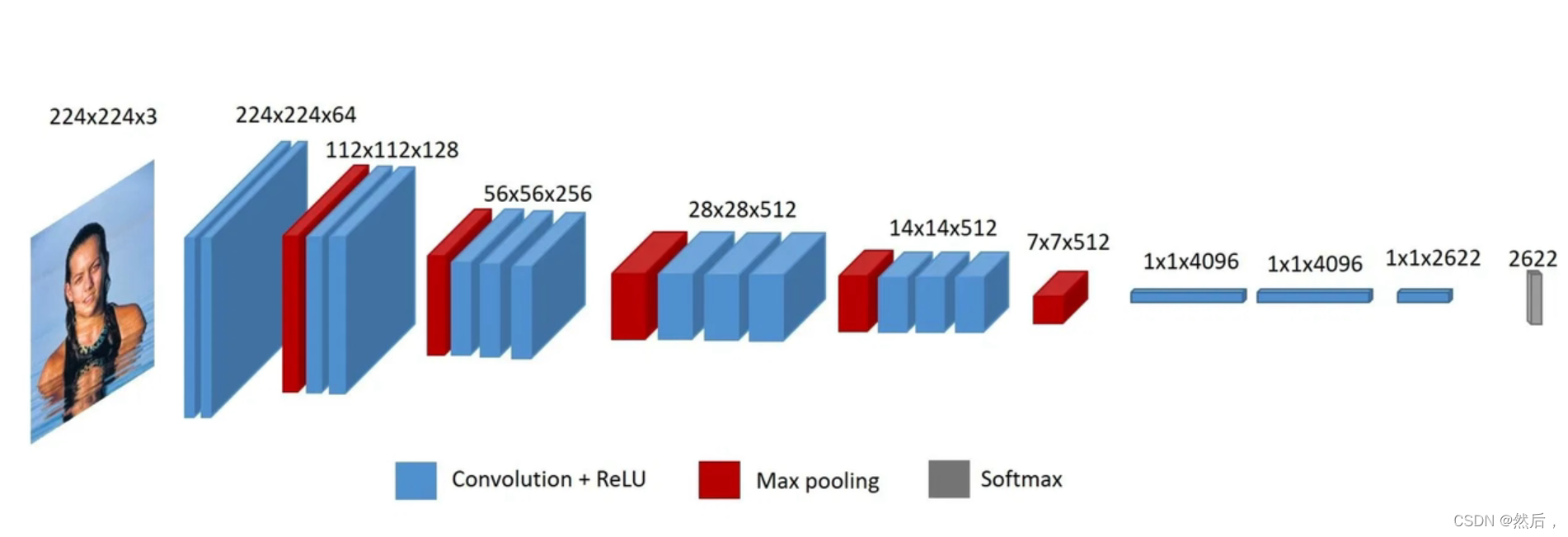
VGG2014年图像分类竞赛的亚军,定位竞赛冠军。
卷积神经网络
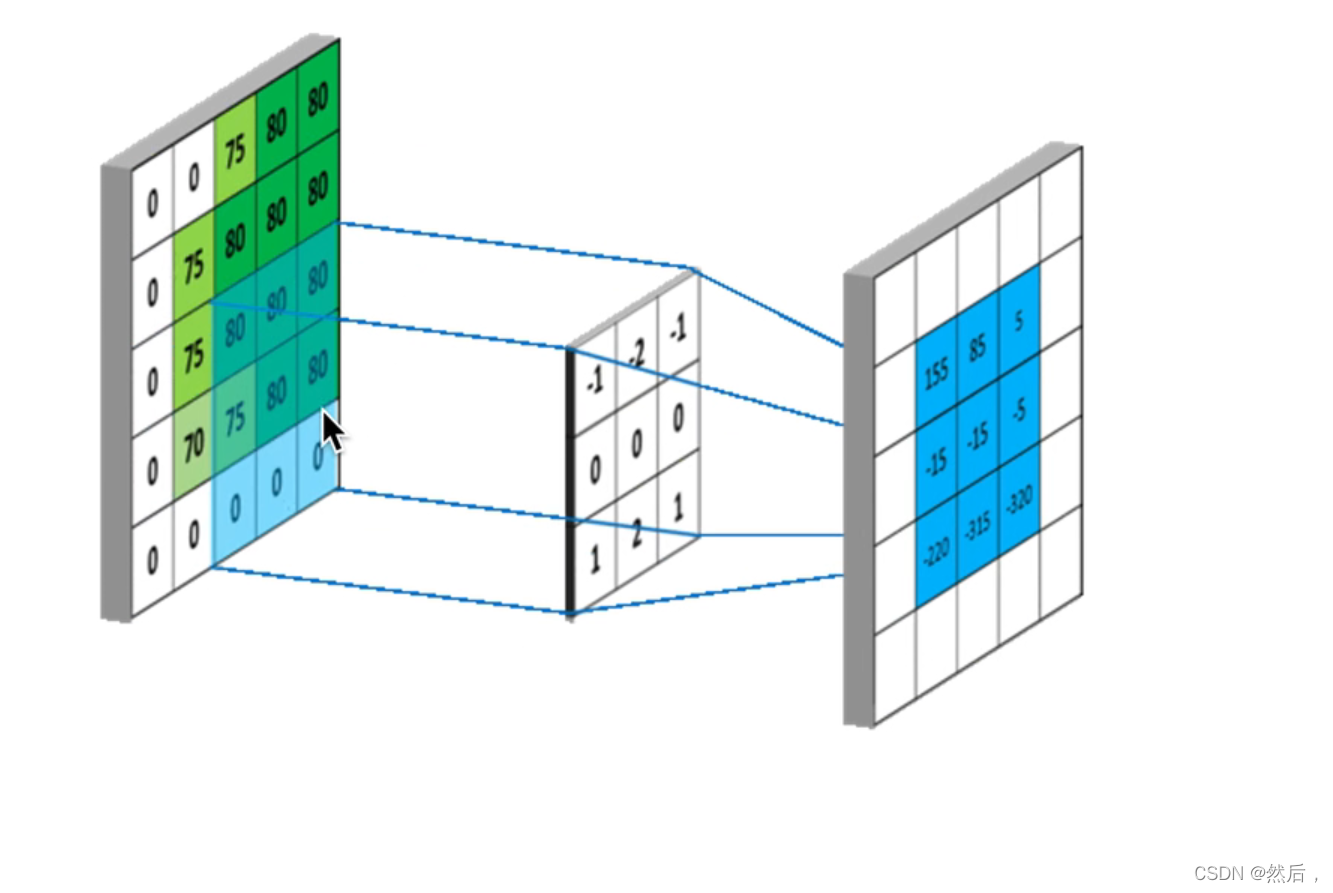
左边为原图,右边为特征提取后得到的feature map
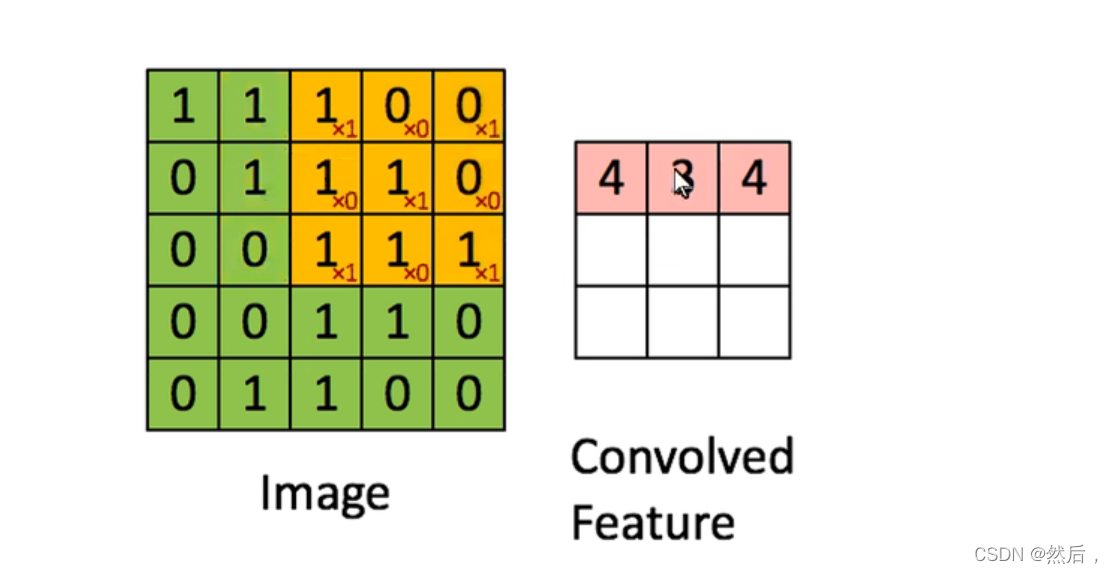
通过不同算法得到的feature map

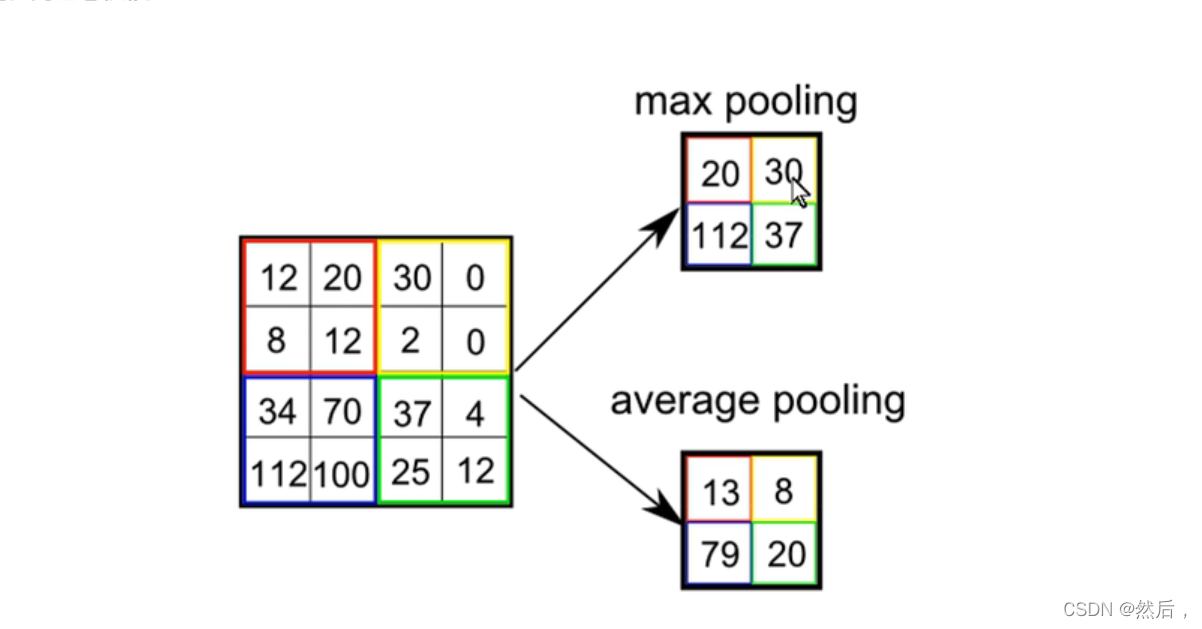
