D Detone, Malisiewicz T , Rabinovich A . Toward Geometric Deep SLAM[J]. 2017.
����ʹ�����ѧϰ������֡��ͼ��ĵ�Ӧ�Ծ���,��Ҫ�ֳ�����:��һ��ͨ��һ�������������ҵ�����ͼ���еĽǵ�;�ڶ����������������ǵ�ͼ(����),������֡��ͼ��ֱ�ͨ����һ������������õ��ĵ�ͼ(����),���Ϊ9������,�� H 3 ? 3 H_{3*3} H3?3?��Ӧ�Ծ���
1������ṹ
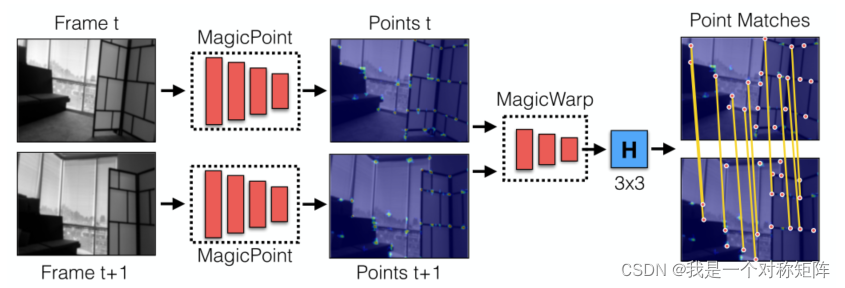
�������������������������:MagicPoint��MagicWarp:
- MagicPoint������Ѱͼ���еĽǵ�,������ͼ��,����ǵ����ͼ��
- MagicWarp������㵥Ӧ�Ծ���,��ͬʱ��������ͼ�Ľǵ����ͼ,�������ͼ֮��ĵ�Ӧ�Ծ���
ע��MagicWarp��������� H 3 ? 3 �� 9 �� �� �� H_{3*3}��9������ H3?3?��9������,����matches�Ǽ���lossʱ�IJ�����,����ϸ����
2��MagicPoint
2.1��MagicPoint�ṹ

����Ϊ�Ҷ�ͼ,ͨ��VGG-like��encoding�õ�65ͨ��������ͼ,ͨ��softmaxת��Ϊ����,���յõ�152065��tensor(��Ϊ������120160),������������ͼ�оֲ�88��������ÿ������Ϊ�ǵ�ĸ��ʡ�ͨ����Ϊ8*8+1,Ϊʲô+1,�����������ͨ��,��ʾ�ڸ�����û�м��ǵ㡣
Ϊ�˽����show����,��ͼ���������������ͨ��,��122064��tensor����reshapeΪһ��heatmap,�Ϳ��Խ�Ԥ������Ľǵ�λ�ÿ��ӻ�������
