面向物联网的可重构流式深度卷积神经网络加速器
摘要
卷积神经网络(CNN)在图像检测中具有显著的准确性。为了在物联网设备中使用CNN实现图像检测,提出了一种流媒体硬件加速器。建议的加速器通过避免不必要的数据移动来优化能效。利用独特的滤波器分解技术,加速器可以支持任意卷积窗口大小。此外,通过使用单独的池单元,最大池函数可以与卷积并行计算,从而提高吞吐量。台积电65nm技术实现了一个加速器原型,核心尺寸为5mm2。该加速器可以支持主要的CNN,并在350mW时实现152GOPS峰值吞吐量和434GOPS/W能效,使其成为智能物联网设备的一个有前途的硬件加速器。
Index Terms―Convolution Neural Network, Deep Learning, Hardware
Accelerator, IoT(卷积神经网络,深度学习,硬件加速器,物联网)
一、导言
机器学习在物联网设备中提供了许多创新应用,如人脸识别、智能安全和目标检测。最先进的机器学习计算主要依赖于云服务器。得益于图形处理单元(GPU)强大的计算能力,云可以处理来自设备的高通量视频数据,并使用CNN在大多数人工智能应用程序上实现前所未有的准确性。然而,这种方法也有自己的缺点。由于网络连接对于基于云的人工智能应用程序是必要的,这些应用程序不能在没有网络覆盖的区域运行。此外,通过网络传输数据会导致显著的延迟,这对于安全系统等实时人工智能应用来说是不可接受的。最后,大多数物联网应用的功耗和成本预算都很高,既不能容忍本地GPU解决方案,也不能向数据中心服务器传输大量图像和音频数据。
为了应对这些挑战,提出了一种本地化的人工智能处理方案。本地化人工智能处理方案的目标是在客户端对采集到的数据进行处理,在不接入通信网络的情况下完成整个人工智能计算。
通常,这是通过本地GPU或DSP完成的。导致有限的计算能力和相对较大的功耗,使得不适合在功率有限的物联网设备上运行计算密集型神经网络,如CNN。在物联网设备内设计一个专用的CNN加速器至关重要,该加速器能够以最小的功耗支持高性能人工智能计算。在神经网络加速方面,一些已报告的工作专注于提供一种计算通用神经网络的体系结构。例如,通过对神经网络进行适当的修剪,提出了一种基于神经网络稀疏性的高效硬件结构。在不考虑参数重用的情况下,计算完全连通的深层神经网络是一种更通用的体系结构。相反,CNN有其独特的功能,即在扫描过程中,过滤器的权重将在整个图像中大量重复使用。得益于这一功能,许多专用CNN硬件加速器被报告。大多数报告的CNN加速器只关注于加速卷积部分,忽略了池函数的实现,这是CNN网络中的一个常见层。
演示了一个CNN硬件加速器,使用了一个带有168个处理元素的空间架构。报告了另一种具有循环展开优化的卷积加速器。由于这些加速器中没有实现池功能,卷积结果必须传输到CPU/GPU以运行池功能,反馈给加速器以计算下一层。这种数据移动不仅消耗大量功耗,而且还限制了整体性能。另一方面,一些工作报告了高度可配置的神经网络处理器,但需要复杂的数据流控制。增加了物联网设备的硬件开销。例如,报告了一个CNN处理器在65nm CMOS技术中占据了16 mm2的硅面积,对于低成本的物联网芯片来说是不可容忍的。此外,最近的一些报告,建议使用存储器为CNN执行神经形态计算。然而,目前在大型CMOS铸造厂中,存储器的制造仍然不受支持。因此,这种架构很难嵌入物联网芯片。
