ЁОЩњаХMOOCЁПЩњаХЪ§ОнПт1
ЮФеТЕФЮФзж/ЭМЦЌ/ДњТыВПЗж/ШЋВПРДдДЭјТчЛђбЇЪѕТлЮФ,ЮФеТЛсГжајаоЩЩИќаТ,НіЙЉДѓМвбЇЯАЪЙгУЁЃ
ФПТМ
?4ЁЂвЛМЖКЫЫсЪ§ОнПтЁЊЁЊNCBIЕФGenbankЪ§ОнПт
4.1ЁЊЁЊДѓГІИЫОњdUTPas(ЭббѕФђмеНЙСзЫсУИ)X01714ЕФDNAађСа
4.2ЁЊЁЊБрТыШЫdUTPaseЕФГЩЪьmRNAађСаU90223
4.3ЁЊЁЊБрТыШЫdUTPaseЕФdutЛљвђађСаЁЃађСаAF018430
5ЁЂвЛМЖКЫЫсЪ§ОнПтЁЊЁЊЛљвђзщЪ§ОнПтEnsemble
6ЁЂвЛМЖКЫЫсЪ§ОнПтЁЊЁЊЮЂЩњЮяКъЛљвђзщЪ§ОнПтJCVI
1ЁЂШЯЪЖЩњЮяЪ§ОнПтзАдиЕФФкШн
HIV-oneВЁЖОЕФећИіЛљвђзщ,АќКЌСЫ9752ИіМюЛљ,БрТы9ИіЛљвђЁЃВюВЛЖрвЛвГA4жН,е§ЗДУцДђгЁОЭПЩвдАбетОХЧЇЖрИіМюЛљМЧТМЯТРДЁЃ

ШЫЕФЛљвђзщвЊДѓЕУЖр,га3ИіG,вВОЭЪЧ30вкИіМюЛљЁЃШчЙћвЛвГA4жНДђгЁ5000ИіМюЛљЕФЛА,ЮвУЧашвЊДђгЁ60ЭђвГ,ВХФмАбећИіШЫЕФЛљвђзщДђгЁЭъЁЃ


?дкЩњЮяжа,1000K=1MЁЃ1000M=1GЁЃ1000G=1T,1000T=1P,вРДЮ1000БЖ1000БЖЕФЭљЩЯдіГЄЁЃ

?
2ЁЂЩњЮяЪ§ОнПтЕФЗжРр
КЫЫсЪ§ОнПт:ЪЧгыКЫЫсЯрЙиЕФЪ§ОнПтЁЃ
ЕААзжЪЪ§ОнПт:гыЕААзжЪЯрЙиЕФЪ§ОнПт
зЈгУЪ§ОнПт:зЈУХеыЖдФГвЛжїЬтЕФЪ§ОнПт,ЛђепЪЧзлКЯадЕФЪ§ОнПт,вдМАЮоЗЈЙщШыЦфЫћСНРрЕФЪ§ОнПтЁЃ
вЛМЖЪ§ОнПт:ДцДЂЕФЪЧЭЈЙ§ИїжжПЦбЇЪжЖЮЕУЕНЕФзюжБНгЕФЛљДЁЪ§ОнЁЃБШШчВтађЛёЕУЕФКЫЫсађСа,ЛђепXЩфЯпбмЩфЗЈЕШЛёЕУЕФЕААзжЪШ§ЮЌНсЙЙЁЃ
ЖўМЖЪ§ОнПт:ЪЧЭЈЙ§ЖдвЛМЖЪ§ОнПтЕФзЪдДНјааЗжЮіЁЂећРэЁЂЙщФЩЁЂзЂЪЭЖјЙЙНЈЕФОпгаЬиЪтЩњЮябЇвтвхКЭзЈУХгУЭОЕФЪ§ОнПтЁЃ

?
3ЁЂЮФЯзЪ§ОнПтЁЊЁЊPubMed
дкЫбЫїЪБ,ПЩвдЪЙгУв§КХЁЃв§КХРяЕФДЪЛсБЛЕБзївЛИіећЬхРДПДД§,ЖјВЛЛсБЛВ№ПЊЁЃ
вВПЩвдЪЙгУТпМДЪANDORNOTЁЃ
дкPubMedЫбЫї1995ФъвдЧАЕФЮФЯзжаХХУћЪЎЮЛвдКѓЕФзїепЪЧАзЗбСІЦјЁЃЫбЫї1976ФъвдЧАЕФЮФЯзЪЧУЛгаеЊвЊЕФЁЃЫбЫї1965ФъвдЧАЕФЮФЯзЮоНсЙћЁЃ

?
?4ЁЂвЛМЖКЫЫсЪ§ОнПтЁЊЁЊNCBIЕФGenbankЪ§ОнПт
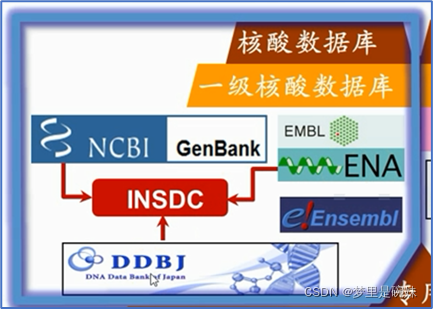
Ш§ДѓКЫЫсЪ§ОнПтАќРЈNCBIЕФGenbank,EMBLЕФENAКЭDDBJ,ЫќУЧЙВЭЌЙЙГЩЙњМЪКЫЫсађСаЪ§ОнПтЁЃЭЈЙ§INSDC,Ш§ДѓКЫЫсЪ§ОнбїЕФаХЯЂУПШеЯрЛЅНЛЛЛЁЂИќаТЛузм,етЪЙЕУЫћУЧМИКѕдкШЮКЮЪБКђЖМЯэгаЯрЭЌЕФЪ§ОнЁЃ
?
