��̬��������:ѧϰ���ڲ�̬ʶ����б�ͽ��ձ�ʾ
������Ŀ:Gait Lateral Network: Learning Discriminative and Compact Representations for Gait Recognition
paper���п�Ժ�Զ�����������ECCV 2020�Ĺ���
���ĵ�ַ:����
Abstract.
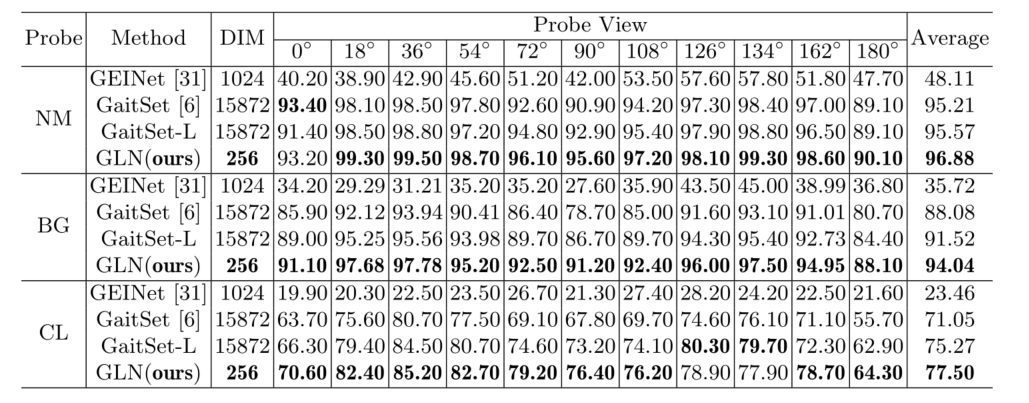
��̬ʶ���Ŀ��ʱ��ͨ������ģʽʶ��ͬ����,���������ߺ�������Զ�������ʶ�𡣲�̬ʶ���һ���ؼ���ս�Ǵ�������ѧϰ��ʾ,��Щ��ʾ���ܷ�װ��Я������������ӽǵ����ص�Ӱ�졣������ʶ��������б�����,��̬��ʾ��Ӧ���ǽ��յĴ洢,�Ա�����������������gallery��ע�ᡣ���������,���������һ����Ϊ Gait Lateral Network (GLN) ����������,�����ԴӲ�̬ʶ���������ѧϰ�б�ͽ��ձ�ʾ��������˵,GLN ������Ⱦ����������еĹ�����������������ǿ��̬��ʾ������ͬ����ȡ���������ͼ��ϼ����������϶��µķ�ʽ����������ںϡ�����,GLN �䱸��һ�� Compact Block,�����ڲ�Ӱ��ȷ�Ե���������Ž��Ͳ�̬��ʾ��ά�ȡ��� CASIA-B �� OUMVLP �Ĵ���ʵ�����,GLN ����ʹ�� 256 ά��ʾʵ�����Ƚ������ܡ��� CASIA-B �ϴ��Ų�ͬ�·����ߵľ�����ս�Ե�������,���ķ����� rank-1 ȷ������� 6.45%��
Keywords:
��̬ʶ��;��������;�б��Ա�ʾ;���ձ�ʾ��
1 Introduction
��̬ʶ��Ŀ����ʹ�ü�¼����ģʽ����Ƶ��ʶ��ͬ���ˡ���������ָ�ƺͺ�Ĥ�����������������,�˵IJ�̬������û�������ߺ����������Զ�����ȡ,������������Ԥ�������ҽ�������罻�ȷ���Ĺ㷺Ӧ�ð�ȫ��Ȼ��,��̬ʶ����ܵ��ܶ�仯��Ӱ��,�����װ��Я������������ӽǡ�һ���ؼ�����ս�ǴӶ��������ز���IJ�̬���е�������ѧϰ��ʾ��
Ϊ�˽���������,�Ѿ�����˸��ַ���,���¿��Է�Ϊ���ࡣ��һ�ཫ������̬���е������ۺϳ�ͼ��(��ģ��)�Խ���ʶ��,���粽̬����ͼ�����ܼ�,����Ԥ�����в��ɱ���ػᶪʧʱ���ϸ���ȵĿռ���Ϣ���ڶ����ǽ���̬���е�������Ϊ��Ƶ������,�� [40] ��,����3D-CNN����ȡ�ռ��ʱ����Ϣ,��ģ���������ѵ��������������������,����̬���е�������Ϊ����,����������������³����,��ȡ����������������Ȼ��,GaitSetѧϰ���ı�ʾ��ά�ȸߴ�15872,Զ��������ʶ��(180)��������ʶ��(2048)��ά�ȡ�
���������,���ߴ�����̬ʶ��,Ŀ���ǴӲ�̬ʶ���������ѧϰ�б�ĺͽ��յı�ʾ�������һ����Ϊ Gait Lateral Network(��ʾΪ GLN)����������,����ÿ����̬���е���������Ϊ���ϡ���ͼ 1 ��ʾ,�������ֲ�ͬ������,ÿ���������ϵ�ѧϰ��ʾ��Ӧ�����ܽ���,�����������صĴ洢����,�Ա�����������������gallery��ע�ᡣֵ��ע�����,GLN ѧϰ���ı�ʾ��ά�ȹ̶�Ϊ 256,��GaitSet��ȼ����˽�����������,����ͬʱ��������в������������ܡ�
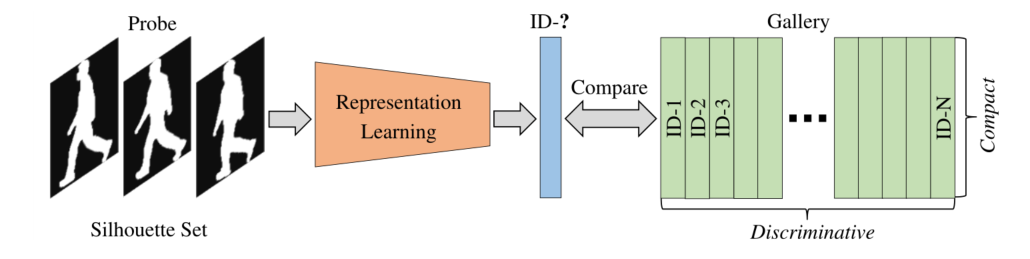
ͼ 1. ���������IJ�̬ʶ��ʾ��ͼ��ѧϰ���ı�ʾӦ�þ����б�����ʶ��ͬ����,���һ�Ӧ�ý����Ա��ڴ洢
������˵,�������������� CNN �еĹ���������������ѧϰ�б��ԵIJ�̬��ʾ����ͬ����ȡ��������������ĸ����Ӿ�ϸ�ڡ�ע��,��ͬsubject�����������������ֻ��ϸ�IJ���,��ʹ��̽�������ֲ��ռ�ṹ��Ϣ��dz���������ڲ�̬ʶ��������Ҫ���ر��,���߽�GaitSet��������Ϊbackbone,����������ȷ����Ϊ�����Ρ�����ͬ����ȡ���������ͼ��ϼ����������϶��µķ�ʽ����������ں�,��ͼ�ۺϲ�ͬ����ȡ���Ӿ�ϸ���Խ���ȷʶ��Ȼ��ͬ��ϸ���������ˮƽ�ָ���ѧϰ���ֱ�ʾ,�������н�������Ԫ����ʧ��Ϊ�м�ල������,���������һ����ӱ�Ľ��տ���ѧϰ���յIJ�̬��ʾ�������о�����,HPMѧϰ�ĸ�ά��ʾ���ڴ�������,HPM���㷺���ڲ��ֱ�ʾѧϰ��������Ľ��տ�����ڲ�Ӱ��ȷ�Ե�����½���ά��̬��ʾ����Ϣ�����ɽ��յı�ʾ�����ļܹ�����ƽ��,������backbone�켯�ɲ��Զ˵��˵ķ�ʽ����ѵ�������߽���ά��ʾ��Ϊ��ά��ʾ�ļ���,������ Dropout ѡ��һ��С�Ӽ�,Ȼ��ͨ��ȫ���Ӳ㽫��ӳ�䵽һ�����տռ䡣
���߶�������Ĺ���������������:(1)���������� CNN �еĹ�����������������ǿ��̬��ʾ��ʵ��ȷʶ�𡣽���ͬ����ȡ���������ͼ��ϼ����������϶��µķ�ʽ����������ںϡ� (2) �����һ�����տ�,���������Ž��Ͳ�̬��ʾ��ά�ȶ���Ӱ��ȷ�ԡ� (3) ���ɵ� GLN ���Դ����ڲ�̬ʶ���������ѧϰ�б��Եĺͽ��յı�ʾ�� CASIA-B��OUMVLP��ʵ�����,GLN ����ʹ�� 256 ά��ʾ�����в���������ʵ�����Ƚ������ܡ��ر��,�� CASIA-B�ϴ��Ų�ͬ�·����ߵ������ս�Ե�������,GLN ʵ�ֵ� rank-1 ȷ�ʳ����� GaitSet [6] �� 15872 ά��ʾ 6.45%��
2 Related Work
Motion-based Gait Recognition. ��Щ��������[1, 3, 16]��ͼ������ṹ���н�ģ,Ȼ����ȡ�˶��������в�̬ʶ��,���ŵ��Ƕ��·���Я����������³���ԡ�Ȼ��,����ͨ���ڵͷֱ��ʵ���Ƶ��ʧ��,��Ϊ�������ȷ�ع������������
Appearance-based Gait Recognition. ��Щ��������[17, 26, 8, 37]ֱ�ӴӲ�̬������ѧϰ����,������ȷ�ض�����ṹ���н�ģ,���ʺ��ڵͷֱ��ʵ�����,�������Խ��Խ��Ĺ�ע������ͨ������Ϊ����,һ���ؼ�����ս�Ǵ�������ѧϰ�Է�װ��Я������������ӽǵ����ؾ���³���Եı�ʾ�����������IJ�̬ʶ����Դ��·�Ϊ����,����������̬���е������ֱ���Ϊͼ����Ƶ�������ͼ�ϡ�
������Ӿ���������ѧϰҲ���㷺���ڲ�̬ʶ�𡣾�����˵,��[41]�ж����ڲ�̬ʶ�����Ⱦ��������������ȫ���о��� [46] �����һ���Զ����������,����ȷ�ֽ��ʾѧϰ�е���ۺ����������� JUCNet���粽̬�Ͷ��ز�̬�ල�붨�Ƶ���Ԫ����ʧ���ϡ�DiGGAN����Conditional GAN��ѧϰ�ӽDz���IJ�̬������ GaitSet��ÿ����̬���е�������Ϊ����,��ˮƽ�ָ�������ѧϰ���ڲ�̬ʶ��IJ��ֱ�ʾ,�Ӷ�ʵ��������߲��ڲ�ͬ���ݼ��ϱ���������ܡ�����,GaitSetѧϰ�������ձ�ʾ��ά��̫��,��15872ά��
Inherent Feature Pyramid. ��Ⱦ����������еĹ����������������������Ӿ������еõ����á�����,FCN���ò�ͬ�����������ϸ������ָ��Ԥ�⡣ Hypercolumns�����һ����Ч�ļ���������ۺϲ�ͬ��������Խ��ж���ָ�Ͷ�λ�� SSD�ֱ�ʹ�ò�ͬ�������������,�����ں������������
��GLN�����϶��µغϲ���ͬ�ε������ķ�ʽ�ܵ�FPN������,����Ŀ���⡣Ȼ��,���ĵķ���������������FPN��ͬ������,��GLN�������������������֧,��ͼ2��ʾ,GLN�еĺ������ӱ�����ͬʱ�ϲ��������ͼ��ϼ��������ڶ�,FPN�в�ͬ�ε�ѵ����ǩ�Ǹ��ݸ���Ұ�����,��GLN�в�ͬ�εļල�ź�����ͬ�ġ�����,FPN�ڲ�ͬ�ε�ͷ����������,��GLN�в�ͬ�εĺ�������ж���������
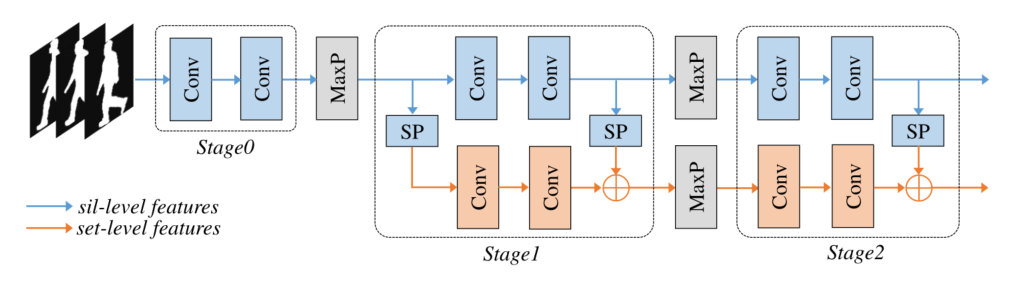
ͼ 2. backbone����ʾ��ͼ,Sil-level Ϊ Silhouette-level,MaxP Ϊ Max Pooling,SP Ϊ Set Pooling�������������Ǵ�ÿ�������зֱ���ȡ��,�����ϼ������Ǵ�������������ȡ�ġ� Set Pooling ��һ�־ۺ��������������IJ���
3 Our Approach
���������,���������һ����Ϊ Gait Lateral Network (GLN) ����������,�����ԴӲ�̬ʶ���������ѧϰ�б�ͽ��ձ�ʾ��������̬���е���������Ϊ���ϡ�����ṹ��ͼ3��ʾ��backbone�в�ͬ����ȡ���������ͼ��ϼ����������϶��µķ�ʽ����������ں�,Ŀ������ǿ��̬��ʾ��ʵ��ȷʶ�����������һ�����տ�,���������Ž��Ͳ�̬��ʾ��ά�ȶ���Ӱ��ȷ�ԡ���������,������ϸ˵�� GLN �еĺ������ӡ�Ȼ�����Compact Block����ɡ����,���� GLN ����Ӧѵ�����ԡ�
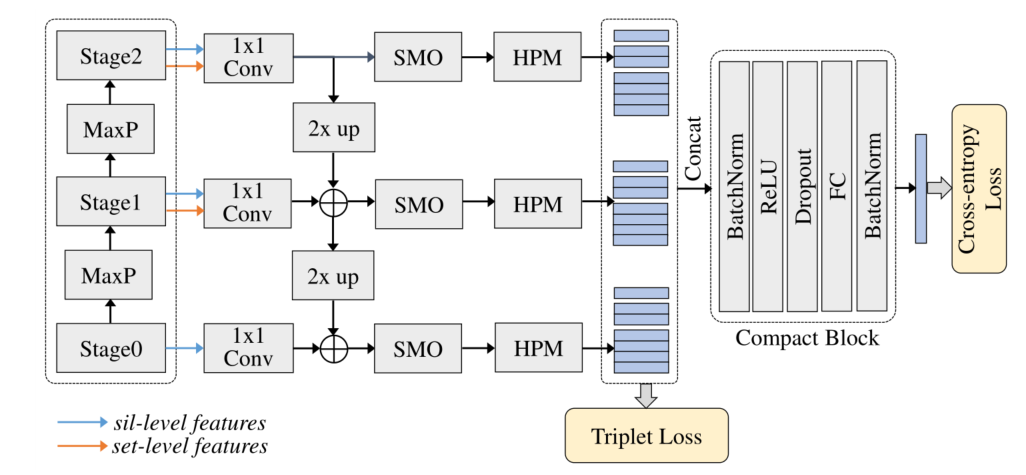
ͼ 3. ��̬��������ʾ��ͼ,Sil-level ������������,MaxP �������ػ�,SMO ����ƽ����,HPM ����ˮƽ������ӳ�䡣Ϊ�����,ʡ����ÿ�� 1 �� 1 1 \times 1 1��1������֮ǰ�����������ļ��ϳػ�,ʹ�ó߶� S = { 1 , 2 , 4 } S=\{1,2,4\} S={1,2,4}�� HPM ��ˮƽ�ָ��������� Compact Block �������Ϊ���ձ�ʾ
3.1 Lateral Connections
�� GLN ��,�������������Ⱦ����������еĹ���������������ѧϰ�б��ԵIJ�̬��ʾ���ۺ�backbone�в�ͬ����ȡ����������ǿ��̬��ʾ��
������˵,���߽�GaitSet��������Ϊ�ڶ��� Set Pooling �� Max Pooling ��˳����backbone����ͼ 2 ��ʾ,��ȷ�ؽ�backbone�еIJ��Ϊ�����Ρ���һ�����������������,���ǽ�����ת��Ϊ�ڲ��������ڶ��͵�������������֧���,�ֱ�ѧϰ�������ͼ��ϼ������� Set Pooling ��һ�־ۺ����������������ĺ���,��Ӧ�ö�������˳�����û������,����Ϊ������� Max Pooling ʵ�֡�
ע��,���ؿռ�ά��(�߶ȺͿ���)���еIJ�ͬ��֮��� Max Pooling ��ͬ,Max Pooling for Set Pooling �ؼ���ά�����С�backbone�����¶��ϵķ�ʽ��ȡ�����������Լ����ϼ���������������ȡ�������ֱ��Ϊ { C 0 , C 1 , C 2 } \left\{C_{0}, C_{1}, C_{2}\right\} {C0?,C1?,C2?},��������������IJ���Ϊ { 1 , 2 , 4 } \{1,2,4\} {1,2,4}��
backbone�в�ͬ�ε������������ĸ����Ӿ�ϸ��,������������϶��µķ�ʽ����ͬ����ȡ��������������Ӻϲ����ò�����ͼ 3 ��ʾ��������˵,����,�����������,���� Set Pooling ����������������,�����������ͨ��ά�ȵļ��ϼ����������������ڵ�һ��,ֻ����������������,��Щ����Ҳ�ɼ��ϳػ�������Ȼ����ÿ����,ȡһ�� 1 �� 1 1 \times 1 1��1�ľ�������������������������ͨ��ά�ȡ�������,���������ɵ�������ʼ,���ռ�ά��(�߶ȺͿ���)�ϲ��� 2 ��,�����ӵ���һ�����ɵ�����(�� 1 �� 1 1 \times 1 1��1������������ͬ��ͨ��ά��)ͨ��Ԫ����ӡ�������̲��ϵ���,ֱ�����н����ɵ����������ϲ������,��ÿ����֮��һ��ƽ����,�Լ������ϲ����Ͳ�ͬ��֮�������������Ļ��ЧӦ��ƽ����������ʾΪ�����ε� { F 0 , F 1 , F 2 } \left\{F_{0}, F_{1}, F_{2}\right\} {F0?,F1?,F2?},��Ӧ�� { C 0 , C 1 , C 2 } \left\{C_{0}, C_{1}, C_{2}\right\} {C0?,C1?,C2?},���Ƿֱ������ͬ�Ŀռ�ά�ȡ�
ע��, 1 �� 1 1 \times 1 1��1�������ƽ��������������ͬ��ͨ���ߴ�,ͨ��ʵ��̶�Ϊ256��ÿ��ƽ���㶼��һ�� 3 �� 3 3 \times 3 3��3�ľ�����ʵ�֡�����,���������в��漰�����Լ����,�ڲ�ͬ��֮��ʹ��������ϲ�����
3.2 Compact Block
���ڽ���ϸ�������տ�����,�ÿ鱻�������ѧϰ���ղ�̬��ʾ���ڴ�֮ǰ,���Ȼع�ˮƽ������ӳ��(HPM)��Ϊ����,����˸߱�ʾά�ȡ�
HPM �൱���� ReID ��ˮƽ��������(HPP),GLN ��������ѧϰ��̬ʶ��IJ��ֱ�ʾ��������Ч,�� HPM ��õı�ʾ���зdz��ߵ�ά��,����15872 ά��������˵,HPM����ʹ�ö���߶�
S
S
Sˮƽ�ָ�����,����
S
=
{
1
,
2
,
4
,
8
,
16
}
S=\{1,2,4,8,16\}
S={1,2,4,8,16}������ÿ���߶�
s
��
S
s \in S
s��S,����
F
F
Fˮƽ�ȷ�Ϊ
s
s
s����Ȼ��,����ȫ�����ػ���ƽ���ػ���Ϊÿ����������������
G
s
,
t
G_{s, t}
Gs,t?:
G
s
,
t
=
MaxPool
?