提出了一种新的流媒体硬件架构,用于在物联网平台上进行CNN推理,假设CNN模型经过预训练。专注于优化数据移动流,以最小化数据访问并实现计算的高能效。本文还提出了一种新的方法,将大型核计算分解为多个并行的小型核计算。结合集成池功能,提出的加速器架构,可以支持完成的一站式CNN加速,包括任意大小的卷积和可重构池。本文的主要贡献包括:
1.CNN加速器设计,使用流式数据流实现最佳能效。
2.一种交错结构,能够在不增加SRAM输入带宽的情况下,对多个输出特性进行并行计算。
3.一种将大型滤波器计算分解为多个小型滤波器计算的方法,在不增加额外硬件代价的情况下实现高可重构性。
4.一个辅助池块,在主机为CNN计算服务时支持池功能。
5.通过FPGA验证的原型设计,可实现152个GOPS的峰值性能和434个GOPS/W的能效。
论文的结构如下。
在第二节中,首先介绍构成CNN的主要层。在第三节中,将介绍系统的总体架构。在第四节中,将讨论所提出的流式体系结构,以实现高效率的卷积计算、提供可重构性的滤波器分解技术和池化实现。第五部分介绍了关键模块的设计。第六部分报告了实验结果,第七部分得出了结论。
二、层描述
最先进的CNN网络(如AlexNet、VGG-18等),主要由三个典型层组成:卷积层、池层和分类层。卷积层构成了神经网络的大部分,在两个卷积层之间插入池层,以实现中间数据大小的缩减和非线性映射。分类层通常是CNN的最后一层,不需要大量计算。假设分类层可以通过软件计算实现,不会在硬件加速器中实现。下面的小节将详细解释卷积层和池层的功能。
A.卷积层
卷积层的主要作用是应用卷积函数将输入(上一)层的图像映射到下一层。因为每个输入层可以有多个输入特征(后面称为通道),所以卷积是3D的。与常规卷积不同的是,神经网络中的卷积是通过在每个单独的输入通道中形成一个区域滤波器窗口,实现本地化的,常规卷积需要整个输入数据来生成一个输出数据。这组区域过滤器窗口被视为一个过滤器。输出数据通过计算滤波器权重的内积和滤波器覆盖的输入数据获得。通过使用卷积滤波器扫描输入通道,可以获得输出特征。使用不同的过滤器可以计算多个输出特征。将在每个最终过滤结果中添加单独的偏差权重。该函数的算术表示如(1)所示。
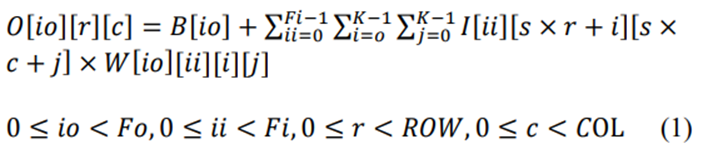
在这里𝑖𝑜 表示当前输出功能的索引号,Fi和𝐹𝑜 表示输入通道和输出功能的总数。r和c代表当前输出特征数据的行和列编号;s是卷积窗口的步长,𝑊 表示过滤器的权重,𝐵 表示每个过滤器的偏移权重。K𝑅𝑂𝑊 和𝐶𝑂𝐿, 分别是内核大小、输出特征行大小和列大小。