ЪзЯШашвЊУїШЗдКЫЩњЮяКЭецКЫЩњЮяЕФЛљвђЧјБ№ЁЃ
дКЫЩњЮя:ЛљвђзщаЁ,ЛљвђЪЧГЪЯпадЗжВМ,ЛљвђУмЖШИп(1000ИіМюЛљРяОЭга1ИіЛљвђ),БрТыЧјКЌСПИп,дКЫЩњЮяУЛгаФкКЌзгЁЃ
ецКЫЩњЮя:ЛљвђзщДѓ,ЛљвђЪЧЗЧЯпадЕФ,ЛљвђУмЖШЕЭ(10ЭђИіМюЛљга1ИіЛљвђ),БрТыЧјКЌСПЕЭ,ецКЫЩњЮягаФкКЌзг,mRNAвЊОРњМєЧаЕФЙ§ГЬ,МєЧаКѓЕФГЩЪьmRNAВХФмНјааЗвыЁЃ
дКЫЩњЮяКЭецКЫЩњЮягаЮоФкКЌзгЕМжТСЫСНжжЛљвђдкЪ§ОнПтжаВЛЭЌЕФДцДЂЗНЪНКЭзЂЪЭЁЃ

?
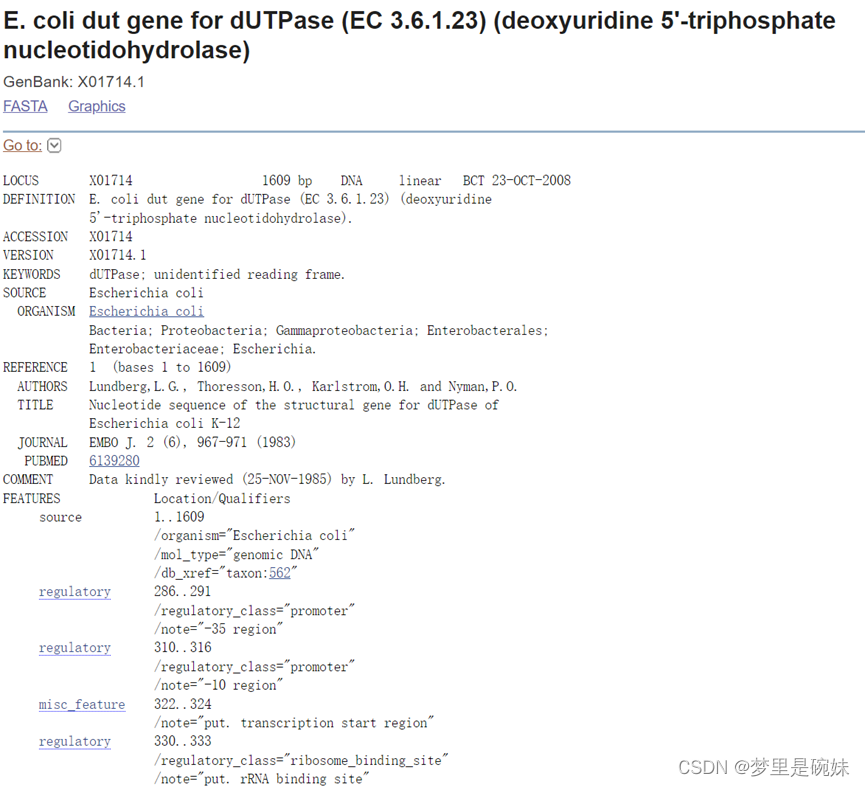
4.1ЁЊЁЊДѓГІИЫОњdUTPas(ЭббѕФђмеНЙСзЫсУИ)X01714ЕФDNAађСа
?
