环境
- tensorflow == 2.8.0
- win10 or linux
概要
目标检测项目的主要步骤如下:
- 搭建虚拟环境
- 采集图像并打标
- 训练
- 预测
- 模型的保存和转换
- 调优
- 项目部署
1. 搭建虚拟环境
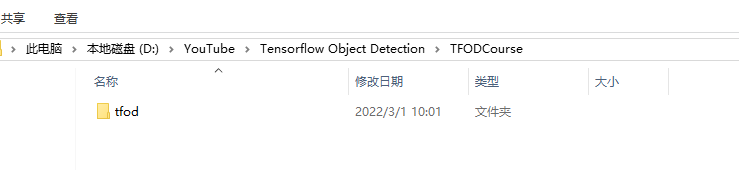
步骤1: 创建虚拟环境
创建文件夹TFODCourse,并在该目录下安装虚拟环境
cd TFODCourse
python -m venv tfod
步骤2: 激活虚拟环境
- LInux 环境
source tfod/bin/activate
- Windows环境
.\tfod\Scripts\activate
步骤3: 安装依赖包并添加虚拟环境到Jupyter Notebook
python -m pip install --upgrade pip # 升级pip
pip install ipykernel # jupyter notebook 与 虚拟环境关联
python -m ipykernel install --user --name=tfod # 将虚拟环境安装到hjupyter notebook里
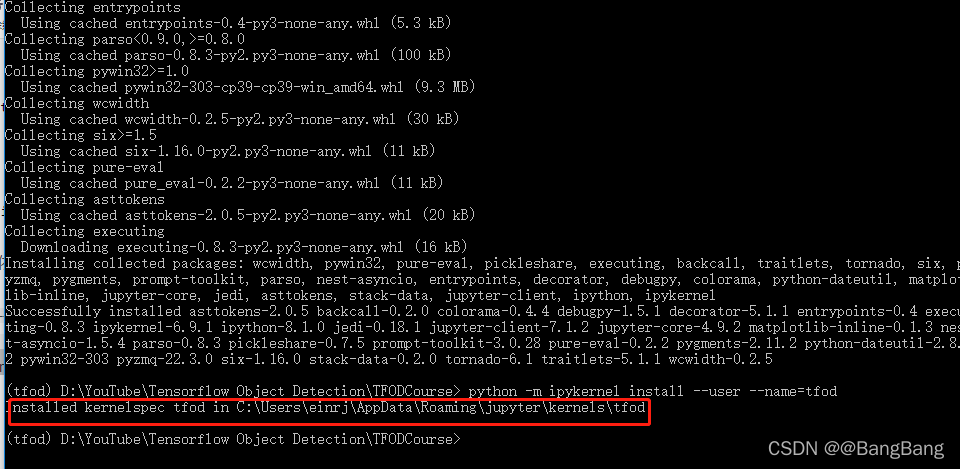
提示:Installed kernelspec tfod in C:\Users\einrj\AppData\Roaming\jupyter\kernels\tfod表示安装成功
步骤4: 打开jupyter notebook
jupyter notebook
错误提示1 : Jupyter command jupyter-notebook not found.
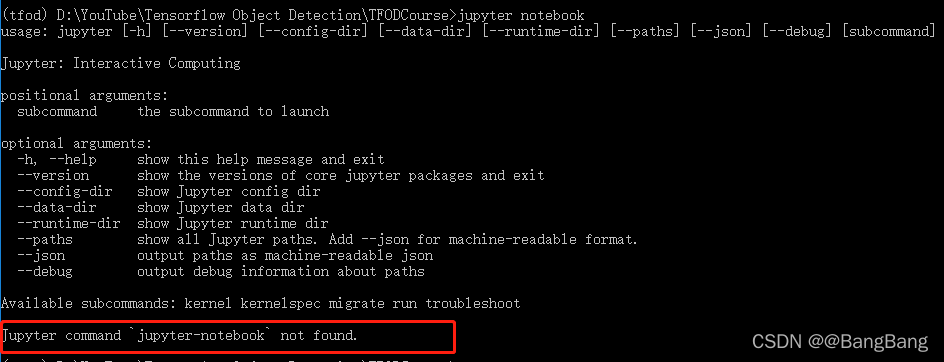
解决方法,在命令行安装 jupyter
pip install jupyter
然后执行 jupyter notebook 就可以打开 notebook了

可以看到tfod 虚拟环境已经成功安装到Jupyter notebook中了
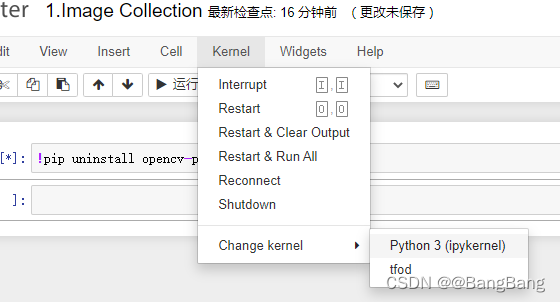
注意1 如果jupyter notebook没有处在虚拟环境中,如下所示:

需要切换到虚拟环境tfod,通过 Kernel -> Change Kernel - > tfod
2. 图片采集并打标
Tips:
- 打标尽量的紧凑,紧贴目标(Keep your label as ‘tight’ as possible)
- 采集的图片应该包含多种角度和光照条件
- 每种类型的图片可以预先采集10-20张进行训练
2.1 导入依赖包
!pip install opencv-python # jupyter notebook中运行需要加 !
