1. 回顾
前文 介绍了语谱图 的 定义, 并介绍了 大体产生语谱图的流程步骤,现在小结如下;
预处理部分:
- 预加重: 对原始信号预加重
- 分帧: 对信号分帧之后, 得到多帧;
- 加窗: 对每帧信号加窗;
得功率谱:
- 功率谱: 求每帧信号的功率谱:
第一步,对每一帧 做 FFT 变换, 得到各帧对应的频谱 spectrum ;
第二步, 对频谱spectrum 取其幅度值的 平方 ,再除以时间长度(时间长度对应于的FFT点数),从而得到每帧信号的功率谱;
- 对数功率谱: 在上一步骤得到的功率,求取其对数,得到对数功率谱;
语谱图:
- 将多帧对数功率谱, 在时间维度上 拼接就组成语谱图;
2. 信号的预处理部分
预处理部分中 包括 1. 预加重 2. 分帧 3. 加窗 ;
2.0 读取音频数据
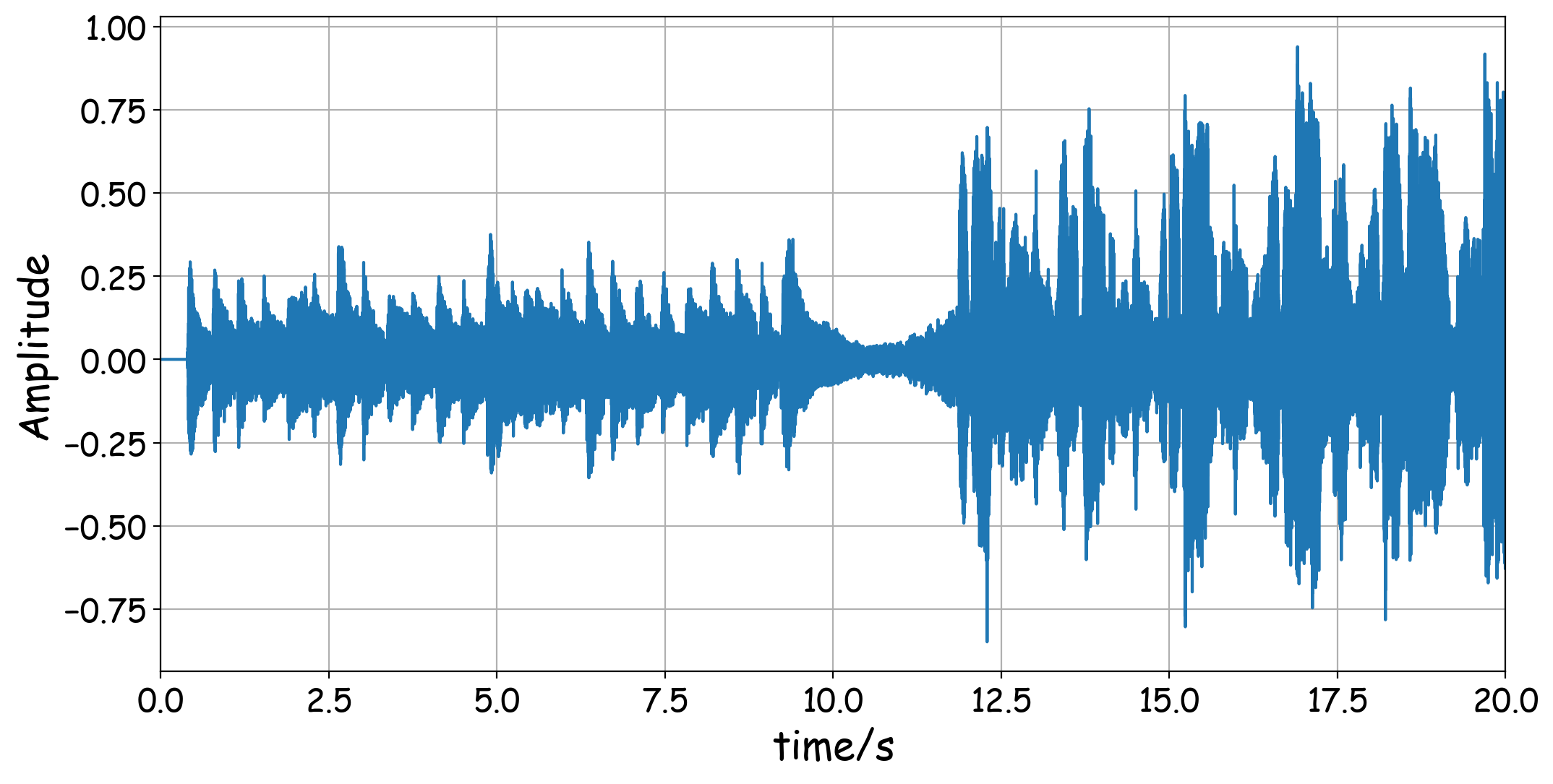
python可以用librosa库来读取音频文件,但是对于MP3文件,它会自动调用audio_read函数,所以如果是MP3文件,务必保证将ffmpeg.exe的路径添加到系统环境变量中,不然audio_read函数会出错。这里我们首先读取音频文件,并作出0-20秒的波形。现在的音乐文件采样率通常是44.1kHz。用y和sr分别表示信号和采样率。代码和图形如下:
import librosa
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import rcParams
import matplotlib.ticker as ticker
#这是一个画图函数,方便后续作图