| зжЖЮ | НтЪЭ |
| LOCUS | АќРЈЛљвђзљЕФУћзж,КЫЫсађСаГЄЖШ,ЗжзгЕФРрБ№,ЭиЦЫРраЭ,дКЫЩњЮяЕФЛљвђЭиЦЫРраЭЖМЪЧЯпадЕФ,зюКѓЪЧИќаТШеЦкЁЃ |
| DEFINITION | ЪЧетЬѕађСаЕФМђЖЬЖЈвх,вВОЭЪЧетЬѕађСаЕФБъЬтЁЃ |
| ACCESSION | ОЭЪЧдкЫбЫїЬѕжаЪфШыЕФФЧИіЪ§ОнПтБрКХ,вВНазіМьЫїКХ,УПЬѕМЧТМЕФМьЫїКХдкЪ§ОнПтжаЪЧЮЈвЛЧвВЛБфЕФЁЃ МДЪЙЪ§ОнЬсНЛепИФБфСЫЪ§ОнФкШн,AccessionвВВЛЛсБфЁЃ ЭЌвЛИіЛљвђдкВЛЭЌЕФЪ§ОнПтжаЛсгаВЛЭЌЕФМьЫїКХ(Accession),ЖјЛљвђЕФУћзжжЛгавЛИі(LOCUS)ЁЃ |
| Version | АцБОКХЕФИёЪНЪЧЁАМьЫїКХ.АцБОБрКХЁБ |
| GIКХ | GIКХгыАцБОКХЯЕЭГЪЧЦНаадЫааЕФЁЃЕБвЛЬѕађСаИФБфКѓ,ЫќНЋБЛИГгшвЛИіаТЕФGIКХ,ЭЌЪБЫќЕФАцБОКХНЋдіМгЁЃ |
| KEYWORDS | ЬсЙЉФмЙЛДѓжТУшЪіИУЬѕФПЕФМИИіЙиМќДЪ,ПЩгУгкЪ§ОнПтЫбЫїЁЃ |
| SOURCE | ЛљвђађСаЫљЪєЮяжжЕФЫзУћЁЃ ЦфзгЬѕФПORGANISM,ЪЧЖдЫљЪєЮяжжИќЯъЯИЕФЖЈвх,АќРЈЫћЕФПЦбЇЗжРрЁЃ |
| REFERENCE | ЪЧЛљвђађСаРДдДЕФПЦбЇЮФЯзЁЃвЛЬѕЛљвђађСаЕФВЛЭЌЦЌЖЮПЩФмРДдДгкВЛЭЌЕФЮФЯз,ЛсгаКмЖрИіREFERENCEЬѕФПГіЯжЁЃ |
| COMMENT | ЪЧздгЩзЋаДЕФФкШн,БШШчжТаЛ,ЛђепЪЧЮоЗЈЙщШыЧАУцМИЯюЕФФкШнЁЃ |