import cv2
import uuid # 产生唯一表示,用来进行图片命名
import os
import time
2.2 定义图片种类
labels= ['thumbsup','thumbsdown','thankyou','livelong'] #可自定义标签
number_imgs=5 #理想最少10-20张
2.3 创建文件夹
IMAGES_PATH=os.path.join(`Tensorflow`,'workspace','images','collectedimages')
if not os.path.exists(IMAGES_PATH):
if os.name == 'posix': # linux
!mkdir -p {IMAGES_PATH}
if os.name == 'nt': # Windows
!mkdir {IMAGES_PATH}
for label in labels:
path=os.path.join(IMAGES_PATH,label)
if not os.path.exists(path):
!mkdir {path}
2.4 拍摄图片
for label in labels:
cap=cv2.VideoCapture(0)
print('Collecting images for {}'.format(label))
time.sleep(5) # leave time to chanage pose
for imgnum in range (number_imgs):
print('Collecting image {}'.format(imgnum))
ret,frame = cap.read()
imgname=os.path.join(IMAGES_PATH,label,label+'.'+'{}.jpg'.format(str(uuid.uuid1())))
cv2.imwrite(imgname,frame)
cv2.imshow('frame',frame)
time.sleep(2)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()


拍摄好图片,其中如果有部分照片没拍好,可以删掉重新针对缺失的照片进行采集
2.5 图片标注
使用labelimg工具进行标注
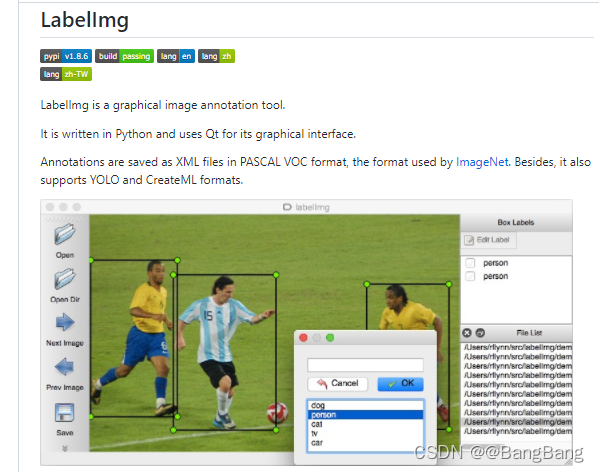
github给出的labelimg编译教程,如下

安装labelmg依赖包
!pip install --upgrade pyqt5 lxml
LABELING_PATH=os.path.join('Tensorflow','labelimg')
将源码拷贝到labelimg文件夹下
If not os.path.exists(LABELING_PATH):
!mkdir {LABELING_PATH}
!git clone https://github.com/tzutalin/labelImg {LABELING_PATH}
源码编译labelimg
if os.name == 'posix':
!make qt5py3
if os.name == 'nt':
! cd {LABELING_PATH} && pyrcc5 -o libs/resources.py resources.qrc
启动labelmg
!cd {LABELING_PATH} && python labelImg.py
标注
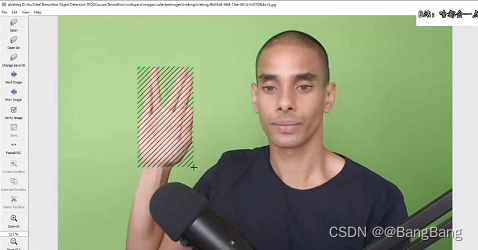
具体labelimg的使用参考labelimg使用教程
2.6 划分测试集和训练集
- 创建train 和test文件夹
TRAIN_PATH=os.path.join('Tensorflow','workspace','images','train')
TEST_PATH=os.path.join('Tensorflow','workspace','images','test')
if not os.path.exists(TRAIN_PATH):
