捉关系带来的信息;其次,随着整个 ripple 的范围的扩大,此时加入模型训练的实体会大幅增多,带来巨大的计算负担和冗余。
? ? ? ? 原文提出一种融合 KG 特点与图卷积神经网络的模型(KGCN),也就是在计算 KG 中某一个给定的 entity 的表示时,将邻居信息与偏差一并结合进来。主要体现出如下的优势:
- 通过邻居信息的综合,可以更好地捕捉局部邻域结构(local proximity structure)并储存在各 entity 中
- 不同邻居的权重取决于之间的关系和特定的用户 u,可以更好地体现用户的个性化兴趣,以展示 entity 的特点
?二.模型解释
? ? ? ?2.1问题叙述
? ? ? ?本质上还是基于知识图谱的推荐系统,考虑此时已经得到一个构造好的,由 (实体,关系,实体)的三元组组成的知识图谱,记作 g
? ? ? ?给定用户――物品矩阵?(本身是一个稀疏矩阵)和知识图谱??,判断用户 u 是否会对物品 v 有兴趣,也就是需要学习到一个预测方程:
![]()
? ? ? ?这里的参数![]() 定义为整个模型的学习参数的集合
定义为整个模型的学习参数的集合
? ? ? ?2.2KGCN思想
? ?? ? ?思想简述:? ?
? ? ? ? RippleNet将用户的兴趣在知识图谱上传播来抽取用户特征。那么我们是否可以将物品的特征在知识图谱上传播来抽取物品特征呢?KGCN模型随之产生。KGCN模型如下如所示。以一个物品为起点传播两次的情况如图a所示。每一个物品的特征矢量为与该物品直接相连的外层物品特征矢量的和,如图b所示。并且重点是在相加之前使用了注意力机制,决定注意力权重的因素有用户特征和关系特征,这样让推荐的结果具有个性化。
 ? ? ?
? ? ?
?
? ? ? ? ?计算过程:
? ? ? ? ?首先设用户是U,用户向量表示为u,物品为V,物品向量表示为v。最基础的自然公式:
![]() ? ?表示预测用户U对物品V的点击率。?
? ?表示预测用户U对物品V的点击率。?

1.计算关系权重
每条边用一个权重w来表示,并令:
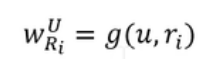
? ? ? ?u是用户向量,ri是连接第i个邻居的关系向量。g(*)是任意函数,![]() 即表示目标用户u对关系Ri的偏好程度,注意这里的现实含义可以理解为计算用户对不同的关系的偏好程度,比如某个用户非常在意影片的演员,则他对于 star 这类的 relationship 会有更多的关注,也会更愿意看他喜欢的演员的电影;而对于不是很在意演员的用户,可能对导演 director 之类的 relationship 反而有更多的帮助,这里的 g 函数即用于衡量用户对于不同关系的偏好程度。也就是经过Ri边时消息传递的权重。因为每次消息传递都加入了用户向量,所以结果比直接取关系向量ri更能体现出用户U的注意力。接下来
即表示目标用户u对关系Ri的偏好程度,注意这里的现实含义可以理解为计算用户对不同的关系的偏好程度,比如某个用户非常在意影片的演员,则他对于 star 这类的 relationship 会有更多的关注,也会更愿意看他喜欢的演员的电影;而对于不是很在意演员的用户,可能对导演 director 之类的 relationship 反而有更多的帮助,这里的 g 函数即用于衡量用户对于不同关系的偏好程度。也就是经过Ri边时消息传递的权重。因为每次消息传递都加入了用户向量,所以结果比直接取关系向量ri更能体现出用户U的注意力。接下来![]() 做一次softmax操作来归一化。
做一次softmax操作来归一化。

2.利用邻居信息的线性组合刻画结点v的邻域信息?
? ? ? ?其中N(v)代表节点V的一阶邻居集,然后我们进行一次加权求和操作得到特征向量![]()
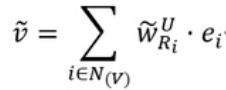
ei代表第i个邻居的特征向量,根据图采样思想,消息传递是由外而内进行的,由e4,e5传递到e1,得到e1消息聚合的特征向量后,最终再传递给中心位置V,得到特征向量![]()
3.控制邻居个数
? ? ? ??注意可能会出现某一个结点 v 存在过多的邻居的情况,会为整体的模型的计算带来巨大的压力。此时定义一个超参数 K,对于每一个结点 v,只是选取 K 个邻居进行计算。也就是说,此时 v 的邻域表示记作![]() ,且满足:
,且满足:
![]()
? 4.消息聚合
? ? ? ?但是![]() 还不是最终代表目标物品V的特征向量v,因为
还不是最终代表目标物品V的特征向量v,因为![]() 和之间还可以进行另一次消息聚合,以及走一次或多次全连接层操作:
和之间还可以进行另一次消息聚合,以及走一次或多次全连接层操作:
![]()
? ? ? ?其中![]() 是非线性激活函数,W是线性变换矩阵,b是偏置项,agg(
是非线性激活函数,W是线性变换矩阵,b是偏置项,agg(![]() ,e)表示对物品V再做一次消息聚合(自变动),e是物品V的特征向量,或者说是物品V在前一轮迭代更新产生的向量。
,e)表示对物品V再做一次消息聚合(自变动),e是物品V的特征向量,或者说是物品V在前一轮迭代更新产生的向量。
作者也提到了三种聚合方式:
(1).求和聚合:将![]() +e对应元素位相加
+e对应元素位相加
![]()
(2).拼接聚合:将向量![]() 与向量e拼接起来,维度变成了2F
与向量e拼接起来,维度变成了2F
![]()
(3).邻居聚合:就是直接采用![]() 当作本层输出向量。
当作本层输出向量。
![]()
5.预测层与损失函数? ??
? ? ? 至此,将聚合好的向量带入![]() ,即可得到预测值
,即可得到预测值![]() ,然后与真实值y(uv)简历损失函数:
,然后与真实值y(uv)简历损失函数:
![]()
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?
三、实验
1.数据集:
MovieLens-20M:是电影推荐中广泛使用的基准数据集,其中包含MovieLens网站上的大约2000万个明确的评分(从1到5)。
Book-Crossing:在“Book-Crossing”社区中包含100万本图书的评分(从0到10)。
Last.FM:包含来自Last.fm在线音乐系统的2000名用户的音乐家收听信息。
2.结果

?邻居采样的大小不同的影响:

? ? ? ?我们改变了抽样邻居K的大小,以调查KG使用的功效。从表3中我们可以看到,当K = 4或8时,KGCN可获得最佳性能。这是因为太小的K没有足够的容量来合并邻域信息,而太大的K容易被噪声所误导。
接收场深度的影响:

? ? ? ? 当H = 3或4时,我们观察到严重的模型崩溃现象,因为更大的H给模型带来大量噪声。这也符合我们的直觉,因为推断项目间相似性时关系链太长毫无意义。根据实验结果,H等于1或2足以满足实际情况。
嵌入尺寸的影响:

?四、结论?与未来方向? ?
- 探索非均匀采样器(例如,重要性采样)是未来工作的重要方向。
- 本文(和所有文献)集中在建模项目终端KG。未来工作的一个有趣方向是研究利用用户端KG是否对改善推荐性能有用。
- 设计一种算法可以很好地结合两个末端的KG也是一个有前途的方向。