前情回顾
笔者目前的方向可以概括为基于多传感器融合的小目标检测,在基于CNN的模型中,我选中了田纳西大学提出的CenterFusion作为自己的实验之一,因为CenterFusion对于nuScenes的数据处理是目前CNN模型中较为全面的,这里的全面指的是:利用的特征较多(包括三维锚框,速度等),模型的性能较其baseline提升较大,对雷达特征进行了多种处理并采用middle-fusion的融合方法,兼顾了检测的分辨率和语义丰富度,是众多融合模型中综合表现和new-idea比较多的一个融合结构。
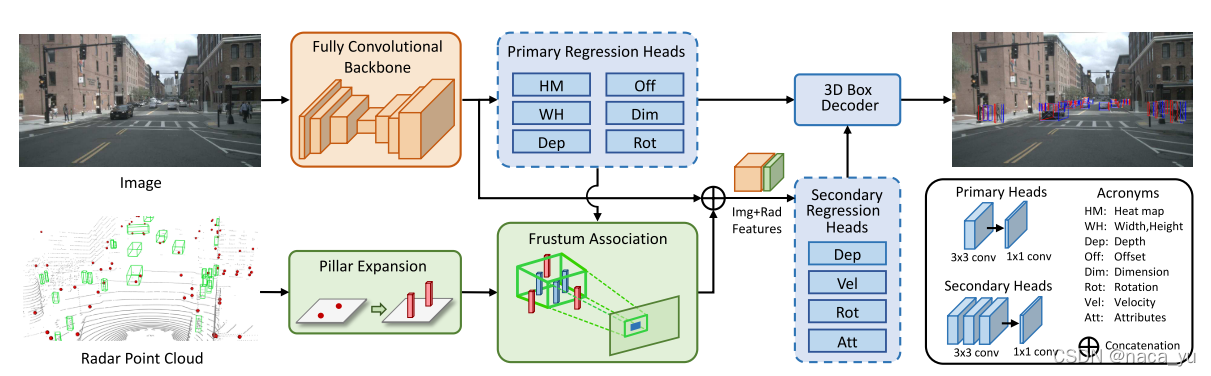
centerfusion先利用backbone(centerNet+DLA)生成的特征图,预先用Primary Regression Heads(多个预测头)对图片中的目标进行初步预测,后将预测结构投影至雷达点云中去除背景点云,两者融合生成Img+Radar features,利用features进行Senconda Regression进行预测,生成最终的预测结果,并结合Primary heads的结果生成最终的三维锚框。
- centerfusion论文地址:https://link.zhihu.com/?target=https%3A//arxiv.org/pdf/2011.04841.pdf
- 源码地址:https://link.zhihu.com/?target=https%3A//github.com/mrnabati/CenterFusion
-
前面笔者主要介绍了:
[nuscenes的数据格式]
[nuscenes的数据转换] -
经过上面两个步骤,我们生成了可以用于COCO的标注文件:mini-train.json,下面用于模型对数据进行加载。建议读本文章之前先阅读前面的两篇博客。
整体数据加载框架
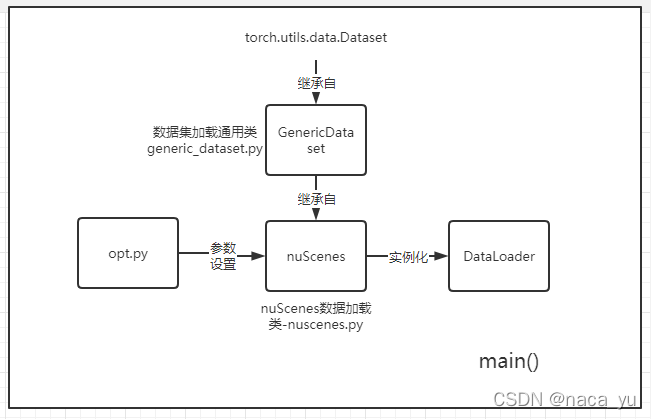
上图为数据加载的流程图,数据先由opt.py中实例化的opt内设置的参数初始化数据集的名称、路径、图片分辨率等,后经过引入 nuScenes类(未经过实例化,继承自GenericDataset),后用opt.py中update_dataset_info_and_set_heads方法 初步更新opt中的基本数据集参数如输入图片大小、目标种类数量,然后对nuScenes进行实例化,并送入Dataloader中。
数据加载关键步骤
opt.py
opt.py中,最关键的除了通过命令行设置运行参数,还增加了下面这个函数,opt将所有的参数,包括数据的参数存储,传入到基本后面所有的类和函数中,是整个模型运行的关键,保证了参数的唯一性和可复用性。
def update_dataset_info_and_set_heads(self, opt, dataset):#将数据集的信息录入opt,并且初始化预测头参数
opt.num_classes = dataset.num_categories if opt.num_classes < 0 else opt.num_classes
#这三个w,h具有优先级大小,opt.input_h > opt.input_res >default
input_h, input_w = dataset.default_resolution
input_h = opt.input_res if opt.input_res > 0 else input_h
input_w = opt.input_res if opt.input_res > 0 else input_w
opt.input_h = opt.input_h if opt.input_h > 0 else input_h
opt.input_w = opt.input_w if opt.input_w > 0 else input_w
#这里就是centerNet中,head_map的大小,利用down_ratio
opt.output_h = opt.input_h // opt.down_ratio
opt.output_w = opt.input_w // opt.down_ratio
opt.input_res = max(opt.input_h, opt.input_w)
opt.output_res = max(opt.output_h, opt.output_w)
#预测头head输出通道数初始化
opt.heads = {'hm': opt.num_classes, 'reg': 2, 'wh': 2}
if 'tracking' in opt.task:
opt.heads.update({'tracking': 2})
if 'ddd' in opt.task:#对应train.sh 输入的'ddd'
opt.heads.update({'dep': 1, 'rot': 8, 'dim': 3, 'amodel_offset': 2})
if opt.pointcloud:#如果开启雷达
opt.heads.update({'dep_sec': 1})
opt.heads.update({'rot_sec': 8})
if 'multi_pose' in opt.task:
opt.heads.update({
'hps': dataset.num_joints * 2, 'hm_hp': dataset.num_joints,
'hp_offset': 2})
if opt.ltrb:
opt.heads.update({'ltrb': 4})
if opt.ltrb_amodal:
opt.heads.update({'ltrb_amodal': 4})
if opt.nuscenes_att:
opt.heads.update({'nuscenes_att': 8})
if opt.velocity:
opt.heads.update({'velocity': 3})
#模型权重初始化
weight_dict = {'hm': opt.hm_weight, 'wh': opt.wh_weight,