if os.name == 'posix': # linux
!mkdir -p {TRAIN_PATH}
if os.name == 'nt': # Windows
!mkdir {TRAIN_PATH}
if not os.path.exists(TEST_PATH):
if os.name == 'posix': # linux
!mkdir -p {TEST_PATH}
if os.name == 'nt': # Windows
!mkdir {TEST_PATH}
由于文件比较少,直接将collectedimages下各个类别的图片前80%的图片及标注xml文件迁移到train文件夹,剩余的图片及标注xml文件迁移到test文件夹
- train 文件
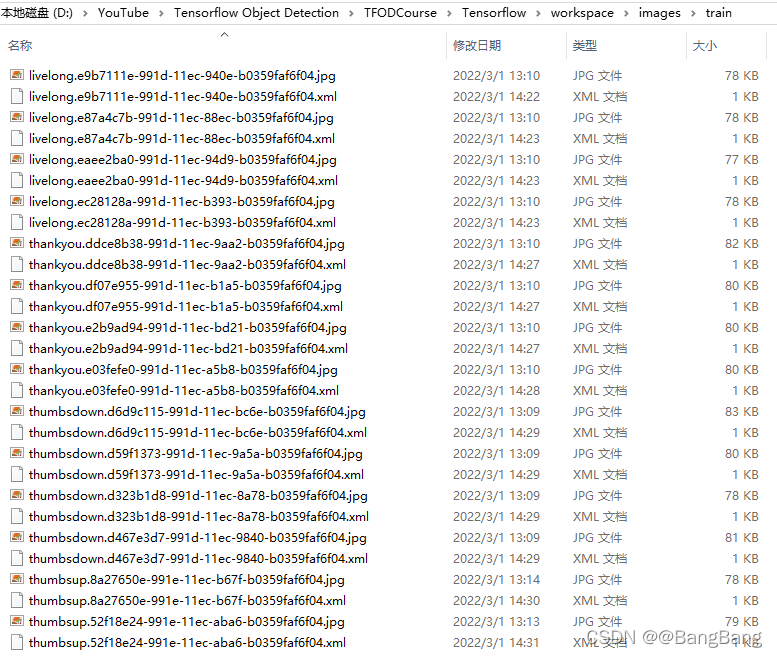
- test文件

3. 训练
Tensorflow Model Zoo
使用迁移学习,对模型进行训练。Tensorflow Model Zoo有大量预训练模型可供选择。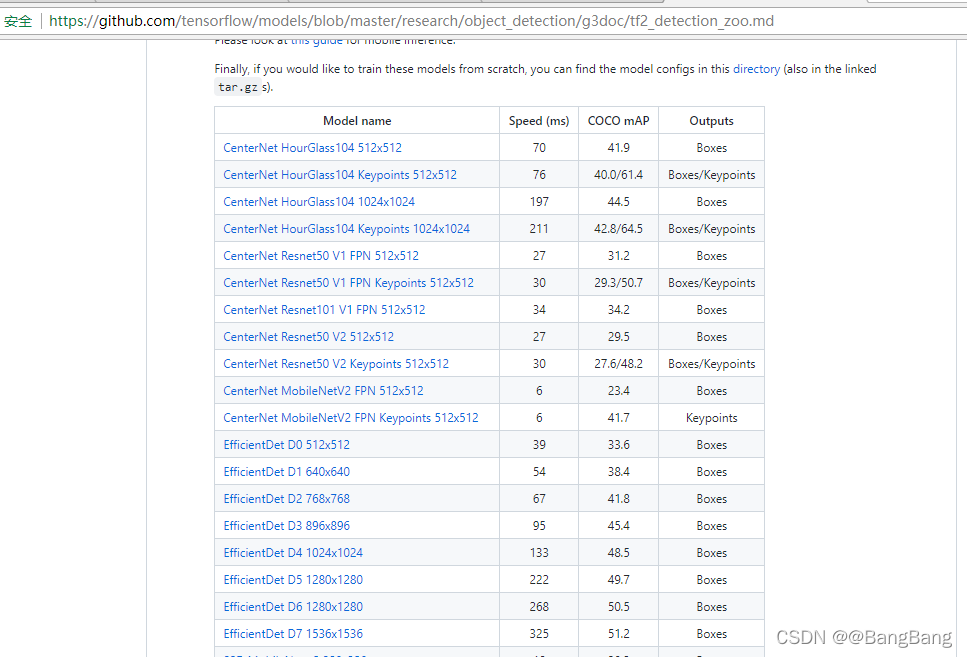
可以不知道模型结构的细节,作为一个开发应用人员可以直接使用这些模型,不同模型对于不同的精度和运行速度。本文使用的模型是SSD MobileNet V2 FPNLite 320x320,用过鼠标右键选择下载链接或者直接下载模型。
其中320 x320 我们自己不需要把图片压缩到320 x320,传入图片后模型自动压缩到320 x 320,然后转换为原始图片的分辨率。预训练模型我们不需要做大量的前处理和后处理工作,模型已经帮忙做好。
3.1 设置路径
import os
CUSTOM_MODEL_NAME='my_ssd_mobnet'
PRETRAINED_MODEL_NAME = 'ssd_mobilenet_v2_fpnlite_320x320_coco17_tpu-8'
PRETRAIN_MODEL_URL = 'http://download.tensorflow.org/models/object_detection/tf2/20200711/ssd_mobilenet_v2_fpnlite_320x320_coco17_tpu-8.tar.gz'
TF_RECORD_SCRIPT_NAME = 'generate_tfrecord.py'
LABEL_MAP_NAME='label_map.pbtxt'
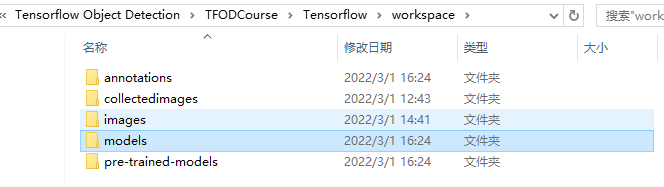
paths={'WORKWAPCE_PATH':os.path.join('Tensorflow','workspace'),
'SCRIPTS_PATH':os.path.join('Tensorflow','scripts'),
'APIMODEL_PATH':os.path.join('Tensorflow','models'),
'ANNOTATION_PATH':os.path.join('Tensorflow','workspace','annotations'),
'IMAGE_PATH':os.path.join('Tensorflow','workspace','images'),
'MODEL_PATH':os.path.join('Tensorflow','workspace','models'),
'PRETRAINED_MODEL_PATH':os.path.join('Tensorflow','workspace','pre-trained-models'),
'CHECKPOINT_PATH':os.path.join('Tensorflow','workspace','models',CUSTOM_MODEL_NAME),
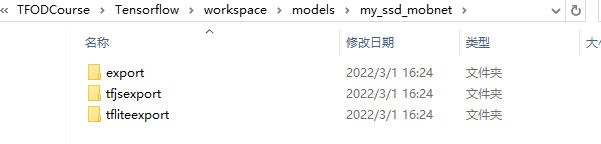
'OUTPUT_PATH':os.path.join('Tensorflow','workspace','models',CUSTOM_MODEL_NAME,'export'),