| FEATURES | ЪЧЗЧГЃживЊЕФзЂЪЭФкШн,ЫќУшЪіСЫКЫЫсађСажаИїИівбШЗЖЈЕФЦЌЖЮЧјгђ,АќКЌКмЖрзгЬѕФП,БШШчРДдД,ЦєЖЏзг,КЫЬЧЬхНсКЯЮЛЕуЕШЕШЁЃ |
| Source | КЫЫсађСаЕФРДдД,ОнДЫПЩвдШнвзЕФЗжБцГіетЬѕађСаЪЧРДдДгкПЫТЁдиЬхЛЙЪЧЛљвђзщЁЃ |
| Promoter | ЦєЖЏзгЕФЮЛжУЁЃЯИОњгаСНИіЦєЖЏзгЧј,-35ЧјКЭ-10ЧјЁЃ |
| misc_feature | СаГіСЫвЛаЉдгЯю,БШШч,putБэЪОЭЦВт,етЬѕЫЕУїСЫДгЕк322ИіМюЛљЕНЕк324ИіМюЛљЪЧвЛИіЭЦВтЕФ,ЕЋЮоЪЕбщжЄЪЕЕФзЊТМЦ№ЪМЮЛжУЁЃ |
| RBS | КЫЬЧЬхНсКЯЮЛЕуЕФЮЛжУЁЃ |
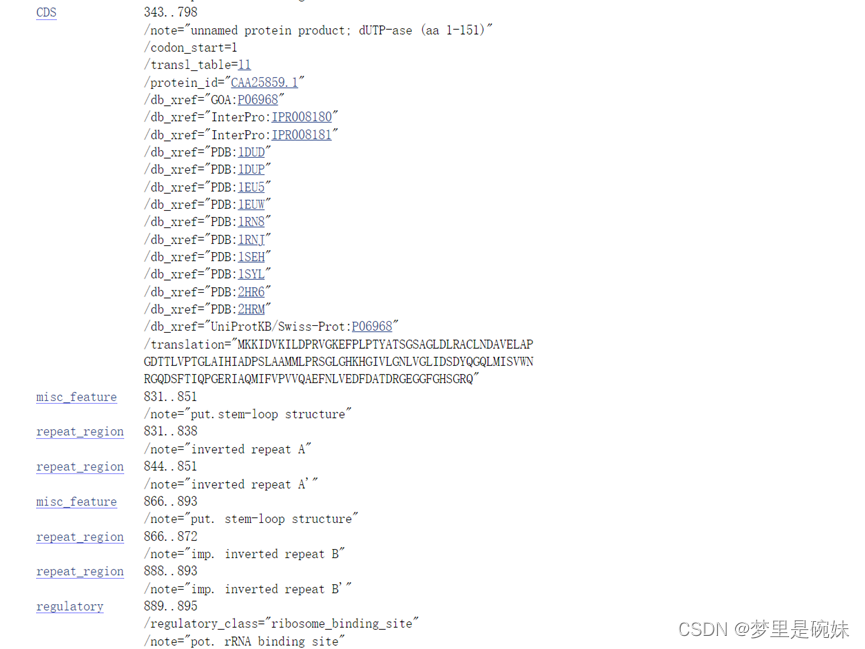
| CDS | CodingSegment,БрТыЧјЁЃЖдгкдКЫЩњЮяРДНВ,CDSМЧТМСЫвЛИіПЊЗХдФЖСПђЁЃДгЕк343ИіМюЛљПЊЪМЕФЦ№ЪМУмТызгATGЕНЕк798ИіМюЛљНсЪјЕФНсЪјУмТызгTAAЁЃГ§СЫЮЛжУаХЯЂ,ЛЙАќРЈЗвыВњЮяЕФжюЖраХЯЂЁЃЗвыВњЮяЕААзЕФУћзжЪЧdUTPase,етИіБрТыЧјБрТыИУЕААзЕФЕк1ЕНЕк151ИіАБЛљЫсЁЃ етВЛЪЧЩњЮяздШЛЗвыЕФ,ЖјЪЧМЦЫуЛњЗвыЕФЁЃ |
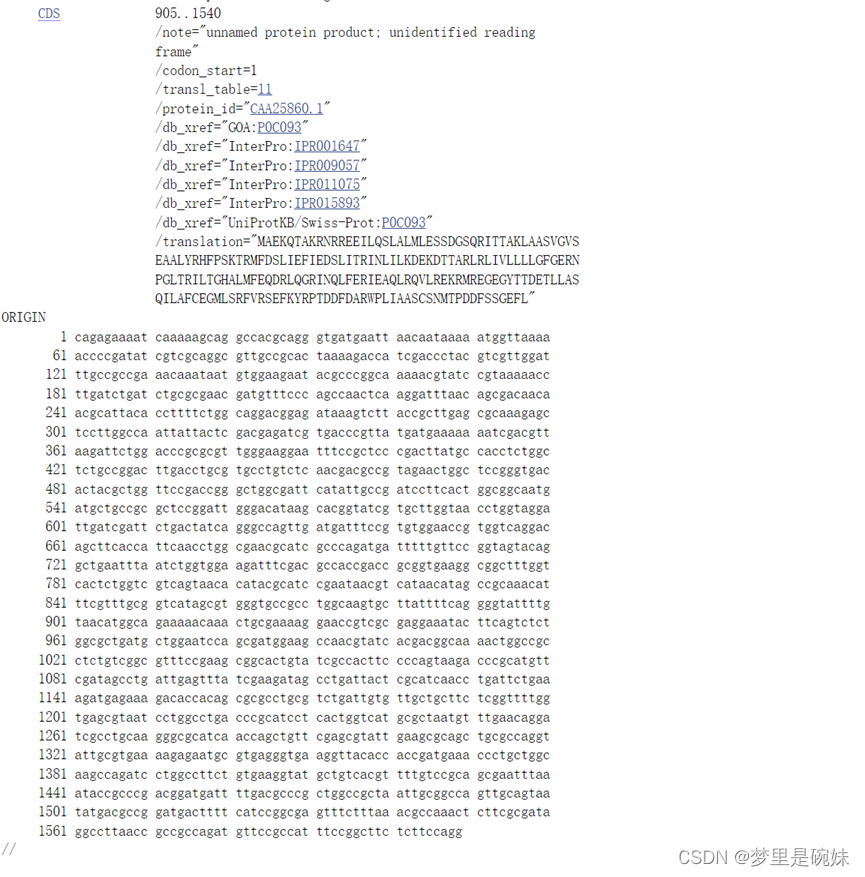
| ORIGIN | ЪЧКЫЫсађСа,вдЫЋаБЯпзїЮЊећЬѕМЧТМЕФНсЪјЗћЁЃ |
4.2ЁЊЁЊБрТыШЫdUTPaseЕФГЩЪьmRNAађСаU90223
ГЩЪьmRNAЪЧвбОМєЧаЕєФкКЌзг,жЛЪЃЭтЯдзгЕФађСа,ЫљвдетЬѕГЩЪьmRNAађСаКЭжЎЧАПДЕНЕФдКЫЩњЮяЕФDNAађСаДгЭиЦЫНсЙЙЩЯПДЪЧМИКѕвЛбљЕФЁЃ