def personal_plot(x,y):
plt.figure(dpi=200,figsize=(12,6))
rcParams['font.family']='Comic Sans MS'
plt.plot(x,y)
plt.xlim(x[0],x[-1])
plt.xlabel('time/s',fontsize=20)
plt.ylabel('Amplitude',fontsize=20)
plt.xticks(fontsize=16)
plt.yticks(fontsize=16)
plt.grid()
#注意如果文件名不加路径,则文件必须存在于python的工作目录中
y,sr = librosa.load('笑颜.mp3',sr=None)
#这里只获取0-20秒的部分,这里也可以在上一步的load函数中令duration=20来实现
tmax,tmin = 20,0
t = np.linspace(tmin,tmax,(tmax-tmin)*sr)
personal_plot(t,y[tmin*sr:tmax*sr])
2.1 预加重
通常来讲语音/音频信号的高频分量强度较小,低频分量强度较大,信号预加重就是让信号通过一个高通滤波器,让信号的高低频分量的强度不至于相差太多。在时域中,对信号x[n]作如下操作:

α通常取一个很接近1的值,typical value为0.97或0.95. 从时域公式来看,可能有部分人不懂为啥这是一个高通滤波器,我们从z变换的角度看一下滤波器的transfer function:
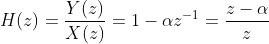