'TFJS_PATH':os.path.join('Tensorflow','workspace','models',CUSTOM_MODEL_NAME,'tfjsexport'),
'TFLITE_PATH':os.path.join('Tensorflow','workspace','models',CUSTOM_MODEL_NAME,'tfliteexport'),
'PROTOC_PATH':os.path.join('Tensorflow','protoc')}
files = {
'PIPELINE_CONFIG':os.path.join('Tensorflow','workspace','models',CUSTOM_MODEL_NAME,'pipeline.config'),
'TF_RECORD_SCRIPT':os.path.join(paths['SCRIPTS_PATH'],TF_RECORD_SCRIPT_NAME),
'LABELMAP':os.path.join(paths['ANNOTATION_PATH'],LABEL_MAP_NAME)
}
for path in paths.values():
if not os.path.exists(path):
if os.name == 'posix':
!mkdir -p {path}
if os.name == 'nt':
!mkdir {path}
3.2 下载Tensorflow Model Zoo 并安装TFOD(tensorflow object detection)
if os.name == 'nt':
!pip install wget
import wget
- 下载
Tensorflow/models源码到APIMODEL_PATH
if not os.path.exists(os.path.join(paths['APIMODEL_PATH'],'research','object_detection')):
!git clone https://github.com/tensorflow/models {paths['APIMODEL_PATH']}
- 安装Tensorflow object Dectection API
if os.name == 'posix':
!apt-get install protobuf-compiler
!cd Tensorflow/models/research && protoc object_detection/protos/*.proto --python_out=. && cp object_detection/packages/tf2/setup.py . && python -m pip install .
if os.name=='nt':
url="https://github.com/protocolbuffers/protobuf/releases/download/v3.15.6/protoc-3.15.6-win64.zip"
wget.download(url)
!move protoc-3.15.6-win64.zip {paths['PROTOC_PATH']}
!cd {paths['PROTOC_PATH']} && tar -xf protoc-3.15.6-win64.zip
os.environ['PATH'] += os.pathsep + os.path.abspath(os.path.join(paths['PROTOC_PATH'], 'bin'))
!cd Tensorflow/models/research && protoc object_detection/protos/*.proto --python_out=. && copy object_detection\\packages\\tf2\\setup.py setup.py && python setup.py build && python setup.py install
!cd Tensorflow/models/research/slim && pip install -e .
