动手实现深度神经网络4 封装成层
经过篇三篇文章,我们的神经网络已经能够较为高效、准确的完成手写数字的识别。但是,它仍然存在一些问题:不易扩展。神经网络模型一般都是由“层”来构成的,这里所说的层和之前提到的“输入层,输出层,隐藏层”概念并不完全相同。我的理解是:这里所说的层是一种把神经组件化的一种工具概念,是一些具体的python类,每一个层(类)都封装一些特定的功能。
我们先来尝试将乘法运算和加法运算封装成层吧,虽然神经网络中并不会单独使用它们,但作为练手还是很好的。
1.简单的层
乘法层的实现
层的实现中有两个共通的方法(接口)forward()和backward()。forward()对应正向传播,backward()对应反向传播。
class MulLayer:
def __init__(self):
self.x = None
self.y = None
def forward(self, x, y):
self.x = x
self.y = y
out = x * y
return out
def backward(self, dout):
dx = dout * self.y
dy = dout * self.x
return dx, dy
我们用之前文章中经常出现的买苹果的简单例子来看一下如何使用层:
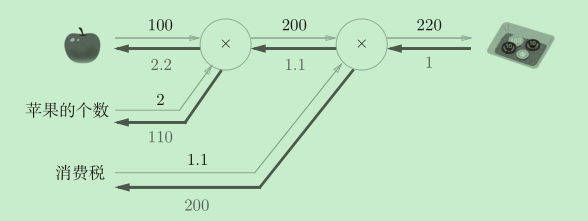
apple = 100
apple_num = 2
tax = 1.1
mul_apple_layer = MulLayer()
mul_tax_layer = MulLayer()
# forward
apple_price = mul_apple_layer.forward(apple, apple_num)
price = mul_tax_layer.forward(apple_price, tax)
# backward
dprice = 1
dapple_price, dtax = mul_tax_layer.backward(dprice)
dapple, dapple_num = mul_apple_layer.backward(dapple_price)
print("price:", int(price))
print("dApple:", dapple)
print("dApple_num:", int(dapple_num))
print("dTax:", dtax)
可以看到,使用层的方法是:
- 初始化层
- 按照正向传播顺序一次调用所有层的.forward方法
- 按照反向传播顺序一次调用所有层的.backward方法,并获取梯度
层的使用让整个路程非常的简洁和规范,事实上之后我们设计的复杂神经网络,都是以这种方式调用层的。
加法层的实现
#加法层
class AddLayer:
def __init__(self):
pass
def forward(self, x, y):
out = x + y
return out
def backward(self, dout):
dx = dout * 1
dy = dout * 1
return dx, dy
2.更进一步 神经网络常用层的实现
Affine层
正如前面所说,神经网络中不会单独使用那么简单的乘法层或加法层。而把它们两者合在一起当成一个层就是神经网络中最基础的Affine层啦。
Affine(仿射)变换包括一次线性变换和一次平移,分别对应神经网络的加权和运算与加偏置运算,而神经网络的正向传播中进行的矩阵的乘积运算在几何学领域被称为“仿射变换”。
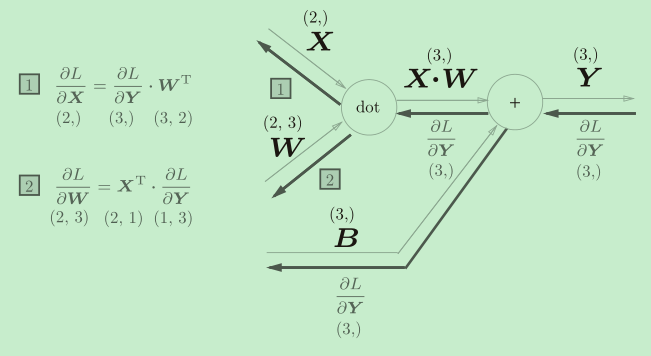
上图就是Affine层的正向传播和反向传播示意图。
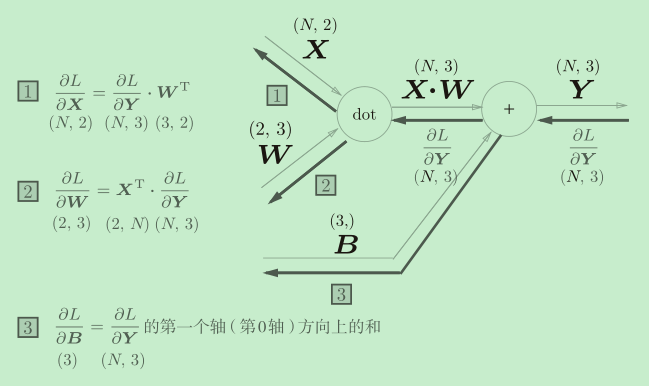
这是实现了批处理的Affine层。
激活函数层的实现
有关激活函数和softmax_with_loss的理论知识,我之前的文章神经网络中的激活函数与损失函数&深入理解推导softmax交叉熵有深入的讲解。
Sigmoid层
class Sigmoid:
def __init__(self):
self.out = None
def forward(self, x):
out = sigmoid(x)
self.out = out
return out
def backward(self, dout):
dx = dout * (1.0 - self.out) * self.out
return dx
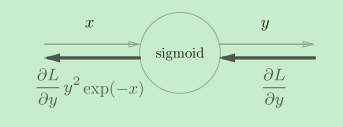 简化后=>
