此问题来自:https://www.zhihu.com/question/308310065
最近再看BN、LN、IN、GN的区别,看到LN的时候,一直没太看懂,只知道:首先,BN天然与batch size有关,batch size太小bn的效果不会太好,并且BN对于图像那样的固定尺寸的输入有效,对RNN这种输入时序列形式的网络效果不好,反而Layer Normlization(LN)派上了用场,为什么,下面的答案总结的很好,简单易懂
RNN是可以用BN的,只需要让每个Batch的长度相等,可以通过对每个序列做补长,截断来实现。RNN不适合用BN的原因:Normalize的对象(position)来自不同分布。CNN中使用BN,对一个batch内的每个channel做标准化。多个训练图像的同一个channel,大概率来自相似的分布。(例如树的图,起始的3个channel是3个颜色通道,都会有相似的树形状和颜色深度)RNN中使用BN,对一个batch内的每个position做标准化。多个sequence的同一个position,很难说来自相似的分布。(例如都是影评,但可以使用各种句式,同一个位置出现的词很难服从相似分布)所以RNN中BN很难学到合适的μ和σ,将来自不同分布的特征做正确变换,甚至带来反作用,所以效果不好。
BN是不适用于RNN这种动态结构的。如果将BN应用在RNN中,由于BN是以batch为单位统计归一化变量的,所以不同长度的样本的时间片如何计算将十分困难。在BN中我们需要根据训练数据保存两个统计量 μ和σ,如果在测试时一组样本的长度大于训练的所有样本,那么它的后面的时间片需要的μ和σ该怎么办?
其实对应RNN有专门的归一化策略,例如Hinton团队的Layer Normalization(LN)等。
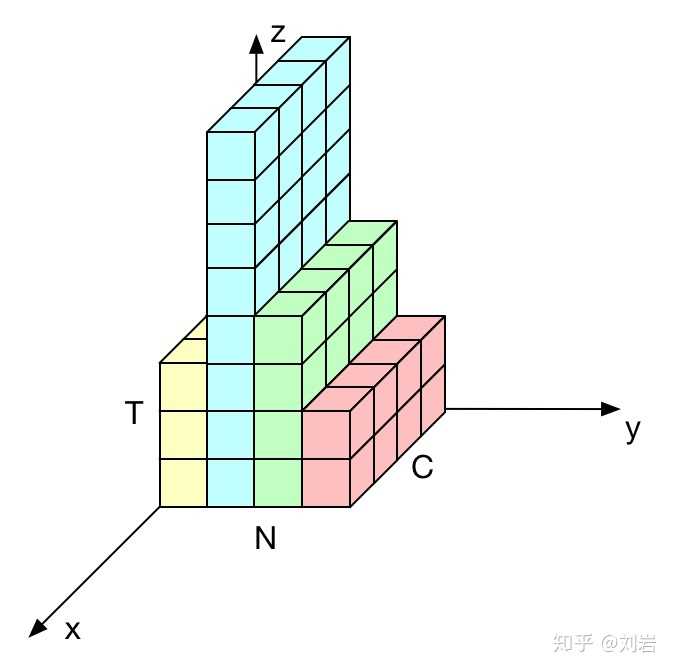
在上图中每个颜色表示一个训练样本,每个样本都有自己的长度。BN是按与y轴平行的方向计算统计量(即[N,T])。由于BN中每个样本的长度都不一样,计算的 和 时就会非常不具有代表性,当t>3时,我们只能获得来自第二个样本的一个统计量,那么此时的均值和方差已经没有意义。
LN是按与x轴平行的方向做归一化(即[C,T]),这个被证明是在RNN中表现比较好的一种归一化方法,因为在每个时间片都会获得相同的数量(通道数)个数值的归一化统计量。LN中不同时间片的μ和σ是共享的。
如果上面的图你觉得还不够形象的话,看这个图你一定就懂了
图来源于:https://zhuanlan.zhihu.com/p/38755603
batch是“竖”着来的,各个维度做归一化,所以与batch size有关系。
layer是“横”着来的,对一个样本,不同的神经元neuron间做归一化。
显示了同一层的神经元的情况。假设这个mini-batch一共有N个样本,则Batch Normalization是对每一个维度进行归一。而Layer Normalization对于单个的样本就可以处理。
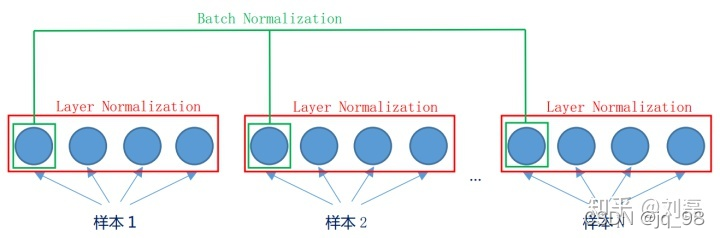
Batch Normalization和Layer Normalization的对比分析
Batch Normalization 的处理对象是对一批样本, Layer Normalization 的处理对象是单个样本。
Batch Normalization 是对这批样本的同一维度特征(每个神经元)做归一化, Layer Normalization 是对这单个样本的所有维度特征做归一化。

这几天会针对BN、LN、IN、GN 分析一下它们之间的区别,写一篇博文