注: 提示git 或者tar 不是内部或者外部命令,需要安装git、tar并加入环境变量,如果不想安装可以手动下载到指定的位置
- 检测是否安装成功
VERIFICATION_SCRIPT = os.path.join(paths['APIMODEL_PATH'], 'research', 'object_detection', 'builders', 'model_builder_tf2_test.py')
# Verify Installation
!python {VERIFICATION_SCRIPT}
运行验证脚本,如果验证没有问题,说明Tensorflow 目标检测API已安装成功
出现的问题1: ModuleNotFoundError: No module named ‘tensorflow’
解决: 运行如下命令
!pip install tensorflow --upgrade
重新运行
!python {VERIFICATION_SCRIPT}
出现的问题2: ModuleNotFoundError: No module named ‘cycler’
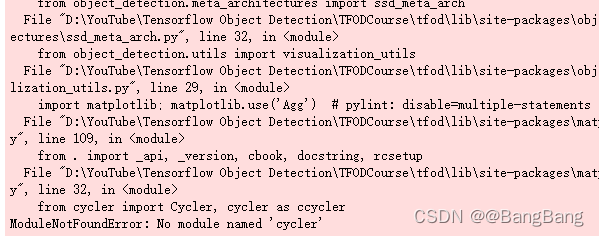
解决2:
!pip install cycler
然后重新运行验证脚本
问题3:ModuleNotFoundError: No module named ‘yaml’
解决3:
!pip install pyyaml
出现如下所示,说明tensorflow 目标检测API已经安装成功
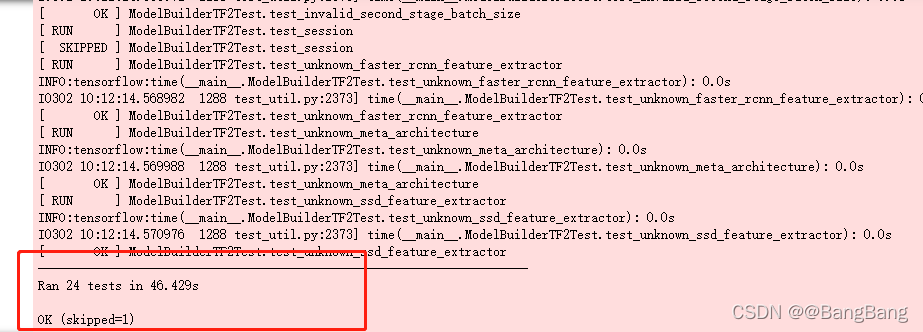
- 导入object_detection
import object_detection
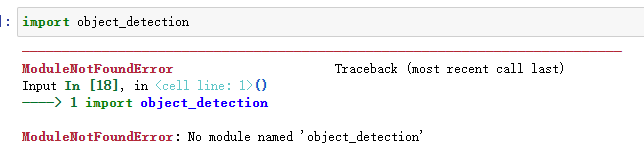
解决方法: 重启jupyter notebook内核
- 如果需要执行GPU加速,需要下载tensorflow对应版本的cudnn和cuda
参见:- TensorFlow与cudnn和cuda的对应关系 ,同时需要下载对应Visual Studio 编译器
- Tensorflow2.0 安装cuda和cudnn教程
- 从Tensorflow Model Zoo 下载预训练模型
if os.name =='posix':
!wget {PRETRAINED_MODEL_URL}
!mv {PRETRAINED_MODEL_NAME+'.tar.gz'} {paths['PRETRAINED_MODEL_PATH']}
!cd {paths['PRETRAINED_MODEL_PATH']} && tar -zxvf {PRETRAINED_MODEL_NAME+'.tar.gz'}
if os.name == 'nt':
wget.download(PRETRAINED_MODEL_URL)
!move {PRETRAINED_MODEL_NAME+'.tar.gz'} {paths['PRETRAINED_MODEL_PATH']}
!cd {paths['PRETRAINED_MODEL_PATH']} && tar -zxvf {PRETRAINED_MODEL_NAME+'.tar.gz'}
3.3 创建标签映射
labels = [{'name':'ThumbsUp', 'id':1}, {'name':'ThumbsDown', 'id':2}, {'name':'ThankYou', 'id':3}, {'name':'LiveLong', 'id':4}]
with open(files['LABELMAP'], 'w') as f:
for label in labels:
f.write('item { \n')
f.write('\tname:\'{}\'\n'.format(label['name']))
f.write('\tid:{}\n'.format(label['id']))
f.write('}\n')

3.3 创建TF Records
- 下载
generate_tfrecord.py
if not os.path.exists(files['TF_RECORD_SCRIPT']):
!git clone https://github.com/nicknochnack/GenerateTFRecord {paths['SCRIPTS_PATH']}
