概述
- Encoder-Decoder 并不是一个具体的模型,而是一个通用的框架。
- Encoder 和 Decoder 部分可以是任意文字,语音,图像,视频数据
- 模型可以是 CNN,RNN,LSTM,GRU,Attention 等等
- 所谓编码,就是将输入序列转化转化成一个固定长度向量, 解码,就是讲之前生成的固定向量再转化出输出序列。
注意点:
- 不管输入序列和输出序列长度是什么,中间的「向量 c」长度都是固定的。 这是Encoder-decoder框架的的缺点
- 不同的任务可以选择不同的编码器和解码器 (RNN,CNN,LSTM,GRU)。
- Encoder-Decoder 是一个 End-to-End 的学习算法,以机器翻译为力,可以将法语翻译成英语。这样的模型也可以叫做 Seq2Seq。
Seq2Seq( Sequence-to-sequence )
- 输入序列和输出序列的长度是可变的
- Seq2Seq 强调目的,不特指具体方法,满足输入序列,输出序列的目的,都可以统称为 Seq2Seq 模型。
- Seq2Seq 使用的具体方法基本都是属于 Encoder-Decoder 模型的范畴。
For example
- 在训练数据集中,我们可以在每个句子后附特殊字符 ”“ (end of sequence) 以表示序列终止
- 每个句子前用到了特殊字符 “” (begin of seqence) 表示序列开始
- Encoder 在最终时间步的隐状态作为输入句子表征和编码信息。??
- Decoder 在各个时间步中使用输入句子的编码信息和上一个时间步的输出以及隐藏状态作为输入。 ??
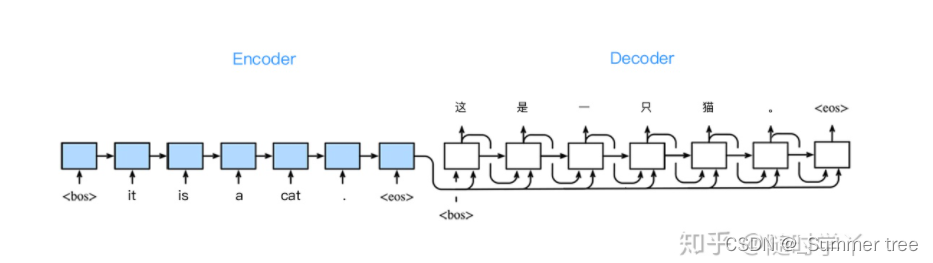
案例:英文 it is a cat. 翻译成中文的过程。
- 先将整个源句子进行符号化处理,以一个固定的特殊标记作为翻译的开始符号和结束符号。此时句子变成 it is a cat .
- 对序列进行建模,得到概率最大的译词,如第一个词为 “这”。将生成的词加入译文序列,重复上述步骤,不断迭代。
- 直到终止符号被模型选择出来,停止迭代过程,并进行反符号化处理,得到译文。
Encoder-Decoder的缺陷
→ 中间的「向量 c」长度都是固定的
- RNN 结构的 Encoder-Decoder 模型存在长程梯度消失问题
- 对于较长的句子,我们很难寄希望于将输入的序列转化为定长的向量而保存所有有效信息
- 即便 LSTM 加了门控机制可以选择性遗忘和记忆,随着所需翻译的句子难度增加,这个结构的效果仍然不理想
Attention 机制的引入
- Attention 就是为了解决信息过长导致信息丢失的问题
- 在 Attention 模型中,我们翻译当前词,会寻找源语句中相对应的几个词语,然后结合之前已经翻译的序列来翻译下一个词。
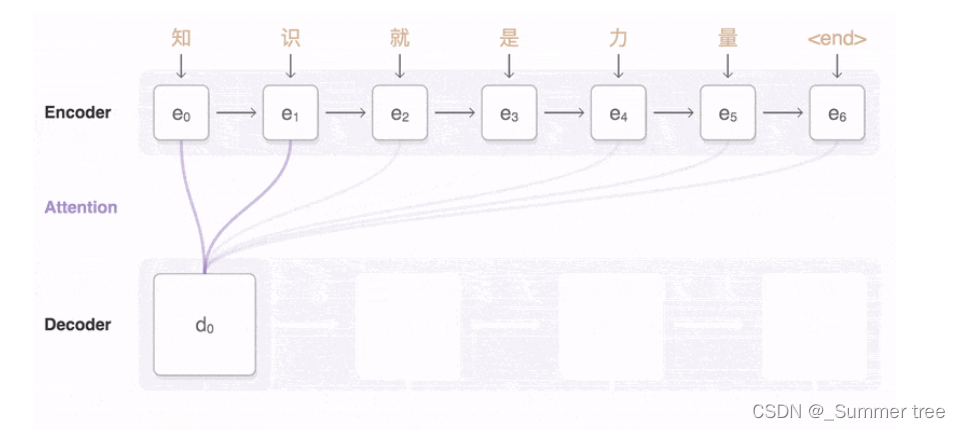
Attention 如何准确将注意力放在关注的地方呢?