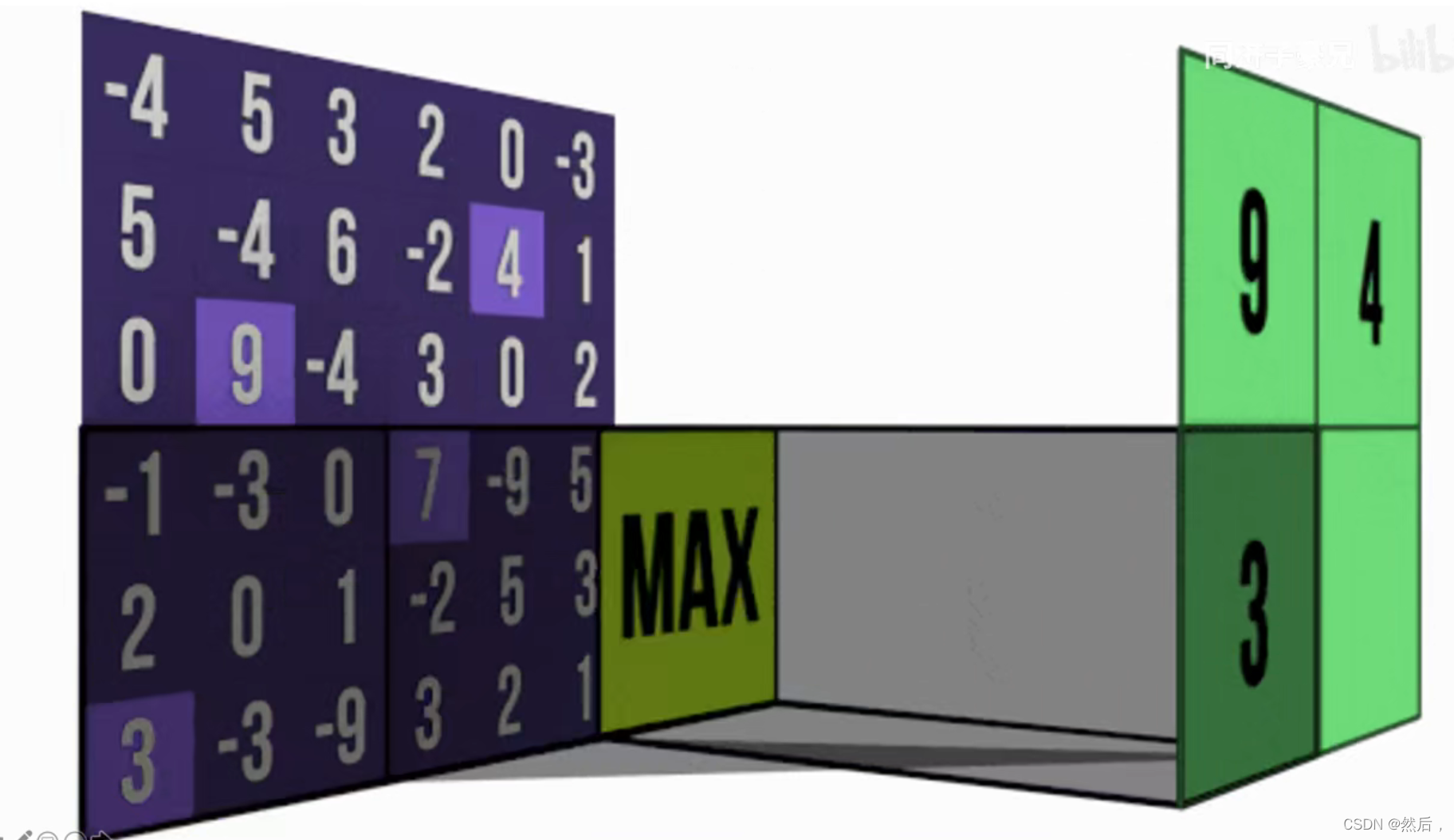
池化:
将左图的像素整个成有图的数据
大大缩小范围
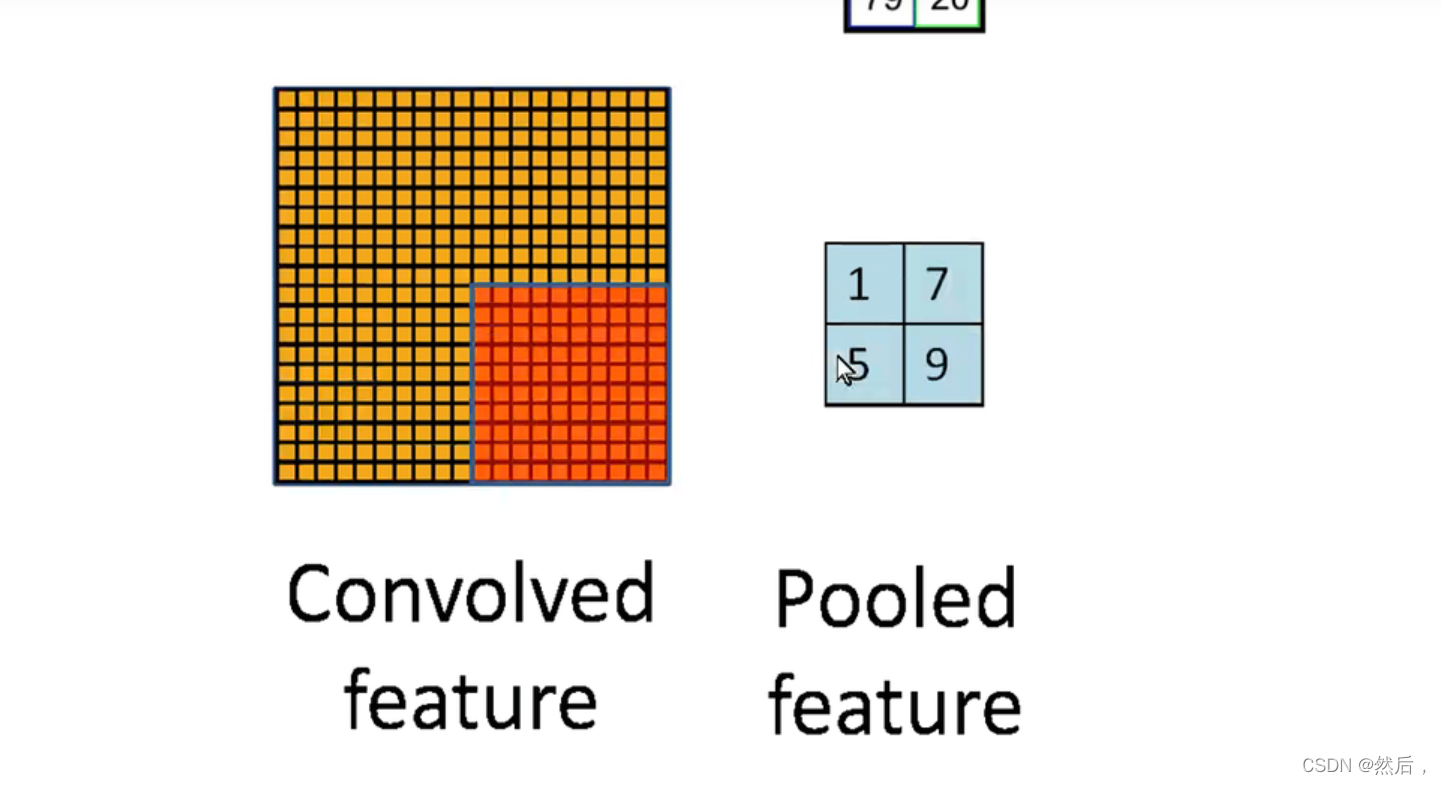
最大池化和平均池化(如果要取图像边缘,就要在边缘补0)
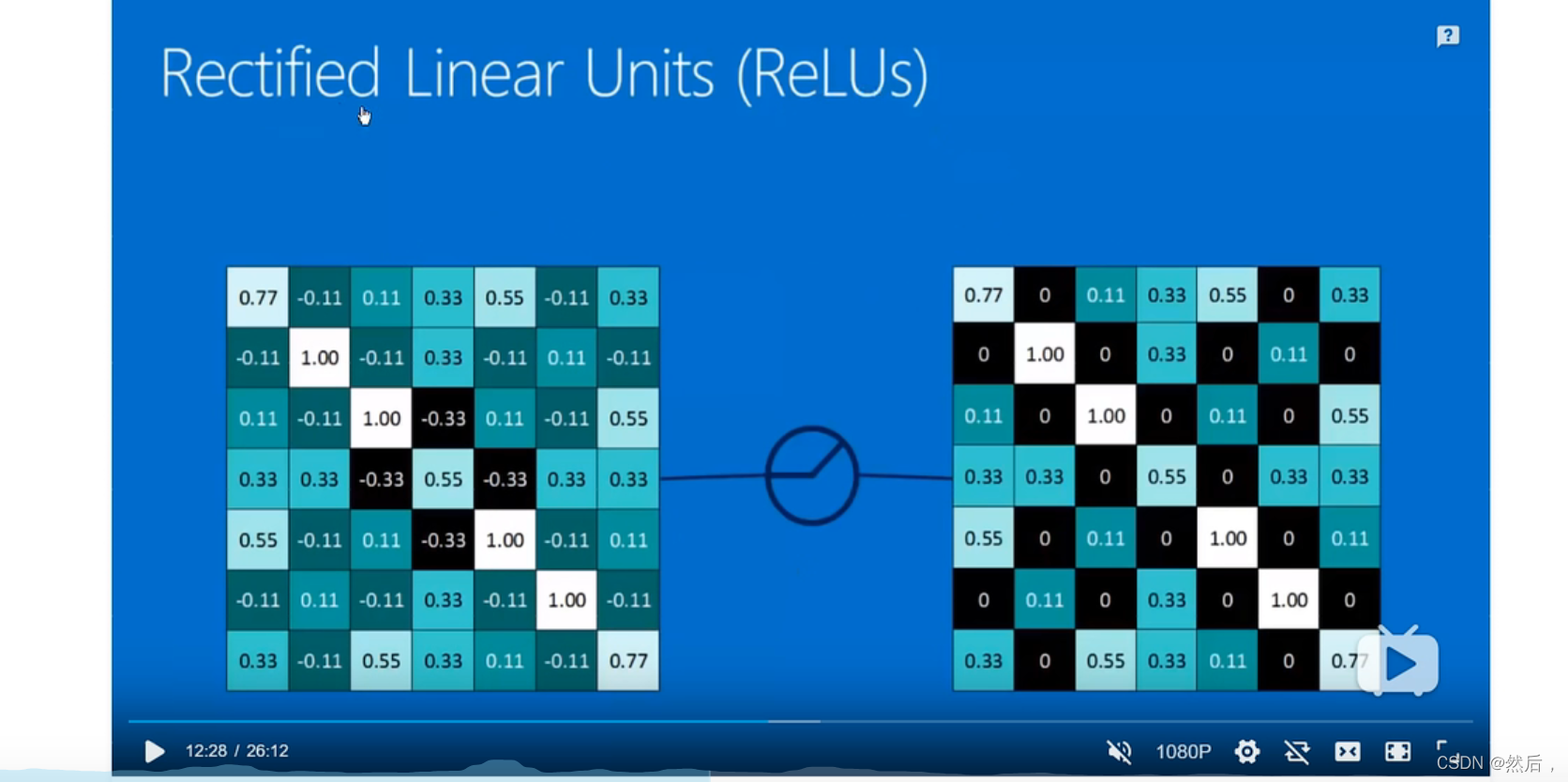
修正线性单元修正函数ReLU(0前为0,0后为x)
