Ŀ�����㷨
�����ѧĿ��������㷨,��Ҫ��Ϊ��ͳ��Ŀ���ⷽ���ͻ������ѧϰ��Ŀ�����㷨,�����¼��һЩ�������㷨���ܡ���ͼ��Ŀ�����㷨�ķ�չ����
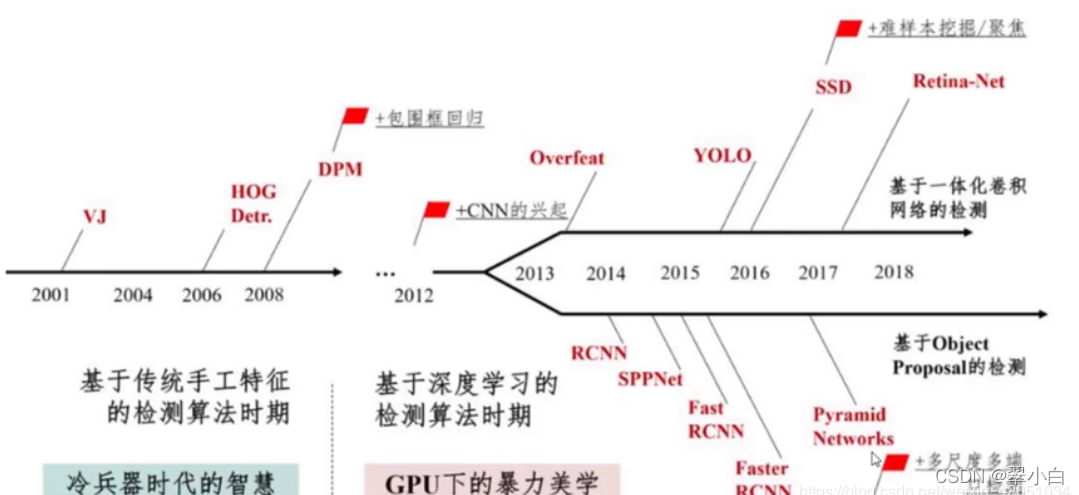
��ͳĿ���ⷽ��
��������:����ѡ��C>������ȡ�C>������
�١�VJ(Viola-Jones)
Viola-Jones��������㷨����˵�Ƿdz������һ���㷨,���д�����������о�����,������Ϥ�˽�����㷨,Viola-Jones�㷨��2001���CVPR�����,��Ϊ���Ч�����ٵļ�⼴ʹ������Ҳ��Ȼ���㷺ʹ�á�����Լ������(���ɫ�ָ�)��������״�ʵ����������ʵʱ��⡣
����㷨�������¼�����Ҫ�IJ���:
1������Haar ��������������������;
Haar����:��һ�ַ�ӳͼ��ĻҶȱ仯��,���ط�ģ�����ֵ��һ��������
2��������һ�ֳ�Ϊ����ͼ�������,���һ��ڻ���ͼ��,���Կ��ٻ�ȡ���ֲ�ͬ�ľ�������;
3������Adaboost �㷨����ѵ��;
4�������㼶��������
����:�������ڼ��,�鿴ͼ�������п��ܵ�λ�úͱ���,�ж��Ƿ��д��ڰ�������
�ڡ�HOG+SVM
HOG����˼��:���ֲ�������ݶȺͱ�Ե������Ϣ�õ����������ľֲ�����,HOG�ܽϺõIJ����ֲ���״��Ϣ,�Լ����Լ���ѧ�ı仯�кܺõIJ����ԡ�
����:����ͼ��C>��ȡHOG�����C>ѵ��SVM�������C>����������ȡĿ��������з����жϨC>��ȡHOG�����C>������
�ۡ�DPM(Deformable Part-based Model)�Ǿ����㷨��չ�۷塣
VOC07��08��09����ļ��ھ���DPM��ѭ���ֶ���֮���ļ��˼��,ѵ���Ŀ�����ѧϰһ����ȷ�ķֽ����ķ���,�����ɿ����ǶԲ�ͬ�����ļ��ļ��ϡ���⡰������ ��������Կ����Ǽ�����Ĵ��ڡ������ͳ��ֵȲ���������,�����������������Ƶı��ֽ�Ϊ����ͷ����֫�����ɵȲ����ļ�����⡣
����:����DPM����ͼ�C>������Ӧͼ�C>ʹ��SVM����Ӧͼ���з���C>������ѡ�����ֲ����ʶ��
�������ѧϰ��Ŀ���ⷽ��
?One-stage(YOLO��SSDϵ��)
����Ҫregion proposal��,ֱ�Ӳ�������������ʺ�λ������ֵ,�������μ�⼴��ֱ�ӵõ����յļ����,������Ÿ���ļ���ٶ�,�������Դﵽʵʱ�Ե�Ҫ���ε�Ŀ���������ھ������ձ��Ե����Ͻε�Ŀ�����㷨��
YOLO�C>SSD�C>YOLO v2�C>YOLO v3�C>RetinaNet�C>CornerNet�C>YOLOv4
�١�YOLO(2015�����)��һ��һ�廯�ľ����������㷨
YOLO�ڼ���ٶ������ż��������,������˻������ѧϰ��Ŀ�����������ٶ��ϵ�ʹ�㡣�㷨��GPU���ٶȿ��Դﵽ45֡/s,���ٰ汾���Դﵽ155֡/s��
�������:
-
����һ������ͼ��,���Ƚ�ͼ��ָ��7*7������
-
ÿһ������,����Ԥ��2���߿�(�߿��λ��(x,y,w,h),Ŀ�����ŶȺͶ������ϵĸ���)
-
