一种(简单的)基于心情的音乐推荐系统
项目完整源码:https://github.com/cdfmlr/murecom-verse-1
你什么时候听音乐?快乐的时候,悲伤的时候,兴奋的时候,失落的时候…时时刻刻。
你听什么音乐?欢快的音乐,治愈的音乐,浪漫的音乐,伤感的音乐…因时而异,因心情而定。
传统的推荐系统做了什么?忠实记录你历史上任意时刻的所有听歌记录,拿去和别的用户比较,推荐他们喜欢的歌给你。。。不管你现在什么心情,不管你想听什么类型。这种东西往往不太懂我。
我是个情绪复杂的人,我早上醒来可能任沉浸在梦里,异常低落,我需要 Sasha Sloan;开始做事情要让脑子活过来,我需要 ZUTOMAYO;中午的疲惫下让 Evan Call 调整心情;午后的阳光里让 Bach 带我创作;日落时分的脑子被思念塞满,这时的 Halsey 也许不错;深夜凉爽的霓虹散发迷离的美,这时的爵士与嘻哈绝配,给我来一段 Nujabes。
不同时刻,不同场景,不同心情,给你听不同的歌,这就是一个基于心情的推荐系统。
(我认为时刻与场景作用于心情从而影响人,所以基于心情,而不是场景或时刻等外在因素)
想法
如何基于心情推荐?
首先,我们需要知道一首歌对应什么心情――(也许是)最简单的方法:分析歌名、歌词、以及热心网友的精彩评论。从文本获取情感,可以用比较简单的实现:每个词会对应一些既定的情感,只要当地新华书店购买一本「情感词典」就容易获取一个句子的情感。
然后,我们需要知道用户目前的心情。可以让用户输入一段话、一首诗、一篇文学大作。析文本中的情感,和前面处理歌曲如出一辙。“但我就听个歌诶,你还要让我写作,我讨厌语文,我不是诗人。”那么,对于这种不浪漫的用户,我们假设他情感比较直接,开心还是忧伤,全写在脸上,一看便知――考虑从人像识别情感。
最后,用户的心情与数据库中歌曲的心情一比较,找出最接近的,推荐出来,完成。
设计
想法很简单,但能实现嘛?先看看我们需要做什么。
- 音乐数据(包括歌词、评论等):我们可以从网易云音乐获取:网易云拥有“丰富”的曲库,“完善”的歌词,“精彩”的评论;
- 文本 => 情感:前面提到需要一个情感词典,大连理工大学的大佬们做了这样的一个情感词汇本体词典,心怀感激地拿来用:http://ir.dlut.edu.cn/info/1013/1142.htm
- 图像 => 情感:也有大佬做过这个:Context Based Emotion Recognition using Emotic Dataset,有开源的实现,可以心怀感激地拿来用:https://github.com/Tandon-A/emotic
- 心情比较、推荐:KNN,这个简单,Sk-learn 随便做,当然也是心怀感激地。
所以说这个系统还是比较简单的。
在开始实现之前,我们还需要讨论一点细节。大连理工情感词典(以下简称 DLUT)把情感分成了 7 大类,21 小类,而那个外国的图像情感识别(以下简称 Emotic) 把情感分成了 26 类。我们需要胶合一下,把二者对应起来。这里我们选择以 DLUT 为主,将 Emotic 的分类映射到 DLUT:
| DLUT | Emotic | |||
|---|---|---|---|---|
| 编号 | 情感大类 | 情感类 | 例词 | emotion categories with definitions |
| 1 | 乐 | 快乐(PA) | 喜悦、欢喜、笑眯眯、欢天喜地 | 17. Happiness: feeling delighted; feeling enjoyment or amusement 20. Pleasure: feeling of delight in the senses |
| 2 | 安心(PE) | 踏实、宽心、定心丸、问心无愧 | 6. Confidence: feeling of being certain; conviction that an outcome will be favorable; encouraged; proud 19. Peace: well being and relaxed; no worry; having positive thoughts or sensations; satisfied | |