根据上述参数的定义,输入层𝐹𝑖 频道。每个通道的宽度是𝐶𝑂𝐿×𝑠 身高是𝑅𝑂𝑊×𝑠. 图层输出包括𝐹𝑜 特征。每个特征的宽度是𝐶𝑂𝐿,高是𝑅𝑂𝑊. 过滤器编号与输出特征编号相同。在每个过滤器中,都是通过𝐹𝑖 分离的过滤器窗口。每个窗口的内核大小为K。整个卷积过程如图1所示。
B.池层
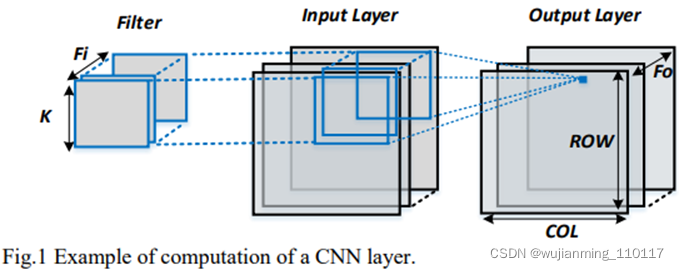
除了卷积层,池层也是常规CNN的重要组成部分。池层的作用是从每个通道中的一组相邻图像像素中提取信息。通常,池层可以分为两类:最大池层和平均池层。最大池层选择池窗口内的最大图像数据值,平均池层提供池窗口内数据的平均值。这两个池操作的数学表示定义为(2)和(3)。每个输入通道分别合并,使图层的输入通道号等于输出特征号。图2是最大池功能的示例。

在这里,𝐼[𝑟][𝑐] 表示位置(r,c)处输入通道的数据,池窗口的内核大小为K。
三、 系统概述
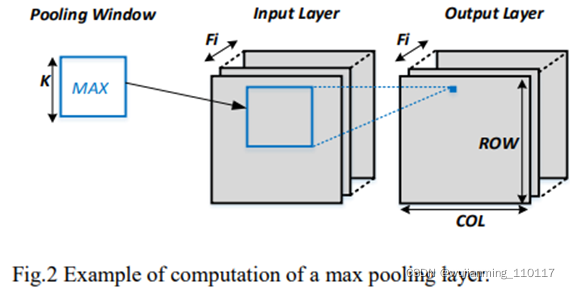
CNN加速器的整体流媒体架构如图3所示。已经证明,深度网络可以用随机舍入的16位定点数表示,分类精度几乎没有降低。与16位定点加法器相比,16位浮点加法器的实现需要更多的逻辑门。该加速器的数据格式被设置为16位定点。加速器包括一个96 Kbyte单端口SRAM作为缓冲bank,用于存储中间数据并与DRAM交换数据。缓冲组分为两组。一个用于当前层的输入数据,另一个用于存储输出数据。输入通道和输出功能已编号。在每一组中,缓冲组进一步分为A组和B组。A组用于存储其编号为奇数的通道/特征,B组用于存储其编号为偶数的通道/特征。实现了一个COL缓冲模块,将缓冲库的输出重新映射到卷积单元(CU)引擎的输入。CU引擎由16个卷积单元组成,实现高度并行的卷积计算。每个单元可以支持卷积运算,内核大小最多为三个。引擎内部包含一个预取控制器,用于定期从直接内存访问(DMA)控制器中获取参数,更新引擎中的权重和偏差值。在加速器中实现了带暂存器的累积(ACCU)缓冲器。scratchpad行与累加器一起用于累积和存储来自CU引擎的部分卷积结果。ACCU缓冲区中还嵌入了一个单独的max pooling模块,在必要时汇集输出层数据。
该加速器通过16位高级可扩展接口(AXI)总线进行控制,命令解码器集成在加速器内部。
处理后的CNN网络的命令预先存储在DRAM中,在加速器启用时自动加载到128深度命令FIFO。这些命令可以分为两类:配置命令和执行命令。在多个层之间插入配置命令,以配置即将到来的层的属性,如通道大小和数量、启用ReLU功能或最大池功能。执行命令用于启动卷积/池计算。大尺寸卷积滤波器的移位地址值的配置,包括在执行命令中(在第五节中解释)。
卷积从重置ACCU缓冲区中的图像scratchpad行开始。然后,输入层数据将按顺序发送到CU引擎。CU引擎将计算每个通道数据的内积及相应输出特征的滤波器权重。CU引擎的输出结果将被传递到ACCU缓冲块,并与暂存器中存储的结果一起累积。扫描完所有通道后,scratchpad行中累积的图像将作为输出特征之一发送回缓冲bank。