������һ����Ԥ�����Ԥ��772��Ŀ�괰��,������ֵȥ��ִ�жȱȽϵ͵�Ŀ�괰��,�����NMSȥ�����ര�ڡ�
�ŵ�:
-
�ٶȿ�:��Ŀ��������ֱ����Ϊһ���ع�����,����ļӿ��˼����ٶȡ�
-
�������ȫ����Ϣ:������Ԥ��ÿһ��Ŀ�괰�ڵ�ʱ��ʹ�õ���ȫ����Ϣ,���Ը��ӳ�ֵ�����ÿ��ͼ��������Ĺ�ϵ��
-
ѧ������ķ�������:��YOLO����Ȼͼ������ѵ��,YOLO���ֵ����ܱ�DPM��RCNN��֮ǰ��������ϵͳҪ�úܶࡣ��ΪYOLO����ѧϰ���߶ȷ���������,�Ӷ�Ǩ�Ƶ���������
ȱ��:
-
���ȵ�:ͼ����7*7�Ĵֲ�������ع�,��λ���Ǻܾ�,���¼��ľ��Ƚϵ͡�
-
����ߴ�̶�:�����Ϊȫ���Ӳ�,����ڼ��ʱ,YOLOѵ��ģ��ֻ֧����ѵ��ͼ����ͬ������ֱ���,�����ֱ�����Ҫ���ųɴ˹̶��ֱ��ʡ�
-
ռ�Ƚ�С����Ҫ��Ŀ����Ч������:��Ȼÿ�����ӿ���Ԥ��B��bounding box,��������ֻѡ��IOU��ߵ�bounding box��Ϊ���������,��ÿ���������ֻԤ���һ�����塣������ռ���������С,��ͼ���а�����Ⱥ����Ⱥʱ,ÿ�����Ӱ����������,��ȴֻ�ܼ�������һ����
�ڡ�SSD(2015�����)
���㷨������YOLO�ٶȿ��RPN��λȷ���ŵ�,������RPN�Ķ�ο����ڼ���,���ڶ���ֱ��ʵ�����ͼ�Ͻ��м�⡣SSD����VOC07��ȡ���˽ӽ�Faster RCNN��ȷ��,�ﵽmAP=72%,ͬʱ�������˺ܺõļ���ٶ�(58֡/s)
SSD���������ȡ��one stage��˼��,�Դ������ٶ�,����������������Faster RCNN�е�anchors˼��,�������������ֲ���ȡ�����μ���߿�ع�ͷ������,�ɴ˿�����Ӧ���ֳ߶�Ŀ���ѵ���ͼ������
�㷨����:
1)����һ��ͼƬ,�������뵽Ԥѵ���õķ�������������ò�ͬ��С������ӳ��;
2)��ȡconv4_3,conv7,conv8_2,conv9_2,conv10_2,conv11_2���feature map,Ȼ��ֱ�����Щfeature map�������ÿһ���㹹��6����ͬ�߶ȴ�С��bbox,Ȼ��ֲ����м��ͷ���,���ɶ��bbox;
3)����ͬfeature map��õ�bbox�������,����NMS(�Ǽ���ֵ����)���������Ƶ�һ�����ص����߲���ȷ��bbox,�������յ�bbox����(�������)
�ۡ�YOLO v2(��Ҫ����YOLO�ϸĽ�)
1)batch normalization:�����е�conv�����BN�ܹ���������õ�����,ͬʱ���������һЩ������ʽ��regularization,���ҿ���ȥ����ֹoverfitting��dropout���������ֹ���ϡ�
2)High resolution classifier:YOLO��224224���ӵ���448448
3)Convolutional with anchor boxes:Ԥ��ƫ��(offsets)������ֱ��Ԥ������(coordinates)�ܹ�������,�������������ѧϰ,����ȥ��ȫ���Ӳ�,����anchor boxesԤ��bounding box
4)Direct location prediction:Լ��λ��Ԥ��,������������Ͻǵ��λ��ƫ��
5)Fine-grained feature:�������,������һ��passthrough layer��һ��earlier layer at 2626 resolution���ӵ���ĩ�˵�1313��feature map�ϡ��������1%���ܡ�
�ܡ�YOLO v3
��Ҫ����:��YOLO v2�����˸�ϸ����Ƶ���,�������������һ�����������һ���������,�ڱ�֤�ٶȵ�ǰ��������˾��ȡ�
�Ľ���:
1)���õ���������:Darknet19->Darknet53����ԪЧ�ʵĻ�����,�ٶ���������
2)���õĶ�߶ȡ�
3)��������ϲ���,���Ը��õļ��СĿ�ꡣ
4)����9��anchor boxes,ʹ��СĿ��Ͷ�����õ��˸��õĽ����
5)������softmax,���Dz���һ�����ν�����,�������Ը��õ�Ӧ����һ��С���������ص�ʱ�����⡣YOLOv3��ʹ��softmax��ÿ������з���,��Ҫ����������:
(1)softmax�ɱ������Ķ��logistic���������,��ȷ�ʲ����½�;
(2)softmaxʹ��ÿ�������һ�����(�÷���ߵ�һ��),������open Image�������ݼ�,Ŀ��������ص�������ǩ,���softmax�������ڶ��ǩ���ࡣ
(3)������ʧ����binary cross-entropy loss
6)û��pooling��,����ʹ���˾���Ϊ2�ľ����㡣
�ݡ�RetinaNet(2017)
��Ի���һ�廯�ľ��������ڼ��ģ��ʱ����ٶȶ����Կ��ڻ���object proposal�ļ���㷨,�����侫��ȴһֱ��ѷ�ں��ߡ�2017��������۽���ʧ����(Focal Loss)��,ͨ����������ѵ���м���������ѧϰȨ��,����ʹ������������ġ��۽����Ͷ�ѧϰ���������·���ʱone stage�ļ�������ھ��������˺ܴ�ĸ��ơ�
�ޡ�CornerNet:�Խǵ�(Ŀ������Ͻǵ�����½ǵ�)����λ�ͷ���Ŀ��,�����˻���anchor free��keypoint based�˳�
Anchor box����ȱ��:��Ҫһ��dz����anchor boxes;anchor boxes��ʹ�����������೬���������ѡ��
CornerNet����:������߽����Ϊһ�Թؼ���(���߽������ϽǺ����½�)����������ͨ��Ԥ��������ͼ����ʾ��ͬ�������Ľǵ�λ��,һ���������Ͻ�,��һ���������½ǡ����绹Ԥ��ÿ�����Ľǵ�Ƕ������,ʹ������ͳһĿ��������ǵ�Ƕ��֮��ľ����С��Ϊ�˲��������ܵı߽��,���绹Ԥ��ƫ�����������ǵ�λ�á�ͨ��Ԥ�����ͼ,Ƕ���ƫ��,���Ӧ��һ���ĺ����㷨��������յı߽��
?Two-stage(Faster RCNNϵ��)
������ѡ���� CNN������>������� λ�þ���
����Object Proposals�ļ���㷨,ͨ��һ�����������������Ŀ�������,����ȡ����CNN��������,��ѵ������ʱ,����Ҫѵ����������,��һ��ʱѵ��RPN����,�ڶ�����ѵ��Ŀ������������硣
**�ص�:**�����ȷ�ȸ�,�ٶ����One-Stage��
RCNN�C>SPP-Net�C>Fast RCNN�C>Faster RCNN�C>Mask RCNN
�١�RCNN(CVPR2014)