| 3 | 好 | 尊敬(PD) | 恭敬、敬爱、毕恭毕敬、肃然起敬 | 13. Esteem: feelings of favourable opinion or judgement; respect; admiration; gratefulness |
| 4 | 赞扬(PH) | 英俊、优秀、通情达理、实事求是 | 14. Excitement: feeling enthusiasm; stimulated; energetic | |
| 5 | 相信(PG) | 信任、信赖、可靠、毋庸置疑 | 4. Anticipation: state of looking forward; hoping on or getting prepared for possible future events 12. Engagement: paying attention to something; absorbed into something; curious; intereste | |
| 6 | 喜爱(PB) | 倾慕、宝贝、一见钟情、爱不释手 | 1. Affection: fond feelings; love; tenderness | |
| 7 | 祝愿(PK) | 渴望、保佑、福寿绵长、万寿无疆 | 4. Anticipation: state of looking forward; hoping on or getting prepared for possible future events | |
| 8 | 怒 | 愤怒(NA) | 气愤、恼火、大发雷霆、七窍生烟 | 2. Anger: intense displeasure or rage; furious; resentful |
| 9 | 哀 | 悲伤(NB) | 忧伤、悲苦、心如刀割、悲痛欲绝 | 21. Sadness: feeling unhappy, sorrow, disappointed, or discouraged 23. Suffering: psychological or emotional pain; distressed; an- guished 22. Sensitivity: feeling of being physically or emotionally wounded; feeling delicate or vulnerable |
| 10 | 失望(NJ) | 憾事、绝望、灰心丧气、心灰意冷 | 5. Aversion: feeling disgust, dislike, repulsion; feeling hate 21. Sadness: feeling unhappy, sorrow, disappointed, or discouraged | |
| 11 | 疚(NH) | 内疚、忏悔、过意不去、问心有愧 | 25. Sympathy: state of sharing others emotions, goals or troubles; supportive; compassionate | |
| 12 | 思(PF) | 思念、相思、牵肠挂肚、朝思暮想 | 15. Fatigue: weariness; tiredness; sleepy | |
| 13 | 惧 | 慌(NI) | 慌张、心慌、不知所措、手忙脚乱 | 18. Pain: physical suffering 3. Annoyance: bothered by something or someone; irritated; impa- tient; frustrated |
| 14 | 恐惧(NC) | 胆怯、害怕、担惊受怕、胆颤心惊 | 16. Fear: feeling suspicious or afraid of danger, threat, evil or pain; horror | |
| 15 | 羞(NG) | 害羞、害臊、面红耳赤、无地自容 | 11. Embarrassment: feeling ashamed or guilty | |