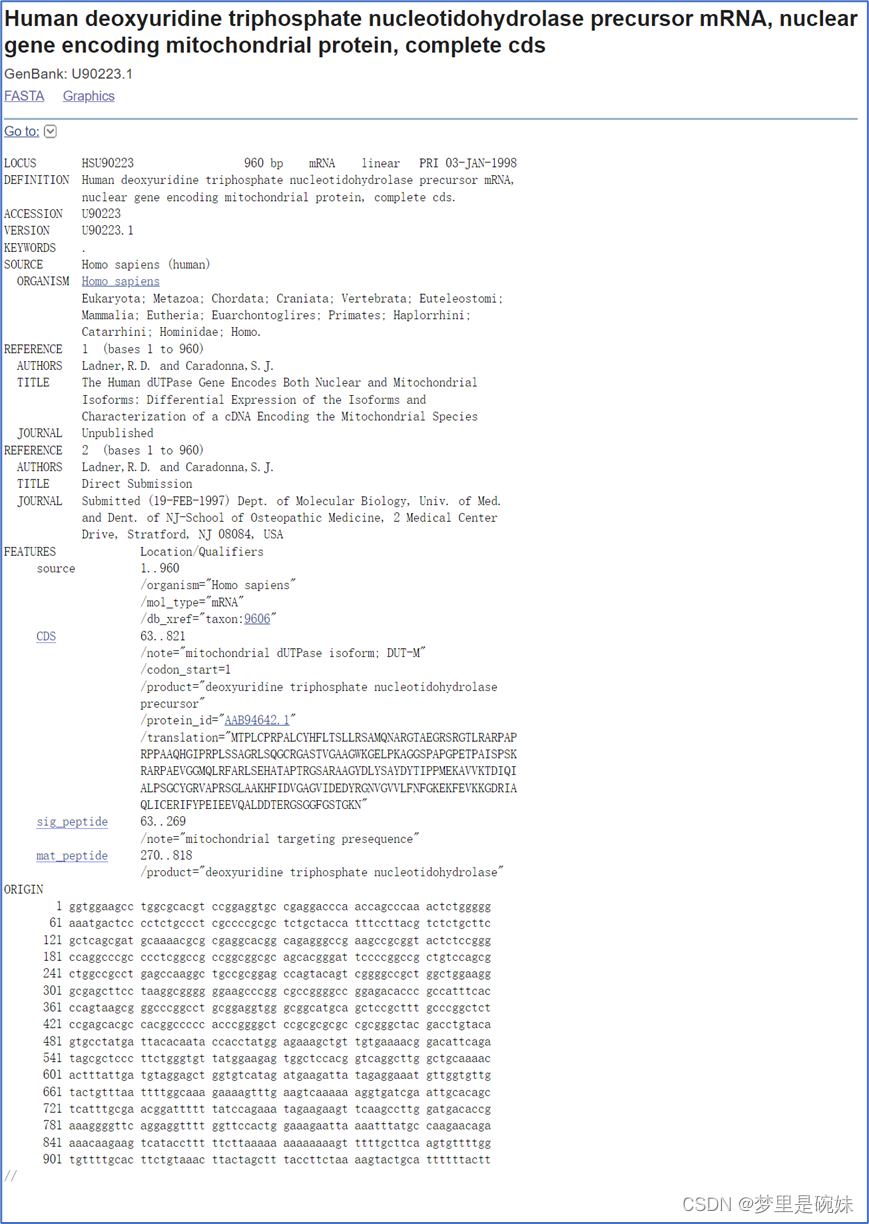
KEYWORDSКѓУцжЛгавЛИіЕуЁЃБэЪОЪ§ОнПтВЂВЛЪЧЭъУРЕФ,ЫљгаЪ§ОнПтЖМДцдкЪ§ОнВЛЭъећЕФЮЪЬтЁЃ
FeaturesРяЕФзЂЪЭФкШнгыдКЫЩњЮяЕФЪ§ОнПтМЧТМЯрЫЦ,
CDSжИГіСЫДг63ЕН821ЪЧвЛЖЮБрТыЧј,дкетЖЮБрТыЧјРяЛљвђЪЧСЌајЕФ,вђЮЊЪЧОЙ§МєЧаКѓЕФГЩЪьmRNA,ЫќНЋБЛЗвыГЩЯпСЃЬхаЭdUTPaseЕААзЁЃ
/translationРяИјГіЕФЪЧМЦЫуЛњЗвыГіЕФИУЕААзЕФађСаЁЃ
sig_peptide(signalpeptide)БрТыаХКХыФЕФМюЛљЕФЮЛжУЁЃаХКХыФОіЖЈСЫЕААзжЪЕФбЧЯИАћЖЈЮЛ,вВОЭЪЧЕААзжЪЙЄзїЕФЕиЗНЁЃ
mat_peptide(maturepeptide)жИГіБрТыГЩЪьыФСДЕФМюЛљЕФЮЛжУЁЃЫћДгаХКХыФКѓУцПЊЪМ,ЕНБрТыЧјНсЮВЬсЧАШ§ИіМюЛљНсЪјЁЃ
БрТыЧјЕФзюКѓШ§ИіМюЛљЪЧжежЙУмТызг,ВЛЗвыЁЃ
4.3ЁЊЁЊБрТыШЫdUTPaseЕФdutЛљвђађСаЁЃађСаAF018430

?
5ЁЂвЛМЖКЫЫсЪ§ОнПтЁЊЁЊЛљвђзщЪ§ОнПтEnsemble
EnsemblЪ§ОнПт(http://www.ensembl.org)ЫќЪеШыСЫИїжжЖЏЮяЕФЛљвђзщ,ЬиБ№ЪЧФЧаЉРыШЫРрНќЕФМЙзЕЖЏЮяЕФЛљвђзщЁЃ

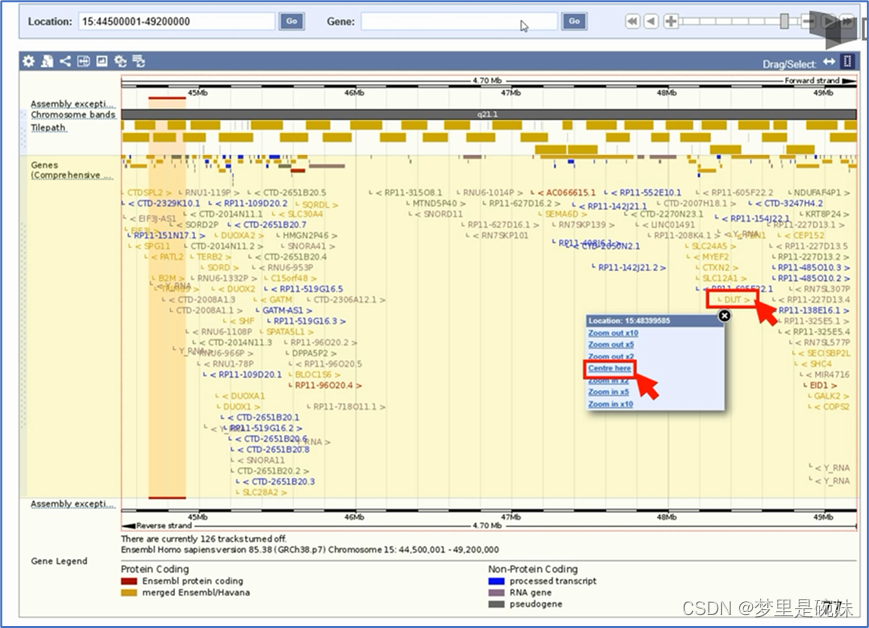
БрТыdUPTaseЕФdutЛљвђОЭдк15КХШОЩЋЬхЩЯЁЃ
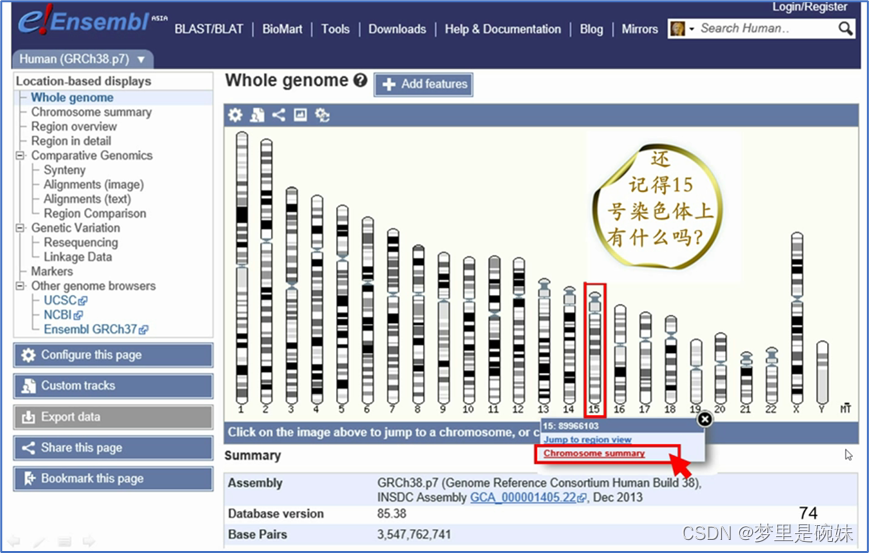