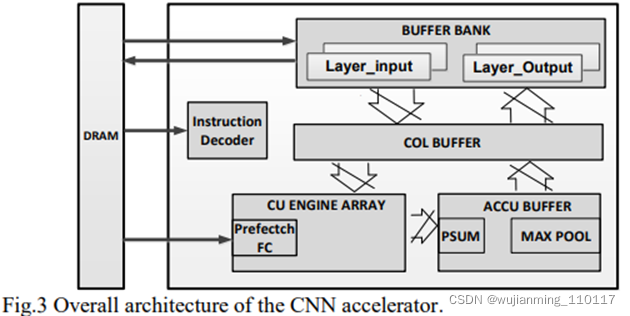
在完成第一个特征的计算后,CNN加速器将使用DRAM更新的滤波器权重复制上述卷积过程,以生成下一个输出特征。该程序将持续复制,直到计算出所有特征。显示该过程的总体示意图如图4所示。

四、 流媒体和可重构功能
拟议的CNN加速器通过使用以下三种技术实现可重构性和高能效:
1.通过仅使用3x3大小的计算单元,使用滤波器分解技术支持大型内核大小的滤波器的计算。
2.流式数据流,最大限度地减少总线控制和模块接口,降低硬件成本,实现高能效。
3.分离池块,与卷积并行计算最大池,将卷积引擎用于平均池功能,以实现最低硬件设计成本。
A.滤波器分解
在典型的CNN网络中,过滤器的内核大小可以从非常小的大小(1x1)到非常大的大小(11x11)。硬件卷积引擎通常是为特定的内核大小设计的,只能支持低于其有限大小的滤波器计算。当计算内核大小超过其限制的卷积时,加速器需要离开软件进行计算,或者为大型内核大小的滤波器卷积添加额外的硬件单元。
为了最大限度地减少硬件资源的使用,提出了一种滤波器分解算法,通过仅使用3x3大小的CU,计算任意大的内核大小(>3x3)的卷积。该算法首先检查过滤器的内核大小。如果原始过滤器的内核大小不是3的精确倍数,将在原始过滤器的内核边界中添加零填充权重,将原始过滤器的内核大小扩展为3的倍数。由于边界中的附加权重为0,在计算过程中,扩展滤波器将产生与原始滤波器相同的输出值。将扩展的过滤器分解为几个3x3大小的过滤器。每个过滤器将根据左上角权重在原始过滤器中的相对位置,分配一个移位地址。例如,图4是将5x5滤波器分解为四个3x3滤波器的示例。在原始滤波器中添加一行和一列零填充。分解后的滤波器:F0、F1、F2、F3的移位地址为(0,0)、(0,3)、(3,0)、(3,3)。

分别计算每个分解后的滤波器和输入层,生成几个分解后的输出特征。通过(4)将这些分解的特征重新组合成一个最终的输出特征。
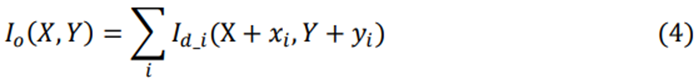
在这里𝐼𝑜 表示输出图像,𝐼𝑑_𝑖 代表𝑖’s分解过滤器的输出图像,(𝑋,𝑌) 表示当前输出数据的坐标地址,(𝑥𝑖,𝑦𝑖) 代表𝑖’过滤器的移位地址。这个滤波器分解的算术推导可以描述为(5)。

在这里𝐹3.𝐾(𝑎,𝑏) 表示内核大小为3K的过滤器,左上角的权重与图像中位置(a,b)处的像素值相乘。过滤器中的每个权重表示为𝑓(𝑖,𝑗) 在哪里,(𝑖,𝑗) 表示权重相对于过滤器内左上角权重的位置,𝐼𝑖(𝑎+3.𝑖+𝑙,𝑏+3.𝑗+𝑚) 表示图像像素在(𝑎+3.𝑖+𝑙,𝑏+3.𝑗+𝑚) 在图片中。𝐹3_𝑖_𝑗 表示K2的不同3x3内核大小的过滤器,计算函数定义为(6)。此外,3𝑖 和3𝑗 可以表示为每个3x3过滤器的移位地址。
根据(5)和(6),可以证明3Kx3K滤波器的计算,可以分解为K2个不同的3x3滤波器的计算,不会损失任何计算精度。图6是使用该滤波器分解技术,计算5x5卷积的示例。