| 16 | 恶 | 烦闷(NE) | 憋闷、烦躁、心烦意乱、自寻烦恼 | 9. Disquietment: nervous; worried; upset; anxious; tense; pres- sured; alarmed 8. Disconnection: feeling not interested in the main event of the surrounding; indifferent; bored; distracted |
| 17 | 憎恶(ND) | 反感、可耻、恨之入骨、深恶痛绝 | 5. Aversion: feeling disgust, dislike, repulsion; feeling hate 7. Disapproval: feeling that something is wrong or reprehensible; contempt; hostile | |
| 18 | 贬责(NN) | 呆板、虚荣、杂乱无章、心狠手辣 | 3. Annoyance: bothered by something or someone; irritated; impa- tient; frustrated | |
| 19 | 妒忌(NK) | 眼红、吃醋、醋坛子、嫉贤妒能 | 26. Yearning: strong desire to have something; jealous; envious; lust | |
| 20 | 怀疑(NL) | 多心、生疑、将信将疑、疑神疑鬼 | 10. Doubt/Confusion: difficulty to understand or decide; thinking about different options | |
| 21 | 惊 | 惊奇(PC) | 奇怪、奇迹、大吃一惊、瞠目结舌 | 24. Surprise: sudden discovery of something unexpected |
(这个映射我随便写的,有待商榷)
没有任何难点,直接撸代码。
实现
音乐数据
在 ncm 目录下,我们从网易云获取了一些数据:
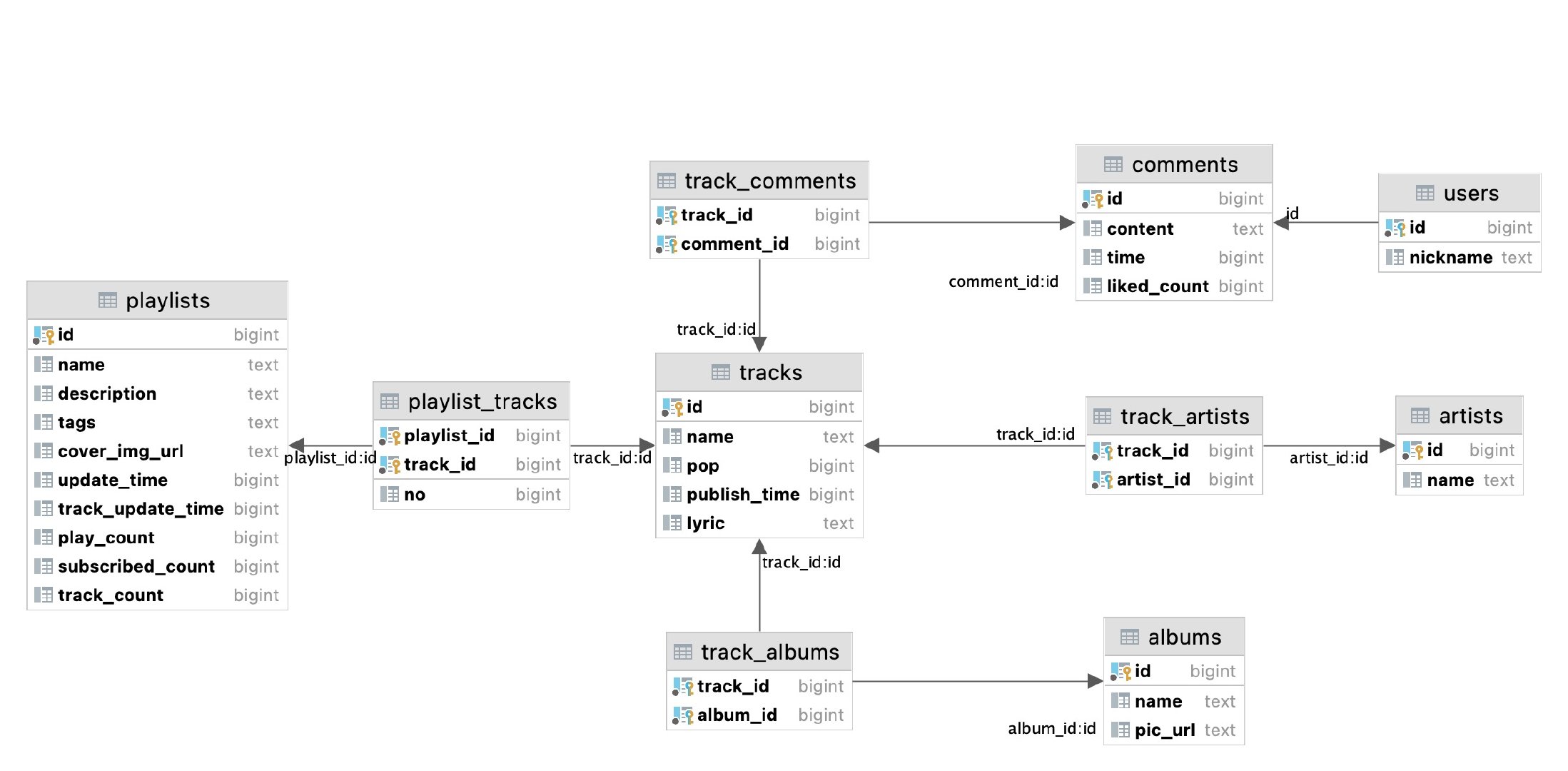
和我们上一篇文章获取 Spotify 的数据不同,网易云有个特点――歌单里面曲目多,所以我们获取了不到 1 万张列表,就得到了 20 万首歌曲,100 万条热门评论。
ncm=# select count(*) from playlists;
8426
ncm=# select count(*) from tracks;
219038
ncm=# select count(*) from comments;
1052112
获取数据的过程如下图所示:
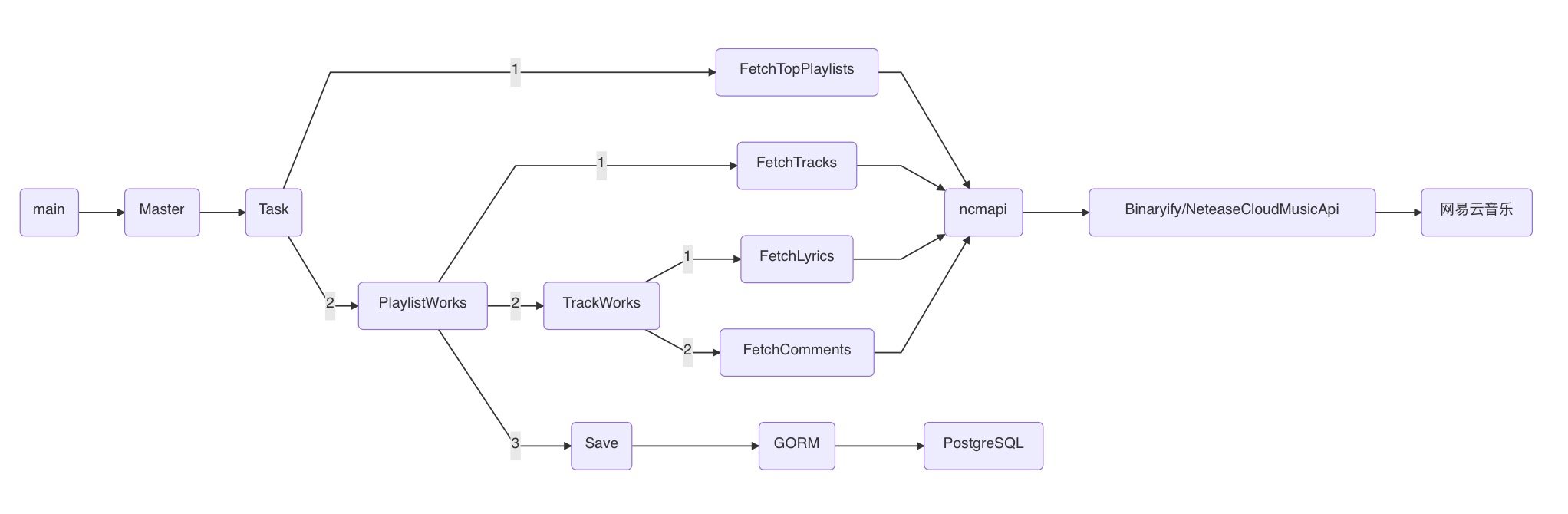
(在 git commit message 中有开发每一步更详细的说明)
这里使用了大量 Master/Worker 模式:
| Master | Worker | Worker工作 |
|---|---|---|
| main | Master | 按照配置,启动 Task |
| Master | Task | 一个 Task 完成一组特定分类的播放列表收集 |
| Task | FetchTopPlaylists | 获取播放列表 |
| Task | PlaylistWorks | 完善一个播放列表及其中曲目的完整信息,并保存 |
| PlaylistWorks | FetchTracks | 获取一个播放列表中的全部曲目 |
| PlaylistWorks | TrackWorks | 完善一首歌曲的完整信息 |
| TrackWorks | FetchLyrics | 获取一首歌的歌词 |
| TrackWorks | FetchComments | 获取一首歌的热门评论 |
这些各种 Worker 都是一个单独的 Goroutine,全在并发运行,靠 channel 传数据。
以及一些 C/S 模式:
| Client Caller | Server | 工作 |
|---|---|---|