- 执行脚本生成TF Records
!python {files['TF_RECORD_SCRIPT']} -x {os.path.join(paths['IMAGE_PATH'], 'train')} -l {files['LABELMAP']} -o {os.path.join(paths['ANNOTATION_PATH'], 'train.record')}
!python {files['TF_RECORD_SCRIPT']} -x {os.path.join(paths['IMAGE_PATH'], 'test')} -l {files['LABELMAP']} -o {os.path.join(paths['ANNOTATION_PATH'], 'test.record')}
运行提示如下报错信息

执行
!pip install pytz
3.4 复制Model Config 到 训练目录下
if os.name =='posix':
!cp {os.path.join(paths['PRETRAINED_MODEL_PATH'], PRETRAINED_MODEL_NAME, 'pipeline.config')} {os.path.join(paths['CHECKPOINT_PATH'])}
if os.name == 'nt':
!copy {os.path.join(paths['PRETRAINED_MODEL_PATH'], PRETRAINED_MODEL_NAME, 'pipeline.config')} {os.path.join(paths['CHECKPOINT_PATH'])}
3.4 更新Config文件用来做迁移学习
import tensorflow as tf
from object_detection.utils import config_util
from object_detection.protos import pipeline_pb2
from google.protobuf import text_format
config = config_util.get_configs_from_pipeline_file(files['PIPELINE_CONFIG'])
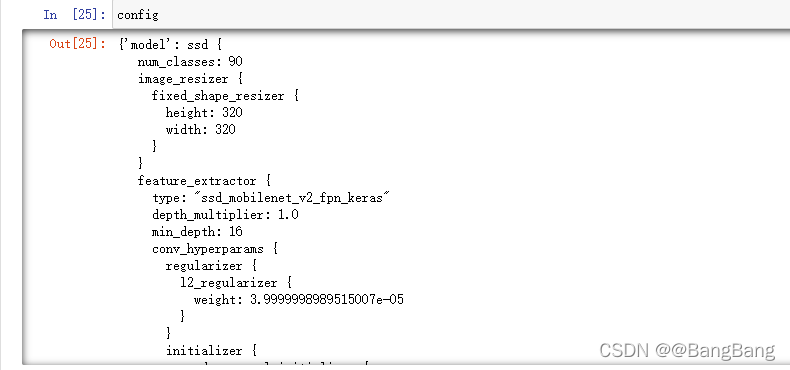
根据config文件,可以看出:label_map_path: "PATH_TO_BE_CONFIGURED", input_path: "PATH_TO_BE_CONFIGURED",fine_tune_checkpoint: "PATH_TO_BE_CONFIGURED",tf_record_input_reader:"PATH_TO_BE_CONFIGURED",这些路径需要我们重新去定义
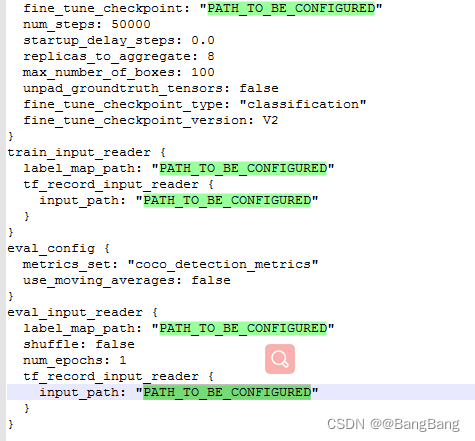
- 执行代码,更新config文件。
pipeline_config = pipeline_pb2.TrainEvalPipelineConfig()
with tf.io.gfile.GFile(files['PIPELINE_CONFIG'], "r") as f:
proto_str = f.read()
text_format.Merge(proto_str, pipeline_config)
pipeline_config.model.ssd.num_classes = len(labels)
pipeline_config.train_config.batch_size = 4
pipeline_config.train_config.fine_tune_checkpoint = os.path.join(paths['PRETRAINED_MODEL_PATH'], PRETRAINED_MODEL_NAME, 'checkpoint', 'ckpt-0')
pipeline_config.train_config.fine_tune_checkpoint_type = "detection"
pipeline_config.train_input_reader.label_map_path= files['LABELMAP']
pipeline_config.train_input_reader.tf_record_input_reader.input_path[:] = [os.path.join(paths['ANNOTATION_PATH'], 'train.record')]
