���ÿ���թ���
������һ�����ÿ�����¼,�ź��������ݾ�������������,ֻ֪��������,ȴ��֪��ÿһ���ֶδ���ʲô����,û��ϵ,�͵�����һ��������������
�����������������,�ֱ��������������ݺ��쳣 ��������,�ֶ�������ȷ�ı�ʶ����Ҫ����������ǽ������ع�ģ��,�Զ����������ݽ��з���,�������ƺ�������,��ʵ��Ӧ��ʱ����ָ�������ȴ������
��Ϥ����Ŀ���,��һ���뷨������ֱ�Ӱ����ݴ����㷨ģ����,�õ��������ͺ��ˡ���ʵ����������,�ڻ���ѧϰ��ģ������,Ҫ�������黹�Ǻܶ��,��������Ԥ������������ȡ��ģ�͵��ε�, ÿһ����������յĽ������Ӱ�졣��Ȼ���,��Ҫ������ÿһ��,���л��漰����ѧϰ�кܶ�ϸ��, ��Щ���Ƿdz���Ҫ��,����������ʵս�����漰��Щ����,���Դ��Ҳ������ݽ����������һ ����·��
1. ���ݷ�����Ԥ����
����������һ�����ÿ�����¼����,��һ��.csv�ļ�:

�������28���������,��ģ�ܴ�
1.1 ���ݵĶ�ȡ�����
�ճ��������������:
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
%matplotlib inline
��ʹ��Pandas���߰���ȡ����,��һ��ǰ������������:
data = pd.read_csv("creditcard.csv")
data.head()


ԭʼ����Ϊ���˽���¼,�����ݼ��ܹ���31��,��������������30��,Time����ʱ������,Amount�б�ʾ����Ľ��,Class�б�ʾ������,��ClassΪ0������������¼����,��Class Ϊ1���������쳣��
�õ�����һ��ԭʼ����֮��,ֱ�۸о����ܾ�����Ϊ�����Ѿ��Ǵ����õ�����,ֻ��Ҫ������н�ģ���ɡ�����,����������ֻչʾ��ǰ5������¼���ҷ���ȫ����������������,��ʵ���������ƺ���������Ҳռ�������,�쳣����ռһ�ٲ���,��ô,���������ݼ���,�����ֲ��Ƿ������?Ҳ����˵,��Class����,�������ݺ��쳣���ݵı����Ƕ���?
���ǻ���һ��ͼ����һ��:
count_classes = pd.value_counts(data['Class'], sort = True).sort_index()
count_classes.plot(kind = 'bar')
plt.title("Fraud class histogram")
plt.xlabel("Class")
plt.ylabel("Frequency")

�����������ȼ����Class���и���ָ��ĸ���,Ҳ����0��1�ֱ��ж��ٸ���Ϊ�˸�ֱ�۵���ʾ,���ݻ��Ƴ�����ͼ,����ͼ�п��Է���,�ƺ�ֻ��0û��1,˵�������о����������������,�쳣���ݼ��١�
�ǵ�����û��1���������?���Dz鿴һ��:


���Կ���,ʵ��������492��������ClassΪ1�����,492��������Ӵ��28��������,�������ǵ���״ͼ����������1����ͼ��
������⿴�����е��Ͼ�,���ݼ��Ȳ�ƽ���Խ�����ʲôӰ����?ģ�ͻ��һ�ߵ���?��Ϊ�������ݶ���������,��ȫ������Щ�쳣��,��Ϊ�쳣��������,����������ֵĿ����Ժܴ�
���ǵ�����Ŀ������ҵ��쳣����,���ģ�Ͳ������쳣����,�����û��������,����,����Ҫ���ľ��ǸĽ���ƽ�����ݡ��ڻ���ѧϰ������,�������ݺ�,����Ӧ���۲������Ƿ��������,�Ȱ��������,�ٿ���������ȡ�뽨ģ����
1.2 �������������
��ô,��ν�����ݱ�ǩ��ƽ��������?����,������ݱ�ǩ��ƽ����������ԭ��������ǵĸ����������,����������ǵĸ�������,���߱����ӽ�,�������ͽ���ˡ�
���ڴ�,����������ֽ��������
(1)�²�����
��Ȼ�쳣���ݱȽ���,�Ǿ��������������쳣����һ���١���������������30���, �쳣����ֻ��500��,�����������������ѡ��500��,���ǵı����;����ˡ�
��Ȼ�²����ķ������ƺܼ�,����Ҳ����覴�,��ʹԭʼ���ݺܷḻ,�²�������,ֻ����������һС����,�����Խ��� ����Ӱ����?
(2)��������
��������κ��м�ֵ������,ֻ�����쳣��������������һ����,��ô������?�쳣������ֻ��500��,��ʱ���Զ����ݽ��б任,�������һЩ�쳣����,��������Ҳ���ֽγ�����һ����·��
��Ȼ�������ɽ�����쳣��������������,�����쳣���ݱϾ����������,������������? �����ַ���������ȱ��,�������ַ���Ч��������?��Ҫ����ʵ��Ƚϡ�
�ڿ�ʼ��,Ӧ����������ֽ���ͶԱȷ���,�������Ȱ�ȫ�ֹ滮�ƶ�����,���ֻ�� ��һ����һ��,���������ظ��Բ���,����Ч�ʡ�
1.3 ��������
��Ȼ�Ѿ����˽������,�Dz���Ӧ�������ƶ��ļƻ�����ʼ��ģ������?ǧ����ļ�,����öಽ��,����Ҫ�����ݽ���Ԥ����,���ܴ�Ҿ��û���ѧϰ�ĺ��ľ��Ƕ����ݽ�ģ,��ʵ��ģֻ������һ ����,ͨ�������ʱ��;������������ݴ�����,����������ϴ��������ȡ��,��Щ������С��ϸ��, ����ʮ����Ҫ�ĺ������ݡ�Ŀ�Ķ���ʹ�����յĽ������,�����dz�˵:�����������������������,��ģ�͵ĵ���ֻ������νӽ�������ޡ���

�۲������������������Է���,Amount�е���ֵ�仯���Ⱥܴ�,��V1~V28�е��������ݵ���ֵ���Ƚ�С,�� ʱAmount�е���ֵ�����˵�Ƚϴ�������ʲôӰ����?ģ�Ͷ���ֵ��ʮ�����е�,�����������ܹ� ����ÿһ��ָ�����������,���ܻ���Ϊ��ֵ���������Ը���Ҫ(�˴����Ǽ���)��������������, ��û��ǿ��Amount�и���Ҫ,����Ӧ��ͬ�ȶԴ�����,�����Ҫ����һ�¡�
������������ϣ�����ݾ���������õ���ÿһ����������ֵ���ڽ�С��Χ�ڸ���,��ʽ����:
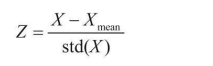
����,ZΪ�����������;XΪԭʼ����;XmeanΪԭʼ���ݵľ�ֵ;std(X)Ϊԭʼ���ݵı��
�������ʽ�Ĺ��̽��зֽ�,�ͻ�����������ˡ����Ƚ����ݵĸ���ά�ȼ�ȥ����Եľ�ֵ, �������ݾ�����ԭ��Ϊ���ĶԳơ�������ֵ�����ϴ������,�����Ҳ��Ȼ����;��ֵ������С������,�����Ҳ��Ƚ�С���ٽ�������Ը��Եı���,���൱���ô������ѹ������С�Ŀռ���,��С�������ܹ�����һЩ,������ͼ��ʾ�Ķ�ά����,�͵õ������֮��Ľ��,��ԭ��Ϊ����,����ά�ȵ�ȡֵ��Χ����һ�¡�

������,�ܶ����ݴ����ͻ���ѧϰ��ģ�����õ�sklearn���߰�,������������,�ù��߰��ṩ�˼������г��õĻ���ѧϰ�㷨,����һ���д���,������ɽ�ģ����,����Ҳ�Ƚϸ�Ч���������,���ṩ�˷dz��ḻ������Ԥ������������ȡģ��,�����ҿ������ִ�����������������Python�зdz�ʵ�õĻ���ѧϰ��ģ���߰�,�ں�����ʵս������,�������������Ӱ��

sklearn���߰��ṩ���ڻ���ѧϰ������ĵ�����ģ��(Classification��Regression��Clustering)��ʵ�ַ�������ҵ���,���������ݽ�ά(Dimensionality reduction)��ģ��ѡ��(Model selection)������Ԥ����(Preprocessing)��ģ��,����ʮ�ַḻ��
sklearn���߰����ṩ�˺ܶ�ʵ��Ӧ�õ�����,����������Ӧ�Ĵ�������ӻ�չʾ����,��ֱ����һ ��������,�dz��ʺϴ��ѧϰ������,����ͼ��ʾ:


sklearn��õ�����API�ĵ�,����ͼ��ʾ,����ִ�н�ģ����Ԥ��������,��������Ϥ�亯��������ʹ�á�

�ҽ�����ʹ��sklearn���߰������������������,
��������:
from sklearn.preprocessing import StandardScaler
data['normAmount'] = StandardScaler().fit_transform(data['Amount'].values.reshape(-1, 1))
data = data.drop(['Time','Amount'],axis=1)
data.head()

��������ʹ�� StandardScaler���������ݽ��б�������,����ʱ���ȵ����ģ��,Ȼ����� fit_transform����,�൱��ִ�й�ʽ
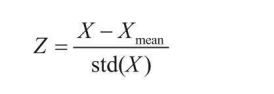
reshape(?1,1)�ĺ����ǽ���������ת����һ�е���ʽ(�谴�պ�������Ҫ����)�������drop����ȥ�����������������������е�normAmount�о��DZ���������Ľ��,�ɼ���ֵ���ڽ�С��Χ�ڸ�����
����Ԥ�������̷dz���Ҫ,�������������Ҫ���������ݽ��б�������(��������Ԥ��������,���һ����)��
2. �²�������
�²���������ʵ�ֹ��̱Ƚϼ�,ֻ��Ҫ�������������в���,�õ����쳣����һ����ĸ�������,��������:
X = data.iloc[:, data.columns != 'Class']
y = data.iloc[:, data.columns == 'Class']
# �õ������쳣����������
number_records_fraud = len(data[data.Class == 1])
fraud_indices = np.array(data[data.Class == 1].index)
# �õ�������������������
normal_indices = data[data.Class == 0].index
# ���������������������ָ������������,��ȡ������
random_normal_indices = np.random.choice(normal_indices, number_records_fraud, replace = False)
random_normal_indices = np.array(random_normal_indices)
# �����������쳣����������ǵ��������õ���
under_sample_indices = np.concatenate([fraud_indices,random_normal_indices])
# ���������õ��²�������������
under_sample_data = data.iloc[under_sample_indices,:]
X_undersample = under_sample_data.iloc[:, under_sample_data.columns != 'Class']
y_undersample = under_sample_data.iloc[:, under_sample_data.columns == 'Class']
# �²��� ��������
print("����������ռ�������: ", len(under_sample_data[under_sample_data.Class == 0])/len(under_sample_data))
print("�쳣������ռ�������: ", len(under_sample_data[under_sample_data.Class == 1])/len(under_sample_data))
print("�²�������������������: ", len(under_sample_data))
������:

�������̱Ƚϼ�,���ȼ����쳣�����ĸ�����ȡ������,���������������������ѡ��ָ����������,����������������ƴ����һ�ɡ�������������ʾ,ִ���²���������,һ����984������,���������������쳣������ռ50%,��ʱ��������ƽ�����
2.1 ������֤
�õ��������ݺ�,�������������ݼ�,�ڻ���ѧϰ��,ʹ��ѵ������ɽ�ģ��,����֪�����ģ�͵�Ч��,Ҳ������Ҫһ�����Լ�,�������ģ�Ͳ��Թ������������,������ģ��ѵ��������,Ҳ���漰һЩ��������,����,����Ҫ��֤��,����ģ�ͽ��в����ĵ�����ѡ��
ͻȻ���ֺܶ��ּ���,�о�������Ū��,�����ܽ�һ��:

���Ȱ����ݷֳ�������,�����ѵ����,�ұ��Dz��Լ�,����ͼ��ʾ��ѵ�������ڽ���ģ��,�������ݶ��½��������Ż�,������Ҫ�����ݾ�����ѵ�����ṩ�ġ����Լ��ǵ����н�ģ��������ɺ�ʹ�õ�,��Ҫǿ��һ��,���Լ�ʮ�ֱ���,�ڽ�ģ�Ĺ�����,���ܼ����κ�����Լ��йص���Ϣ,������൱����,��������Ͳ���ȷ�������Լ��趨ѵ�����Ͳ��Լ��Ĵ�С�ͱ���,8�U2��9�U1���dz������зֱ�����
��������Ҫ�����ݼ��ٽ��д���,����ͼ��ʾ,���Է��ֲ��Լ�û���κα仯,����ѵ�������ֳɺܶ�ݡ���������Ŀ������,��ģ���Թ�����,��Ҫ�������ֿ���Ӱ�����IJ���,�����Ҫ֪��ÿһ �ֲ���������Ч��,�������ﲻ���ò��Լ�,��Ϊ��ģ����û��ȫ�����,������֤�������ڽ�ģ���������������õ�,��ô������ѵ�������ҳ���һ������֤��(����fold5)���Ϳ�������,ΪʲôҪ���ֳ�����ô��С����?

�����ʵս������,�漰�dz����ϸ��֪ʶ��,��Щ֪ʶ����ͨ�õ�,�κ�ʵս������ �ϡ����ֻ�ǵ����ҳ���һ��,ǡ����һ�����ݱȽϼ�,��ô���յĽ�����ܻ�ƫ��;���ѡ��������һ��������һЩ����������Ⱥ��,�õ��Ľ�����ܾͻ�ƫ�͡������������,��������������һ ��ƫ�Ϊ�˽���������,����ѵ�����зֳɶ��,���罫ѵ�����ֳ�10��,����ͼ��ʾ:
����֤ijһ �ν��ʱ,��Ҫ���������̷ֳ�10��,��һ����ǰ9�ݵ���ѵ����,���һ�ݵ�����֤��,�õ�һ�����,�Դ�����,ÿ�ζ�����������һ�ݵ�����֤��,�������ֵ���ѵ��������������10��֮��,�͵õ� 10�����,ÿ������ֱ��Ӧ����ÿһС��,�����һ��ǡ�ð���ԭʼѵ��������������,�ٶ����յ� ����10���������ƽ��,�͵õ�����ģ�������Ľ����������̾ͽ���������֤��
������֤��������Щ����,�����ܶ�ģ�ͽ��и��õ�����,ʹ�ý����ȷ,�Ӻ�����ʵ����,��һᷢ��,�ò�ͬ��֤��������ʱ��,�������ܴ�,���������·�DZ���Ҫ���ġ�
��sklearn���߰� ��,�Ѿ�ʵ�ֺ����ݼ��зֵĹ���,�������Ƚ����ݼ����ֳ�ѵ�����Ͳ��Լ�,�з���֤���Ĺ����ȵ���ģ��ʱ������Ҳ���ü�,��������:
#from sklearn.cross_validation import train_test_split
# ��sklearn 0.18�����ϵİ汾��,cross_validation���Ѿ���������
from sklearn.model_selection import train_test_split
# �������ݼ����л���
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size = 0.3, random_state = 0)
print("ԭʼѵ����������������: ", len(X_train))
print("ԭʼ���Լ�������������: ", len(X_test))
print("ԭʼ��������: ", len(X_train)+len(X_test))
# �²������ݼ����л���
X_train_undersample, X_test_undersample, y_train_undersample, y_test_undersample = train_test_split(X_undersample
,y_undersample
,test_size = 0.3
,random_state = 0)
print("")
print("�²���ѵ����������������: ", len(X_train_undersample))
print("�²������Լ�������������: ", len(X_test_undersample))
print("�²�����������: ", len(X_train_undersample)+len(X_test_undersample))
����������:

ͨ�����������Է���,���з����ݼ�ʱ����������:���ȶ�ԭʼ���ݼ����л���,Ȼ����²������ݼ����л��֡����������Ŀ�겻��Ҫ���²������ݼ���ģ��,Ϊʲô�ֶ�ԭʼ���ݽ����зֲ�����?��������һ������,����������������
2.2 ģ����������
��������û��ʵ�ʽ�ģ����,����Ҫ����ģ�͵���������,Ϊʲô��ģ֮ǰҪ��������������?��Ϊ��ģ��һ������,��Ҫ���ȿ�������������ֵ,�����ǽ����ṩһ��ģ�Ͳ���ֵ��
ȷ���Ƿ����������ʹ�õ�һ������,����˵���������������˶��١������һ����������ݼ����Ƶ�����:ҽԺ����1000������,����10������,990��û�л���,��Ҫ����һ��ģ�����������ǡ� ����ģ����Ϊ���˶�û�л���,ֻ��10���˷����д�,��˵õ���ȷ�ʸߴ�990/1000,Ҳ����0.99,��������ʮ�ֲ����Ľ�������ǽ�ģ��Ŀ�����ҳ����а�֢�IJ���,��ʹһ����û�ҵ�,ȷ��Ҳ�ܸߡ� ��˵�����ڲ�ͬ������,��Ҫָ���ض���������,��Ϊ��ͬ����������������dz���IJ��졣
ѡ����ʵ����������dz���Ҫ,��Ϊ����������Ϊ����ʵ���ṩ���ߵķ����,����һ�� Ҫ����ʵ�����������ݼ�����ѡ��
�����������,��֢������ǰ�֢������������ʮ�ֲ�����,��ô,����ν�ģ��?��Ȼ�Ѿ���ȷ��ģ��Ŀ����Ϊ�˼���֢����(�쳣����),Ӧ���ѹ�ע�������������,���Կ���ģ�����쳣�����м����ٸ�����������������˵,һ����֢���˶�û��,��ζ���ٻ���(Recall)Ϊ0��
�����ᵽ���ٻ���,��ͨ������һ��:���ǹ۲����Ŀ��,������Ŀ��ͳ����ȡ���˶��ɼ�,���������������ԡ� ���ֱ�Ӹ������㹫ʽ,�������������е����,������������һ���ڻ���ѧϰ�Լ����ݿ�ѧ�����г��õ�����,��������Щ����,�ͺ�����������Щ���������� ���滹����һ������������,����ij���༶������80��,Ů��20��,����100��,Ŀ�����ҳ�����Ů��������ij��ʵ����ѡ��50����,����20����Ů��,�������ذ�30������Ҳ����Ů����ѡ����(�����Ů����������,������������)��
�±��г���TP��TN��FP��FN�ĸ��ؼ��ʵĽ���,������ߴ��һ������,����Ҫ����Ӳ��,�Ӵʱ������˼��Ҳ������������:

(1)TP
����,��һ������True,��ͱ���ģ��Ԥ������ȷ,�ٿ�Positive,ָԤ�������,�� ����һ���������ģ��Ԥ����ȷ,��������Ԥ�������������������Ŀ,ѡ������50������20����Ů ��,��ôTPֵ����20,��20��Ů��������Ů��ѡ������
(2)FP
FP����ģ��Ԥ��������,���ұ�����Positive(Ҳ��������)������Ŀ��,���Ǵ����� ������Ů��ѡ������������Ŀ����ѡŮ��,ѡ������50������30��ȴ���е�,���FP����30��
(3)FN
ͬ��,����Ԥ��������,���ұ���������,Ҳ���ǰ�Ů������������ѡ����,���в�û���������,����FN����0��
(4)TN
Ԥ������ȷ,���Ѹ�����������,��������������ѡ����,������100��,ѡ����Ϊ��Ů����50��,ʣ�µľ���������,����TN����50��
�������������г�����4��ָ��ֻ��Ҫ�����京�弴�ɡ�����������ͨ����4��ָ���ܵó�ʲô�� �ۡ�
?ȷ��(Accuracy):��ʾ�ڷ���������,���Ե�ռ����İٷֱȡ�
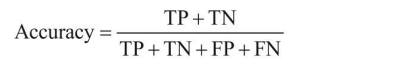
?�ٻ���(Recall):��ʾ���������ж�����Ԥ�,������Ĵ�С��
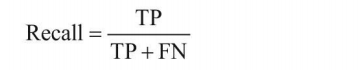
?��ȷ��(Precision):��ʾ����Ϊ������ʵ��Ϊ�����ı�����

���������3�ֱȽϳ���������ָ��,����ص����ÿ���������,��һ������ݼ��������,Ӧ��ʹ����һ������ָ����?����Ŀ���Dz鿴�ж����쳣�����ܱ�������,����Ӧ��ʹ���ٻ��ʽ���ģ��������
2.3 ���ͷ�
���ͷ�,������ֿ������е��Ť,�úõ�ģ��ΪʲôҪ�ͷ���?

��������һ �¹���ϵĺ���,��ģ�ij�������Ǿ����ܶ��������������,��ͼ(a)��ֱ�߿������е��,û�����������������,�����������Ƿ���,����ԭ��,��������ģ�ͱ������ڼ������¡�������ͼ(b),��ͼ(a)��ʾģ��������Щ,������������������,����һ���Ƚϲ�����ģ�͡�����ͨ���۲���Է���,����û��ץס����������,��ֻ��һ����������,��ô����ܰ�ģ�����ø�����,���Ǹ���?������ͼ(c),����һ���dz����ӵĻع�ģ��,��Ȼ�����������㶼ץ�� ��,���˵ĵ�һ�о���ģ��ʮ��ǿ��,����Ҳ�����һ�����⡪ģ������ѵ�����ϵõ���,���Լ���ѵ ����ȴ����ȫһ��,һ�����в���,Ч�����ܲ��������⡣
�ڻ���ѧϰ��,ͨ���������ü�ģ�ͽ��г���,����ﲻ��Ҫ��,��������һ���,������������ӵ�ģ������,��Ȼѵ������ȷ�ȿ��Դﵽ99%��������,����ʵ��Ӧ�õ�Ч��ȴ�ܲ�,����ǹ���ϡ�
�����ڻ���ѧϰ�����о������������������,����������������ģ���ӳ̶ȵ�����,ѵ����Ч��Խ��Խ��,���Dz��Լ�Ч������Խ��Խ��,����ͼ��ʾ:

����ͬһ�㷨��˵,ģ�͵ĸ��ӳ̶���˭��������?��Ȼ��������Ҫ���IJ���(�����ݶ��½����Ż��IJ���),�����ѵ�����ϵõ��IJ���ֵ���ߺ���,�ͺܿ��ܵ��¹����,�������ͷ�����Ϊ������������,���ͷ���ֵ�ϴ��Ȩ�ز���,�����ǶԽ����Ӱ��Сһ�㡣
���Ǿ�һ������������������,������һ������������x:[1,1,1,1],����������ģ��:
?��1:[1,0,0,0]
?��2:[0.25,0.25,0.25,0.25]
���Է���,ģ�Ͳ�����1����2������x���֮��Ľ����Ϊ1(Ҳ���Ƕ�Ӧλ�������͵Ľ��)�����Dz�����ζ������ģ�͵�Ч����ͬ��?�ٹ۲췢��,���������������źܴ�IJ���,��1ֻ�е�һ��λ����ֵ,�൱��ֻע�������е�һ������,����������ȫ������;����2��ͬ�ȶԴ������е�������������Ȼ ���ǵĽ����ͬ,����,����ô����ѡ��,��Ŷ���ѡ��ڶ���,��Ϊ���ȽϾ���,û����ô���ԡ�
��ʵ�ʽ�ģ��,ͨ��Ҫѡ��������ǿ��Ҳ���Ƕ������ȶ���Ȩ�ز�������ô��ΰѿز�����?��ʱ����Ҫһ���ͷ���,�ͷ������Ŀ�꺯������� һ��,��ģ���ڵ��������оͿ�ʼ�����������,�����ǽ�ģ��ɺ���������,��������L1��L2���ͷ���:
-
L1����:
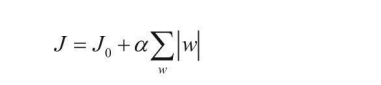
-
L2����:
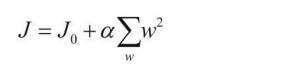
�������ͷ���������Ȩ�ز��������˴���,��Ȼ�ӵ�Ŀ�꺯����,Ŀ�ľ��Dz��ø���Ȩ��̫��,���¶Ծֲ������ϴ�Ӱ��,Ҳ���ǹ���ϵĽ������L1�����п��Զ�|w|���ۼӺ�,����ֱֻ�Ӽ������ֵ���ۼӺ͵Ļ�,�������������Ц�1�ͦ�2�Ľ����Ȼ��ͬ,������1,��û���������֡���ʱ��L2 ���͵dz���,���ijͷ����ȸ���,��Ȩ�ز�����ƽ����,Ŀ�ľ����ô�ĸ���,��Գͷ�Ҳ���ࡣ ��1��L2�ͷ�Ϊ1,��2��L2�ͷ�ֻ��0.25,������1��������ʧ����,��ģ��Ч��һ�µ�ǰ����,��Ȼѡ������Ч�����ŵĦ�2��ģ�͡�
�ڳͷ����ǰ�滹��һ����ϵ��,����ʾ���ͷ������ȡ���һ�ּ����������˵��:�����ֵ�Ƚϴ�,��ζ��Ҫ�dz��ϸ�ضԴ�Ȩ�ز���,��ʱ���ͷ��Ľ���������Ŀ�꺯�������ϴ�Ӱ�졣�����ֵ��С,��ζ�ųͷ������Ƚ�С,����Խ������̫��Ӱ�졣
���ս���Ķ������ɲ��Լ�������,ѵ�����ϵ�Ч�������ο�,��Ϊ���������ʮ�ֳ�����
3. ���ع�ģ��
����ǧ�����,�������ڵ���ģ��ʱ����,������Ҫ�����濼�ǵ��������ݶ������һ��,���ù��߰�����һ������ģ�;ͷdz���,�ѵ����������õ����ŵĽ��,����ÿһ���ڶ���Խ��������ͬ��Ӱ�졣
3.1 �����Խ����Ӱ��
�����ع��㷨��,�漰�IJ����Ƚ���,����������ͷ����Ƚ��е���ʵ��,Ϊ�˶Աȷ���������֤��Ч��,�Բ�ͬ��֤���ֱ���н�ģ����������,��������:
#Recall = TP/(TP+FN)
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import KFold, cross_val_score
from sklearn.metrics import confusion_matrix,recall_score,classification_report
from sklearn.model_selection import cross_val_predict
def printing_Kfold_scores(x_train_data,y_train_data):
fold = KFold(5,shuffle=False)
# ���岻ͬ���ȵ����ͷ�����
c_param_range = [0.01,0.1,1,10,100]
# չʾ����õı���
results_table = pd.DataFrame(index = range(len(c_param_range),2), columns = ['C_parameter','Mean recall score'])
results_table['C_parameter'] = c_param_range
# k-fold ��ʾK�۵Ľ�����֤,�����õ�������������: ѵ���� = indices[0], ��֤�� = indices[1]
j = 0
#ѭ��������ͬ�IJ���
for c_param in c_param_range:
print('-------------------------------------------')
print('���ͷ�����: ', c_param)
print('-------------------------------------------')
print('')
recall_accs = []
#һ�����ֽ���ִ�н�����֤
for iteration, indices in enumerate(fold.split(y_train_data),start=1):
# ָ���㷨ģ��,���Ҹ�������
lr = LogisticRegression(C = c_param, penalty = 'l1',solver='liblinear')
# ѵ��ģ��,ע��������Ҫ������,ѵ����ʱ��һ���������ѵ����,����X��Y����������0
lr.fit(x_train_data.iloc[indices[0],:],y_train_data.iloc[indices[0],:].values.ravel())
# ������ģ�ͺ�,Ԥ��ģ�ͽ��,�����õľ�����֤��,����Ϊ1
y_pred_undersample = lr.predict(x_train_data.iloc[indices[1],:].values)
# ����Ԥ����֮��Ϳ���������������,����recall_score��Ҫ����Ԥ��ֵ����ʵֵ��
recall_acc = recall_score(y_train_data.iloc[indices[1],:].values,y_pred_undersample)
# һ�ỹҪ��ƽ��,����ÿһ���Ľ�����ȱ���������
recall_accs.append(recall_acc)
print('Iteration ', iteration,': �ٻ��� = ', recall_acc)
# ��ִ�������еĽ�����֤��,����ƽ�����
results_table.loc[j,'Mean recall score'] = np.mean(recall_accs)
j += 1
print('')
print('ƽ���ٻ��� ', np.mean(recall_accs))
print('')
#�ҵ���õIJ���,��һ��Recall��,��Ȼ������õ��ˡ�
best_c = results_table.loc[results_table['Mean recall score'].astype('float32').idxmax()]['C_parameter']
# ��ӡ��õĽ��
print('*********************************************************************************')
print('Ч����õ�ģ����ѡ���� = ', best_c)
print('*********************************************************************************')
return best_c
����������,KFold����ѡ����֤������,����ѡ��5��,����ѵ����ƽ���ֳ�5�ݡ�c_param�� ���ͷ�������,Ҳ�������ͷ���ʽ�е�a��Ϊ�˹۲첻ͬ�ͷ����ȶԽ����Ӱ��,�ڽ�ģ��ʱ ��,Ƕ������forѭ��,����ѡ��ͬ�ijͷ����Ȳ���,Ȼ�����ÿһ������������5�۵Ľ�����֤,���õ�����֤�����ٻ��ʽ����
��sklearn���߰���,�����㷨�Ľ�ģ���÷����������Ƶ�,����ѡ����Ҫ���㷨ģ��,Ȼ��.fit()����ʵ�����ݽ��е���,�����.predict()����Ԥ�⡣
�������ݿ�һ��Ч��:
best_c = printing_Kfold_scores(X_train_undersample,y_train_undersample)
������:


�������������ͷ�������CΪ0.01ʱ,ͨ��������֤�ֱ�õ�5 ��ʵ����,���Է���,��������ͬ�����������,������֤����IJ��컹�Ǻܴ�,��ֵ��0.93~1.0֮�両��,����ǧ���С���⼸���ٷֵ�,��ģ����Χ����һ����С���������Ż���,���Խ�����֤�dz��б�Ҫ��
��sklearn���߰���,C���������������ǵ�������,����C=0.01��ʾ�������ȱȽϴ�,��C=100�� ��ʾ���ȱȽ�С���������е�������,����Ȼ���߰�����������,���Ǿ�����������,����һ��Ҫ�ο���API�ĵ�:

�����Աȷ�����ͬ�����õ��Ľ��,ֱ�ӹ۲콻����֤����ƽ���ٻ���ֵ�Ϳ���,��ͬ�������� ����,�õ��Ľ��������ͬ,���컹�Ǵ��ڵ�,�����ڽ�ģ��ʱ����αز�����,���ܴ�Ҷ�����Ӧ�� ���վ���ֵȥ��,�������ʱ����ֵֻ���ṩһ�����µķ���,�����̽������ͨ��������ʵ��� �з�����
�����Ѿ���ɽ�ģ�ͻ����ĵ�������,ֻ�����90%���ҵĽ��,�о�������,���������֪��ģ �͵ľ������,��Ҫ�����������
3.2 ��������
Ԥ������ȷ֮��,�����Ը�ֱ�۵ؽ���չʾ,��ʱ���������������ó��ˡ�

�����������õ���ָ��ֵǰ���Ѿ�����,��Ȼ�Ѿ�ѵ����ģ��,�Ϳ���չʾ����,�����õ� Matplotlib���߰�,��ҿ�������Ĵ��뵱��һ����������ģ��,�õ�ʱ��ֻ�贫���Լ������ݼ���:
def plot_confusion_matrix(cm, classes,
title='Confusion matrix',
cmap=plt.cm.Blues):
"""
���ƻ�������
"""
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=0)
plt.yticks(tick_marks, classes)
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, cm[i, j],
horizontalalignment="center",
color="white" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
����û�������Ļ���֮��,��Ҫ����ʵ��Ԥ����,����֮ǰ�����ع�ģ��,�õ����Խ��, �ٰ����ݵ���ʵ��ǩֵ����ȥ����:
import itertools
lr = LogisticRegression(C = best_c, penalty = 'l1',solver='liblinear')
lr.fit(X_train_undersample,y_train_undersample.values.ravel())
y_pred_undersample = lr.predict(X_test_undersample.values)
# ��������ֵ
cnf_matrix = confusion_matrix(y_test_undersample,y_pred_undersample)
np.set_printoptions(precision=2)
print("�ٻ���: ", cnf_matrix[1,1]/(cnf_matrix[1,0]+cnf_matrix[1,1]))
# ����
class_names = [0,1]
plt.figure()
plot_confusion_matrix(cnf_matrix
, classes=class_names
, title='Confusion matrix')
plt.show()
������:

��������ݼ���,Ŀ�������Ƕ�����,����ֻ��0��1,���Խ����ϵ�ֵ����Ԥ��ֵ����ʵֵһ�µ����,��ɫ�������ģ��Ԥ����ȷ(��ʵֵ��Ԥ��ֵһ��),����λ�ô���Ԥ�������ֵ10������10 ���������ݱ������쳣��,ģ��ȴ����Ԥ���Ϊ����,�൱�ڡ�©�족����ֵ12������12���������ݱ�����������,ȴ���������쳣��ʶ�����,�൱�ڡ���ɱ����
���յõ����ٻ���ֵԼΪ0.9319,��������һ����������ָ��,���ǻ���û��������?���²��������ݼ����н�ģ,���Ҳ��Լ�Ҳ���²����IJ��Լ�,����ݲ��Լ���,�쳣���������������ı�����������,��Ϊ�Ѿ������ݼ����й�����������ʵ�ʵ����ݼ�������������,�൱���ڲ���ʱ�����������������ʵ���,�����ļ��Ч�����ܻ�ƫ��,����ֵ��ע�����,�ڲ��Ե�ʱ��,��Ҫʹ��ԭʼ���ݵIJ��Լ�,������ߴ�����,ֻ��Ҫ�ı䴫��IJ������ݼ���,��������:
lr = LogisticRegression(C = best_c, penalty = 'l1',solver='liblinear')
lr.fit(X_train_undersample,y_train_undersample.values.ravel())
y_pred = lr.predict(X_test.values)
# ��������ֵ
cnf_matrix = confusion_matrix(y_test,y_pred)
np.set_printoptions(precision=2)
print("�ٻ���: ", cnf_matrix[1,1]/(cnf_matrix[1,0]+cnf_matrix[1,1]))
# ����
class_names = [0,1]
plt.figure()
plot_confusion_matrix(cnf_matrix
, classes=class_names
, title='Confusion matrix')
plt.show()
������:

���ǵ����з����ݼ���ʱ��,����������������?�������²������ݼ������з�,���Ҷ�ԭʼ���ݼ�Ҳ�������з֡���ʱ��������ó���,�õ����ٻ���ֵΪ0.925,��Ȼ�����½�,����������˵���ǿ��Եġ�
��ʵ�ʵIJ�����,������Ҫ������������,��Ҫע��ʵ��Ӧ�����,���������������,�������� ��Щʵ�����⡣��ͼ�����½ǵ���ֵΪ13,������û������,˵����13��©��ġ�����,���Ͻ���һ�����ָ������ۡ���9145,��ζ����9145����������ɱ������֮ǰ���²������ݼ����в��Ե�ʱ��û��ע���һ��,��Ϊֻ��20����������ɱ������,��ʵ�ʵIJ��Լ���ȴ��������������:�������Լ�һ��ֻ��100����쳣����,ģ��ȴ��ɱ��9145��,�е������,����ʵ��ҵ������,�����϶�Ҫ�Լ��������쳣������һЩ����,���綳���˺š��绰ѯ�ʵ�,�����ɱ����ô������,ʵ��ҵ��Ҳ��������⡣
�ڲ����л����ۺϿ���,����Ҫ��ģ�;����ָ��ֵ(�����ٻ��ʡ����ȵ�),����Ҫ��ʵ������Ƕ�����ģ�͵��ɲ���ȡ�� �����Ѿ����Ͼ�,ģ�����ڳ����˴�����,����θĽ���?�Ƕ�ģ�͵�������,�����Ż��㷨��? ���������ݲ�����һЩ������?һ�������,�������ȴ���������,��Ϊ���������任Ҫ���Ż��㷨ģ������,�õ���Ч��Ҳ��ͻ������Ҫ����֮ǰ��������ַ���,���ҹ�����������û�г���,��ᷢ��һЩ�仯��?������������𰸡�
3.3 ������ֵ�Խ����Ӱ��
����һ�����ع��㷨ԭ��,ͨ��Sigmoid�������÷�ֵת���ɸ���ֵ,��ô,��ô�õ�����ķ�������?Ĭ�������,ģ�Ͷ�����0.5Ϊ�������������:
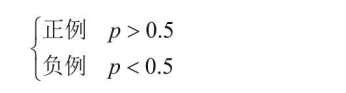
����˵0.5��һ������ֵ,���Dz����ǹ̶������,ʵ��ʱ���Ը����Լ��ı���ָ������ֵ��С�� �����ֵ���õô�һЩ,�൱��Ҫ�����ϸ�,ֻ�зdz��쳣���������ܵ����쳣;�����ֵ���õñȽ�С,�൱�����ϴ�ɱҲ���ϷŹ�,ֻҪ��һ���쳣��ͨͨץ������
��sklearn���߰��мȿ�����.predict()�����õ�������,�൱����0.5ΪĬ����ֵ,Ҳ���� ��.predict_proba()�����õ������ֵ,������������жϡ�
���ǿ����ȿ�һ������������ݽ��д���,��ԭʼ����ֱ�ӽ�ģ���:
lr = LogisticRegression(C = best_c, penalty = 'l1',solver='liblinear')
lr.fit(X_train,y_train.values.ravel())
y_pred_undersample = lr.predict(X_test.values)
# Compute confusion matrix
cnf_matrix = confusion_matrix(y_test,y_pred_undersample)
np.set_printoptions(precision=2)
print("Recall metric in the testing dataset: ", cnf_matrix[1,1]/(cnf_matrix[1,0]+cnf_matrix[1,1]))
# Plot non-normalized confusion matrix
class_names = [0,1]
plt.figure()
plot_confusion_matrix(cnf_matrix
, classes=class_names
, title='Confusion matrix')
plt.show()
���:

�ٻ���ƫ��,�����Ȼ��������֮ǰ���²������ݴ���Ч���á�
�ٿ�һ����ֵ�Խ����Ӱ��:
# ��֮ǰ��õIJ��������н�ģ
lr = LogisticRegression(C = 0.01, penalty = 'l1',solver='liblinear')
# ѵ��ģ��,�������²��������ݼ�
lr.fit(X_train_undersample,y_train_undersample.values.ravel())
# �õ�Ԥ�����ĸ���ֵ
y_pred_undersample_proba = lr.predict_proba(X_test_undersample.values)
#ָ����ͬ����ֵ
thresholds = [0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9]
plt.figure(figsize=(10,10))
j = 1
# �û�������������չʾ
for i in thresholds:
y_test_predictions_high_recall = y_pred_undersample_proba[:,1] > i
plt.subplot(3,3,j)
j += 1
cnf_matrix = confusion_matrix(y_test_undersample,y_test_predictions_high_recall)
np.set_printoptions(precision=2)
print("������ֵΪ:",i,"ʱ���Լ��ٻ���: ", cnf_matrix[1,1]/(cnf_matrix[1,0]+cnf_matrix[1,1]))
class_names = [0,1]
plot_confusion_matrix(cnf_matrix
, classes=class_names
, title='Threshold >= %s'%i)
������:


����������0.1~0.9�����ֵ,����ȷ��ÿһ�ν�ģ��ʹ����ͬ�IJ���,���õ��ĸ���ֵ�������ֵ���бȽ�����ɷ������� ���ڹ۲�һ��������,����ֵ�Ƚ�С��ʱ��,���Է����ٻ���ָ��dz���,��һ����ͼ��Ȼ�����������������쳣��,������ɱ��Ҳ�Ǻܸߵ�,ʵ�����岢����������ֵ������,�ٻ������½�, Ҳ����©���������,����ɱ����������,��������������ֵ�����м䷶Χʱ,������������ȱ��,����ֵ����0.5ʱ,�ٻ���ƫ��,������ɱ�����������е�ࡣ����ֵ����0.6ʱ,�ٻ��������½�, ������ɱ�����������Լ��١���ô,����ѡ����һ����ֵ�ȽϺ�����?�����Ҫ��ʵ��ҵ��ĽǶȳ���,��һ��ʵ��������,������Ҫģ��������һ������
4. ����������
���²���������,��Ȼ�õ��ϸߵ��ٻ���,������ɱ����������ʵ��̫����,������������ù����������ܷ���������⡣
4.1 SMOTE�㷨�������ɲ���
��β������쳣��������������һ������?������Ҫ������������������,��ɲ��Ǹ���ճ��,һ ģһ����������û���õ�,��Ҫ����һЩ����,��õľ���SMOTE�㷨(����ͼ),

����������:
�ڢٲ�:������������ÿһ������x,��ŷʽ����Ϊ��,�������������������������������ľ���,��������,�õ������������
�ڢڲ�:����������ƽ���������һ����������N,����ÿһ����������x,������ڿ�ʼ����ѡ��N ��������
�ڢ۲�:����ÿһ��ѡ���Ľ�������,�ֱ���ԭ�����������µĹ�ʽ�����µ��������ݡ�
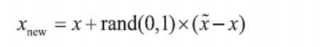
�ܽ�һ��:����ÿһ���쳣����,�����ҵ����������ͬ������,Ȼ��������֮��ľ�����,ȡ0~1�е�һ�����С����Ϊ����,�ټӵ�ԭʼ���ݵ���,�͵õ��µ��쳣������
����SMOTE�㷨,����ʹ ��imblearn���߰�����������,������Ҫ��װ�ù��߰�,����ֱ������������ʹ��pip install imblearn����conda install -c glemaitre imbalanced-learn��ɰ�װ������(��ܰ��ʾ:��װ��ɺ�,�������һ��,����!����!����!!!��Ȼ���ܻ��д��,�Ҿ����˸��ָ���������˼���Сʱ,���������װ��anaconda,��ɱ��,����̫���ˡ�����)���ٰ�SMOTE�㷨���ؽ���,ֻ��Ҫ���������ݺͱ�ǩ����ȥ,�������͵õ�20W+���쳣����,��ɹ�����������
4.2 ������Ӧ��Ч��
������������Ч������������?ͬ��ʹ�����ع��㷨��������
import pandas as pd
from imblearn.over_sampling import SMOTE
from sklearn.metrics import confusion_matrix
from sklearn.model_selection import train_test_split
credit_cards=pd.read_csv('creditcard.csv')
columns=credit_cards.columns
# ��������ȥ������ǩ
features_columns=columns.delete(len(columns)-1)
features=credit_cards[features_columns]
labels=credit_cards['Class']
features_train, features_test, labels_train, labels_test = train_test_split(features,
labels,
test_size=0.3,
random_state=0)
����SMOTE�㷨��������������,������������������������һ�µ���
oversampler=SMOTE(random_state=0)
os_features,os_labels=oversampler.fit_resample(features_train,labels_train)
ѵ������������:

os_features = pd.DataFrame(os_features)
os_labels = pd.DataFrame(os_labels)
best_c = printing_Kfold_scores(os_features,os_labels)