?дкЕЏГіДАПкжабЁдёШОЩЋЬхИХвЊ(chromosomesummary)ЁЃетЪБЮвУЧЛсЕУЕН15КХШОЩЋЬхЕФвЛИівЛРРЭМЁЃРяУцАќРЈБрТыЕААзЕФЛљвђЁЂЗЧБрТыЛљвђЁЂМйЛљвђЗжБ№дкШОЩЋЬхЩЯВЛЭЌЧјЖЮФкЕФКЌСП,вдМАGCАйЗжБШ(КьЯп),КЭЮРаЧDNAАйЗжБШ(КкЯп)ЁЃШОЩЋЬхЭГМЦБэИјГіСЫ15КХШОЩЋЬхЕФГЄЖШ,вдМАИїжжРраЭЕФЛљвђЕФИіЪ§ЁЃ
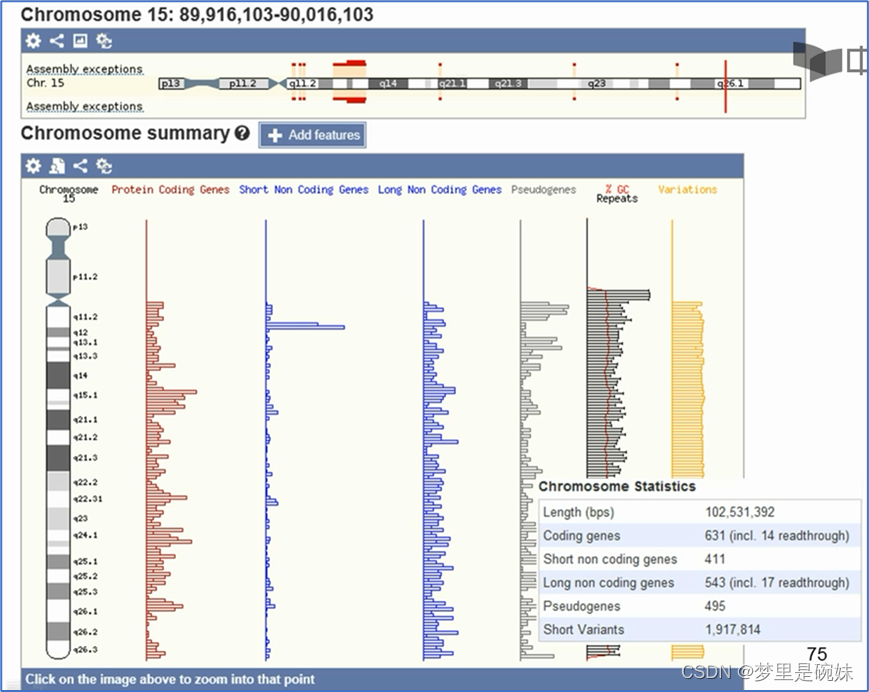
?ДгGenbankЮвУЧСЫНтЕН,dutЛљвђЕФЕкШ§КХЭтЯдзгЮЛгк15КХШОЩЋЬхЕФГЄБлЬѕДј21.1ИННќЁЃЫљвдЮвУЧНјвЛВННјШыетИіЬѕДјПДвЛЯТЁЃЕуЛїЬѕДј21.1,бЁдёЧјМфСДНгЁЃетЪБ,етИіЧјМфФкЫљгаЕФЛљвђОЭЖМБЛЯдЪОдквЛеХЭМЩЯЁЃПЩвдДгетИіЭМЦзЩЯжБНгевЕНdutЛљвђ,ВЂвдЫћЮЊжааФЗХДѓЁЃШчЙћевВЛЕН,вВПЩвдЭЈЙ§ЫбЫїЬѕЪфШыЛљвђЕФУћзжНјааВщевЁЃ
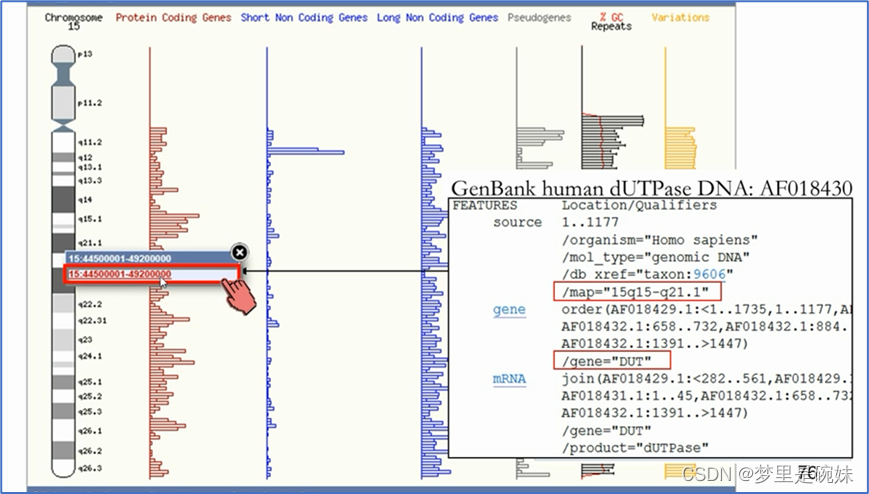
?дквдdutЛљвђЮЊжааФЯдЪОЕФЗХДѓЭМЦзжа,ЕуЛїdutЛђепЖдгІЕФЧјгђ,дкЕЏГіЕФИХПіДАПкжабЁдёEnsembleЪ§ОнПтЕФМьЫїКХЁЃжЎКѓОЭЛсГіЯжdutЛљвђдкEnsembleЪ§ОнПтжаЕФЯъЯИМЧТМЁЃ
6ЁЂвЛМЖКЫЫсЪ§ОнПтЁЊЁЊЮЂЩњЮяКъЛљвђзщЪ§ОнПтJCVI
TIGRЪЧNCBIЛљвђзщзЪдДЕФгаСІВЙГф,вђЮЊЫќВЛНігЕгавбЭъГЩВтађЕФЛљвђзщ,ЛЙгаФЧаЉВтађжаЕФЛљвђзщаХЯЂЁЃдкжВЮяЛљвђзщЯюФПжаПЩвдевЕНФтФЯНцЁЂгёУзЁЂмйоЃКЭСјЪїЕФЛљвђзщаХЯЂЁЃдкЮЂЩњЮягыЛЗОГЛљвђзщФПжа,ЬиБ№жЕЕУЙизЂЕФЪЧЁАШЫРрЮЂЩњЮязщМЦЛЎЁБ,HMPЁЃ
