5.2 实例分割
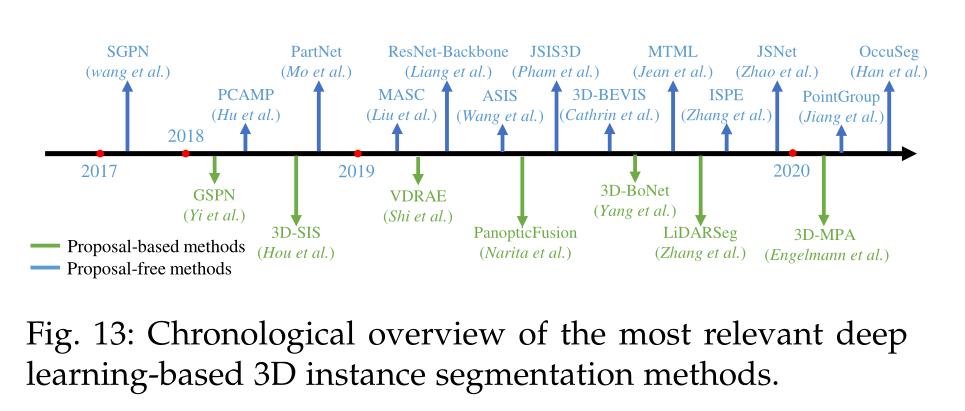
与语义分割相比,实例分割更具挑战性,因为它需要更精确和更细粒度的点推理。特别是,它不仅需要区分语义不同的点,还需要分离语义相同的实例。总的来说,现有的方法可以分为两组:基于proposal的方法和无proposal的方法。几个里程碑方法如图13所示。
图13:最相关的基于深度学习的3D实例分割方法的时序概述。
5.2.1 基于Proposal的方法
这些方法将实例分割问题转化为两个子任务:3D目标检测和实例掩码预测。Hou等人[226]提出了一个Semantic Instance Segmentation(3D-SIS)网络来实现RGB-D扫描的语义实例分割。该网络从颜色和几何特征中学习。 类似于3D目标检测,3D Region Proposal Network(3DRPN)和3D Region of Interesting(3D-RoI)层用于预测边界框位置、目标类别标签和实例掩码。按照通过合成分析的策略,Yi等人[227]提出了一个Generative Shape Proposal Network(GSPN)来生成高objectness的三维proposal。基于proposals的PointNet(R-PointNet)进一步完善了这些建议。 最终的标签是通过预测每个类标签的每点二进制掩码来获得的。与从点云直接回归三维边界框不同,该方法通过加强几何理解去除了大量无意义的建议。
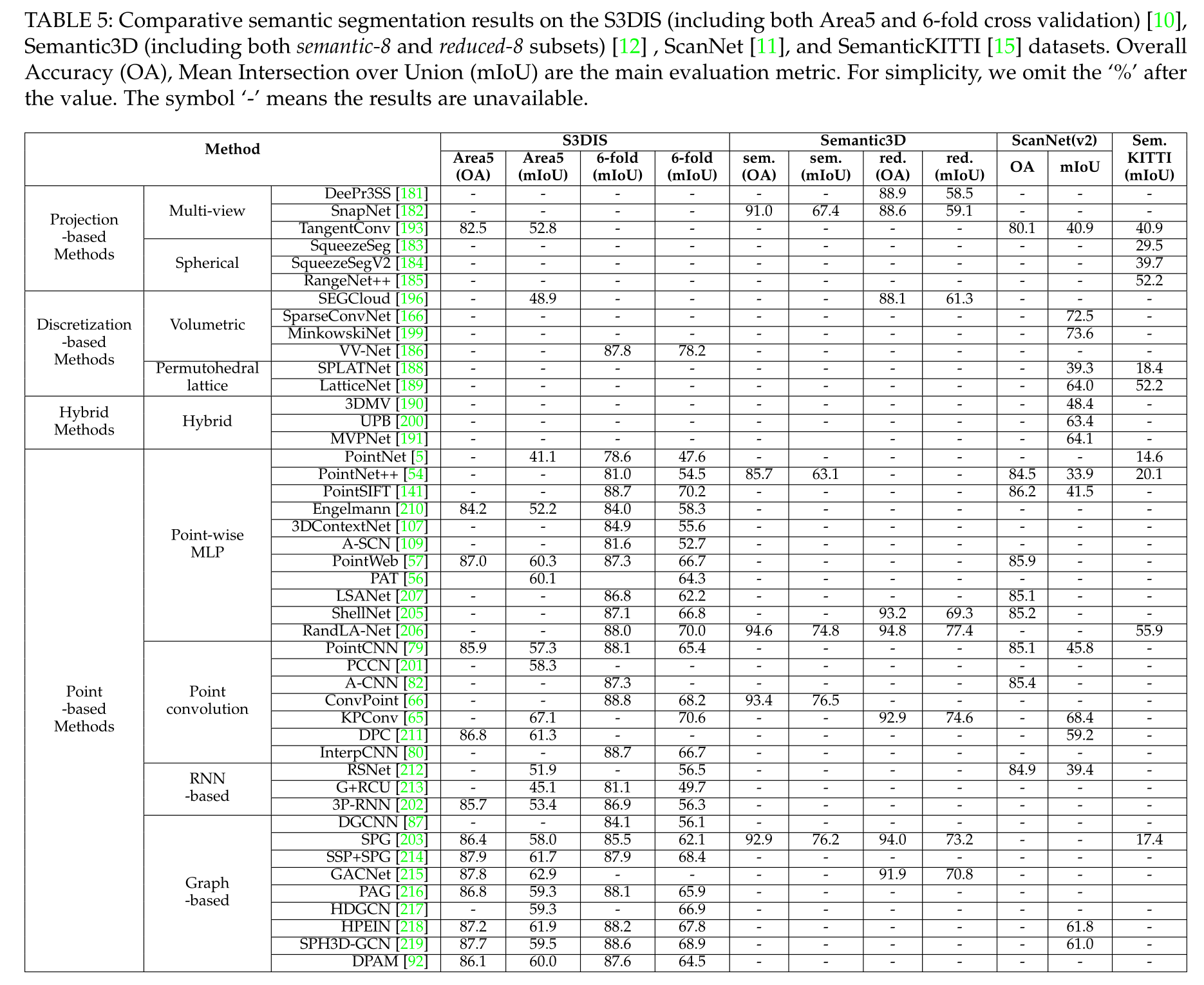
表5:在S3DIS(包括Area5和6重交叉验证)[10]、Semantic3D(包括semantic-8和reduced-8子集)[12]、ScanNet [11]和SemanticKITTI [15]数据集上的比较语义分割结果。总体准确性(OA)、联合平均交集(mIoU)是主要的评估指标。为了简单起见,我们省略了值后面的“%”。符号“-”表示结果不可用。
通过将二维全景分割扩展到三维映射,Narita等人[228]提出了一个在线体积三维映射系统,以共同实现大规模三维重建、语义标签和实例分割。他们首先利用2D语义和实例分割网络获得像素全景标签,然后将这些标签集成到立体地图中。全连接的CRF被进一步用于实现精确的分割。该语义映射系统可以实现高质量的语义映射和有区别的目标识别。Yang等人[229]提出了一种称为3D-BoNet的单阶段(single-stage)、无锚点(anchor-free)和端到端可训练网络,以实现点云上的实例分割。这种方法直接对所有可能的实例进行粗糙的三维边界框的回归,然后利用一个点级的二进制分类器来获得实例标签。特别地,边界框生成任务被描述为一个最优分配问题。 此外,还提出了一种多准则损失函数来正则化生成的边界框。 该方法不需要任何后处理,计算效率高。Zhang等人[230]提出了一个网络,用于大规模户外激光雷达点云的分割。该方法使用自关注块学习点云鸟瞰图上的特征表示。 根据预测的水平中心和高度限制获得最终实例标签。