��ѵ�����ϵ�Ч��������,������������Խ���Ļ�������:
lr = LogisticRegression(C = best_c, penalty = 'l1',solver='liblinear')
lr.fit(os_features,os_labels.values.ravel())
y_pred = lr.predict(features_test.values)
# �����������
cnf_matrix = confusion_matrix(labels_test,y_pred)
np.set_printoptions(precision=2)
print("�ٻ���: ", cnf_matrix[1,1]/(cnf_matrix[1,0]+cnf_matrix[1,1]))
# ����
class_names = [0,1]
plt.figure()
plot_confusion_matrix(cnf_matrix
, classes=class_names
, title='Confusion matrix')
plt.show()
������:

�õ����ٻ���ֵ��֮ǰ���²���������������½�,�Ͼ����쳣�����кܶ�Ǽ�ð��,��������ʵ������������ֵ����ο����,���ģ�͵���ɱ��������½�,ԭ����ɱ����ռ�����в���������10%����,����ֻռ����1%,ʵ��Ӧ��Ч���кܴ�������
�����Աȿ������Է���,������������Ч�������²���(��������ʵ��Ӧ��Ч���������),��Ϊ�����õ�������Ϣ����,ʹ��ģ������ʵ�ʵ�����������,���ڲ�ͬ������������Դ��˵,��û��һ�ɲ���Ĵ�,�κν������Ҫͨ��ʵ��֤��,���Ե������������ʱ,��õĽ��������ͨ������ʵ����з�����
�ܽ�
- ��������֮ǰһ��Ҫ�������,����������ʲô���⡣�ڴ���Ŀ��,ͨ�������ݽ��й۲�,�������������������������,�����Щ����,����ѡ����������
- �������������ַ���:�²�����������ͨ������·�߽��жԱ�ʵ��,�κ�ʵ��������ֺ�,ͨ�������ȵõ�һ������ģ��,Ȼ��Ը��ַ������жԱ�,�ҵ�����ʵ�,����������ʼ֮ǰ,һ��Ҫ�ද�Խ�,��������,�õ��Ľ�����п�ѡ�����ء�
- �ڽ�ģ֮ǰ,��Ҫ�����ݽ��и���Ԥ��������,�������ݱ�����ȱʧֵ����,��Щ���DZ�Ҫ��,�������ݱ����Ѿ���������,�˴���û���漰���������������,����ʵս�л�������,��ʵ����Ԥ�����������������������ء�����һ��������,���ݴ����úû��Խ����Ӱ�����
- ��ѡ����������,�ٽ��н�ģʵ�顣��ģ��Ŀ�ľ���Ϊ�˵õ����,���Dz�����һ�ξ͵õ���õĽ��,�϶�Ҫ���Ժܶ��,����һ��Ҫ��һ�����ʵ���������,����ѡ��ͨ�õ�,�����ٻ��ʡ�ȷ�ʵ�,Ҳ���Ը���ʵ�������Լ�ָ�����ʵ�����ָ�ꡣ
- ѡ����ʵ��㷨,������ѡ�����ع��㷨,��ϸ�������е�ϸ��,֮�ὲ�������㷨,���� һ����Ҫ�����ع�����������,�����㷨Ч�����ܻ���á��ڻ���ѧϰ��,������Խ���ӵ��㷨Խʵ��,����Խ���㷨Ӧ��Խ�㷺�����ع��������һ�����͵Ĵ���,��ʵ��,�����κη������ⶼ�������ع鵱��һ�����ȽϵĻ���ģ�͡�
- ģ�͵ĵ���Ҳ�Ǻ���Ҫ��,ͨ��ʵ�鷢�ֲ�ͬ�IJ������ܻ�Խ�������ϴ��Ӱ��,��һ��Ҳ�DZ���ġ�ʹ�ù��߰�ʱ,��������Ȳ�����API�ĵ�,֪��ÿһ������������,��������ʵ�顣
������ɡ�������ʱ�����ǿ��ܻ�о��ܿ���,��������,���װ�������,���������,����ɹ�ֻ��һ����֡�ǰ�ڻ��۵Ĺ���ע����һ�γ�Ĭ��ʱ��,Ҳ����о�����,Ҳ���������Ѿ���ԥ��Ҫ��Ҫ����,�����ҿ��Ը�����,ÿһ�������ж���һֻ��������ǡ��߹�ķ��,Ψ�о��������,��������������
�����Dzȹ����ڶ�Ŀ�,�������ڶ�ļ���,���ǻ����װ�����ʱ����������������������۵�һ���ij̶���ᷢ��,�������������һ�����������,Ϊ�˿����������ķ��,���һֱ���ȵ�һ·����ȥ���ɹ���·�ϲ���ӵ��,��Ϊ��ֵ��˲��ࡣֻ�м����,���Dz�֪��,��һ·���ж���������Ҫ��,�ж��ٶ�����Ҫѧϰ������ʱ�������,�κ�һ��ͨ���ɹ��ĵ�·��ͬ����Խ��Խ�١��ѡ�ʤ��Ϊ������Ϊ��ʣ��Ϊ����Ҳ������ȷ�ر���ɹ����ֵĹ�ϵ��������Ҫһ�ּ���,�����ּ������ñ��˸е����Dz����赲��ʱ��,�ͻ�Ϊ��ijɹ���·������,�װ���������,������ǻ�ļ��������ְ�!