(��������Ϊ,����tensor���Ͻǵ�һ����,��65��ͨ��,��1*1*64+1*1*1,1x1��ʾԭͼ��8*8��������������,������������64�����ص�,��64�����ص�����Щ�ǽǵ�?�պ�64��ͨ��ֵ�ͱ�ʾ64������Ϊ�ǵ�ĸ��ʡ���65��ͨ����ʾ��64�����ص��Ƿ�û�нǵ�)
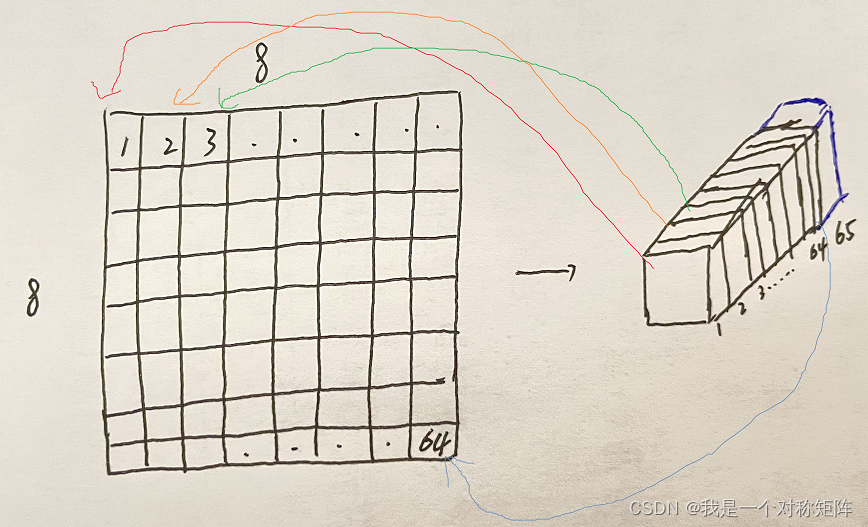
(���Ǹо��е�ǣǿ,��Ȼ�ܽ���ͨ���ĺ���??������������ʱû������ϸ�Ľ���)
2.2��MagicPoint�����ѵ��
��Ϊû�����õĽϴ�����ݼ�,���������Լ����߾ȹ�������µķ�����ʹ��Opencv����һϵ�е�ͼ,���Ǿ�����ѵ��ͼ��ͽǵ��λ��:

ͬʱ����������������³����:

2.3��MagicPoitn�����Loss
ʹ��:cross entropy loss
3��MagicWarp
3.1���ṹ
�ṹͼ����,�������ǿ��Կ�����������,ͨ��MagicPoint���ǵ�λ��,����֡ͼ��Ľǵ�λ��ͼ��ΪMagicWarp���������,���������Ӧ�Ծ���
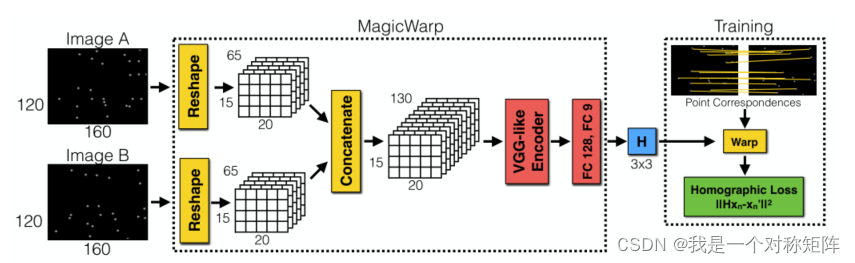
MagicWarp������Image A��A������Ӧ�Ա任�����ɵ�Image B,��һ��Reshape���DZ����Magic Point�ı����(���Ի�ͷȥ����),Ȼ������tensorͨ��cat��һ��,�پ���VGG��Encoding,ͨ������ȫ���Ӳ����9����ֵ,��3*3�ĵ�Ӧ�Ծ���
3.2��ѵ��
ѵ������Ҫ���ݼ�������ͼ���Կ���,����������ǵ�λ��ͼ,���߽е�ͼ,�������߱������һ�ַ�ʽ���ɼ�:
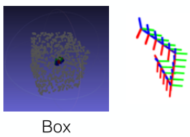