| PlaylistWorks | DB(GORM):PostgreSQL | 保存数据 |
| FetchXxx | ncmapi | 完成网络请求,获取数据 |
数据库和网络作为数据入口/出口,以 C/S 模式来访问,各自集中维护自己的链接池。
(ncm 是个实验性的程序,效率并不高。我只是想尝试在编程时去面向对象化,尝试回归比较纯粹的数据驱动、面向过程、函数式,就像 Rob Pike 的代码那样。)
中文文本情感分析
在 emotext 中,实现了利用大连理工大学情感本体库进行中文文本情感分析。
从 DLUT 的网站下载到情感词典:http://ir.dlut.edu.cn/info/1013/1142.htm
它给的是 Excel 表格,为了方便,我们将其重新导出为 CSV 格式,得到的文件形如:
词语,词性种类,词义数,词义序号,情感分类,强度,极性,辅助情感分类,强度,极性
脏乱,adj,1,1,NN,7,2,,,
糟报,adj,1,1,NN,5,2,,,
战祸,noun,1,1,ND,5,2,NC,5,2
招灾,adj,1,1,NN,5,2,,,
接下来,要把这个大表读到程序里。我们把「词语 + 情感」视为一个 Word 对象,如果一个词有「辅助情感分类」则把它看成两个 Word:
class Word:
word: str
emotion: str
intensity: int # 情感强度: 分为 1, 3, 5, 7, 9 五档,9 表示强度最大,1 为强度最小。
polarity: Polarity
再写一个 Emotions 类来放所有的这些 Word 即对应情感。用一个 self.words dict,把每种情感的 Word 分开放。
class Emotions:
def __init__(self):
self.words = {emo: [] for emo in emotions} # {"emotion": [words...]}
with open('/path/to/dict.csv') as f:
self._read_dict(f)
现在给定一个词汇,只需在表中查找,若存在,就到的了情感与对应强度(Word 对象);若不存在,就认为这个词没有感情,直接忽略。
def _find_word(self, w: str) -> List[Word]:
result = []
for emotion, words_of_emotion in self.words.items():
ws = list(map(lambda x: x.word, words_of_emotion))
if w in ws:
result.append(words_of_emotion[ws.index(w)])
return result
而给定一个句子,则先进行分词,取出句子中的前 20 个关键词,做前面的查表分析,将所有得到的关键词情感累加,就得到了句子的情感:
def emotion_count(self, text) -> Emotions:
emotions = empty_emotions()
keywords = jieba.analyse.extract_tags(text, withWeight=True)
for word, weight in keywords:
for w in self._find_word(word):
emotions[w.emotion] += w.intensity * weight
return emotions
如果你不喜欢看文字叙述,也不爱阅读代码,那么可以数学一下。这里我们使用 TF-IDF 算法抽取关键词:
- TF(term frequency, 词频):字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降: t f ( t , d ) = f t , d ∑ t ′ ∈ d f t ′ , d {\displaystyle \mathrm {tf} (t,d)={\frac {f_{t,d}}{\sum _{t'\in d}{f_{t',d}}}}} tf(t,d)=∑t′∈d?ft′,d?ft,d??