简化后=> 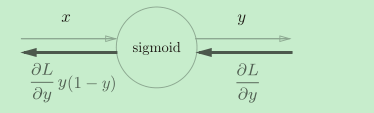
Sigmoid层的实现就很简单了,我们之前也构建过sigmoid正向和反向传播的实现,这里就不在细说了。
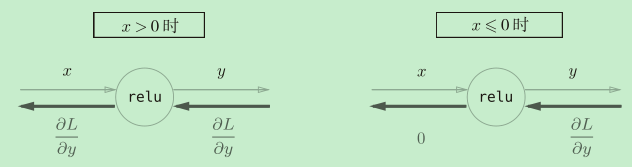
ReLU层
ReLU也是一个常用的激活函数。
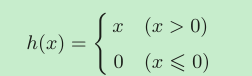
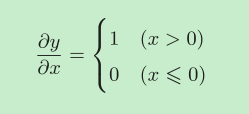
class Relu:
def __init__(self):
self.mask = None
def forward(self, x):
# 记录值小于等于零的输入的坐标
self.mask = (x <= 0)
out = x.copy()
# 正向传播时,把这些位置变为一,其余不变
out[self.mask] = 0
return out
def backward(self, dout):
# 反向传播时,把这些位置变为零,其余不变
dout[self.mask] = 0
dx = dout
return dx
Relu实现的关键是保存记录“值小于等于零的输入的坐标”:正向传播时,把这些位置变为一,其余不变;反向传播时,把这些位置变为零,其余不变。
SoftmaxWithLoss层
在实际使用中,softmax激活函数常常和交叉熵损失放在一起使用,这是因为它们组合在一起反向传播时会带来神奇的结果(即反向传播值是y-t)例如在tensorflow库中,一般也推荐使用统一的接口,而不是单独使用Softmax函数与交叉熵损失函数。
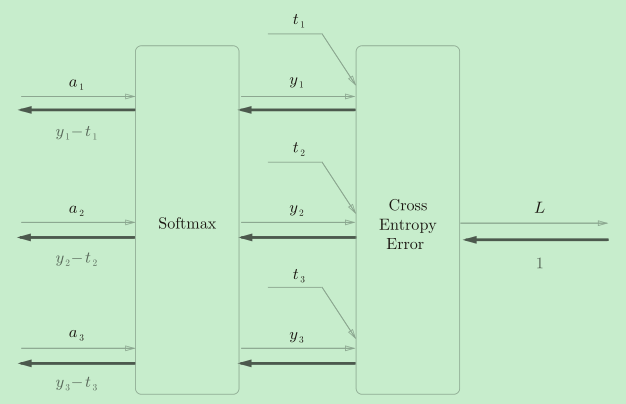
class SoftmaxWithLoss:
def __init__(self):
self.loss = None
self.y = None # softmax的输出
self.t = None # 监督数据
def forward(self, x, t):
self.t = t
self.y = softmax(x)
self.loss = cross_entropy_error(self.y, self.t)
return self.loss
def backward(self, dout=1):
batch_size = self.t.shape[0]
if self.t.size == self.y.size: # 监督数据是one-hot-vector的情况
dx = (self.y - self.t) / batch_size
else: # 监督数据是标签形式的情况
dx = self.y.copy()
dx[np.arange(batch_size), self.t] -= 1
dx = dx / batch_size
return dx
SoftmaxWithLoss的正向传播和反向传播不论是推导还是代码实现,我们之前都做过了,这里只是简单的把它们组合在一起。
3.使用层组装神经网络
class TwoLayerNet:
def __init__(self, input_size, hidden_size, output_size, weight_init_std = 0.01):
# 初始化权重
self.params = {}
self.params['W1'] = weight_init_std * np.random.randn(input_size, hidden_size)
self.params['b1'] = np.zeros(hidden_size)
self.params['W2'] = weight_init_std * np.random.randn(hidden_size, output_size)
self.params['b2'] = np.zeros(output_size)
# 生成层
self.layers = OrderedDict()
self.layers['Affine1'] = Affine(self.params['W1'], self.params['b1'])
self.layers['Relu1'] = Relu()
self.layers['Affine2'] = Affine(self.params['W2'], self.params['b2'])
self.lastLayer = SoftmaxWithLoss()
def predict(self, x):
#!!!!!!!!!!!!!!!!