可以看出滤波器有一个极点0,和一个零点α。当频率为0时,z=1, 放大系数为(1-α)。当频率渐渐增大,放大系数不断变大,当频率到pi时,放大系数为(1+α)。离散域中,[0,pi] 对应连续域中的 0, fs/2。其中fs为采样率,在我们这里是44.1kHz。因此当频率到22000Hz时,放大系数为(1+α)。下面用两段代码和对应的图像给出一个直观感受:
alpha = 0.97
emphasized_y = np.append(y[tmin*sr],y[tmin*sr+1:tmax*sr]-alpha*y[tmin*sr:tmax*sr-1])
n = int((tmax-tmin)*sr) #信号一共的sample数量
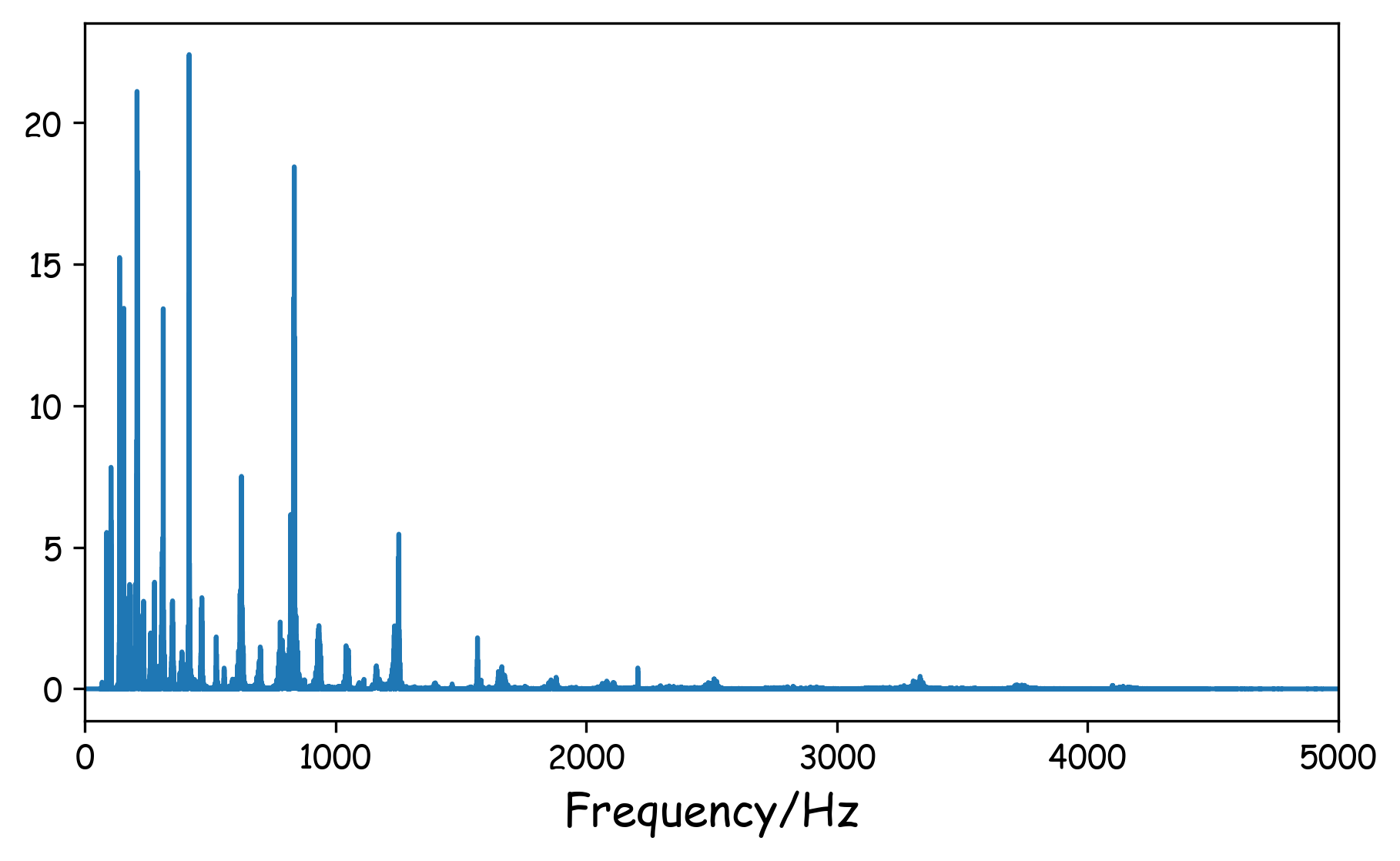
#未经过预加重的信号频谱
plt.figure(dpi=300,figsize=(7,4))
freq = sr/n*np.linspace(0,n/2,int(n/2)+1)
plt.plot(freq,np.absolute(np.fft.rfft(y[tmin*sr:tmax*sr],n)**2)/n)
plt.xlim(0,5000)
plt.xlabel('Frequency/Hz',fontsize=14)
#预加重之后的信号频谱
plt.figure(dpi=300,figsize=(7,4))
plt.plot(freq,np.absolute(np.fft.rfft(emphasized_y,n)**2)/n)
plt.xlim(0,5000)
plt.xlabel('Frequency/Hz',fontsize=14)