这种分解技术可以最大限度地利用硬件资源,但代价是在过滤器边界中添加额外的零填充。虽然这种增加的零填充会导致计算资源的浪费,但CNN网络的整体效率损失相对较小。相反,CU引擎的设计变得简单得多,因为只需要支持1x1和3x3的卷积滤波器大小。可根据(7)计算总效率损失。

这是𝑀𝐴𝐶𝑡𝑜𝑡𝑎𝑙 表示引擎计算CNN网络所需的总乘法-累加运算,𝑀𝐴𝐶𝑧𝑒𝑟𝑜_𝑝𝑎𝑑𝑑𝑖𝑛𝑔 表示用于计算零填充部分的MAC操作。例如,一个11x11过滤器实际上有23/144 MAC操作用于计算零填充部分,导致效率损失16%。
表一是使用这种分解技术,对不同主要CNN网络效率损失的比较。

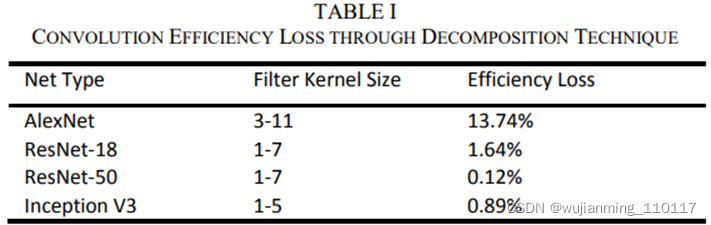
如表一所示,AlexNet的效率损失最大,因为在第一层有一个大的11x11过滤器。相反,小型过滤器大小的网络,如Resnet-18、Resnet-50、Inception V3,由于零填充,效率损失非常小。因此,非常适合这种体系结构。
B.流媒体架构
为了最小化数据移动并实现卷积计算的最佳能量效率,提出了一种用于CNN加速器的流结构。对于常规CNN卷积,包括多个级别的数据和权重重用:
1.重复使用每一组滤波器权重,扫描整个通道的图像。
2.每个输出特征都是通过扫描相同的输入层生成的。
流式架构通过利用CNN卷积中的上述功能,减少数据移动。
1) 过滤器权重重复使用:
在每个过滤器中,内核之间的权重是不同的。每个内核的权重将仅用于特定输入通道的数据。为了从中受益,所有滤波器权重都存储在DRAM中,只有在卷积过程中才会被提取到加速器中。
在3x3卷积过程中,获取的滤波器权重将存储在CU引擎中,输入通道的图像数据将流入CU引擎。CU引擎将产生权重和流式输入数据之间的内积,生成相应输出特征的部分结果,供ACCU缓冲器累积。在扫描整个通道之前,CU引擎中的权重不会更新。1x1卷积遵循与3x3卷积类似的方法,只是九个乘法器中有七个在卷积过程中关闭。左侧的两个乘法器将打开,同时计算两个不同输出特征的部分求和结果。
图7是显示该流的一个过滤器窗口移动的示例。真正的实现包括16个3x3过滤窗口,同时处理多行数据。通过使用该滤波器窗口扫描输入通道,数据流和模块接口变得更加简单,降低了硬件设计成本。
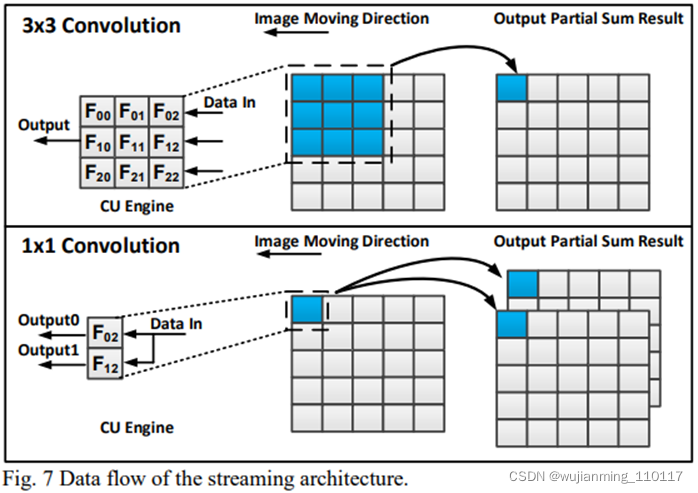
缓冲bank的输出带宽设置为256位/周期,每个数据大小为16位,对应于同时从不同行到CU引擎的16个数据流。这16个数据分为两组:八个数据来自奇数信道,另八个数据来自偶数信道。
为了最大限度地利用缓冲bank的输出带宽,两行FIFO缓冲区与每组行数据配对,将八个输入行传输到十个重叠的输出行。使得为每组行数据并行运行八个3x3 CU。包括在COL缓冲器中的FIFO缓冲器,如图8所示。这里,只为偶数个通道的数据绘制一半大小的COL缓冲区。真正的实现包括奇偶通道的FIFO缓冲区。

2) 输入通道重用:
在1x1卷积中,每个输出特征数据计算只需要在每个通道中进行一次乘法。导致浪费大部分硬件资源,因为CU引擎中的大多数乘法器都不会使用。