HMPгЩУРЙњNIHЗЂЦ№,гЩ4ИіЫФИіВтађжааФЙВЭЌЭъГЩ,ЦфжавЛИіОЭЪЧПЫРГИёЗВЬибЇдКЁЃЁАШЫРрЮЂЩњЮязщМЦЛЎЁБПАБШЁАШЫРрЛљвђзщМЦЛЎЁБЁЃФПЧА,HMPжївЊАќРЈСЫШЫРрБЧЧЛЁЂПкЧЛЁЂЦЄЗєЁЂЮИГІЕРКЭУкФђЩњжГЕРЕФКъЛљвђзщбљБОЪ§ОнКЭЗжЮіСїГЬЁЃ
?ЮвУЧФПЧАШЯжЊЕФЮЂЩњЮяВЛЕН1%,ЩњЛюдкЮвУЧГІЕРжаЕФЮЂЩњЮяЯИАћ,ЪЧШЫЬхЯИАћЕФ10БЖЁЃетаЉЮЂЩњЮяЛљвђзщжЎКЭЪЧШЫРрЛљвђзщЕФ100БЖЁЃЮЂЩњЮягАЯьВЂГЌдНЮвУЧЕФЩњРЯВЁЫР,гавЛЬьШЫЫРСЫ,ЕЋЩэЬхжаЕФЮЂЩњЮяШДЛЙЛюзХЁЃГ§СЫНќФъРДЩйСПЕФгаЙиЬЧФђВЁЕШгыГІЕРЮЂЩњЮяЕФбаОПЭт,ЮвУЧЭъШЋВЛЧхГўГІЕРЮЂЩњЮя,КєЮќЕРЮЂЩњЮя,ЛЙгаЬхБэЮЂЩњЮяЕШдкШЫЬхФкзіСЫЪВУД,ЫћУЧЕФЯВХАЇРжгыЮвУЧЕФЩњРЯВЁЫРгаЪВУДЙиЯЕЁЃ
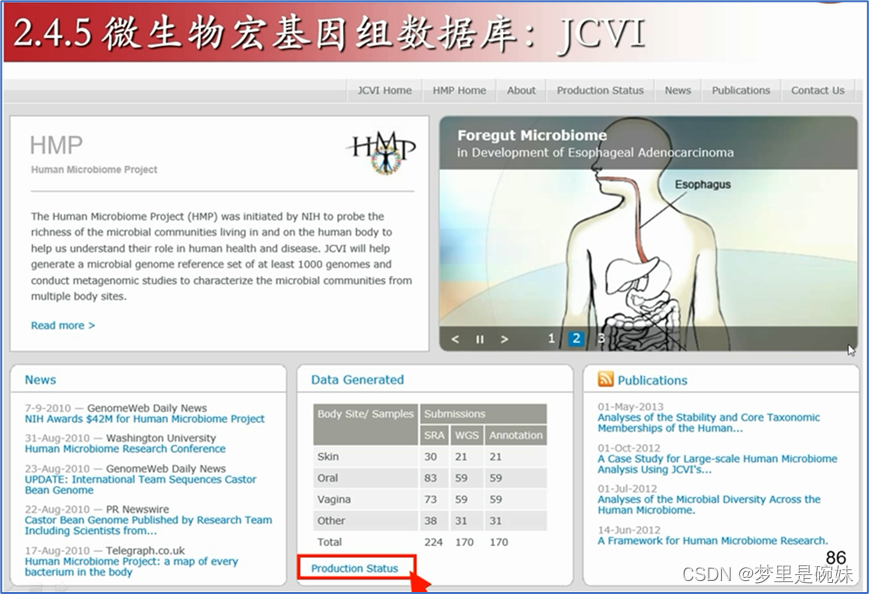
ЕуЛїЭГМЦСДНгЁЃПЩвдЕУЕНHMPжавббаОПЕФЫљгаЮЂЩњЮяЛљвђзщЁЃетаЉЮЂЩњЮядкШЫЬхжаДцдкЕФЮЛжУ,ВтађМАзЂЪЭЪЧвбЭъГЩЛЙЪЧдкНјаажаЁЃ
вбЭъГЩЕФЛљвђзщКѓУцЛсгаШ§ИіСДНг:
WGS? ЪЧШЋЛљвђзщФёЧЙЗЈВтађЯюФПЪ§ОнПтМЧТМЕФСДНгЁЃ
SRA? ЪЧИпЭЈСПВтађЪ§ОнПтМЧТМЕФСДНгЁЃетСНИіСДНгРяМЧТМЕФЪЧВтађЕФаХЯЂЁЃ