for layer in self.layers.values():
x = layer.forward(x)
return x
# x:输入数据, t:监督数据
def loss(self, x, t):
y = self.predict(x)
return self.lastLayer.forward(y, t)
def accuracy(self, x, t):
y = self.predict(x)
y = np.argmax(y, axis=1)
if t.ndim != 1: t = np.argmax(t, axis=1)
accuracy = np.sum(y == t) / float(x.shape[0])
return accuracy
def gradient(self, x, t):
# forward
self.loss(x, t)
# backward
dout = 1
dout = self.lastLayer.backward(dout)
layers = list(self.layers.values())
# 反转list
layers.reverse()
# !!!!!!!!!!!!!!!!!!!!!!!!
for layer in layers:
dout = layer.backward(dout)
# 设定
grads = {}
grads['W1'], grads['b1'] = self.layers['Affine1'].dW, self.layers['Affine1'].db
grads['W2'], grads['b2'] = self.layers['Affine2'].dW, self.layers['Affine2'].db
return grads
代码中用来存放所有层的是“OrderedDict” 也就是”有顺序的字典“,它在提供像字典一样的键值对存储访问的同时,还提供了顺序访问能力。
可以看到,神经网络计算梯度的方式就是:
- 初始化
- 按照正向传播顺序一次调用所有层的.forward方法
- 按照反向传播顺序一次调用所有层的.backward方法,并获取梯度
调用层的方法和之前一模一样,这里就不再展示代码了。
4.扩展神经网络
如果我们想要把我们的神经网络编程一个类似下面的结构,那么用层实现的好处就凸显出来了,因为我们仅仅需要在初始化和存梯度的时候简单得加上机上代码,就可以实现对网络的扩展或更改了。
初始化时简单增加几行代码:
def __init__(self, input_size, hidden_size_1,hidden_size_2, output_size, weight_init_std=0.01):
# 初始化权重
self.params = {}
self.params['W1'] = weight_init_std * np.random.randn(input_size, hidden_size_1)
self.params['b1'] = np.zeros(hidden_size_1)
self.params['W2'] = weight_init_std * np.random.randn(hidden_size_1, hidden_size_2)
self.params['b2'] = np.zeros(hidden_size_2)
self.params['W3'] = weight_init_std * np.random.randn(hidden_size_2, output_size)
self.params['b3'] = np.zeros(output_size)
# 生成层
self.layers = OrderedDict()
self.layers['Affine1'] = Affine(self.params['W1'], self.params['b1'])
self.layers['Relu1'] = Relu()
self.layers['Affine2'] = Affine(self.params['W2'], self.params['b2'])
self.layers['Sigmoid1'] = Sigmoid()
self.layers['Affine3'] = Affine(self.params['w3'],self.params['b3'])
self.lastLayer = SoftmaxWithLoss()
存梯度时增加两行代码。
# 设定
grads = {}
grads['W1'] = self.layers['Affine1'].dW
grads['b1'] = self.layers['Affine1'].db
grads['W2'] = self.layers['Affine2'].dW
grads['b2'] = self.layers['Affine2'].db
grads['W3'] = self.layers['Affine3'].dW
grads['b3'] = self.layers['Affine3'].db