ͻ���˴�ͳ��Ŀ�����㷨��˼��,Ϊ�����ѧϰ��Ŀ����������״γɹ�ͻ��,��Ŀ������������������ѧϰ�ĸ��ٷ�չʱ�ڡ�RCNN��VOC07�����ݼ���ȡ���˾���Ч��,mAP��33.7%������58.5%��
**ȱ��:**ѵ��ʱ��ε�,�ȽϷ����ͺ�ʱ:�ڸ��ܶȺ�ѡ�����Ľ���������ȡ
RCNNʹ��SS��ȡ��ѡ����,���ö��������ʶ��ķ���:
1������ͼƬ,��ͼƬ����ȡ2K���������ĺ�ѡ����(Object Proposal)
2����ÿ����ѡ�������þ���������(AlexNet)��ȡ��������
3������SVM���з���,��ͨ��һ��bounding box regression������Χ��Ĵ�С��
�ڡ�SPP-Net
RCNN����������ȫ���Ӳ�Ĵ���,ֻ�ܽ��̶ܹ���С��ͼ������,�������е�����ͼ�ᱻresize���̶��Ĵ�С,����һЩĿ����ɼ��ϻ��䡣
SPPNet(2014):�������CNN������ȡ����ʱ����ͼ��ߴ�̶������⡣�ھ������ȫ���Ӳ�֮�����ӿռ�������ػ���(SPP),�ڲ���ʧ���ȵ�ǰ����,ROI����ֱ�Ӵ�����ͼ��ȡ,��RCNN�ļ���ٶ�������38��,��Ч��������������������⡣
ȱ��:CNN�еľ���������ʱʱ���ܼ���ѵ���ġ�����ȻʱRCNN�Ŀ��,��������Ҫ�Ķ˵��˵ļ���ܶࡣ
�ۡ�Fast RCNN(2015)���RCNN��SPPNet���ŵ�
���µ�:
1)�����һ���������SPP Layer��ΪROI Pooling Layer;
2)��������ʧ����:��ѡ���������ʧ��λ�ûع���ʧ
3)ʵ������������ͬʱ,��Ŀ�����Ͱ�Χ��ع��ͬ��ѵ����
ѵ���ٶ���RCNN��9��,����ٶ���RCNN��200������VOC2007���ݼ���,Fast RCNN��mAP��RCNN��58.5%������70%��
����:
1)����һ�Ŵ�����ͼ��;
2)��ȡ��ѡ����:����SS�㷨������ͼ������ȡ����ѡ����,������Щ��ѡ�����տռ�λ�ù�ϵӳ�䵽���ľ���������;
3)�����һ��:���ھ����������ϵ�ÿ����ѡ�������ROI Pooling����,�õ��̶�ά�ȵ�����;
4)������ع�:����ȡ������������ȫ���Ӳ�,Ȼ����softmax���з���,�Ժ�ѡ�����λ�ý��лع顣
�ܡ�Faster RCNN
Faster rcnn�Ǻο����ȴ�����2015�����Ŀ�����㷨,���㷨��2015���ILSVRV��COCO�����л�ö����һ�����㷨��fast rcnn�����������RPN��ѡ�������㷨,ʹ��Ŀ�����ٶȴ����ߡ�
�ݡ�Mask RCNN
��һ��ʵ���ָ��㷨,����ɶ�������,����Ŀ����ࡢĿ���⡢����ָʵ���ָ������̬ʶ��ȡ����кܺõ���չ�Ժ������ԡ�

���������㷨������ȱ��,���ڴ�ͳͼ�����ij�������㷨�ٶȽϿ�,����ȷ�ʽϵ�,�������ѧϰ�ij�������㷨�ٶ�����,����ȷ�ʺܸ�,����Ŀǰ������������������,�������ѧϰ�ij�������㷨��Ϊ�����ļ���㷨��
�����:https://blog.csdn.net/weixin_42051034/article/details/104463850