为了加快1x1卷积的计算速度,提出了一种交织结构,用于并行计算1x1卷积中两个输出特征的结果。由于计算每个输出特征需要扫描同一输入层,加速器可以在一次扫描期间,同时计算多个输出特征。如果同时计算多个特征,将导致CU引擎的输出带宽按比例增加。例如,同时输出两个功能,将导致CU引擎生成两倍于输入数据带宽的输出数据带宽。
为了防止这种情况,提出了一种交织结构,将16个输入数据分为偶数信道数据和奇数信道数据。这两组数据分别与两个不同特征的权重相乘,在CU引擎输出端总共得到32个数据(两个输出特征的部分结果)。然而,由于32个数据流是从两个不同的通道生成的,因此CU输出端需要一个求和函数组合,来自不同通道的相同特征的部分结果。通过这样做,数据带宽减少了一半,加法器的最终输出将与输入数据带宽相同。该功能的详细实现如图9所示。这里是X(O,0)?X(O,7)代表奇数通道的第1至第8行数据,X(E,0)?X(E,7)表示偶数个通道的第1到第8行数据。O(0,1),E(0,1)是奇数和偶数通道的第一特征部分结果,O(0,2),E(0,2)是奇数和偶数通道的第二特征部分结果。
C.汇集
加速器中还实现了池功能。池功能可以分为两类:最大池和平均池。
1) 平均池:
为了最小化硬件成本,通过重用卷积引擎实现了平均池功能。这可以通过使用以下步骤将平均池层替换为相同内核大小的卷积层实现:
1.创建一个卷积层,输出特征的数量等于输入通道的数量。内核大小与池窗口大小相同
2.在每个过滤器中,将相应通道的过滤器权重设置为1𝐾2,其中K是内核大小。所有其他通道的过滤器权重均设置为0。
这个卷积层的算术表示可以导出为(8)。

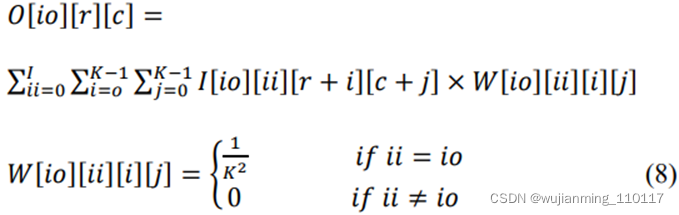
这里ii和io是输入通道号和输出特征号,r和c是输出特征的行和列号,W代表滤波器的权重。K是平均池窗口的内核大小。
2) 最大池:
max pooling层作为ACCU缓冲区内的一个单独块实现,用于汇集来自卷积块的输出特征。池块旨在支持两个和三个池窗口大小,涵盖主要CNN。第五节将描述该块的详细实现及与scratchpad行的连接。
五、模块实施
在本节中,有三个主要模块:
将讨论该加速器中的CU引擎、ACCU缓冲区和最大池。
A.CU引擎
如第四节所述,加速器使用九个乘法器组成CU,使用十六个CU组成CU引擎。CU的模块实现如图10所示。

CU引擎阵列包括九个处理引擎(PE)和一个用于组合输出的加法器。PE为输入数据和滤波器权重提供乘法函数,同时通过D触发器将其输入数据传递给下一级的PE。当卷积步长大于1时,可以根据EN_Ctrl信号打开/关闭乘法函数,以节省计算能力。
在3x3卷积中,相乘的结果将发送到CU中的加法器以执行求和,将求和的结果传递到最终输出。滤波器权重将通过DMA控制器从DRAM获取,通过全局总线预存储在CU中。当扫描一个通道时,将向CU发送一个同步的过滤器更新请求信号,以更新PE输入端的过滤器权重,用于下一个通道。