- 对 RNN 的输出计算注意程度,通过计算最终时刻的向量与任意 i 时刻向量的权重,通过 softmax 计算出得到注意力偏向分数,如果对某一个序列特别注意,那么计算的偏向分数将会比较大。
- 计算 Encoder 中每个时刻的隐向量 ??
- 将各个时刻对于最后输出的注意力分数进行加权,计算出每个时刻 i 向量应该赋予多少注意力
- decoder 每个时刻都会将 ③ 部分的注意力权重输入到 Decoder 中,此时 Decoder 中的输入有:经过注意力加权的隐藏层向量,Encoder 的输出向量,以及 Decoder 上一时刻的隐向量
- Decoder 通过不断迭代,Decoder 可以输出最终翻译的序列。
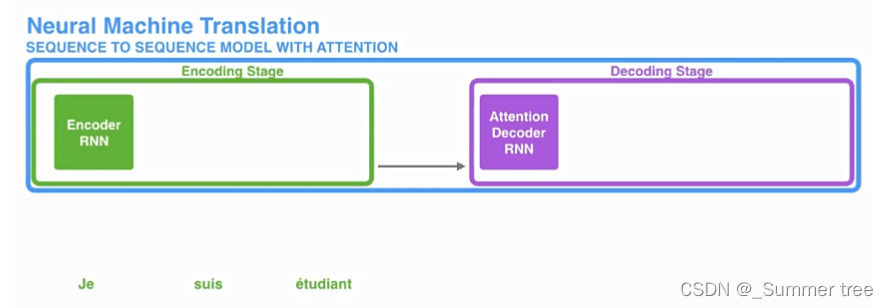
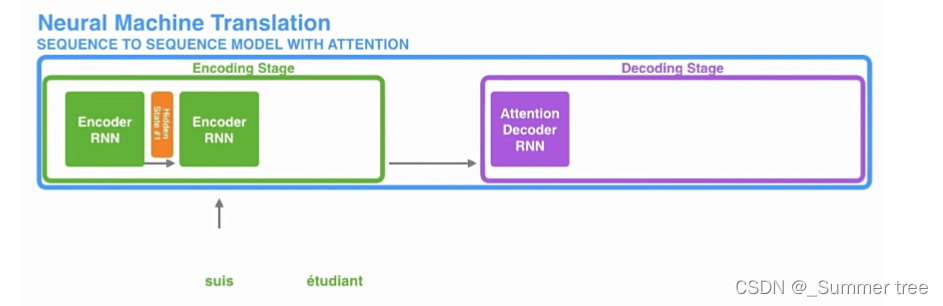
引入 Attention 的 Encoder-Decoder 框架下,完成机器翻译任务的大致流程如下:
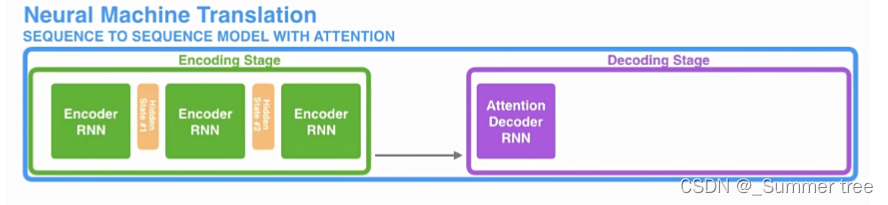
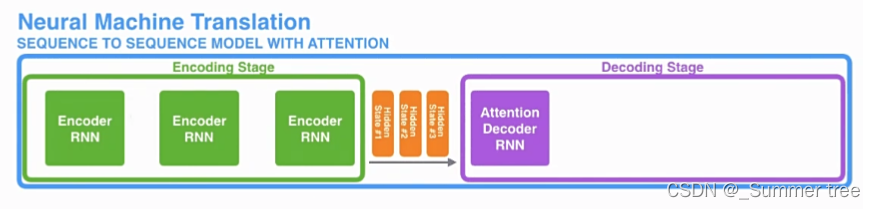