Shi等人[231]提出了一种层次感知的Variational Denoising Recursive AutoEncoder(VDRAE),用于预测室内3D空间的布局。目标proposals通过递归上下文聚合和传播迭代生成和细化。 总的来说,基于提议的方法[226]、[227]、[229]、[232]是直观和直接的,而且实例分割结果通常具有良好的objectness。然而,这些方法需要多阶段训练和删减冗余proposals。因此,它们通常耗时且计算成本高。
5.2.2 Proposal-free方法
无proposal方法[233]、[234]、[235]、[236]、[237]、[238]、[239]、[240]没有目标检测模块。相反,他们通常将实例分割看作语义分割后的后续聚类步骤。特别是,大多数现有的方法都基于这样的假设,即属于同一实例的点应该具有非常相似的特征。因此,这些方法主要集中在鉴别特征学习和点分组上。
在一项开创性的工作中,Wang等人[233]首先引入了Similarity Group Proposal Network(SGPN)。该方法首先学习每个点的特征和语义映射,然后引入相似度矩阵来表示每个成对特征之间的相似度。为了学习更多的判别特征,他们使用双铰链损失来相互调整相似度矩阵和语义分割结果。最后,采用启发式和非最大限度的限制方法,将相似的点合并为实例。由于构建相似性矩阵需要消耗大量内存,这种方法的可扩展性是有限的。类似地,Liu等人[237]首先利用子流形稀疏卷积[166]来预测每个体素的语义分数以及相邻体素之间的亲和力。然后,他们引入了一种聚类算法,根据预测的亲和力和网格拓扑将点分组到实例中。Mo等人[241]在PartNet中引入了分段检测网络来实现实例分段。 使用PointNet++作为主干来预测每个点和不相交实例掩码的语义标签。此外,Liang等人[238]提出了一种结构感知的缺失,用于区分嵌入的学习。这种损失同时考虑了特征的相似性和点之间的几何关系。基于注意的图CNN进一步用于通过聚集来自邻域的不同信息来自适应地细化所学习的特征。由于一个点的语义类别和实例标签通常相互依赖,人们提出了几种方法将这两个任务耦合成一个任务。Wang等人[234]通过引入端到端且可学习的关联分段实例和语义(ASIS)模块,将这两项任务整合在一起。实验表明,语义特征和实例特征可以相互支持,从而提高了ASIS模块的性能。类似地,Zhao等人[242]提出了JSNet来实现语义和实例分割。此外,Pham等人[235]首先引入了MultiTask Point-wise Network(MT PNet),为每个点分配一个标签,并通过引入判别损失[243]来规范特征空间中的嵌入。然后,他们将预测的语义标签和嵌入融合到Multi-Value Conditional Random Field(MV-CRF)模型中进行联合优化。最后,利用均值场变分推理产生语义标签和实例标签。Hu等人[244]首先提出了一种Dynamic Region Growing(DRG)方法,将点云动态分离为一组不相交的切,然后使用无监督的K-means++算法对所有切片进行分组。 然后在块之间的上下文信息的引导下执行多尺度块分割。最后,将这些标记的补丁合并到目标级别,以获得最终的语义和实例标签。