pipeline_config.eval_input_reader[0].label_map_path = files['LABELMAP']
pipeline_config.eval_input_reader[0].tf_record_input_reader.input_path[:] = [os.path.join(paths['ANNOTATION_PATH'], 'test.record')]
注:``
config_text = text_format.MessageToString(pipeline_config)
with tf.io.gfile.GFile(files['PIPELINE_CONFIG'], "wb") as f:
f.write(config_text)
4 训练模型
4.1 训练模型
TRAINING_SCRIPT = os.path.join(paths['APIMODEL_PATH'], 'research', 'object_detection', 'model_main_tf2.py')
command = "python {} --model_dir={} --pipeline_config_path={} --num_train_steps=3000".format(TRAINING_SCRIPT, paths['CHECKPOINT_PATH'],files['PIPELINE_CONFIG'])
print(command)
python Tensorflow\models\research\object_detection\model_main_tf2.py --model_dir=Tensorflow\workspace\models\my_ssd_mobnet_tuned --pipeline_config_path=Tensorflow\workspace\models\my_ssd_mobnet_tuned\pipeline.config --num_train_steps=2000
为了看到模型训练的进度,复制训练脚本到windows 命令窗口中进行训练,因为jupyter notebook观察不到训练进度
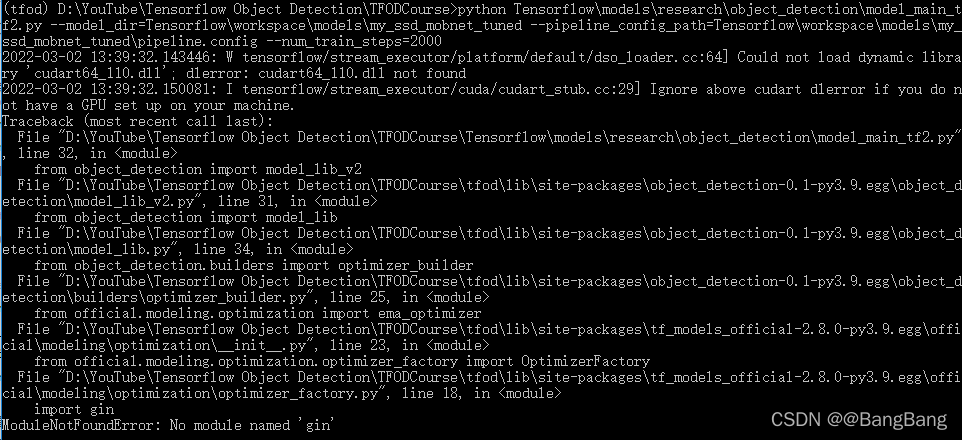
提示No module named 'gin'
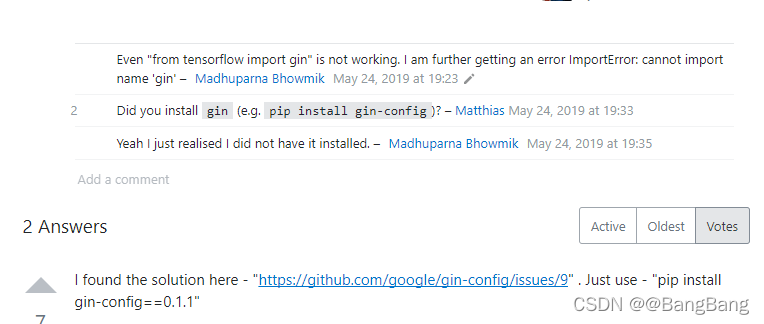
pip install gin-config == 0.1.1
提示:No module named 'tensorflow_addons'
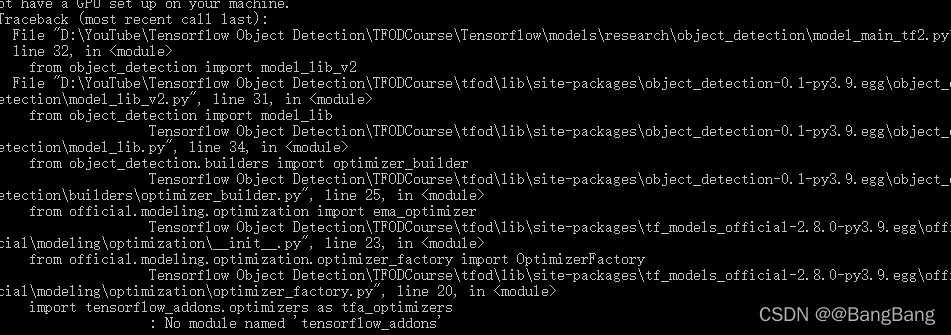
pip install tensorflow_addons

训练完成
4.2 模型评估
command = "python {} --model_dir={} --pipeline_config_path={} --checkpoint_dir={}".format(TRAINING_SCRIPT, paths['CHECKPOINT_PATH'],files['PIPELINE_CONFIG'], paths['CHECKPOINT_PATH'])
print(command)
python Tensorflow\models\research\object_detection\model_main_tf2.py --model_dir=Tensorflow\workspace\models\my_ssd_mobnet_tuned --pipeline_config_path=Tensorflow\workspace\models\my_ssd_mobnet_tuned\pipeline.config --checkpoint_dir=Tensorflow\workspace\models\my_ssd_mobnet_tuned
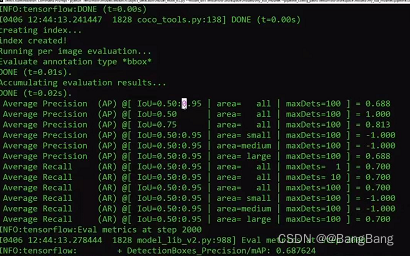
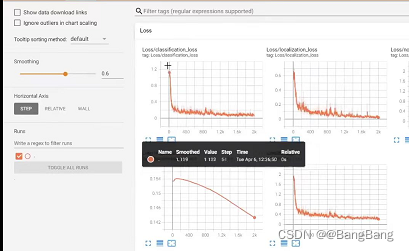
4.3 tensorboard 展示
模型训练和验证后,生成的结果保存如下:
cd 到train 或者 eval 执行如下命令
tensorboard --logdir=.