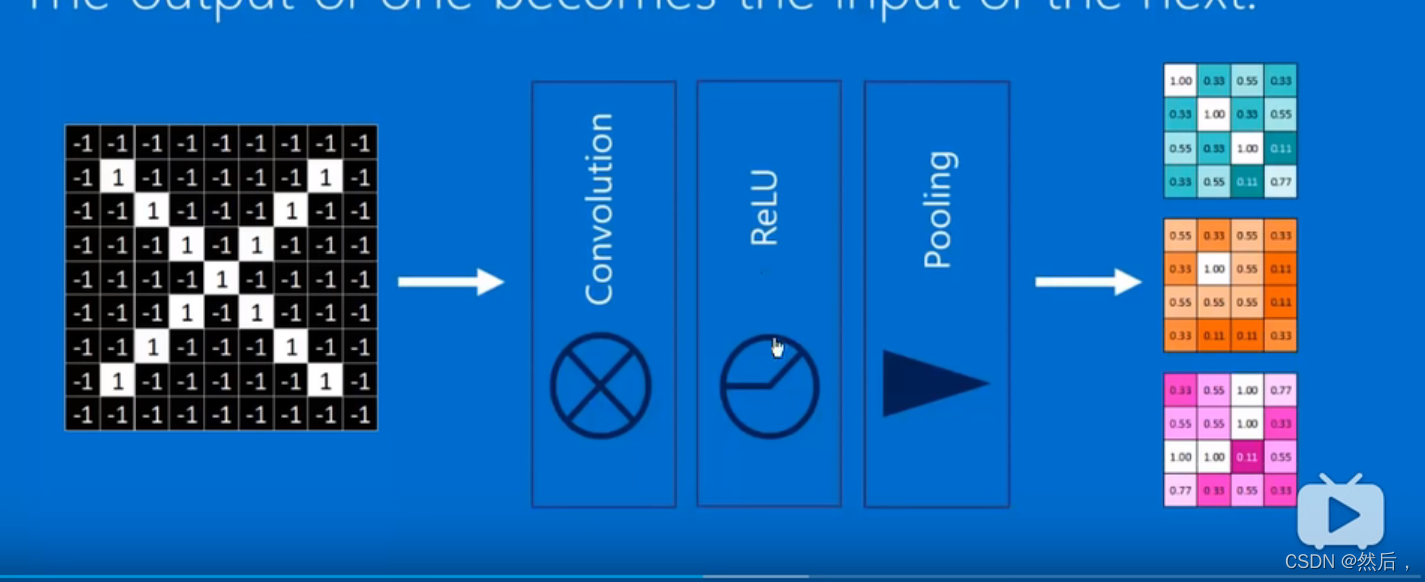
中间部分就是神经网络
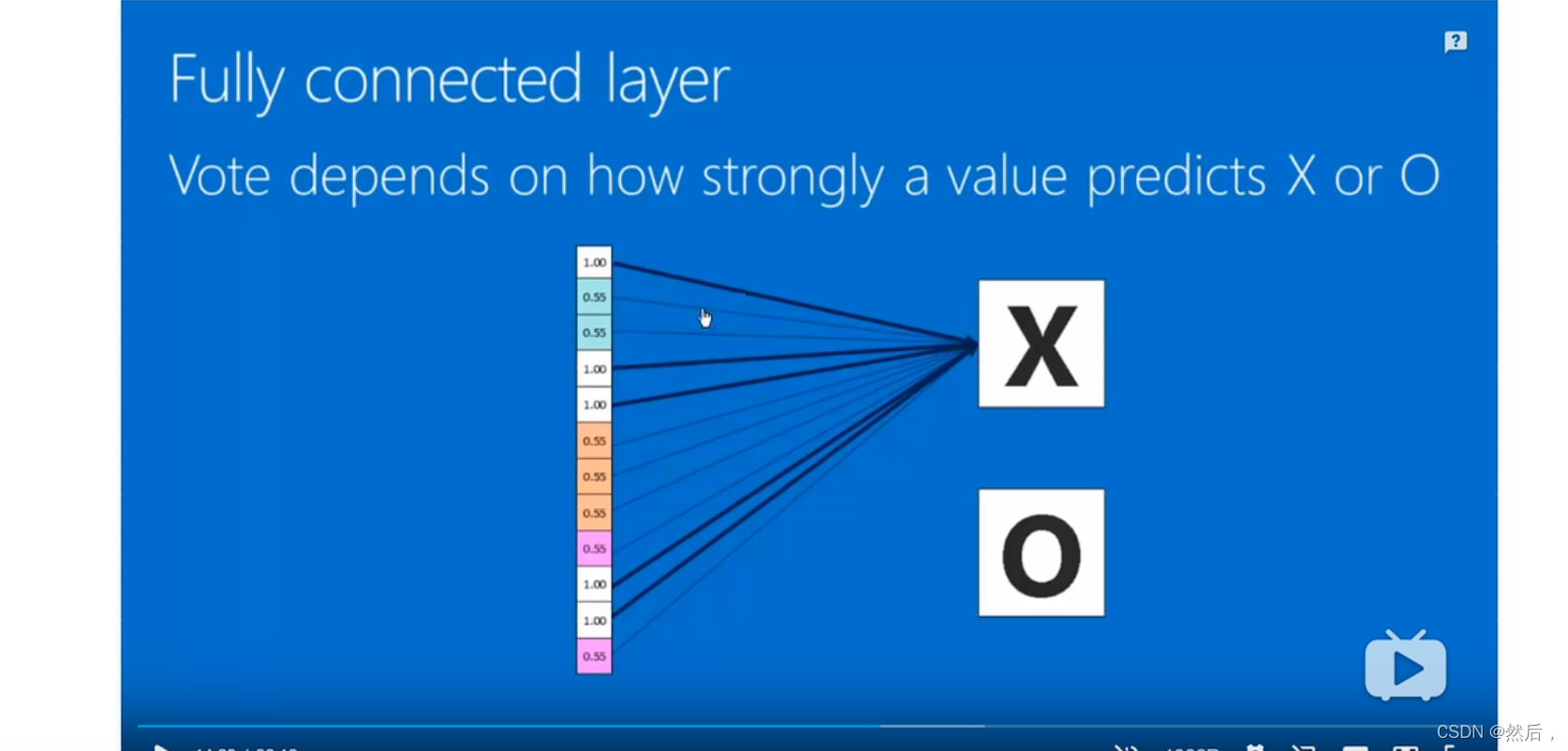
全连接层:判断概率(通过训练得到)和神经元*权重得到最后的概率。(判断是x还是o)
损失函数:
神经网络得到的结果和真实的结果进行误差的计算(通过修改卷积核的参数,修改全连接每一个权重,进行微调,使得损失函数最小,层层把误差反馈回去【反向传播算法】//image.net网站(图片网站))
将误差降到最小:(梯度下降)