在1x1卷积中,只有PE(1,0)和PE(2,0)将开启。加法器将被禁用,两个输出结果将作为两个输出特征部分结果直接输出。
B.累计缓冲器
ACCU缓冲器用于累积CU引擎的输出部分求和结果,同时将特征输出数据临时存储在其scratchpad行中,等待缓冲bank读回。
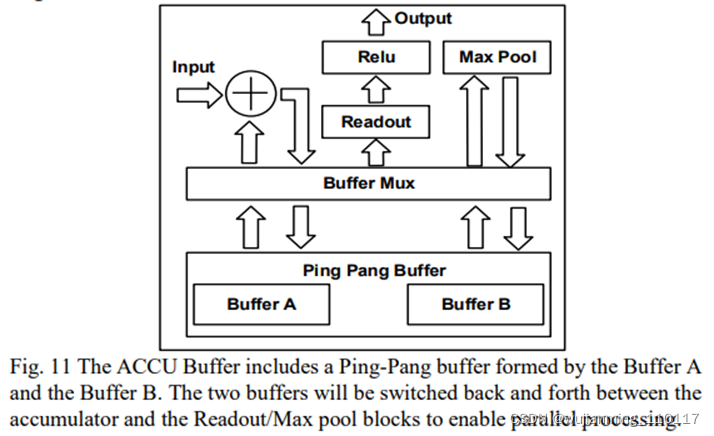
ACCU缓冲区包括一个乒乓缓冲区作为scratchpad行,一个累加器用于对部分结果求和,一个单独的池块用于最大池,以及一个读出块,用于将数据从scratchpad行读回缓冲bank。
乒乓球缓冲区分为两个不同的子缓冲区。在卷积期间,只有一个缓冲器将指向累加器,另一个缓冲器将连接到池块和读出块。这使得内核能够同时处理池函数和卷积函数。此外,从scratchpad行读回缓冲bank的数据,可以与卷积并行处理。
当累加器完成一个输出特征的累加时,乒乓缓冲器将切换其子缓冲器的方向,将存储输出特征的缓冲器指向池块和读出块。同时,之前连接到池侧的子缓冲区将转向累加器,以连续累加下一个输出特征部分求和结果。此外,ReLU功能在读出期间实现。ReLU功能可以通过将读出块的负输出归零来实现。
与卷积相比,读出和池函数每次只需要扫描一个输出特征,因此处理时间要短得多。得益于此,加速器可以连续运行卷积,不会对池和数据读出造成任何速度损失。ACCU-Buffer体系结构的详细实现如图11所示。
C.Max Pool
图12示出了最大池模块及其与scratchpad行的连接的总体架构。scratchpad并行存储来自一个输出特性的八行数据。八行数据共享一个列地址,可以同时访问。由于步幅大小在卷积中的差异,存储在scratchpad行中的数据可能无法全部验证。例如,当步幅等于2时,只有R0、R2、R4、R6存储验证数据。此外,池窗口的内核大小也可以配置为2或3。
为了适应不同的卷积步长和池大小情况,在最大池模块前面放置一个MUX,以选择相应最大池单元的验证输入数据。最大池单元由一个四输入比较器和一个反馈寄存器实现,用于存储中间比较器的输出结果。此外,max pooling模块中还嵌入了一个内部缓冲区。这是为了在池窗口内的某些数据尚未准备好时缓冲中间结果。



当池化开始时,比较器首先获取来自附近行的三个输入数据(2x2情况下有两个数据),输出输入数据中的最大值。这个临时最大值将反馈给比较器的输入,视为一个额外的输入,与下一个时钟周期的输入数据进行比较。此过程将重复,直到扫描整个池窗口的输入数据。将验证输出启用信号,在池窗口中输出最大值。
六、 结果
加速器在台积电65nm上实现加速器的技术和布局特征,如图13所示。核心尺寸为2mm x 2.5mm,在500MHz核心时钟下达到152 GOP/s的峰值吞吐量。由于内核可以支持任意大小的卷积层和池函数,可以加快大型CNN的建设。表II列出了芯片规格的摘要。电源基于概要设计汇编中的综合报告,面积和时钟速度基于Cadence中的地址和路线报告。PE代表芯片中的处理引擎,每个CU中的乘法器。能量效率定义为峰值吞吐量除以动态功耗。