(
F
s
,
t
)
+
AvgPool
?
(
F
s
,
t
)
G_{s, t}=\operatorname{MaxPool}\left(F_{s, t}\right)+\operatorname{AvgPool}\left(F_{s, t}\right)
Gs,t?=MaxPool(Fs,t?)+AvgPool(Fs,t?)
����
s
��
S
s \in S
s��S��
t
��
{
1
,
?
?
,
s
}
t \in\{1, \cdots, s\}
t��{1,?,s}�����,��ȫ���Ӳ�Ӧ����
G
s
,
t
G_{s, t}
Gs,t?,�����ʾΪ
G
^
s
,
t
\widehat{G}_{s, t}
G
s,t?����ѵ����,��ʧ�����ӵ�ÿ�����ֵ������С������ڲ��Խ�,���в��ֵ�����������������Ϊ���յı�ʾ�����,���ձ�ʾ��ά����߶�֮��(����
sum
?
(
S
)
=
31
\operatorname{sum}(S)=31
sum(S)=31,����
S
=
{
1
,
2
,
4
,
8
,
16
}
)
S=\{1,2,4,8,16\})
S={1,2,4,8,16})��ÿ�����ֵ�����ά��(���� 256 ),�������ʵ�����Ӧ�ó����Dz����еġ�ͨ�������о� HPM �Ĺ�ʽ,�۲쵽��ͬ�߶ȵı�ʾ������һЩ�ظ�����Ϣ������,����Ϊ (s, t) = (4, 1) �� (s, t) = {(8, 1), (8, 2)} �IJ��ֱ�ʾ��Ӧ�����������е���ͬ������������Ʋ�HPM�õ��ĸ�ά��ʾ���ڴ������ࡣ
Ϊ�˽���������,���������һ�����տ�,��Ŀ�����ڲ�Ӱ��ȷ�Ե�����½���ά��ʾ����Ϣ�����ɽ��յı�ʾ����ͼ 3 ��ʾ,Compact Block ��һ���Ľṹ,����������һ�� (BN-I)��ReLU��Dropout��ȫ���Ӳ� (FC) ����һ��������һ�� (BN-II)���ÿ����Ч,�����������ṩÿһ������ԭ��:
- ����BN-I��HPM�õ���concatenated�������й�һ��,�������ȶ�ѵ��������
- ���� ReLU ��Ϊ����������� Compact Block �ķ����ԡ�
- Dropout �� Compact Block �Ĺؼ�����������,HPM ��õı�ʾ���Կ����ǵ�ά��ʾ�ļ��ϡ�������,���� Dropout ��ÿ����ά��ʾ��ѡ��һ��С�Ӽ���
- FC ���ڽ� Dropout �е�С�Ӽ�ӳ�䵽���߱�����Ŀռ��С� FC ��������������ձ�ʾ��ά��,ͨ��ʵ������Ϊ 256��
- BN-II ��������Ϊ�˷����Ż��������Ľ�������ʧ,����ѵ�����е�ÿ��subject������Ϊһ���������ࡣ
��֮,Compact Block ����̬��ʾ���ż��ٵ�һ���̶�ά��(����ʵ���е� 256 ��),����backbone�켯�ɲ��Զ˵��˵ķ�ʽ����ѵ����ע��,���߲�����PyTorch�е� Dropout ��ʵ�֡���ֻ��ѵ����������,������ʱ,���յı�ʾ���Ա���Ϊ�����Լ�ļ��ϡ�
3.3 Training Strategy.
GLN ��ѵ����������������:����Ԥѵ����ȫ��ѵ������ͼ 3 ��ʾ,ѵ�����漰�������͵���ʧ,����Ԫ����ʧ�ͽ�������ʧ���� HPM ֮������Ԫ����ʧ��Ϊ�м�ල,���� GLN ��ĩβ���ӽ�������ʧ��ѧϰȫ�ֱ�ʾ��
����,Ϊ�˻�ú����ĺ������ӳ�ʼ��,����˽�����Ԫ����ʧ�ල�ĺ���Ԥѵ����������˵,�����нε���Ԫ����ʧ��batch all�汾���ӵ�HPM�����нλ�õ�ÿ�����ֵ������С���ʽΪ:
L
t
p
=
1
N
t
p
+
��
s
��
S
��
t
=
1
s
?
bins
��
i
=
1
P?
