?
1.概述:Conditional GAN可以利用图像与对应的标签进行训练并在测试阶段生成指定标签(类别标签、图像中的某个部分用于图像修复)的图像。
1.1 马尔科夫链 :随即过程中,马尔科夫链认为过去的所有状态都被保存在现在的状态了。
?
Paper
1 . Introduction
对抗学习的优点是不用马尔科夫链,只需要反向传播梯度,在学习中不用推理。条件GAN的条件可以是类别标签、用于图像修复的数据的一部分或者不同模态(modality)的数据。
本文展示了如何构建CGAN,并为了检验结果在MNIST数据集和MIR Flickr25000数据集上进行多模态学习[multi-modal learning]。
More:多模态学习
2.Related Work
2.1 图片标签的多模态学习
尽管有监督学习网络(CNN为首)取得了不错的成果,但这些模型在面对类别数巨大的分类预测输出问题是仍有挑战。第二个问题是许多数据工作主要在学习从输入到输出的一对一映射(one-to-one mappings)。然而,许多问题是概率上的一对多映射。一个例子就是在图像标签问题上,可以合适得给一张图片分配很多不同的标签,而对于不同的注解者可能使用不同的术语(一般是相近或者相关联的)或表达方式来描述同一张图片。
对于第一个问题,一个办法是利用(leverage)附加信息。举个例子,使用自然语言集合学习一个标签的向量表示,这个向量中的几何(geometric)关系具有语义含义。这个方法的优势在于,在这样的空间中做预测,当预测错误时结果仍然很靠近真实标签,并且可以自己生成在训练时没有出现的标签。引用[3]展示了甚至一个从图片特征空间到词汇表示的简单线性映射就可以表现出更好的分类性能。
对于第二个问题,可以使用条件概率生成模型,将输入视为条件变量,一对多的映射被实例化(instantiated)为一个有条件的预测分布。
[16]使用简单的方法来解决这个问题,并在MIR Flickr25000数据集上训练了一个多模态深度玻尔兹曼机,本文也这么做了。
另外,[12]中作者展示了证明训练一个有监督多模态神经语言模型,它们能够为图片生成描述语句。
3.Conditional Adversarial Nets 条件生成网络
3.1 GAN
条件生成网络由两个生成模型组成:生成模型G用来接受数据分布,辨别模型D估计来自训练样本而不是生成图片的概率。生成器和判别器都是非线性映射,比如多层感知机(multi-layer perceptron)
为了学习在数据x上生成器分布pg,生成器建立了一个从初始噪声分布pz(z)到数据空间G(z;θg)的映射功能。并且判别器,D(x;θd),输出一个标量来表示x是来自训练数据而不是生成数据的概率。
生成器和判别器同时训练。对于G,最小化参数使log(1 - (D(G(z))))最小,对于D,调整参数使log(D(X))最小化。
3.2 条件对抗网络
在将额外的信息y输入GAN的生成器和判别器,得到条件模型。y可以是辅助(auxiliary)信息,比如类别标签或者其他模态的数据。可以将y当作附加的输入层输入生成器和判别器。
在生成器中原始输入噪声为pz(z),y被以结合隐式表示组合起来(combined in joint hidden representation),对抗训练框架允许更加灵活的方式来进行这种隐式表示。
在判别器中,x和y被当作输入来进行判别。
CGAN的损失函数如下:
??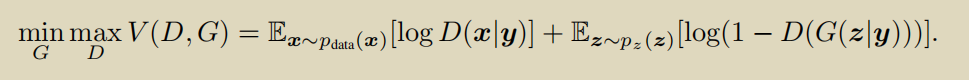
4. 实验结果
4.1 单峰
用MINST数据集和类别标签进行训练CGAN,将类别标签编为one-hot向量。
在生成网络中,从hypercube中提取一个均匀分布(uniform distribution)作为100维的噪声初始分布z。z和y都被ReLU映射到隐藏层,层大小分别为200和1000,在映射到第二层前,将隐藏的ReLU层组合为1200维。接着通过一个sigmoid层当作输出,生成784维的和MINST样本大小匹配的样本。
脚注:现在我们只是使用条件输入和初始噪声作为MLP的单一隐藏层的输入,但也可以想象使用更多层的方式来实现复杂的生成机制,但这种生成机制在传统的生成框架里极其难运行。