�������һ��3D����ͼ,�����һ����������Ĺ켣��������ڹ켣���˶�������,���γ���һ������֡�������������й�����֡���һ�Ӷ���������������ѵ�������н����������������ȡ��30%���Ӿ��ص���ͼ���,������ѵ��ʱ,���������һЩ��,�����³���ԡ������������50%��ƥ���(���Զ���?)���������25%�Ķ�����(ֻ��һ��ͼ�ж�����?)Ч���ܺá�
3.3����ʧ����
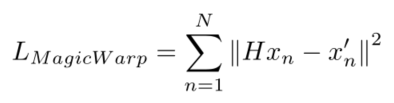
x
n
x_n
xn?:Ϊ֡ͼ1
H
H
H:Ϊ֡ͼ1�任��֡ͼ2ʱ��Ӧ�Ծ���(�����λ�˱仯)
x
n
��
x^{'}_{n}
xn��?:Ϊ֡ͼ2
Ҳ����˵�������Ԥ���H����ʵ��H�ܽӽ�,��ô�ҽ�H������֡ͼ1��õ���֡ͼ2,����ʵ֡ͼ2�ϵĽǵ�λ��,Ӧ����һ����,���ǵ�λ�õ�L2���롣
(������:��������Լ�ʵ��ͨ��֡��ͼ��������λ�˵ı仯,��ô��ι������ǹ��Ƶ�λ�� H H H����ʵλ��֮�� H g t H_{gt} Hgt?����,һ���뵱Ȼ�ķ����Ǽ��� H H H�� H g t H_{gt} Hgt?�IJ��,������ʵ�� H g t H_{gt} Hgt?�����ò���,����Ҫ֪���������ת��ƽ�����������������������Ҫ H g t H_{gt} Hgt?,ֱ�Ӳ����ǵ�λ�õIJ��,�Ͼ���һ��ͼ�ϼ��������ؼ���IJ��Ǹ�����һЩ��)
4����
4.1��MagicPoint��
4.1.1��ƽ�����ȺͶ�λ���
��ͼչʾû�������ij�����,��ͬ�ǵ��ⷽ����ƽ������

��ͼչʾ���������ij�����,��ͬ�ǵ��ⷽ����ƽ������

�ɼ�MagicPoint��������³���Ժ�ǿ
ͬ����,��ͼչʾ��ͬ�ǵ��ⷽ���Ľǵ㶨λ���(��ͼ������,��ͼ������)