为了在全3D场景中实现实例分割,Elich等人[236]提出了一种2D-3D混合网络,以从BEV表示和点云的局部几何特征中联合学习全局一致的实例特征。然后将学习到的特征组合起来,实现语义和实例分割。请注意,与启发式分组合并算法[233]不同,更灵活的Meanshift[245]算法用于将这些点分组到实例中。此外,还引入了多任务学习,例如分段。 Lahoud等人[246]了解了每个实例的独特特征嵌入和估计目标中心的方向信息。提出了特征嵌入损失和方向损失来调整潜在特征空间中的学习特征嵌入。采用均值漂移聚类和非最大值抑制将体素分组为实例。这种方法在ScanNet [11]基准测试中获得了一流的性能。此外,预测的方向信息对于确定实例的边界特别有用。张等人[247]概率嵌入引入点云实例分割。该方法还结合了不确定性估计,并为聚类步骤提出了一个新的损失函数。Jiang等人[240]提出了一个PointGroup网络,它由一个语义分割分支和一个偏移预测分支组成。进一步利用双集聚类算法和ScoreNet来获得更好的分组结果。
总之,无proposal方法不需要计算量大的区域proposal组成。然而,由这些方法分组的实例段的目标性通常较低,因为这些方法不明确地检测目标边界。
5.3 部分分割
3D形状的部分分割有两个困难。首先,具有相同语义标签的形状部分具有较大的几何变化和歧义。第二,语义相同的物体中的部分数量可能不同。首先,具有相同语义标签的形状部分具有很大的几何变化和模糊性。第二,具有相同语义的目标中的部分数量可能不同。
提出了VoxSegNet[248]以在有限的解决方案下实现对3D体素化数据的细粒度部分分割。提出了一种Spatial Dense Extraction(SDE)模块(由堆叠的空洞残差块组成)来从稀疏体积数据中提取多尺度判别特征。通过逐步应用注意力特征聚合(AFA)模块,进一步重新加权和融合学习到的特征。Kalogerakis等人[249]结合FCN和基于表面的CRF来实现端到端的3D部分分割。他们首先从多个视图生成图像以实现最佳表面覆盖率,并将这些图像输入 2D 网络以生成置信度图。然后,这些置信度图由基于表面的CRF聚合,该CRF负责对整个场景进行一致的标记。易等人[250] 引入了Synchronized Spectral CNN(SyncSpecCNN)来对不规则和非同构形状图执行卷积。为了解决零件多尺度分析和形状信息共享问题,引入了扩展卷积核的谱参数化和谱变换网络。
Wang等人[251]首先通过引入Shape Fully Convolutional Networks(SFCN)并采用三个低级几何特征作为其输入,在3D网格上进行形状分割。然后,他们利用基于投票的多标签图切割来进一步细化分割结果。Zhu等人[252]提出了一种用于3D形状共同分割的弱监督协同CoSegNet。该网络将未分割的3D点云形状的集合作为输入,并通过迭代最小化组一致性损失来产生形状部分标签。类似于CRF,提出了预训练的部分细化网络来进一步细化和去噪部分proposals。