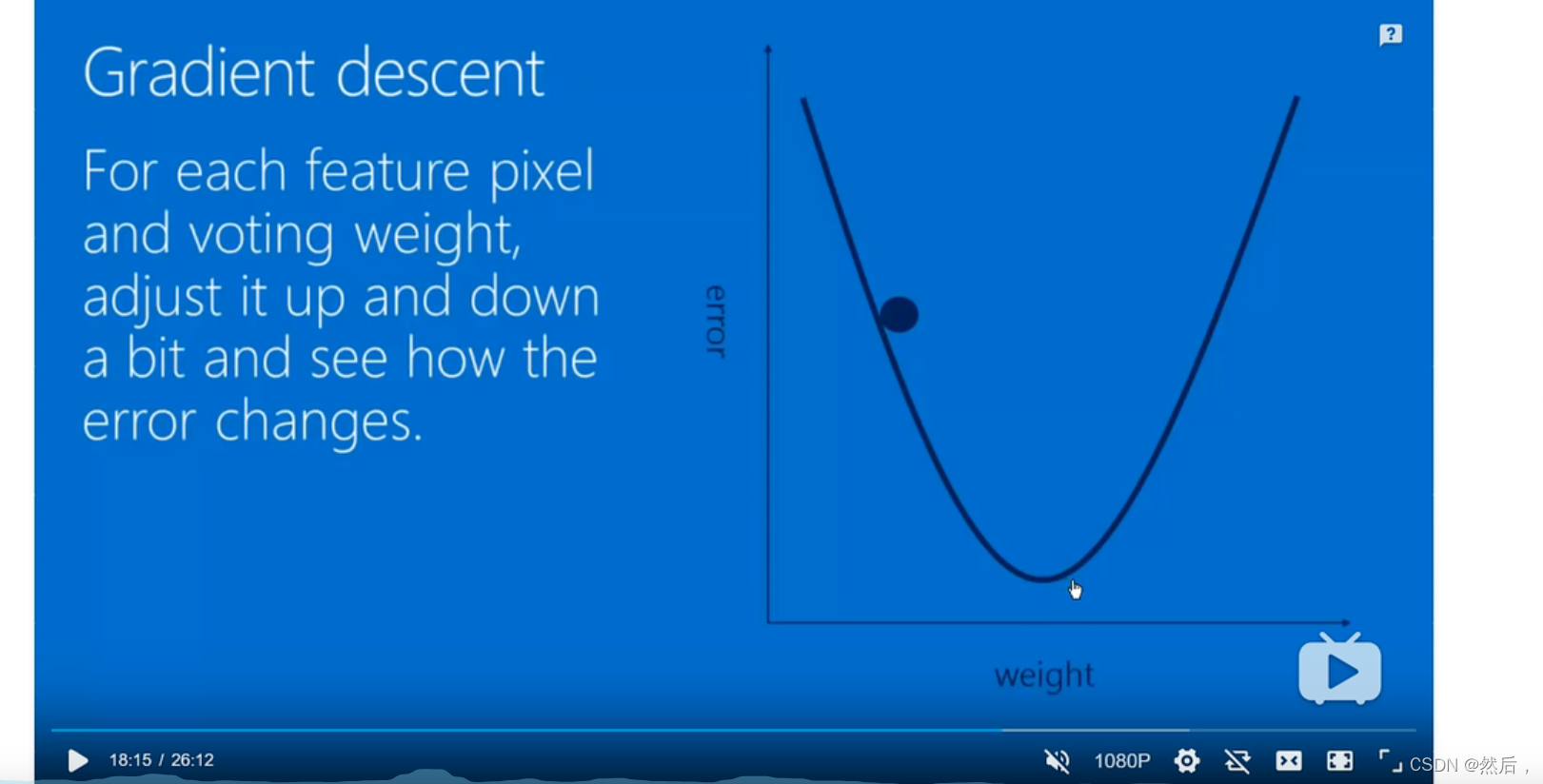
大佬的讲解课程:https://www.bilibili.com/video/BV1sb411P7pQ?spm_id_from=333.788.b_636f6d6d656e74.39
VGG:
以VGG16为例:第一个block有两个卷积层,第二个block有两个卷积层…(2,2,3,3,3)下采样,经过三个全连接层,最后soft-max输出(所有卷积层的卷积核都为33)随模型变深,每一个block的channel个数翻倍。