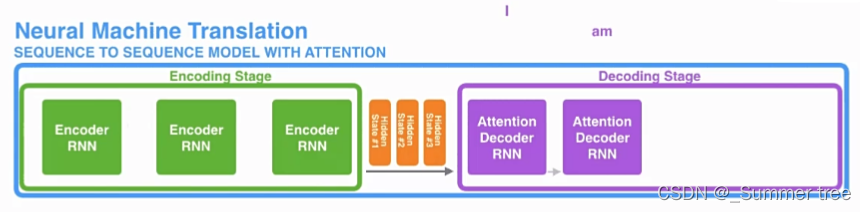
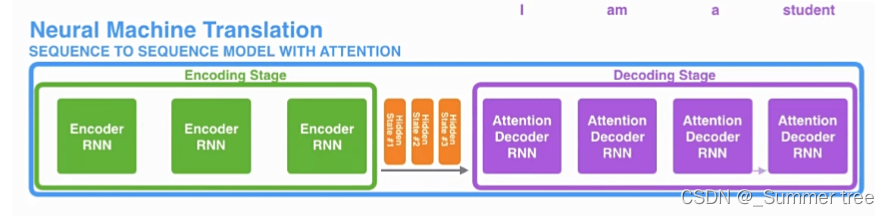
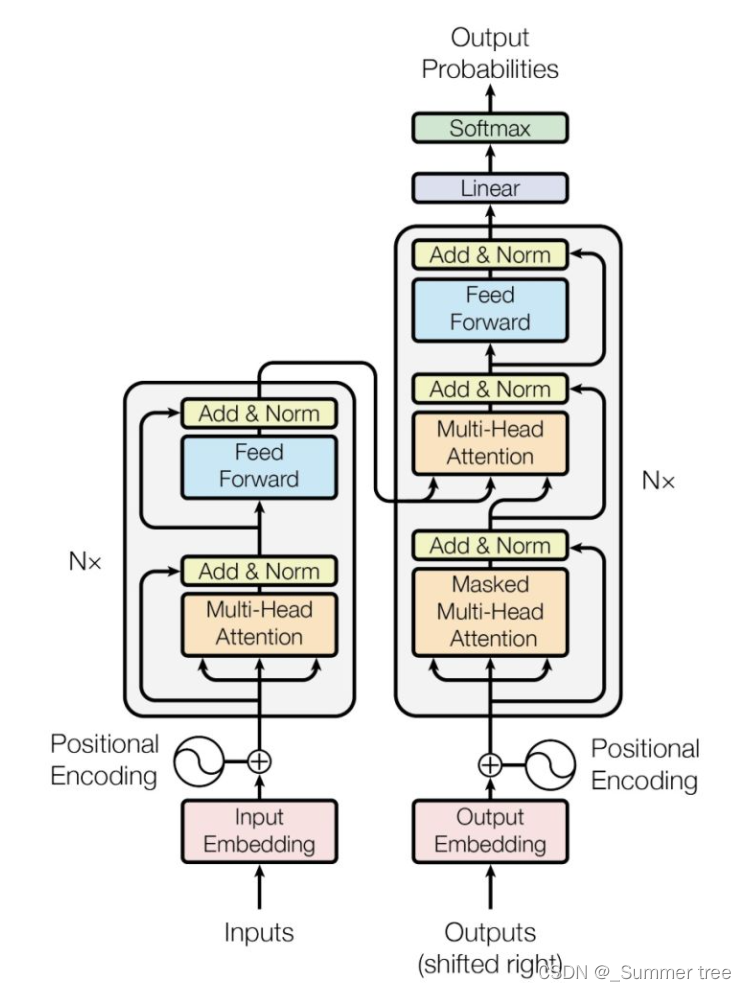
Transformer中的Encoder-Decoder
- Transformer 中的 Attention 是 Self-Attention (自注意力机制),而且是 Multi-Head Attention (多头注意力机制)
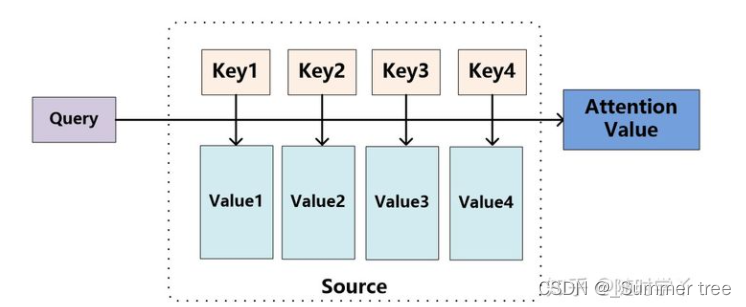
Attention 机制
- Source 是由一系列 组成,此时给定 Target 中某个元素 Query,通过计算 Query 和 各个 Key 的相似性,得到每个 Key 对 Value 的权重系数,然后对 Value 进行加权求和,即得到最终 Attention 数值。
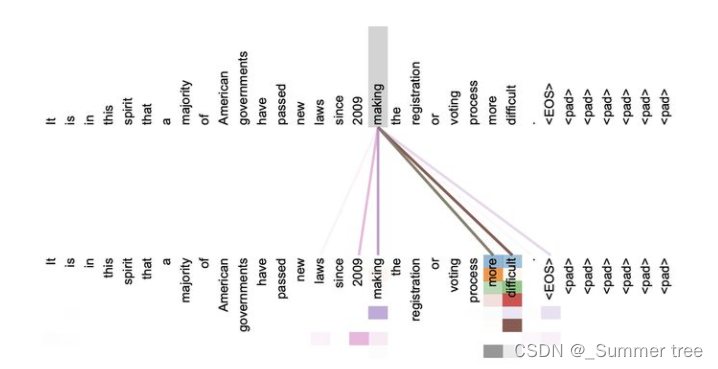
self-Attention