'reg': opt.off_weight, 'hps': opt.hp_weight,
'hm_hp': opt.hm_hp_weight, 'hp_offset': opt.off_weight,
'dep': opt.dep_weight, 'dep_res': opt.dep_res_weight,
'rot': opt.rot_weight, 'dep_sec': opt.dep_weight,
'dim': opt.dim_weight, 'rot_sec': opt.rot_weight,
'amodel_offset': opt.amodel_offset_weight,
'ltrb': opt.ltrb_weight,
'tracking': opt.tracking_weight,
'ltrb_amodal': opt.ltrb_amodal_weight,
'nuscenes_att': opt.nuscenes_att_weight,
'velocity': opt.velocity_weight}
opt.weights = {head: weight_dict[head] for head in opt.heads}
#删除weight == 0,也就是权重为0的无效参数
for head in opt.weights:
if opt.weights[head] == 0:
del opt.heads[head]
temp_head_conv = opt.head_conv
opt.head_conv = {head: [opt.head_conv for i in range(opt.num_head_conv if head != 'reg' else 1)] for head in opt.heads}
'''
heads为各个head的名字及对应通道数,例如这里的head作为primary_head的内容,其中hm为类的个数,因为heat_map要生成每一类的热图
head_conv就是预测头3x3卷积的卷积核数量
arch就是模型结构名称:arch-34就是本文所选模型
num_head_conv:num_head_conv是head_conv的卷积核的组数,每个head头最终的卷积核数目为:num_head_conv x head_conv
在论文中,num_head_conv = 1 or 3
'''
## update custom head convs,这里是seconda heads,它每个头包含3x(3x3)的卷积核数为256的卷积
if opt.pointcloud:
temp = {k: [temp_head_conv for i in range(v)] for k,v in opt.custom_head_convs.items()}
opt.head_conv.update(temp)
return opt
nuscenes.py
nuscenes.py包含了Dataset的初始化功能,这个类继承了GenericDataset,负责初始化数据集的名称,传入标注文件和图片雷达点云的路径,并且在最后调用父类的初始化方法。
class nuScenes(GenericDataset):
...省略
def __init__(self, opt, split):
split_names = {
'mini_train':'mini_train', #在这里选择的是mini_train训练集
'mini_val':'mini_val',#选择此为验证集
'train': 'train',
'train_detect': 'train_detect',
'train_track':'train_track',
'val': 'val',
'test': 'test',
'mini_train_2': 'mini_train_2',
'trainval': 'trainval',
}
split_name = split_names[split]
#数据的路径
data_dir = os.path.join(opt.data_dir, 'nuscenes')#data/nuscenes
print('Dataset version', opt.dataset_version)
anns_dir = 'annotations'
if opt.radar_sweeps > 1:#we choose 3
anns_dir += '_{}sweeps'.format(opt.radar_sweeps)#-------------------------------
if opt.dataset_version == 'test':
ann_path = os.path.join(data_dir, anns_dir, 'test.json')
else:
#训练的时候这是标注json文件的路径
ann_path = os.path.join(data_dir, anns_dir, '{}.json').format(split_name)
self.images = None
'''
前面进行了一系列的参数设置,包括数据集名字,标注json文件路径等,最后传入generic_dataset这个数据集通用类中
'''
super(nuScenes, self).__init__(opt, split, ann_path, data_dir)#继承通用类
print('Loaded {} {} samples'.format(split, self.num_samples))
generic_dataset.py
generi_dataset.py中含有GenericDataset类,这个类被当作通用数据加载器用来被不同数据格式的加载类继承,其主要的关键部分在于__getitem__函数中,这个函数的返回值决定了模型的输入模式。
def __getitem__(self, index):#重点
opt = self.opt
img, anns, img_info, img_path = self._load_data(index)