输入224224图像,输出1000个后验概率(挑出最大的概率作为预测结果)。
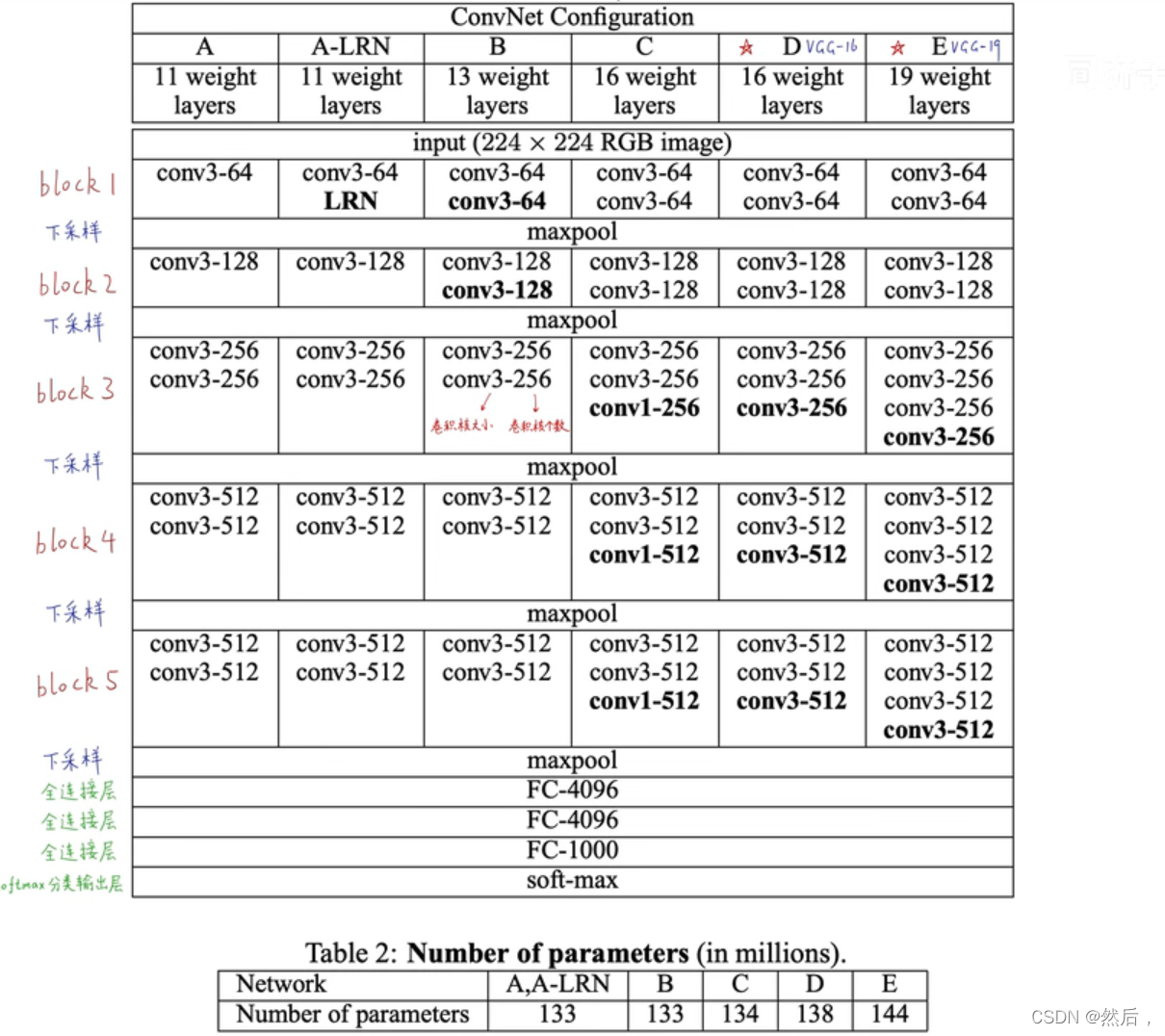
红色表示max-pooling最大池化层,像素长宽不断变小,语义通道数不断变多,(下采样层不包含参数,所以不算层数)
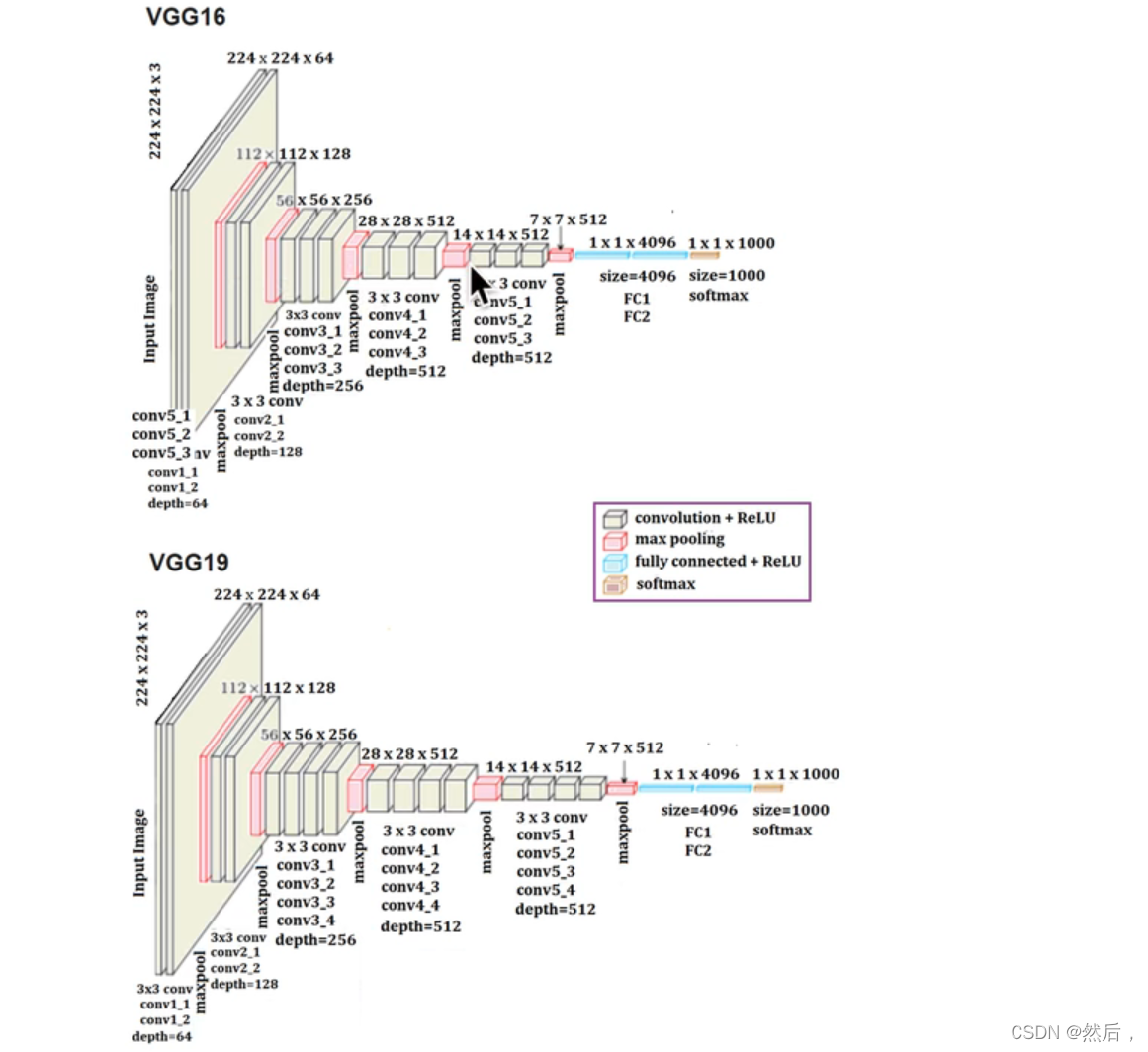
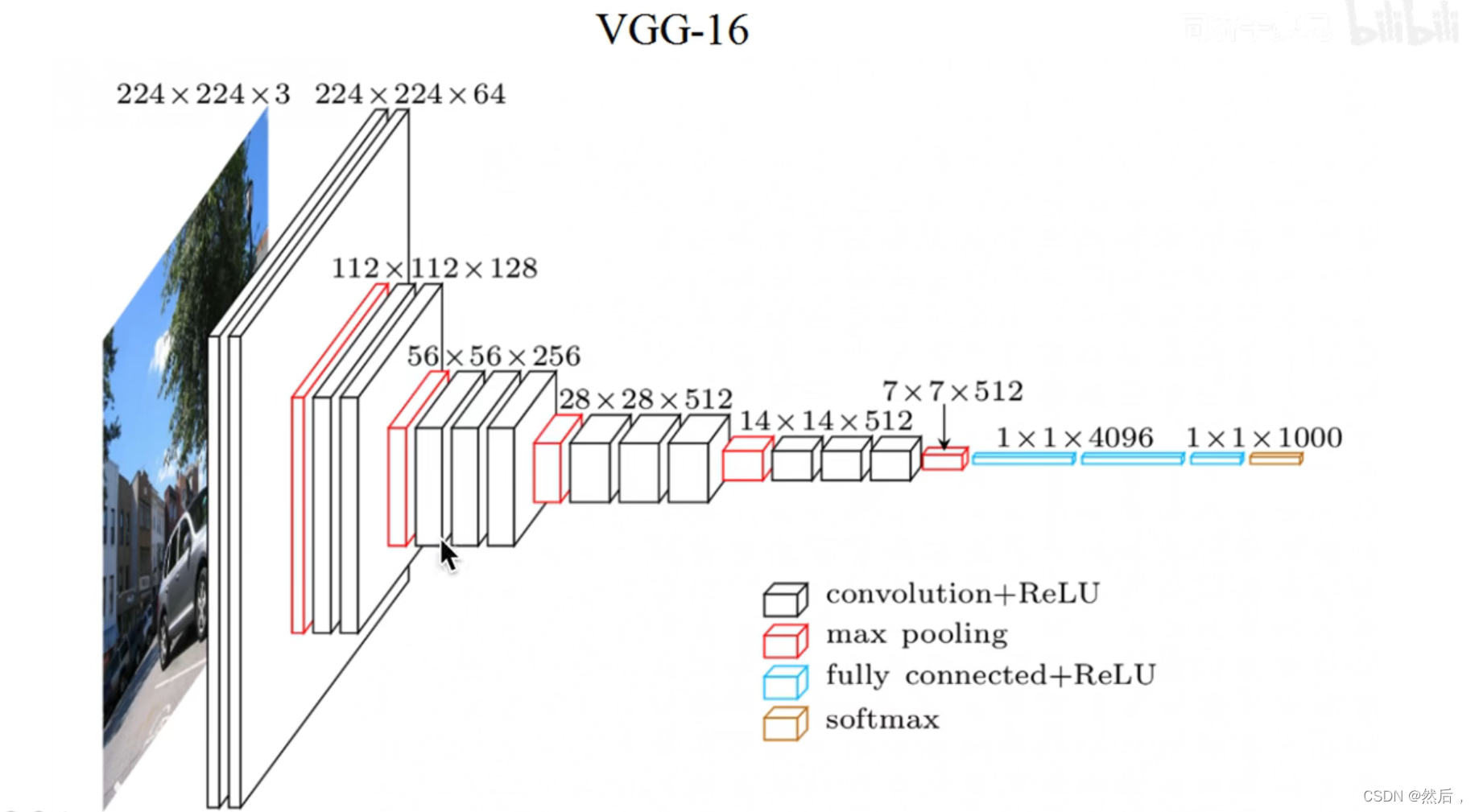