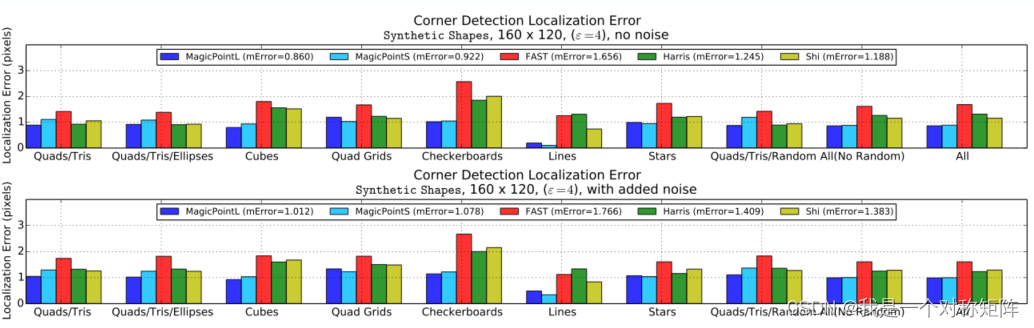
���漸��ͼ�ı�������:

4.1.2����ͬ�����̶��µĽǵ���Ч��
��Ȼչʾ��������������,��ô��Ч����������ǿ�Ȳ�ͬ,��ʲô�仯��?
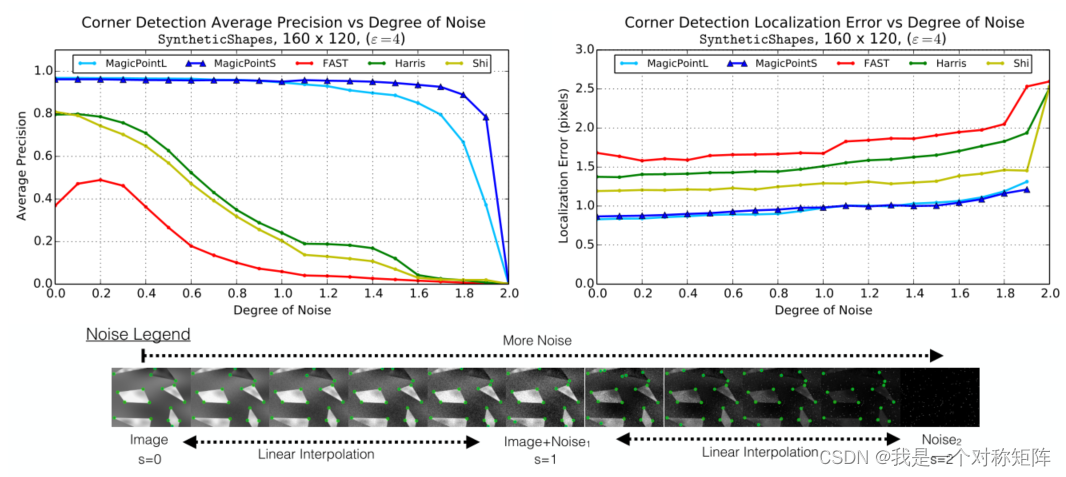
��ͼչʾ�˲�ͬ���������̶ȵļ�ǿ,���ֽǵ����㷨�ı��֡�
4.1.3����ͬ���������µĽǵ���Ч��
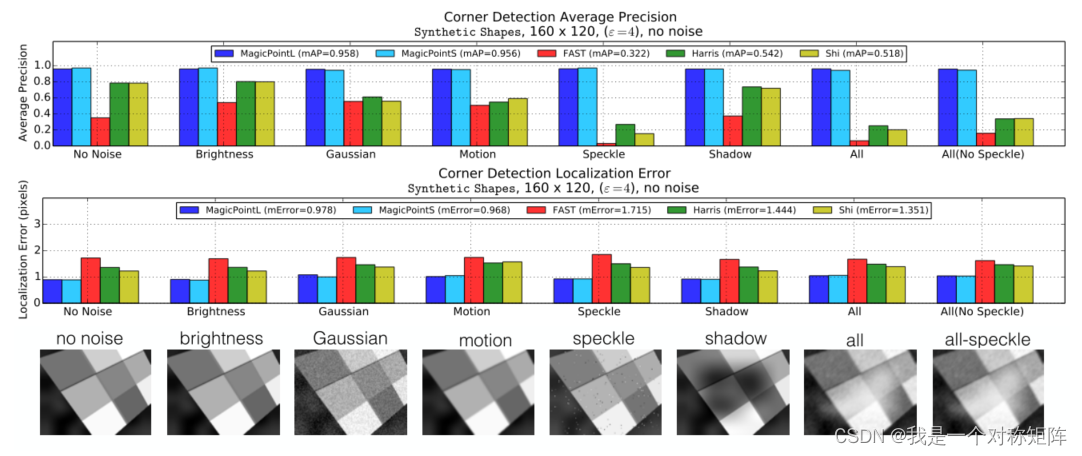
4.1.4����ͬ��̬�����½ǵ���Ч��
�ȿ�Ҫʵ���4�ֳ�����30��Ч��ͼ

����4�ֳ�����,��ͬ�ǵ����㷨�ı��������?
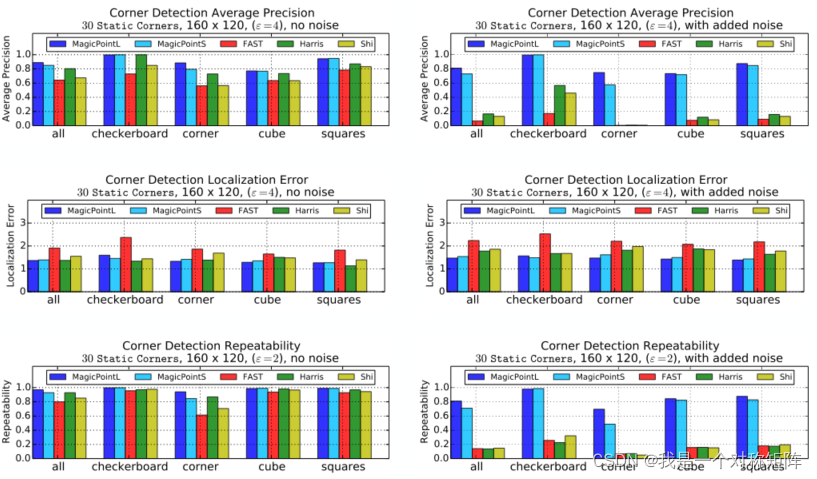
4.2��MagicWarp��
4.2.1��MagicWarp��ƥ������
���й���ƥ�������Ķ�������:
��ͼ1�ж���һ���㼯
x
i
x_i
xi?,����
i
��
{
1
,
.
.
.
,
N
1
}
i��\{1,...,N_1\}
i��{1,...,N1?},
��ͼ2�ж���һ���㼯
x
j
x_j
xj?,����
j
��
{
1
,
.
.
.
,
N
2
}
j��\{1,...,N_2\}
j��{1,...,N2?},
������ground truthת������
H
^
\hat{H}
H^,��Ԥ���ת������
H
H
H
��:
M
a
t
c
h
C
o
r
r
(
x
i
)
=
MatchCorr(x_i)=
MatchCorr(xi?)=
a
r
g
m
i
n
j
��
1
,
.
.
.
,
N
2
�O
�O
H
x
i
��
?
x
j
�O
�O
=
=
H
^
x
i
��
argmin_{j��{1,...,N_2}}||Hx^{'}_i-x_j||==\hat{H}x^{'}_i
argminj��1,...,N2??�O�OHxi��??xj?�O�O==H^xi��?