- 指的不是 Target 和 Source 之间的 Attention 机制,而是 Source 内部元素之间或者 Target 内部元素之间发生的 Attention 机制,也可以理解为 Target = Source 的特殊情况下的 Attention 机制。
- Source = Target,也即是 Key = Value = Query
- Self-Attention 可以捕获同一个句子中单词之间的一些句法特征 (图 1:有一定距离的短语结构) 或语义特征 (图 2:its 指代的对象 Law)。
- 引入 Self-Attention 后会更容易捕获句子中长距离相互依赖特征,因为 Self-Attention 在计算过程中直接将句子任意两个单词的联系起来
- 由于不依赖时间序列这一特性,Self-Attention 增加了计算的并行性。
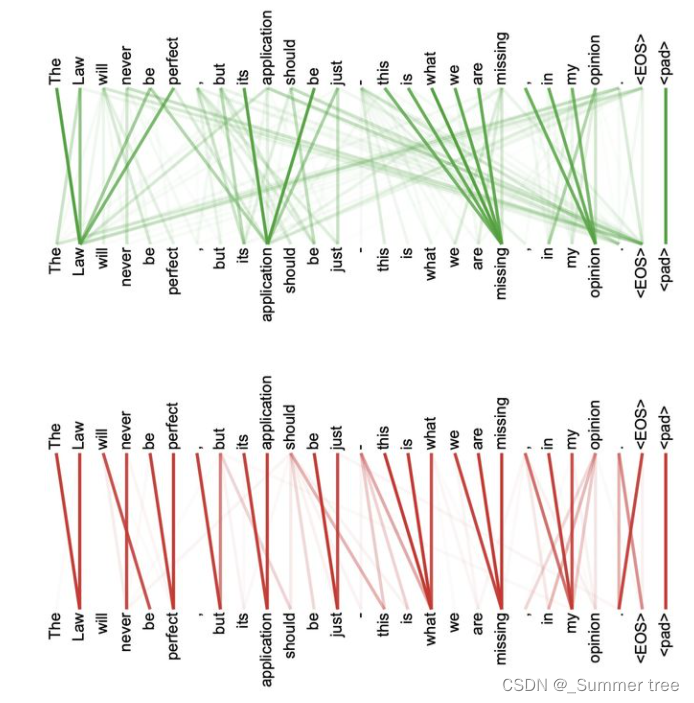
Multi-Head Attention
- 将模型分为多个头,形成多个子空间,可以让模型去关注不同方向的信息
- Transformer 或 Bert 的特定层是有独特功能的,底层更偏向于关注语法,顶层更偏向于关注语义
- 同一层中,总有那么一两个头独一无二,和其它头关注的 Token 不同