池化层:
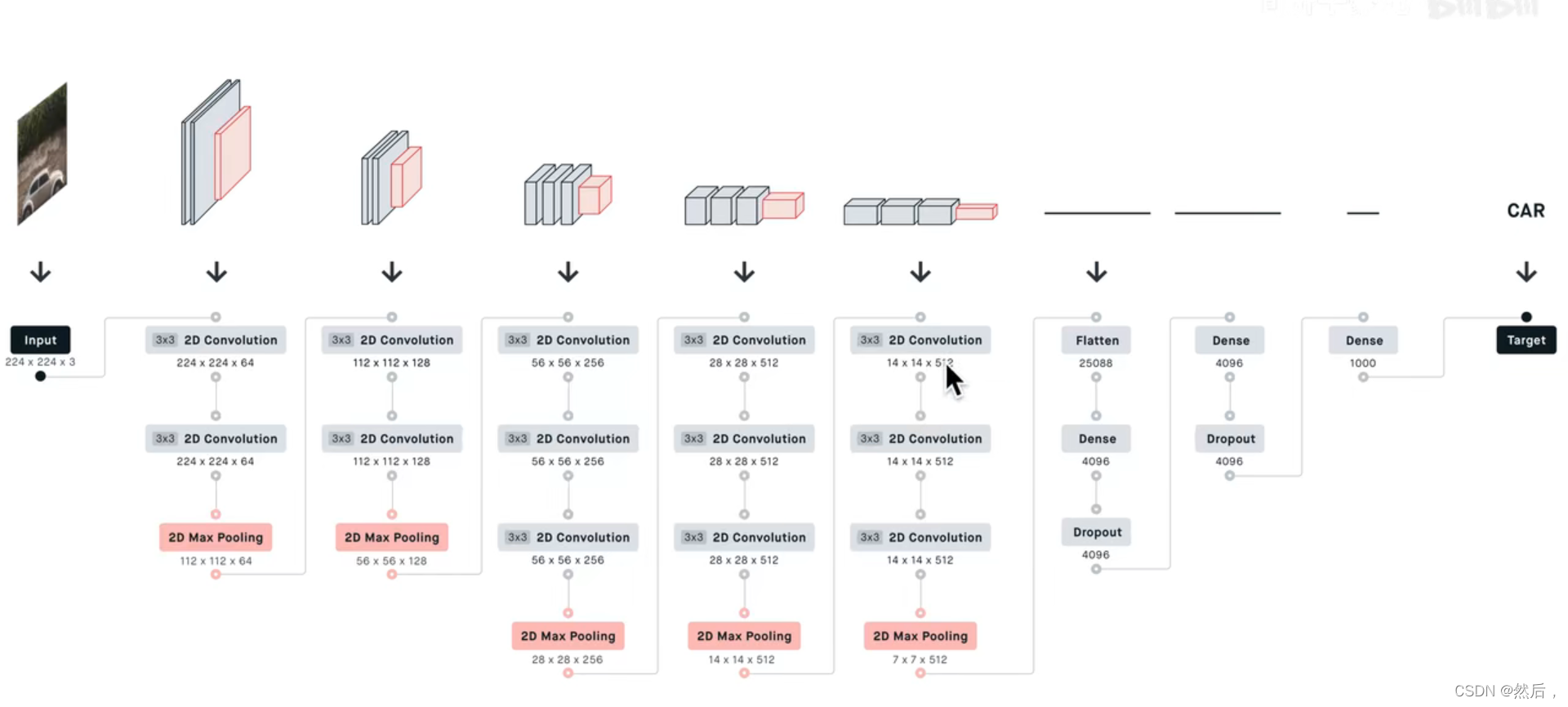
前两层占据绝大部分内存,第一个全连接层占据绝大部分参数:

33卷积核(下亮上暗)
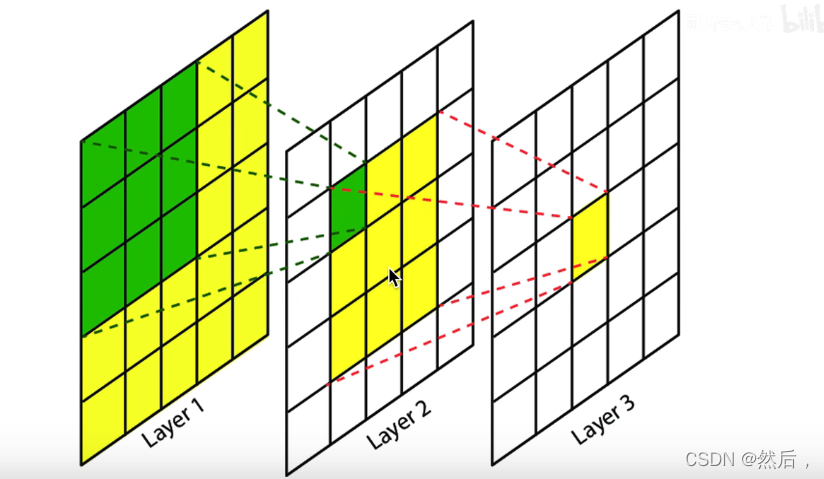
2层33卷积反映的55卷积(参数数量变少)【3层33卷积可以替代7*7卷积】
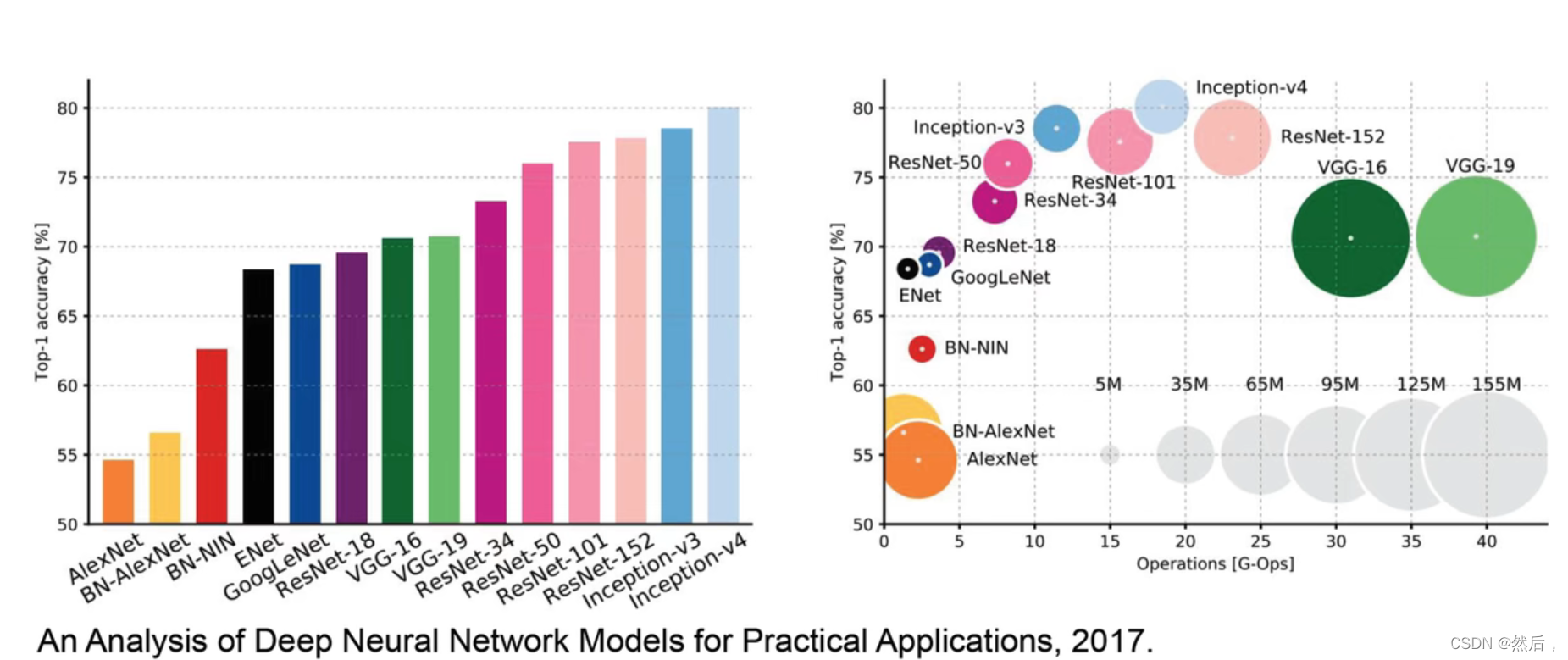