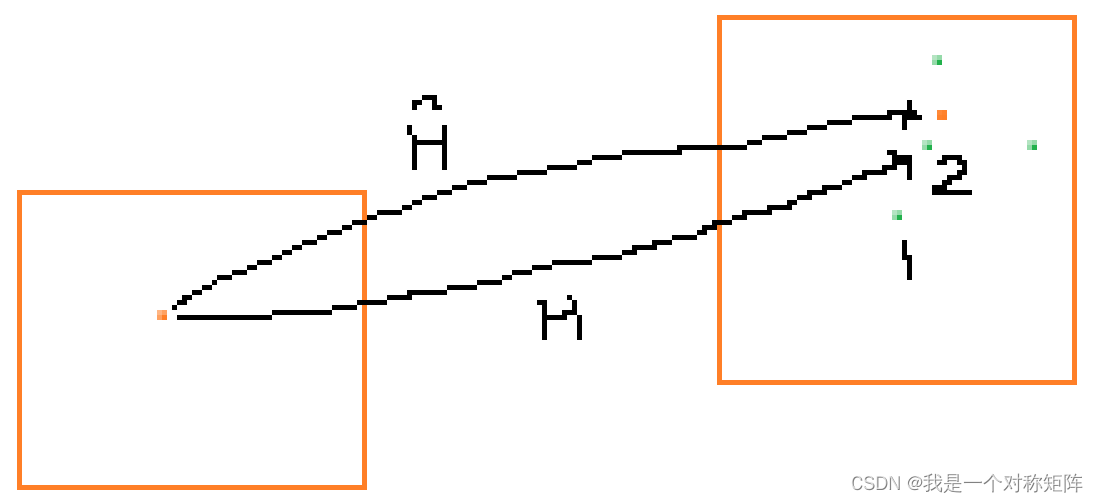
�ɹ�ʽ���Կ���,����ǽ�ԭ���꾭Ԥ���ת������Hת����,�ҵ������Լ�����ĵ���Ϊƥ����;�Ҳ��ǽ�ԭ���꾭gtת������Hת����ĵ㡣���������һ��,��֤��Ԥ�����H�ǽӽ�gt����H�ġ�
���
H
H
H��
H
^
\hat{H}
H^һ��,��Ӧ������ɫ��ת������ɫ��,������Ϊ�����,��������ȫһ��,��ת����ĵ���ƫ��,����ƫ���,��������Ϊ����ȷ�ġ��������
H
H
Hƫ�����,��ת�ƺ���ܾ�ӳ�䵽��1��,��ʱ�����ɫ��������ǵ�2,��==������,����δƥ��ʧ�ܡ�
ƥ��ٷֱȾͼ���:
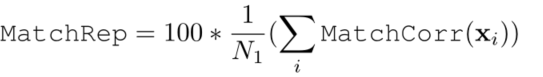
û�п���?
4.2.2��չʾƥ��Ч��


��������չʾ��Translation��Rotation��Scale��Random H���ֱ任��Ч����
- ���������ͼ,����ϸ�����Կ���ͼ�еĵ�������ͻҵ�����,�ҵ��ʾԭͼ,�����ʾ�任���ͼ��
- ��ɫ:��ʾgtƥ��,����������ȷ��ƥ���
- ��ɫ:��ʾ���ڽ������ҵ���ƥ���(�ӵ�һ�оͿ��Կ���,�����Ǽ�ƽ��,���㷨���ҵ���ƥ�����)