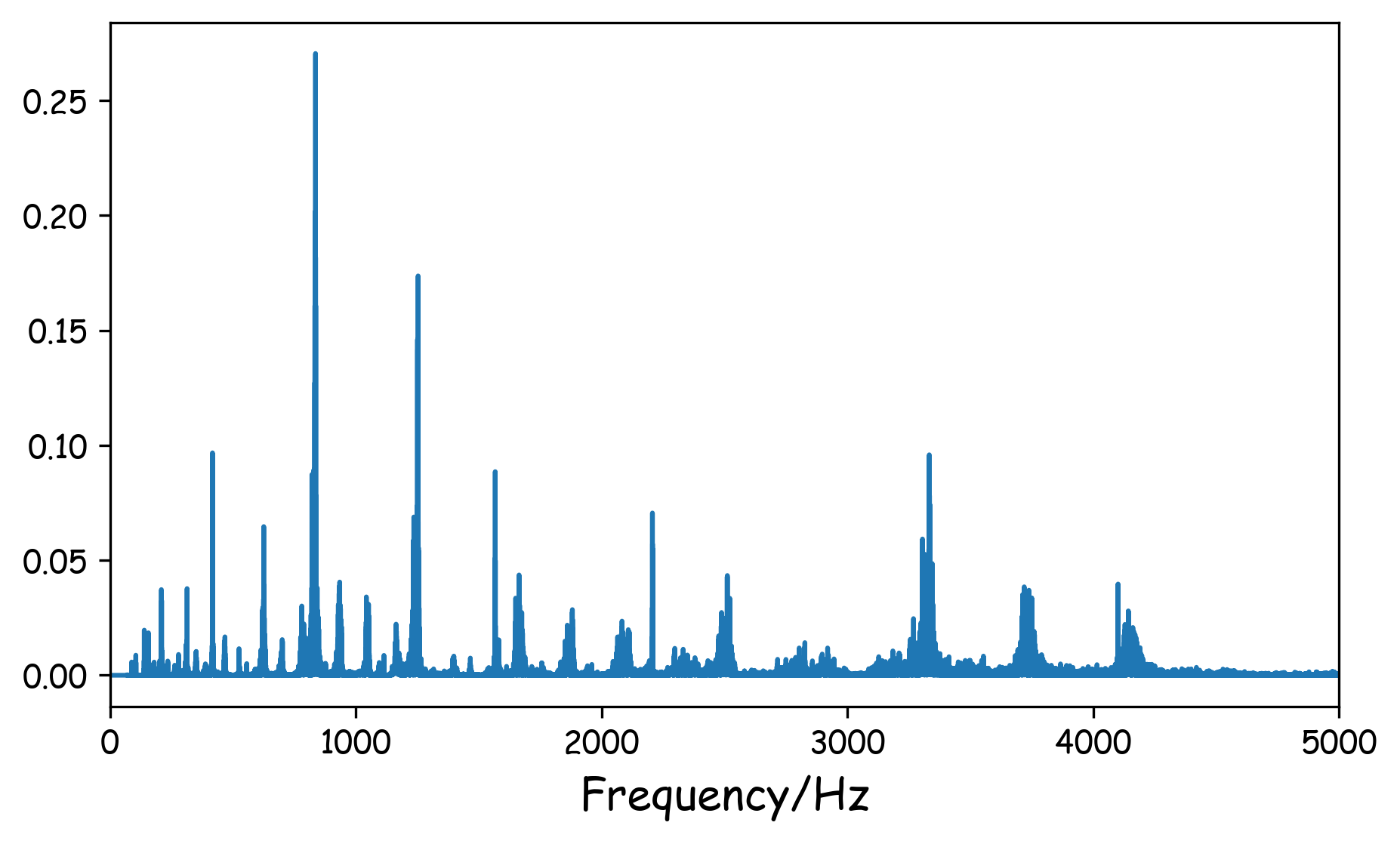
这两段代码里用了函数librosa.fft.rfft(y,n),rfft表示经过fft变换之后只取其中一半(因为另一半对应负频率,没有用处), y对应信号,n对应要做多少点的FFT。我们这里的信号有44.1k20=882000个点,所以对应的FFT 也做882000点的FFT,每一个点所对应的实际频率是该点的索引值fs/n,这是咋得出来的?因为第882000个点应该对应(约等于)fs(或者离散域中的2pi),所以前面的点根据线性关系一一对应即可。这里只展示0-5000Hz,可以看出,经过预加重之后的信号高频分量明显和低频分量的差距没那么大了。
这样预加重的好处有什么?原文提到了三点:(1)就是我们刚刚提到的平衡一下高频和低频 (2)避免FFT中的数值问题(也就是高频值太小出现在分母的时候可能会出问题) (3)或许可以提高SNR。
2.2 分帧
预处理完信号之后,要把原信号按时间分成若干个小块,一块就叫一帧(frame)。为啥要做这一步?因为原信号覆盖的时间太长,用它整个来做FFT,我们只能得到信号频率和强度的关系,而失去了时间信息。我们想要得到频率随时间变化的关系,所以将原信号分成若干帧,对每一帧作FFT(又称为短时FFT,因为我们只取了一小段时间),然后将得到的结果按照时间顺序拼接起来。这就是语谱图(spectrogram)的原理。
下面定义几个变量:
frame_size: 每一帧的长度。通常取20-40ms。太长会使时间上的分辨率(time resolution)较小,太小会加重运算成本。这里取25ms.