VGG古典学院的经典卷积神经网络(比较臃肿)(横轴计算量,纵轴准确率,圆圈大小为参数量)
.多分类交叉熵损失函数
.mini-batch带动量的随机梯度下降优化器
.全连接层引入dropout和权重衰减
.74个epchos就能快速收敛
初始化:每一个卷积层都是用ReLu激活函数(容易一开始熄火)。
先随机初始化(从正态分布或者高斯分布中取得)A模型(VGG11),再使用训练好的VGG11初始化其他更深的模型

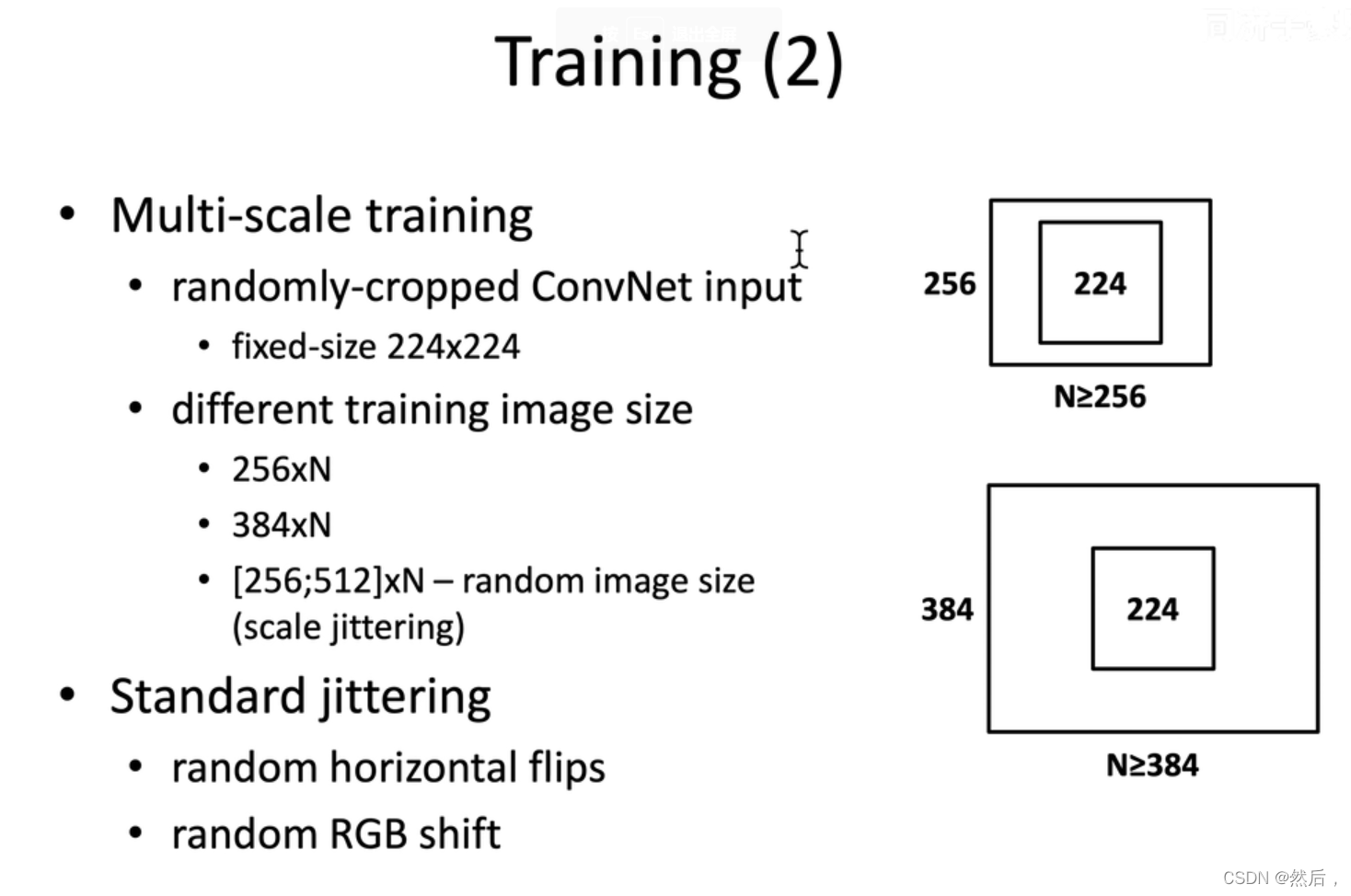