- 下面是两个 Self-Attention 执行同一个句子时候展现的不同的注意力,利用多头机制,明显学会了不同的任务下采取不一样的注意力。
Transformer 中 Encoder 由 6 个相同的层组成,每个层包含 2 个部分:
- Multi-Head Self-Attention
- Position-Wise Feed-Forward Network (全连接层)
Decoder 也是由 6 个相同的层组成,每个层包含 3 个部分:
- Multi-Head Self-Attention
- Multi-Head Context-Attention
- Position-Wise Feed-Forward Network
上面每个部分都有残差连接 (redidual connection),然后接一个 Layer Normalization。
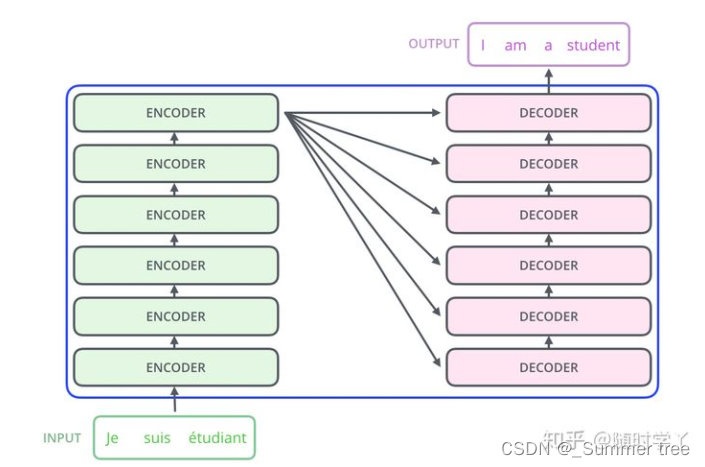
encoder-decoder的局限性:
编码和解码之间的唯一联系就是一个固定长度的语义向量C。编码器要将整个序列的信息压缩进一个固定长度的向量中去 。
- 语义向量无法完全表示整个序列的信息
- 先输入的内容携带的信息会被后输入的信息稀释掉
注意力模型:
模型在产生输出的时候,还会产生一个“注意力范围”表示接下来输出的时候要重点关注输入序列中的哪些部分,然后根据关注的区域来产生下一个输出,如此往复。
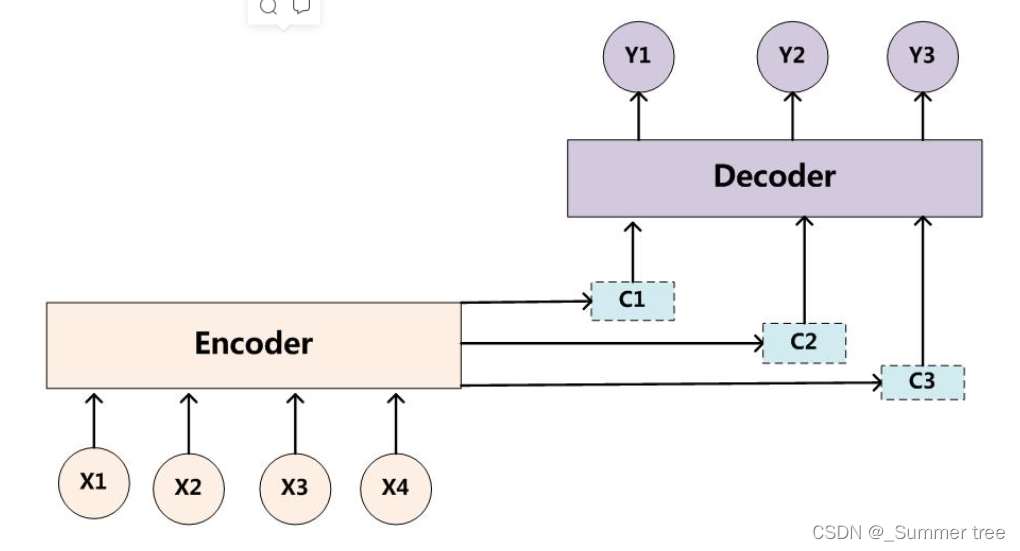
attention模型最大的区别就在于它不在要求编码器将所有输入信息都编码进一个固定长度的向量之中。
- 编码器需要将输入编码成一个向量的序列,而在解码的时候,每一步都会选择性的从向量序列中挑选一个子集进行进一步处理。
- 这样,在产生每一个输出的时候,都能够做到充分利用输入序列携带的信息。、
编码解码器的表示:
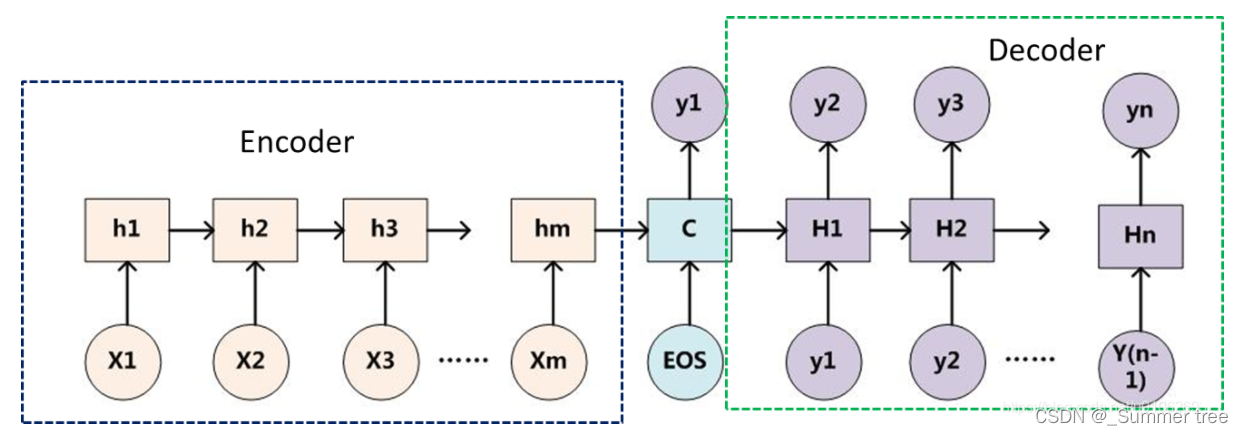
几点说明
- 不论输入和输出的长度是什么,中间的“向量c”长度都是固定的(这是它的缺陷所在)。
- 根据不同的任务可以选择不同的编码器和解码器(例如,CNN、RNN、LSTM、GRU等)
- Encoder-Decoder的一个显著特征就是:它是一个end-to-end的学习算法。
- 只要符合这种框架结构的模型都可以统称为Encoder-Decoder模型。
Seq2Seq与Encoder-Decoder的关系
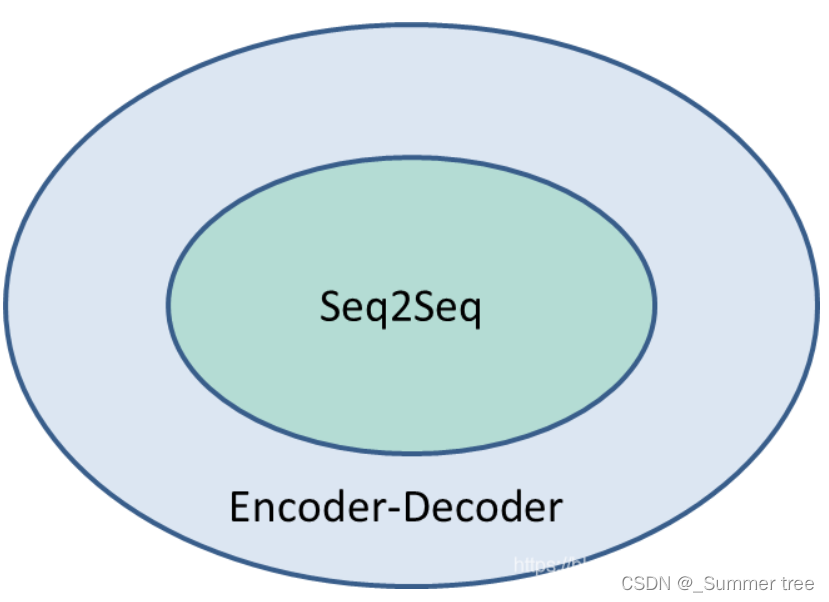 Encoder-Decoder强调的是模型设计(编码-解码的一个过程),Seq2Seq强调的是任务类型(序列到序列的问题)。
Encoder-Decoder强调的是模型设计(编码-解码的一个过程),Seq2Seq强调的是任务类型(序列到序列的问题)。
Encoder-Decoder的四种模式
最简单的解码模式:
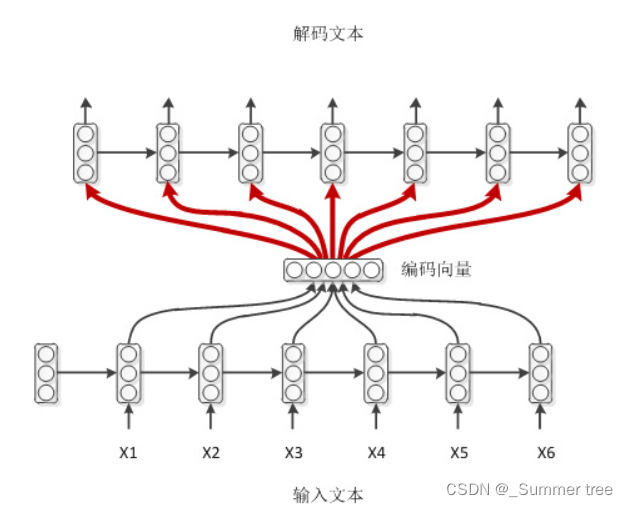
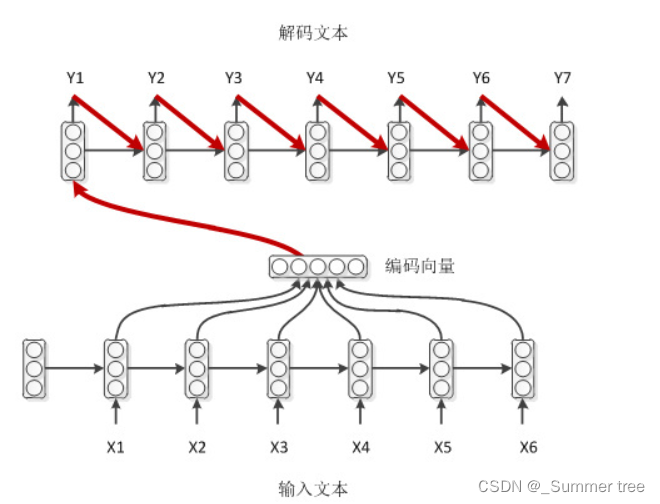
带输出回馈的解码模式
带编码向量的解码模式
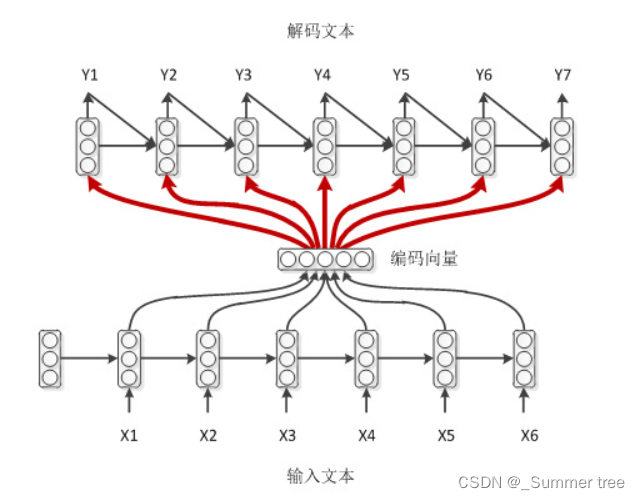
带注意力的解码模式

参考链接:
- https://zhuanlan.zhihu.com/p/109585084
- https://blog.csdn.net/u014595019/article/details/52826423
- https://blog.csdn.net/u010626937/article/details/104819570