加速器的区域分解如图14所示。
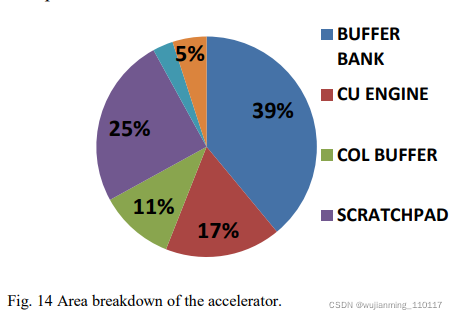
面积估计包括逻辑单元、寄存器和ARM编译器生成的单端口/双端口SRAM。如图所示,CU引擎仅占总面积的17%。缓冲区和scratchpad行占据了大部分区域。scratchpad采用双端口SRAM设计,以支持连续流,缓冲区组采用单端口SRAM实现。尽管scratchpad行内存的大小仅为缓冲区的1/6,但仍然占据了缓冲区一半以上的面积。
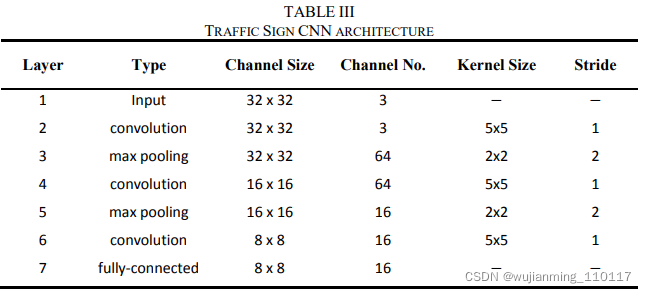
为了验证加速器的性能,有将硬件加速器IP下载到Xilinx Zynq 7200 FPGA中,使用修改了LeNet-5[21]来检测交通标志。过滤器坏了权重通过FPGA的现有的DMA控制器。DMA控制器配置为256深度64位宽度。交通标志网包括三个卷积层和两个池层,其结构总结见表三。
集成到FPGA中的应用处理器(AP)是用于控制加速器并启动计算。通过在FPGA内部使用DMA控制器,实现了加速器可以成功访问存储在DRAM中的数据和权重。演示设置如图15所示。演示从将交通标志下载到FPGA开始。计算完成后,检测到的交通标志结果将发送回PC并显示在监视器上。原始视频演示如所示。

即使是演示过的LeNet-5模型也只有一个输入通道大小为32×32,此加速器可适用于大于此的通道大小。事实上,大型通道可以提高系统的能效。这是因为在计算过程中,大型通道会导致更多的滤波器权重重用。例如,在扫描图像期间,100×100输入通道将导致大约10000倍的滤波器重用,10×10输入通道仅具有100倍的滤波器权重重用。
当输入通道或中间数据大小较大时,比总可用SRAM大小大。DMA控制器是需要在DRAM和片上SRAM之间交换数据。在DRAM和片上SRAM之间交换中间数据时,这将消耗大量能源。
该硬件加速器中的数据格式设置为16位定点,实现最低硬件成本。通过对CU模块中乘法器和加法器的重新设计,该体系结构可以用于其他数据格式,如16位浮点、32位浮点或8位定点。
表四是所设计加速器与现有加速器的比较其他报告的工作。如图所示,该加速器以较低的面积成本实现了高能效和可比性能,适合集成到物联网设备中。

七、结论
在本文中,提出了一种用于CNN硬件加速器。建议的加速器通过减少不必要的数据移动来优化能效。通过使用滤波器分解技术,支持任意窗口大小的卷积。通过集成单独的池模块和卷积引擎的适当配置,该加速器还支持池功能。加速器采用台积电65nm技术,核心尺寸为5mm2。使用该硬件IP实现了一个交通标志网,在FPGA上进行了验证。结果表明,该加速器可以支持最流行的CNN,实现434GOPS/W的能效,适合与物联网设备集成。
参考文献:
A Reconfigurable Streaming Deep Convolutional Neural Network Accelerator for Internet of Things