��
j
=
1
K
?
anchors?
��
a
=
1
a
��
j
K
?
pos.?
��
b
=
1
b
��
i
P
��
c
=
1
K
?
negative?
[
m
+
d
s
,
t
,
i
,
j
,
i
,
a
s
,
t
,
i
,
j
,
b
,
c
]
+
d
s
,
t
,
i
,
j
,
i
,
a
s
,
t
,
i
,
j
,
b
,
c
=
dist
?
(
f
(
sil
?
i
,
j
s
,
t
)
,
f
(
sil
?
i
,
a
s
,
t
)
)
?
dist
?
(
f
(
sil
?
i
,
j
s
,
t
)
,
f
(
sil
?
b
,
c
s
,
t
)
)
\begin{aligned} &L_{t p}=\frac{1}{N_{t p_{+}}} \overbrace{\sum_{s \in S} \sum_{t=1}^{s}}^{\text{bins}} \overbrace{\sum_{i=1}^{\text {P }} \sum_{j=1}^{K}}^{\text {anchors }} \overbrace{\sum_{a=1 \atop a \neq j}^{K}}^{\text {pos. }} \overbrace{\sum_{b=1 \atop b \neq i}^{P} \sum_{c=1}^{K}}^{\text {negative }}\left[m+d_{s, t, i, j, i, a}^{s, t, i, j, b, c}\right]_{+}^{\text {}}\\ &d_{s, t, i, j, i, a}^{s, t, i, j, b, c}=\operatorname{dist}\left(f\left(\operatorname{sil}_{i, j}^{s, t}\right), f\left(\operatorname{sil}_{i, a}^{s, t}\right)\right)-\operatorname{dist}\left(f\left(\operatorname{sil}_{i, j}^{s, t}\right), f\left(\operatorname{sil}_{b, c}^{s, t}\right)\right) \end{aligned}
?Ltp?=Ntp+??1?s��S��?t=1��s?
?bins?i=1��P??j=1��K?
?anchors??a��?=ja=1?��K?
?pos.??b��?=ib=1?��P?c=1��K?
?negative??[m+ds,t,i,j,i,as,t,i,j,b,c?]+?ds,t,i,j,i,as,t,i,j,b,c?=dist(f(sili,js,t?),f(sili,as,t?))?dist(f(sili,js,t?),f(silb,cs,t?))?
����
N
t
p
+
N_{t p_{+}}
Ntp+??���� mini-batch �е��·�����ʧ�����Ԫ����,
S
S
S�� HPM �Ķ���߶�,
(
P
,
K
)
(P, K)
(P,K)��mini-batch��ÿ�������ߵ����������е�����,
m
m
m��margin threshold,
f
f
f��ʾ������ȡ,
sil
\text{sil}
sil��ʾ������,dist������������֮������ƶ�,����ŷ����þ��롣��ע��,�ں���Ԥѵ����,���ή��ѧϰ���Է�ֹ����ϡ�
Ȼ��,����ȫ��ѵ��,����Ԫ����ʧ�ͽ�������ʧ֮�Ͷ������������ѵ�������ڽ�������ʧ,ѵ�����е�ÿ�������߶�����Ϊһ����������,�������˱�ǩƽ����������ʽΪ:
L
c
e
=
?
1
P
��
K
��
i
=
1
P
��
j
=
1
K
��
n
=
1
N
q
n
i
j
log
?
p
n
i
j
L_{c e}=-\frac{1}{P \times K} \sum_{i=1}^{P} \sum_{j=1}^{K} \sum_{n=1}^{N} q_{n}^{i j} \log p_{n}^{i j}
Lce?=?P��K1?i=1��P?j=1��K?n=1��N?qnij?logpnij?