height, width = img.shape[0], img.shape[1]
#一个图片的标注由远及近重新排序
new_anns = sorted(anns, key=lambda k: k['depth'], reverse=True)
## Get center and scale from image
c = np.array([img.shape[1] / 2., img.shape[0] / 2.], dtype=np.float32)#center
s = max(img.shape[0], img.shape[1]) * 1.0 if not self.opt.not_max_crop else np.array([img.shape[1], img.shape[0]], np.float32)#图片大小
aug_s, rot, flipped = 1, 0, 0#图像增强的参数:旋转、翻转
## data augmentation for training set
if 'train' in self.split:
c, aug_s, rot = self._get_aug_param(c, s, width, height)
s = s * aug_s
if np.random.random() < opt.flip:
flipped = 1
img = img[:, ::-1, :]#img第二维度的倒序取,也就是左右翻转,img.shape=[3, 226, 226]
anns = self._flip_anns(anns, width)#同时对应的annotation也要更新
#生成用作对照片进行数据增强、规定大小的转换矩阵
trans_input = get_affine_transform(
c, s, rot, [opt.input_w, opt.input_h])
trans_output = get_affine_transform(
c, s, rot, [opt.output_w, opt.output_h])
#这是转换后的照片
inp = self._get_input(img, trans_input)#Augment, resize and normalize the image
#ret存储经过数增强后的各类数据
ret = {'image': inp}
gt_det = {'bboxes': [], 'scores': [], 'clses': [], 'cts': []}#这里将ann中的数据转换到gt_det中存储
#gt_det为centerNet的数据标注格式
#在对图片进行数据增强后,对对应的雷达点也要相应调整位置
if opt.pointcloud:
pc_2d, pc_N, pc_dep, pc_3d = self._load_pc_data(img, img_info,
trans_input, trans_output, flipped)
#这些参数的意义:
ret.update({ 'pc_2d': pc_2d,
'pc_3d': pc_3d,
'pc_N': pc_N,
'pc_dep': pc_dep })
#以上获得了所有数据,通过_init_ret将所有数据向量重整到与head输出格式相同,以进行loss计算
self._init_ret(ret, gt_det)
calib = self._get_calib(img_info, width, height)
# get velocity transformation matrix,因为这些雷达点都是相对于全球坐标下的坐标
if "velocity_trans_matrix" in img_info:
velocity_mat = np.array(img_info['velocity_trans_matrix'], dtype=np.float32)
else:
velocity_mat = np.eye(4)
num_objs = min(len(anns), self.max_objs)
for k in range(num_objs):
ann = anns[k]
cls_id = int(self.cat_ids[ann['category_id']])
if cls_id > self.opt.num_classes or cls_id <= -999:
continue
bbox, bbox_amodal = self._get_bbox_output(
ann['bbox'], trans_output, height, width)
if cls_id <= 0 or ('iscrowd' in ann and ann['iscrowd'] > 0):
self._mask_ignore_or_crowd(ret, cls_id, bbox)
continue
self._add_instance(
ret, gt_det, k, cls_id, bbox, bbox_amodal, ann, trans_output, aug_s,
calib, pre_cts, track_ids)
if self.opt.debug > 0 or self.enable_meta:
gt_det = self._format_gt_det(gt_det)
meta = {'c': c, 's': s, 'gt_det': gt_det, 'img_id': img_info['id'],
'img_path': img_path, 'calib': calib,
'img_width': img_info['width'], 'img_height': img_info['height'],
'flipped': flipped, 'velocity_mat':velocity_mat}
ret['meta'] = meta
ret['calib'] = calib
#--------------------
return ret #ret返回所有与数据集有关的字典信息ret{img, radar_pc, meta, calib...},所有的这些数据后面要经过dataloader处理