判别器将x映射到带有240个单元和5块的最大输出层,将y输入有50个单元和5块的最大输出层(maxout layer??)。在输入sigmoid层之前,两个隐藏层都映射到相连的maxout layer,这层带有240个单元和4块。(只要有足够的性能,判别器的结构是否严谨就没有那么重要,我们发现maxout单元能够很好的适配这个任务)
More:maxout layer
使用100的mini-batch和随机梯度下降,学习率初始化为0.1,然后以指数方式(exponentially)减小到0.000001,衰减因子为1.00004。动量初始值为0.5,然后增至0.7。Dropout的概率为0.5,分别应用于生成器和判别器上。以验证集上的最佳对数似然估计作为停止点。
表1 略
条件对抗网络的结果超越了一些网络,但表现也逊于其他网络,包括非条件的对抗网络。此结果更多的是证明概念而不是其性能,在之后对超参数空间的和结构探索中条件模型应该会超越非条件模型的结构。
4.2 多模态
像Flickr这样的图片网站有非常丰富的带标签数据资源,以图片和它们相关联的用户生成元数据(User-generatormetadata,UGM)的形式出现,特别是用户标签。
用户生成元数据不同于有标准标签(canonical)图片,前者跟具有描述性,并且在语义上跟接近人们怎么用自然语言描述图片而不是仅仅确定目标在图片中是否存在。UGM的另一个方面是synoymy很常见(prevalent),并且不同的用户可能使用不同的词汇来描述同一个概念,因此,有一个高效的方式去正则化这些标签很重要。概念词汇嵌入(Conceptual word embeddings)在这里很有用处,因为相关概念最终被相似的向量表示。
这节我们做了图片的多标签预测的自动标签,利用条件对抗网络来生成一个(也可能是多模态)的在图片特征上的条件标签向量分布。
提前在带有21000个标签的全ImageNet数据集上训练好图片特征,卷积模型与[13]中的类似。使用最后带有4096个单元的全连接层的输出结果作为图片表示。
对于词汇表示,先从YFCC100M的数据集元数据中,聚集彼此相关联的用户标签、标题和描述,得到一个文本语料库。在预处理和文本清洗后训练一个连续跳跃元语法(skip-gram)模型,这个模型有大小是200的词向量。其中省略了包含任意出现次数少于200次的单词的词向量,最终得到大小为247465的字典。
在训练对抗网络过程中保证卷积模型和语言模型的固定性。
为了评价模型性能,对每个图片生成100个样本,并对每个样本使用词汇中单词表示向量的余弦相似,最后找到20个最接近的单词。然后选择100个样本中前十个最常见的单词。表4.2展示了一些用户分配的标签和注释以及生成的标签。
模型性能最好的生成器接受了100维的高斯噪声作为初始化噪声并把它映射为500维后输入ReLU层(?映射到500维的ReLU层)。接着将4096维的图片特征向量映射为2000维的ReLU隐藏层。然后这些层都将映射到相连的200维线性层,线性层将会输出生成的词向量。
判别器由500和1200维的ReLU隐藏层组成,分别对应于词向量和图片特征。下一层是1000个单元和3块的maxout层,其输出最终输入至单一sigmoid单元。
训练模型使用随机梯度下降,mini-batch大小为100,初始学习率为0.1,后以指数形式减小为0.000001,衰退率为1.00004。动量为0.5,后增长至0.7。生成器和判别器都使用0.5的Dropout。
通过交叉验证和随即网格搜索及人工选择的混合,得到超参数和网络结构选择。
5 . Future work
本文展示的结果非常初级,但证实了条件对抗网络的潜力并展示了有趣和实用的应用。
在未来的探索中期待更复杂、细节更多的模型,分析它们的表现和性能。
现在我们的实验中只单独使用每个标签。但通过同时使用多重标签(有效地将集合问题作为生成集合问题中的一个)希望得到更好的结果。
另外一个未来工作的方向是构建一个联合训练方案(joint training scheme)去学习语言模型。[12]的工作显示能够学习到一个适配特定任务的语言模型。