- IDF(inverse document frequency, 逆向文件频率):由总文件数目除以包含该词语之文件的数目,再将得到的商取对数:$ \mathrm{idf}(t, D) = \log \frac{N}{|{d \in D: t \in d}|}$,这里 D D D 使用默认的常见词典。
- TF-IDF 权重就是把两个乘起来,达到过滤掉常见的词语,保留重要的词语的目的: t f i d f ( t , d , D ) = t f ( t , d ) ? i d f ( t , D ) {\displaystyle \mathrm {tfidf} (t,d,D)=\mathrm {tf} (t,d)\cdot \mathrm {idf} (t,D)} tfidf(t,d,D)=tf(t,d)?idf(t,D)
- 将词语按照得到的 tfidf 权重从大到小排序,取前 20 个作为关键词。
- 我们认为关键词最终的情感 E t E_t Et? 为由该词语的情感强度 I t I_t It? (查字典得到)以及它的 TF-IDF 权共同决定: E t = I t ? t f i d f ( t , d , D ) \mathrm{E}_t=I_t \cdot \mathrm {tfidf} (t,d,D) Et?=It??tfidf(t,d,D)
- 那么文本 d d d 最终的总情感为所有关键词情感的叠加:
E ( d ) = ∑ t ∈ k e y ( d , D ) I t ? t f i d f ( t , d , D ) E(d)=\sum_{t \in \mathrm{key}(d, D)}I_t\cdot \mathrm {tfidf} (t,d,D) E(d)=t∈key(d,D)∑?It??tfidf(t,d,D)
这里我们并没有分析句子的连续特征,只是简单的用关键词分析,但对于分析常见的,不是藏的非常深的句子已经可以用了。
>>> t = '后悔也都没有用 还不如一切没有发生过 不过就是又少一个诗人 换一个人沉迷你的笑'
>>> r = Emotext.emotion_count(t)
>>> r.emotions = softmax(r.emotions)
>>> e = Emotion(**r.emotions)
Emotion(PA=0.0, PE=0.0, PD=0.0, PH=0.0, PG=0.2428551306285703, PB=0.0, PK=0.0, NA=0.0, NB=0.0, NJ=0.41260819965515805, NH=0.175202571704109, PF=0.0, NI=0.0, NC=0.0, NG=0.0, NE=0.1693340980121628, ND=0.0, NN=0.0, NK=0.0, NL=0.0, PC=0.0)
这里我们获取到了 NJ、PG、NH、NE 的情感,即:失望,相信,内疚,和烦闷。差不多,至于文字下埋藏的爱意,我们目前这种方式并不能让计算机理解,这是个缺陷。
注意到这个例子中,我们在算法外面做了 softmax,将情感权重值映射为各种情感的概率。但我们没有在算法内部进行 softmax,是因为在下面的曲目情感标注的过程中,对一首歌,我们需要处理多个文本(歌名、歌词、多条评论),其中可能有的文本情感丰富饱满,而有的干涩无情。如果在算法内部做 softmax,则它们的情感总量都会被拉到 1,我们不想要这种平均主义。我们要保留每句话的情感真实大小,情感大的重要,没感情的忽略。所以我们要在处理过程中保留每一个文本的绝对大小,最后累加完成后再做 softmax。
曲目情感标注
接下来,利用刚才实现好的 emotext 文本情感分析工具,我们就可以分析曲目情感。
对于一首歌曲,将其歌名、歌词以及热门评论送入 emotext 进行情感分析:
def track_emotion(t: Track):
texts = [t.name, t.lyrics] + [c.content for c in t.comments]
weights = text_weights(t.name, t.lyrics, t.comments)
for text, weight in zip(texts, liked_weights):
emo_result = Emotext.emotion_count(text)
for k, v in emo_result.emotions.items():
track_emotions[k] += v * weight
return softmax(track_emotions)
其中的weights 是文本所占的权重:
- 对于评论 c c c,我们认为点赞数 L c Lc Lc 越多,说明评论质量越高,所以权重 w c w_c wc? 和点赞数挂钩: w c = log ? ( L c + 1 ) w_c=\log (L_c + 1) wc?=log(Lc?+1)
- 对于歌词 l l l,这是歌曲创作者情感的凝结,权重应该比任何评论更高: w l = log ? ( ∑ L c ? 10 + 2 ) w_l=\log(\sum L_c\cdot 10 + 2) wl?=log(∑Lc??10+2)
- 对于歌名 n n n,权重应该是最高的,毕竟是名字诶: w n = log ? ( ∑ L c ? 20 + 2 ) w_n=\log(\sum L_c \cdot 20 +2) wn?=log(∑Lc??20+2)
在项目的 emotracks 子目录中实现了这些东西,遍历数据库中所有曲目,分析并写入情感信息:
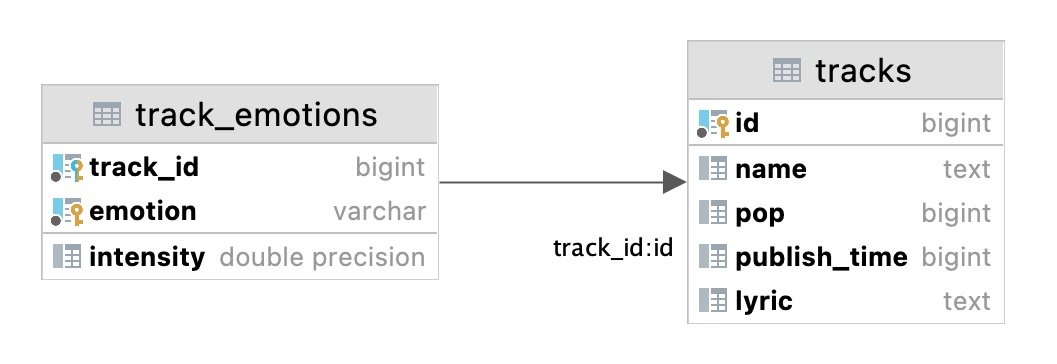
从文本进行心情音乐推荐
完成标注之后,就可以做基于情感的音乐推荐了。实现方式和我们上一篇文章里做基于音频特征的音乐推荐类似。(这个基于情感的推荐的思路,本质上来说,只是另外一种基于内容的推荐 CBF。)
在那篇文章中,我们分析音乐频谱,对每首歌得到一个 256 维的「音乐特征向量」,将该向量交给一个无监督的最近邻模型,推荐出最相似的歌。
而现在,在 recommend-text.ipynb 里,我们那标注好的 21 种情感作为曲目的「情感特征向量」:
Emotion = namedtuple('Emotion', emotext.emotions)
def emotion_vector(emotions: List[TrackEmotion]) -> Emotion:
elems = dict.fromkeys(emotext.emotions, 0.0)
elems.update({x.emotion: x.intensity for x in emotions})
return Emotion(**elems)
然后就和之前同样的,建立数据集,训练 KNN 模型。
data = { 'ids': [], 'emo': [] }
# query db
for t in session.query(Track).order_by(Track.pop.desc(), Track.id):
data['ids'].append(t.id)
data['emo'].append(emotion_vector(t.track_emotions_collection))
X = np.array(data)
nbrs = NearestNeighbors(
n_neighbors=10,
algorithm='ball_tree'
).fit(X)
训练完就可以让用户输入文本,分析其中情感,送入模型中,找出最近的邻居,即得到了推荐的曲目。
def recommend_from_text(text: str):
"""给文本,算情感,找近邻,作推荐
:return: (emotion, distances, tracks): 计算得到的 text 情感,和推荐结果:距离与曲目
"""
# emotext
r = Emotext.emotion_count(text)
e = Emotion(**softmax(r.emotions))
# recommend
distances, indices = nbrs.kneighbors([e], 10)
# result tracks
tracks = []
for i in range(len(indices[0])):
tid = data['ids'][indices[0][i]]
t = session.query(Track).where(Track.id == tid)[0]
tracks.append(t)
return e, distances, tracks
沿用前面的例子:
>>> t = '后悔也都没有用 还不如一切没有发生过 不过就是又少一个诗人 换一个人沉迷你的笑'
>>> emotion, distances, tracks = recommend_from_text(t)
>>> print_nbrs(distances, tracks)
dist=0.3137: (108983) 会有那么一天 - ['林俊杰']
dist=0.3740: (27731486) Talk Dirty (feat. 2 Chainz) - ['Jason Derulo', '2 Chainz']