Chen等人[253]提出了一种Branched AutoEncoder网络(BAE-NET),用于无监督、oneshot和弱监督3D形状协同分割。该方法将形状共分割任务描述为一个表征学习问题,旨在通过最小化形状重建损失来寻找最简单的部分表征。 基于编码器-解码器体系结构,该网络的每个分支都可以学习特定部分形状的紧凑表示。 然后,从每个分支学习的特征和点坐标被提供给解码器,以产生一个二进制值(指示该点是否属于该部分)。该方法具有良好的泛化能力,可以处理大型三维形状集合(多达5000多个形状)。 然而,该方法对初始参数敏感,并且没有将形状语义纳入网络,这阻碍了该方法在每次迭代中获得鲁棒稳定的估计。 Yu等人[254]提出了一种用于分层形状分割的自顶向下递归部分分解网络(PartNet)。与现有的将形状分割成固定标签集的方法不同,该网络将部分分割表述为级联二进制标签的问题,并根据几何结构将输入点云分解为任意数量的部分。罗等人[255]针对zeroshot 3D部分分割任务介绍了一种基于学习的分组框架。为了提高跨类别的泛化能力,该方法倾向于学习一种分组策略,限制网络在部分的局部背景下学习part-level特征。
5.4 总结
表5显示了现有方法在公共数据集上取得的结果,包括S3DIS[10]、Semantic3D[12]、ScanNet[39]和SemanticKITTI[15]。以下问题需要进一步调查:
-
得益于常规的数据表示,基于投影的方法和基于离散化的方法都可以利用2D图像中成熟的网络架构。然而,基于投影的方法的主要限制在于由3D-2D投影引起的信息损失,而基于离散化的方法的主要瓶颈在于由分辨率的增加引起的计算和存储成本的立方增加。为此,基于索引结构的稀疏卷积将是一个可行的解决方案,值得进一步探索。
-
基于点的网络是最常研究的方法。然而,点表示自然没有明确的邻域信息,大多数现有的基于点的方法都采用邻域搜索机制(例如KNN[79]或ball query[54])。这固有地限制了这些方法的效率,最近提出的point-voxel联合表示[256]将是进一步研究的有趣方向。从不平衡的数据中学习仍然是点云分割中的一个挑战性问题。尽管一些方法[65], [203], [205]已经取得了显著的整体性能,但它们在少数类别上的性能仍然是有限的。例如,RandLA Net[206]在Semantic3D的reduced-8子集上实现了76.0%的总体IoU,但在hardscape类上实现了41.1%的极低IoU。
-
大多数现有方法[5]、[54]、[79]、[205]、[207]都适用于小型点云(例如,1米×1米,4096个点)。 实际上,深度传感器获取的点云通常是巨大的、大规模的。 因此,需要进一步研究大规模点云的有效分割问题。
-
少数工作[178]、[179]、[199] 已经开始从动态点云中学习时空信息。我们期望时空信息有助于提高后续任务的性能,如3D目标识别、分割和完成。
6 结论
本文综述了三维理解的最新方法,包括三维形状分类、三维目标检测和跟踪、三维场景和目标分割。 对这些方法进行了全面的分类和性能比较。 文中还介绍了各种方法的优缺点,并列出了潜在的研究方向。