- ��ɫ:��ʾMagicWarp�ҵ���ƥ���,��������ɫ�ľ�����ȷƥ��һ��
4.2.3�����ֱ任�ڲ�ͬǿ����,MagicWarp��Ч��
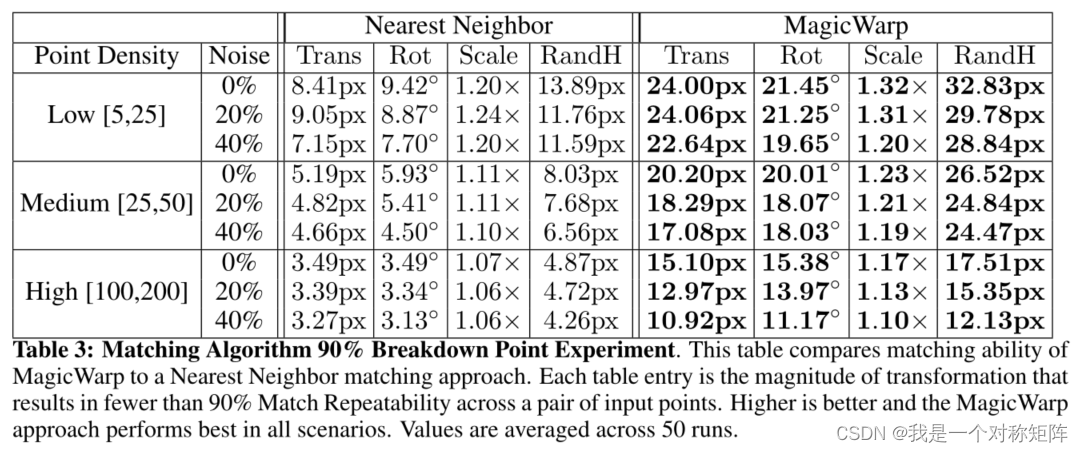
�ֱ�չʾ��Translation��Rotation��Scale��Random H���ֱ任��Ч��,�ڲ�ͬǿ����(����ƽ�Ƹ���,��ת����,���ű��������),ƥ��Ч����
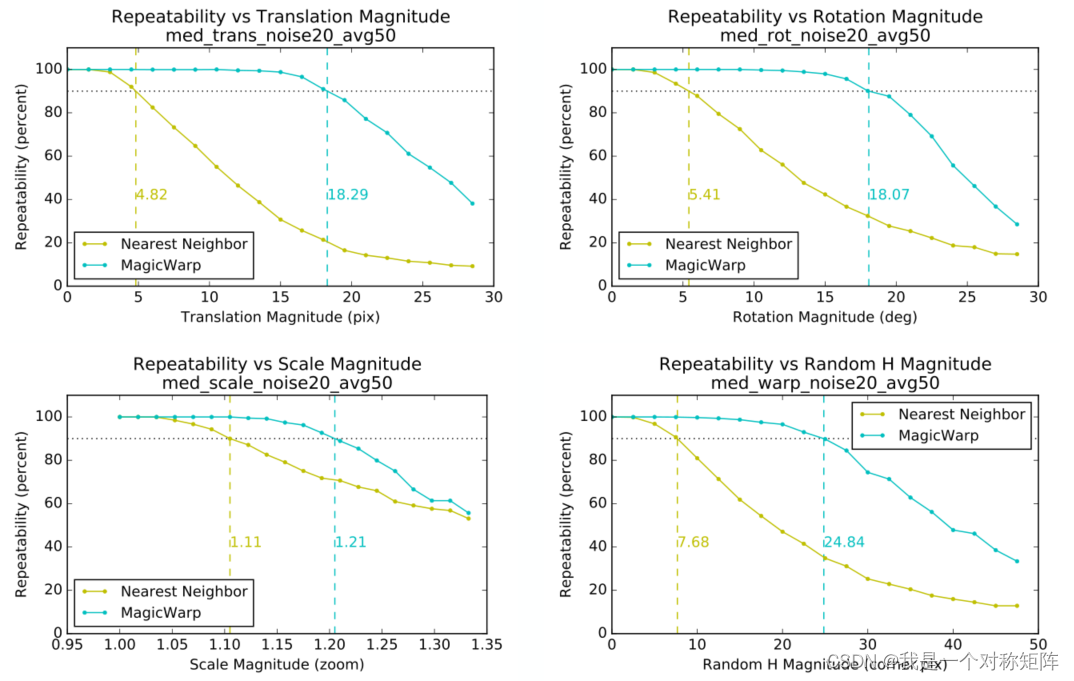
ע��,Ϊʲôͼ��ѡ����90%����ڵ�,����˵:��We choose 90% because we believe that a robust geometric decomposition using the correspondences should be able to deal with 10% of incorrect matches. Unsurprisingly, the MagicWarp approach outperforms the Nearest Neighbor matching approach in all scenarios.��,��ž���˵����90%�ľ��ȶ��ﲻ��,������˼˵�Լ���ϵͳ³��?
4.3����¼չʾMagicPoint��Ч��
ÿ��������6��ͼ,�ֱ���:MagicPoint����Ŀ��ӻ�ͼ;��������ͼ;��ǿ�ĸ��ʷֲ�����ͼ(ͨ��logʵ��);�������ֽǵ����㷨��Ч��ͼ;