dist=0.3758: (1329999687) 50 Feet - ['SoMo']
dist=0.3804: (210287) 遗憾 - ['陈洁仪']
dist=0.3808: (307018) 遗憾 - ['许美静']
dist=0.3980: (25650033) 遗憾 - ['李代沫']
dist=0.4004: (424262521) Rolling in the deep - ['廖佳琳']
dist=0.4019: (1943186) Blanc - ['Sylvain Chauveau']
dist=0.4051: (17405587) Still D.R.E. - ['Snoop Dogg', 'Dr. Dre']
dist=0.4052: (34834450) 雷克雅未克 - ['麦浚龙', '周国贤']
不说推荐的有多好,起码一堆遗憾看名字就比较符合心情了。
当然,我们也可以不写小作文,直接写个关键词,也能推荐出适合心情的歌曲:

图片人物情绪识别
接下来,这个比较有意思了:拍张照片,识别心情,推荐音乐。
我们主要是做音乐推荐系统,不想深陷计算机视觉的泥沼,所以用一点开源的实现:https://github.com/Tandon-A/emotic (我 Fork 修改了一点点他的实现,并添加了一点边缘功能,作为一个 git submodule: https://github.com/cdfmlr/emotic)
大佬提供了完整的代码和训练好的模型。把代码 clone 下来,数据也下载下来。我们在 emopic 目录里堆放这些东西:
emopic
├── emotic
│ ├── Colab_train_emotic.ipynb
│ ├── README.md
│ ├── emotic.py
│ ├── ...
│ └── yolo_utils.py
├── experiment
│ └── inference_file.txt
├── models
│ ├── model_body1.pth
│ ├── model_context1.pth
│ ├── model_emotic1.pth
└── results
└── val_thresholds.npy
安装好依赖的 pytorch、opencv-python 等模块后,就可以用这个东西了:
$ python3 emotic/yolo_inference.py --mode inference --inference_file experiment/inference_file.txt --experiment_path . --model_dir ./models
(首次运行它会自己下载 YOLO 模型,可能用时较久,还有注意保持“网络通畅”)
这个东西接口有点复杂,你需要把要识别的图像绝对路径写到 experiment/inference_file.txt 里,例如:
/Path/to/imgs/26.jpg 10 10 1000 1000
它会按指示读取文件,分析处理,把结果输出到 result 目录里。
当然这个项目还有其他好几种接口,总之是不太方便使用的,我重新封装了一个给人用的接口:
def yolo_emotic_infer(image_file, verbose=False):
"""Infer on an image_file to obtain bounding boxes of persons in the images using yolo model, and then get the emotions using emotic models.
:param image_file: image file to do inference: path str or a readable IO object
:param verbose: print the result
:return: infer result: a list of bbox of a person in the image,
the categorical Emotions dict and continuous emotion dimensions.
"""
pass
这个就比较方便了:输入图片,输出结果列表:图片中的每个检测到的「人」一个对象,bbox 为人的边框坐标,cat 为离散的情感及其权重。(cont 是三种连续的情感,我们暂时用不到)
[
{
'bbox': [x1, y1, x2, y2],
'cat': {"Anger": 0.44, ...},
'cont': [5.8, 7.1, 2.1]
},
...