4.4 加载模型
import os
import tensorflow as tf
from object_detection.utils import label_map_util
from object_detection.utils import visualization_utils as viz_utils
from object_detection.builders import model_builder
from object_detection.utils import config_util
# Load pipeline config and build a detection model
configs = config_util.get_configs_from_pipeline_file(files['PIPELINE_CONFIG'])
detection_model = model_builder.build(model_config=configs['model'], is_training=False)
# Restore checkpoint
ckpt = tf.compat.v2.train.Checkpoint(model=detection_model)
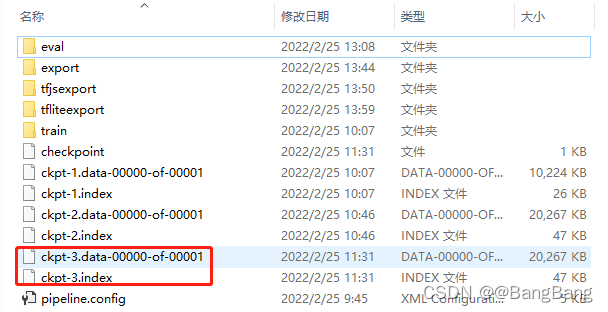
ckpt.restore(os.path.join(paths['CHECKPOINT_PATH'], 'ckpt-3')).expect_partial()
@tf.function
def detect_fn(image):
image, shapes = detection_model.preprocess(image)
prediction_dict = detection_model.predict(image, shapes)
detections = detection_model.postprocess(prediction_dict, shapes)
return detections
其中ckpt.restore(os.path.join(paths['CHECKPOINT_PATH'], 'ckpt-3')).expect_partial() 其中参数ckpt-3根据保存的模型文件最新的ckpt修改。
5 预测
5.1 单张图片检测
import cv2
import numpy as np
from matplotlib import pyplot as plt
%matplotlib inline
category_index = label_map_util.create_category_index_from_labelmap(files['LABELMAP'])
IMAGE_PATH = os.path.join(paths['IMAGE_PATH'], 'test', 'thumbsup.6223230a-947f-11ec-a250-48ba4e5e8c8f.jpg')
img = cv2.imread(IMAGE_PATH)
image_np = np.array(img)
input_tensor = tf.convert_to_tensor(np.expand_dims(image_np, 0), dtype=tf.float32)
detections = detect_fn(input_tensor)
num_detections = int(detections.pop('num_detections'))
detections = {key: value[0, :num_detections].numpy()
for key, value in detections.items()}
detections['num_detections'] = num_detections
# detection_classes should be ints.
detections['detection_classes'] = detections['detection_classes'].astype(np.int64)
label_id_offset = 1
image_np_with_detections = image_np.copy()
viz_utils.visualize_boxes_and_labels_on_image_array(
image_np_with_detections,
detections['detection_boxes'],
detections['detection_classes']+label_id_offset,
detections['detection_scores'],
category_index,
use_normalized_coordinates=True,
max_boxes_to_draw=5,
min_score_thresh=.8,
agnostic_mode=False)
plt.imshow(cv2.cvtColor(image_np_with_detections, cv2.COLOR_BGR2RGB))
plt.show()

5.2 实时视频检测
cap = cv2.VideoCapture(0)
width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
while cap.isOpened():
ret, frame = cap.read()
image_np = np.array(frame)
input_tensor = tf.convert_to_tensor(np.expand_dims(image_np, 0), dtype=tf.float32)
detections = detect_fn(input_tensor)
num_detections = int(detections.pop('num_detections'))
detections = {key: value[0, :num_detections].numpy()
for key, value in detections.items()}
detections['num_detections'] = num_detections
# detection_classes should be ints.
detections['detection_classes'] = detections['detection_classes'].astype(np.int64)
label_id_offset = 1
image_np_with_detections = image_np.copy()
viz_utils.visualize_boxes_and_labels_on_image_array(
image_np_with_detections,
detections['detection_boxes'],
detections['detection_classes']+label_id_offset,
detections['detection_scores'],
category_index,
use_normalized_coordinates=True,
max_boxes_to_draw=5,
min_score_thresh=.8,
agnostic_mode=False)
cv2.imshow('object detection', cv2.resize(image_np_with_detections, (800, 600)))
if cv2.waitKey(10) & 0xFF == ord('q'):
cap.release()
cv2.destroyAllWindows()
break
完整代码: