���� PS (��������)������ʼ�Ȩ(IPTW )��������Rosenbaum��Ϊһ����ģ��Ϊ������ֱ�ӱ��������,���ڱʽṹģ�͡�����˵,���ǰ�����Э�����ͻ������ش����һ�����ʲ����м�Ȩ,�����Ļ�,��ֻ�ü�������Ȩ�ؾͿ�����,���������ࡣ��ô,��ν����Э������Ӱ����һ����������ֵ����ʾ��? ����ι�����������ֵ��? ���� Rosen-baum �� Rubin �Ķ���:��������ֵΪ�ڸ���һ��Э����(X i )������,�о����� i(i =1,2,��N)�����䵽ij����������ij��¶����(Z i =1)���������ʡ�

���� logistic �ع�ģ������������ֵ����ģ��
������ʵ�֡���ֱ�ӵõ���������ֵ��������ڽ��͵��������ơ�
������logistic �ع�������:
logistic �ع�����������Ĺ�����������ֵ�ķ���,������ԭ��Ϊ��������Ϥ������ʵ��,
Ҳ��Ŀǰ��õĹ��Ʒ�����logistic �ع�ģ������:
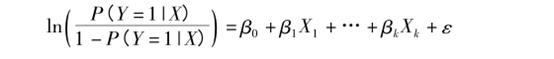
����Ϊ��Ԫlogistic �ع�,�ұ�һϵ�л������صķ��̻�����һ��0-1֮���Ŀ���¼�ʱ�䷢���ĸ���,����Խ������¼������Ŀ�����Խ��,�����͵��ڰѶ����������������һ���ۺ���������ʾ������ʼ�Ȩ(IPTW)���������������ֵĵ������������ݼ���ӵ�һ�ַ�����Robins�ȸ����ļ�Ȩϵ��(��)���㷽����:������۲쵥λ��Ȩ��Wt=1/PS,������۲쵥λ��Ȩ��Wc=1/(1һPS)��PSΪ�۲쵥λ����������ֵ���˷����õ���
��Ⱥ������ԭ����Ⱥ��������ͬ,���������Ⱥ�������ķ����С���б仯,�����нϵ� PS �Ĵ�����������нϸ� PS �ķǴ���������úܴ��Ȩ�ء����ڷdz����Ȩ�ػ��յ����ȶ��ԡ�Heman���˶Լ��㷽�����е���,�������о���Ⱥ�Ĵ����ʺͷǴ����ʼ��빫ʽ������õ��ȶ�Ȩ��(stabilized weights)���߷�����:������۲쵥λ��Ȩ��Wt=Pt/PS,������۲쵥λ��Ȩ��Wc=(1�CPt)/(1�CPS)�� Ŀǰ��������ʹ���ȶ�Ȩ�ء�
�ڼ���������,�����Ѿ���������ôʹ��R��SPSS��������ʼ�Ȩ����,��̨�з�˿��,��λ��Ƽ�Ȩ��Ļ��߱�,����ͼ,��Ȩ��������ϻ����ϱ���ƽ

��������ͨ��R����ʾһ����λ��Ƽ�Ȩ��Ļ��߱�,����ʹ�����ǵ��������(���ںŻظ�:�������,���Ի�ø�����),�����ȵ���R��������
library(tableone)
library(survey)
bc<-read.csv("E:/r/test/zaochan.csv",sep=',',header=TRUE)
bc <- na.omit(bc)