]
为了更方便使用,可以写一个简单的 HTTP 服务:
from aiohttp import web
async def handle(request):
data = await request.post()
img = data['img'].file
result = yolo_emotic_infer(img)
return web.json_response(result)
app = web.Application()
app.add_routes([web.post('/infer', handle)])
if __name__ == '__main__':
web.run_app(app)
这样就容易以任何地方使用这个功能了,并且保持以 Daemon 形式运行,避免反复加载模型。
例如,我们给定一张图片:

(图片来自 Pixabay: vdnhieu,标签为:女孩、伤心、肖像、沮丧、独自的、压力)
访问服务即可得到结果:
$ curl -F "img=@/test/imgs/26.jpg" http://localhost:8080/infer

(左:emotic infer 响应的结果,右:emotic2emotext 转化后的 DLUT 情感)
可以看到机器确实识别出了图中人物的 Sadness,Suffering,Fatigue 这些情感。
为了和前面的工作对接,我们在 emopic/emotic2emotext 包中实现将 Emotic 的情感转化为 DLUT 字典情感的功能。
‘刷脸’心情音乐推荐
接下来的工作,便是把这个图片人物情绪识别模块嫁接到心情音乐推荐系统上。
在 recommend-pic.ipynb 里面实现了这个。我们直接读取了 recommend-text.ipynb 里面处理好的数据集以及修炼好的模型:
data, nbrs = load_data_model('savedata/7597.json', 'savemodels/7597.joblib')
把上一节的 cURL 命令翻译成 Python 代码,访问前面写好的服务,即可提取图片的「情感特征向量」:
def emotion_from_pic(imgpath: str) -> Emotion:
emotic_result = requests.post(EMOPIC_SERVER, files={
'img': (imgpath, open(imgpath, 'rb')),
}).json()
# 总的情感
total_emotion = dict.fromkeys(emotext.emotions, 0.0)
# 人在图片中占的面积
area = lambda bbox: (bbox[2] - bbox[0]) * (bbox[3] - bbox[1])
areas = [area(p['bbox']) for p in emotic_result]
# 转成 emotext 情感,面积大的人权重大
for person, person_area in zip(emotic_result, areas):
person_emo = emotic2dlut(person['cat'], person['cont']) # 调用emotic2emotext包
weight = person_area / sum(areas)
for emo, value in person_emo.items():
total_emotion[emo] += value * weight
return Emotion(**softmax(total_emotion))
这里我们把图片中识别到的所有人物都考虑进来,并且人物占图片面积越大,就认为越重要,权重越大。
最后,封装给图片推荐音乐的功能,和前面的 recommend_from_text 非常类似:
def recommend_from_pic(imgpath: str):
"""给图片,算情感,找近邻,作推荐
:return: (emotion, distances, tracks): 计算得到的图片情感,和推荐结果:距离与曲目
"""
# get emotion
e = emotion_from_pic(imgpath)
# do recommend
distances, indices = nbrs.kneighbors([e], 10)
# result tracks
tracks = []
for i in range(len(indices[0])):
tid = data['ids'][indices[0][i]]
t = session.query(Track).where(Track.id == tid)[0]
tracks.append(t)
return e, distances, tracks
你现在就可以自己照一张照片,看看程序给你推荐什么样的音乐了。
对于前面例子那张伤心的图片,推荐结果如下:

上来就 Say Something 了,够对味吧!(淦,我先去抑郁一下再接着写)后面的大多数也都很对这个画面,记事本、空白格什么的。毕竟是网抑云的数据,这种情绪给你拿捏的很准的。
再来一个例子:

我不太懂电音,所以两首 Avicii 以及 Crazy Frog 不做评价,什么 DJ 版的也自动忽略(应该直接从数据库中把所有 DJ 版、抖音版全删了)。 另外几首 Pearl、林宥嘉、RADWIMPS、陈奕迅、TAZ 在这个场景做 BGM 都还是不错的吧,你可以把自己带入图中人物(或狗子)想象一下。只有 Hedwig’s Theme,,,似乎是机器想多了,我等麻瓜只能将其算作误推。
问题
其实,如果你尝试更多的照片,或者文本,拿去推荐,有些结果是没这么好的,甚至非常差。我试过个两小孩打游戏大笑的图片,推荐出来全是伤心情歌。。。
我觉得比较大的问题是数据,网抑云数据杂乱,质量完全没保障。我还在想有没有构建更高质量数据集的方法。但目前我手上没有这种数据。
使用 DLUT 的 21 类情感是否合理也是个问题。我完全是为了实现方便而选择这种分类的。但我认为这个情感分类不如 Emotic 的。emotic 还有 3 个连续情感值,我们甚至都没有利用到。
还有,文本情感分析的模块,我们用了最简单的古老方法,只能说可以用,效果绝对谈不上好。我想用神经网络来做,应该效果会好得多。但没有数据。
大佬训练好的 Emotic 也是不太完美的,比如我本人的照片,不管笑多开心都是所有负面情绪叠满,识别不出一点正面的情感。(它倒是准确预言了我看到结果之后的心情。)要解决这个问题也是需要数据来微调模型。但没有数据。
总之,如果你喜欢这个东西,欢迎 star、点赞吧;如果你有合适的数据或者其他改进的想法,请与我分享。
参考文献与项目
[1] Binaryify. 网易云音乐 API. github.com/Binaryify/NeteaseCloudMusicApi
[2] 徐琳宏,林鸿飞,潘宇,等.情感词汇本体的构造[J]. 情报学报, 2008, 27(2): 180-185.
[3] hiDaDeng. 中文情感分析库. github.com/hiDaDeng/cnsenti
[4] Kosti R , Alvarez J M , Recasens A , et al. Context Based Emotion Recognition using EMOTIC Dataset[J]. 2020.
[5] Tandon-A. PyTorch implementation of Emotic. github.com/Tandon-A/emotic