数据增强采用随机水平翻转和随机颜色变化
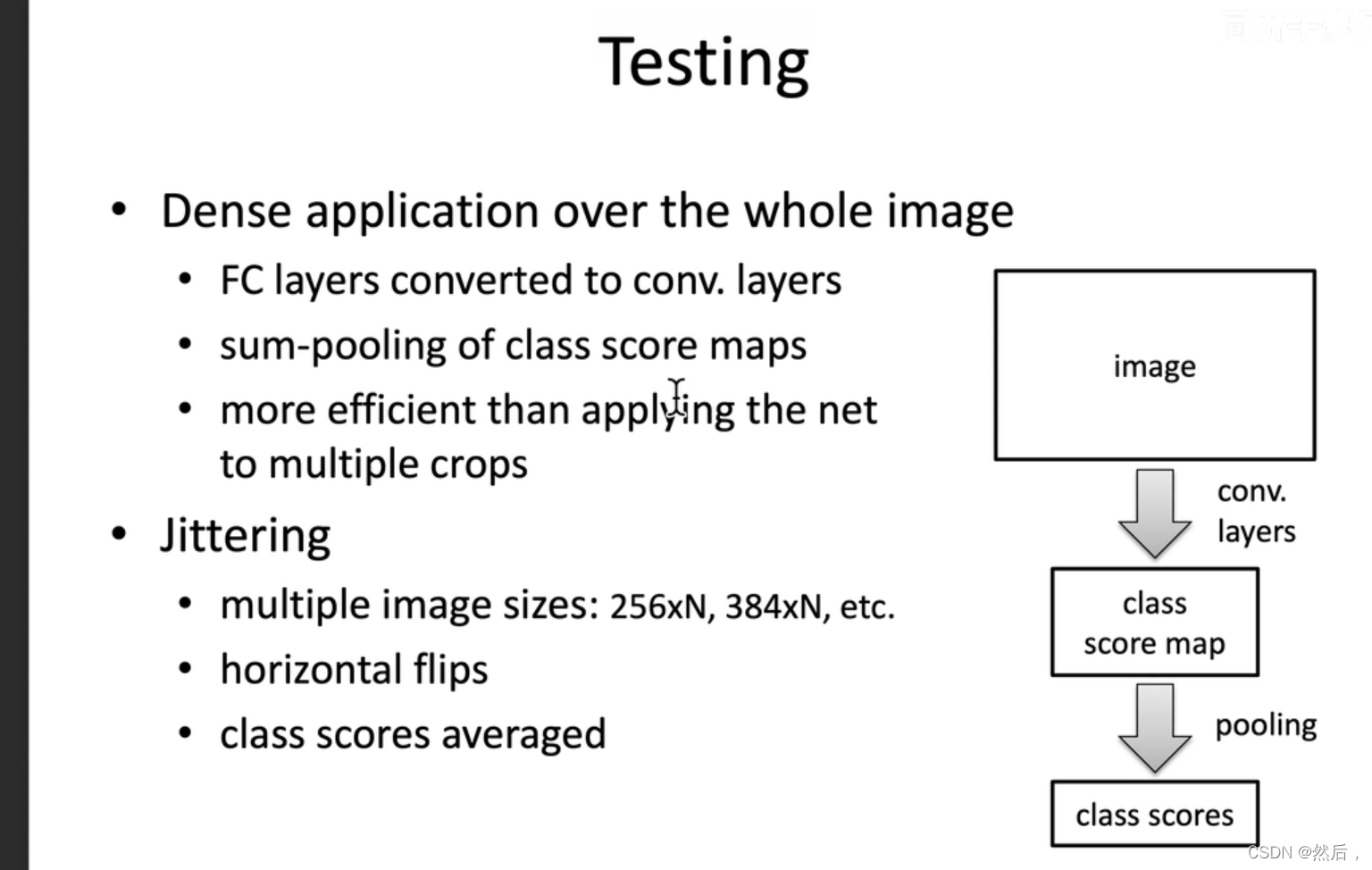
将全连接层转化成卷积层,可以输入任意大小图像。
multiple crops将一个图截成一个一个小块
VGG迁移学习:(把最后一层全连接层换成自己所需的个数,保留之前所有的结构不变,仅仅把之前的模型当作提取器。此图把最后一层全连接层神经元改成2622个神经元,输出2622类别概率。仅训练改的这一层【把image.net上预训练的模型用于解决问题】)