����
N
N
N��ѵ���������������ߵ�����,
p
p
p������ÿ�������ߵĸ���,
q
q
q����������Ϣ,��������(�Ե�
y
t
h
y^{th}
yth����������):
q
n
i
j
=
{
1
?
N
?
1
N
?
?if?
n
=
y
?
N
?otherwise?
q_{n}^{i j}= \begin{cases}1-\frac{N-1}{N} \epsilon & \text { if } n=y \\ \frac{\epsilon}{N} & \text { otherwise }\end{cases}
qnij?={1?NN?1??N????if?n=y?otherwise??
����
?
\epsilon
?��һ��С����,ʹģ�Ͷ�ѵ��������ô���С�ʵ����,
?
\epsilon
?����Ϊ 0.1�� Global Training ������ʧ��������:
L
=
L
t
p
+
L
c
e
L=L_{t p}+L_{c e}
L=Ltp?+Lce?
ע��,��ѵ����,�� Compact Block ֮����������һ��ȫ���Ӳ�������ÿ��subject�ĸ���,����������ʱ���á� Compact Block �������Ϊÿ�������������ձ�ʾ,��ƥ��probe��gallery��
Results
CASIA-B
OU-MVLP
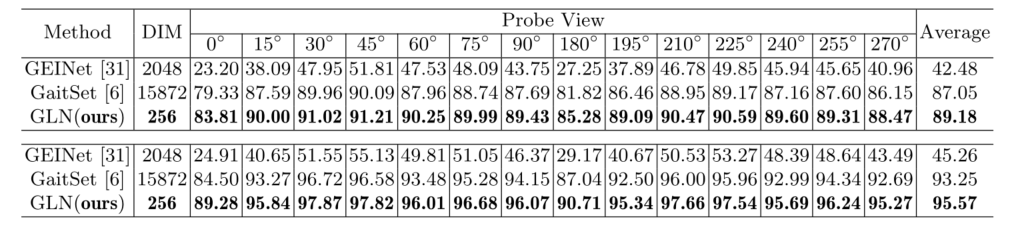
�����
[1]. Ariyanto, G., Nixon, M.S.: Model-based 3d gait biometrics. In: International JointConference on Biometrics. pp. 1�C7 (2011)
[3]. Bodor, R., Drenner, A., Fehr, D., Masoud, O., Papanikolopoulos, N.: View-independent human motion classification using image-based reconstruction. Imageand Vision Computing 27(8), 1194�C1206 (2009)
[8]. Han, J., Bhanu, B.: Individual recognition using gait energy image. TPAMI 28(2),316�C322 (2005)
[16]. Kusakunniran, W., Wu, Q., Li, H., Zhang, J.: Multiple views gait recognitionusing view transformation model based on optimized gait energy image. In: ICCVWorkshops. pp. 1058�C1064 (2009)
[17]. Kusakunniran, W., Wu, Q., Zhang, J., Ma, Y., Li, H.: A new view-invariant featurefor cross-view gait recognition. IEEE Transactions on Information Forensics andSecurity 8(10), 1642�C1653 (2013)
[26]. Makihara, Y., Sagawa, R., Mukaigawa, Y., Echigo, T., Yagi, Y.: Gait recognitionusing a view transformation model in the frequency domain. In: ECCV. pp. 151�C163 (2006)
[37]. Wang, C., Zhang, J., Wang, L., Pu, J., Yuan, X.: Human identification using tem-poral information preserving gait template. TPAMI 34(11), 2164�C2176 (2011)
[40]. Wolf, T., Babaee, M., Rigoll, G.: Multi-view gait recognition using 3d convolutionalneural networks. In: ICIP. pp. 4165�C4169 (2016)
[41]. Wu, Z., Huang, Y., Wang, L., Wang, X., Tan, T.: A comprehensive study oncross-view gait based human identification with deep cnns. TPAMI 39(2), 209�C226 (2016)
[46]. Zhang, Z., Tran, L., Yin, X., Atoum, Y., Liu, X., Wan, J., Wang, N.: Gait recog-nition via disentangled representation learning. In: CVPR. pp. 4710�C4719 (2019)