ANNOTATION? СДНгРяЕФФкШн,ЫћСаГіСЫФГИіЛљвђзщдкGenbankжаЫљгазЂЪЭЕФСДНгЁЃБШШчЮЂЩњЮяAcinetobacterradioresistensSK82ЕФЛљвђзщЙВЗжГЩ82ЬѕађСаМЧТМдкGenbankЪ§ОнПтжаЁЃ
 ?
?
7ЁЂЖўМЖКЫЫсЪ§ОнПт

ЖўМЖКЫЫсЪ§ОнПтАќРЈЕФФкШнЗЧГЃЖрЁЃЦфжаNCBIЯТЪєЕФШ§ИіЪ§ОнПтОГЃЛсгУЕНЁЃЫћУЧЪЧRefSeqЪ§ОнПт,dbESTЪ§ОнПтКЭGeneЪ§ОнПтЁЃ
RefSeqЪ§ОнПт,вВНаВЮПМађСаЪ§ОнПт,ЪЧЭЈЙ§здЖЏМАШЫЙЄОЋбЁГіЕФЗЧШпгрЪ§ОнПт,АќРЈЛљвђзщађСаЁЂзЊТМађСаКЭЕААзжЪађСаЁЃЗВЪЧНаrefЪВУДЕФЪ§ОнПтЖМЪЧЗЧШпгрЪ§ОнПт,ОЭЪЧвбОАяФуАбжиИДЕФФкШнШЅГ§ЕєСЫЁЃ
dbESTЪ§ОнПт,вВОЭЪЧБэДяађСаБъЧЉЪ§ОнПт,ДцДЂЕФЪЧВЛЭЌЮяжжЕФБэДяађСаБъЧЉЁЃ
GeneЪ§ОнПтвдЛљвђЮЊМЧТМЖдЯѓЮЊгУЛЇЬсЙЉЛљвђађСазЂЪЭКЭМьЫїЗўЮё,ЪеТМСЫРДзд5300ЖрИіЮяжжЕФ430ЭђЬѕЛљвђМЧТМЁЃ

ЗЧБрТыRNAЪ§ОнПт,ЬсЙЉЗЧБрТыRNAЕФађСаКЭЙІФмаХЯЂЁЃ
ЗЧБрТыRNAВЛБрТыЕААзжЪЕЋдкЯИАћжаЦ№ЕїНкзїгУЁЃФПЧАИУЪ§ОнПтАќКЌРДдДгк99жжЯИОњ,ЙХЯИОњКЭецКЫЩњЮяЕФ3ЭђЖрЬѕађСаЁЃmicroRNAЪ§ОнПтжївЊДцЗХвбЗЂБэЕФmicroRNAађСаКЭзЂЪЭЁЃетИіЪ§ОнПтПЩвдЗжЮіmicroRNAдкЛљвђзщжаЕФЖЈЮЛКЭЭкОђmicroRNAађСаМфЕФЙиЯЕЁЃ

?
ПЮГЬбЇЯАСДНг:ЩњЮяаХЯЂбЇ_жаЙњДѓбЇMOOC(ФНПЮ) (icourse163.org)