frame_length: 每一帧对应的sample数量。等于fsframe_size。我们这里是44.1k0.025=1102.
frame_stride: 相邻两帧的间隔。通常间隔必须小于每一帧的长度,即两帧之间要有重叠,否则我们可能会实去两帧边界附近的信息。做特征提取的时候,我们是绝不希望实去有用信息的。 这里取10ms,即有60%的重叠。
frame_step: 相邻两帧的sample数量。这里是441.
frame_num: 整个信号所需要的帧数。一般希望所需要的帧数是个整数值,所以这里要对信号补0(zero padding)让信号的长度正好能分成整数帧。
具体代码如下:
frame_size, frame_stride = 0.025,0.01
frame_length, frame_step = int(round(sr*frame_size)),int(round(sr*frame_stride))
signal_length = (tmax-tmin)*sr
frame_num = int(np.ceil((signal_length-frame_length)/frame_step))+1 #向上舍入
pad_frame = (frame_num-1)*frame_step+frame_length-signal_length #不足的部分补零
pad_y = np.append(emphasized_y,np.zeros(pad_frame))
signal_len = signal_length+pad_frame
2.3 加窗
分帧完毕之后,对每一帧加一个窗函数,以获得较好的旁瓣下降幅度。通常使用hamming window。
为啥要加窗?要注意,即使我们什么都不加,在分帧的这个过程中也相当于给信号加了矩形窗,学过离散滤波器设计的人应该知道,矩形窗的频谱有很大的旁瓣,时域中将窗函数和原函数相乘,相当于频域的卷积,矩形窗函数和原函数卷积之后,由于旁瓣很大,会造成原信号和加窗之后的对应部分的频谱相差很大,这就是频谱泄露。hamming window有较小的旁瓣,造成的spectral leakage也就较小。代码实现如下:首先定义indices变量,这个变量生成每帧所对应的sample的索引。np.tile函数可以使得array从行或者列扩展。然后定义frames,对应信号在每一帧的值。frames共有1999行,1102列,分别对应一共有1999帧和每一帧有1102个sample。将得到的frames和hamming window直接相乘即可,注意这里不是矩阵乘法。
indices = np.tile(np.arange(0, frame_length), (frame_num, 1)) + np.tile(
np.arange(0, frame_num * frame_step, frame_step), (frame_length, 1)).T
frames = pad_y[indices] #frame的每一行代表每一帧的sample值
frames *= np.hamming(frame_length) #加hamming window 注意这里不是矩阵乘法
2. 求功率谱
2.1 做FFT,求频谱
多帧信号做FFT, 在上一节中 获得了frames变量,其每一行对应每一帧,所以我们分别对每一行做FFT。
由于每一行是1102个点的信号,所以可以选择1024点FFT(FFT点数比原信号点数少会降低频率分辨率frequency resolution,但这里相差很小,所以可以忽略)。
2.2 取频谱模平方, 求功率谱
将得到的FFT变换取其magnitude,并进行平方再除以对应的FFT点数,即可得到功率谱。
注意: 此时 这里得到的功率谱 是指 将多帧的功率谱 进行拼接得到的功率谱;
此时 多帧信号的信号的功率谱 便组成 语谱图
NFFT = 1024 #frame_length=1102,所以用1024足够了
mag_frames = np.absolute(np.fft.rfft(frames,NFFT))
pow_frames = mag_frames**2/NFFT
plt.figure(dpi=300,figsize=(12,6))
plt.imshow(20*np.log10(pow_frames[40:].T),cmap=plt.cm.jet,aspect='auto')
plt.yticks([0,128,256,384,512],np.array([0,128,256,384,512])*sr/NFFT)

参考资料
Mel-frequency cepstrum
Mel Frequency Cepstral Coefficient (MFCC) tutorial
Notes on Music Information Retrieval
机器学习中距离和相似性度量方法
https://robinchao.github.io/2018/07/24/speech-recognation-mfcc.html
https://blog.csdn.net/weixin_50547200/article/details/117294164