����һ��������������ض�������(���ںŻظ�:�������,���Ի�ø�����),����2500g����Ϊ�ǵ����ض������ݽ�������:low �Ƿ���С��2500g��������ض�,age ĸ������,lwt ĩ���¾�����,race ����,smoke ���ڳ���,ptl ���ʷ(����),ht �и�Ѫѹ��ʷ,ui �ӹ�����,ftv ����ʱ��ҽ���Ĵ���
bwt ������������ֵ��
�����Ȱѷ������ת������
bc <- na.omit(bc)
bc$race<-ifelse(bc$race=="black",1,ifelse(bc$race=="white",2,3))
bc$smoke<-ifelse(bc$smoke=="nonsmoker",0,1)
bc$low<-factor(bc$low)
bc$race<-factor(bc$race)
bc$ht<-factor(bc$ht)
bc$ui<-factor(bc$ui)
���������о���������Ѫѹ(ht)�����������ض�(low)��Ӱ��,�����Ȼ���һ����û�м�Ȩ�Ļ����߱�
dput(names(bc))##���������
allVars <-c("age", "lwt", "race", "smoke", "ptl", "ht", "ui",
"ftv", "bwt")###�������
fvars<-c("race", "smoke","ht","ui")#�����������Ϊfvars
tab2 <- CreateTableOne(vars = allVars, strata = "low" , data = bc, factorVars=fvars,
addOverall = TRUE )###���ƻ��߱�
print(tab2)#�������
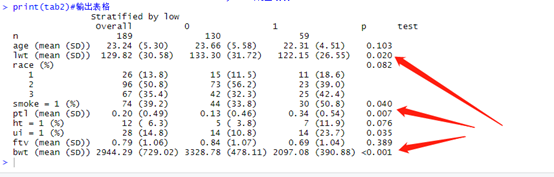
����ע�,��ͼ����3��ָ��P��С��0.05��,bwt���ڽ��ָ��,lwt�������ڻ���ָ�ꡣ
�����Ƚ����ع鷽������Ԥ��ֵ
pr<- glm(ht ~age + lwt + race + smoke + ptl + ui + ftv, data=bc,
family=binomial(link = "logit"))
pr1<-predict(pr,type = "response")
summary(bc$ht)

��ͼ��ʾ�и�Ѫѹ12��,û�и�Ѫѹ177��,�����������ֱ���������Ȩ��һ����Robins�ȸ����ļ�Ȩϵ��(��)���㷽��,
w<- (bc$ht==1) * (1/pr1) + (bc$ht==0) * (1)/(1-pr1)
�������Heman���˶Լ��㷽��,�����ȶ�Ȩ��Ҫ�����ɸ���(������Ѫѹ�ĸ���)
pt<-12/(177+12)
w1 <- (bc$ht==1) * (pt/pr1) + (bc$ht==0) * (1-pt)/(1-pr1)

����Ȩ�غ�Ϳ��Ի��Ƽ�Ȩ��Ļ��߱���,�������Ҫʹ�õ�survey����svydesign����,����һ��ǿ���R��,�������ɸ���Ȩ�صĻ��߱���
bcSvy1<- svydesign(ids = ~ id, strata = ~ low, weights = ~ w,
nest = TRUE, data = bc)
���ɺ�Ϳ���ʹ��TableOne�����Ƽ�Ȩ����
Svytab1<- svyCreateTableOne(vars = c( "age", "lwt", "race", "smoke", "ptl","ui",
"ftv", "bwt"),
strata = "low", data =bcSvy1 ,
factorVars = c("race", "smoke","ht","ui"))
Svytab1
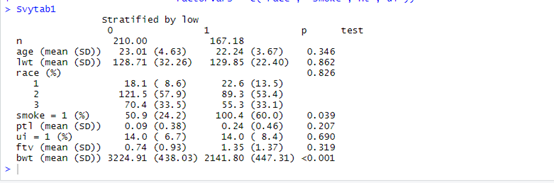
����ͼ��֪������Ȩ��,ÿ�鲡�����Ѿ������˸ı�,lwt������������Ѿ�����ƽ,ʹ�����黼�ߵıȽϸ��Ӿ��пɱ���,��������ʹ��Heman���˶Լ��㷽������Ȩ�����ɻ��߱���
bcSvy2<- svydesign(ids = ~ id, strata = ~ low, weights = ~ w1,
nest = TRUE, data = bc)
Svytab2<- svyCreateTableOne(vars = c( "age", "lwt", "race", "smoke", "ptl", "ui",
"ftv", "bwt"),
strata = "low", data =bcSvy2 ,
factorVars = c("race", "smoke","ht","ui"))
Svytab2
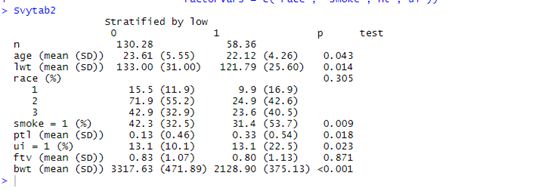
���ǿ��Կ���,��Ա������е�����,Heman�������ɵĻ��߱���,������û��Robins�����IJ������仯��ô��,��������ƽ����������û��Robins������úá�������˵Robins������Heman��������,�����ڲ�ͬ��������,���ַ����������ơ�
