前言
import torch
import torch.nn as nn
from torch.nn.utils.rnn import pad_sequence
from torch.nn.utils.rnn import pack_padded_sequence
from torch.nn.utils.rnn import pad_packed_sequence
注意到上面的utils.rnn了没有?这几个函数“通常”都是用于RNN相关处理的。所以你得明白RNN的一些标准概念,然后5分钟你就能看懂了。
#假设我们有如下数据。
a=torch.tensor([1,2,3,4],dtype=torch.float32).unsqueeze(1)#[4,1]
b=torch.tensor([5],dtype=torch.float32).unsqueeze(1)#[1,1]
#shape[seq_len,emb_dim=1]
可以看到,两句话长度seq_len不一样。我们知道,现在的神经网络训练时都是采用mini-batch的方式,而这要求一个batch之内的数据长度要一样。
pad_sequence
我们希望,将上面两个数据制作成一个batch,但是长度不一样怎么办?
batch=[a,b]
real_batch=pad_sequence(batch,batch_first=True)
real_batch

无需解释,这个函数实现了数据长度一样。
pack_padded_sequence
上面那个real_batch被称之为padded_sequence(被填充的序列),这个pack的意思就是压缩的意思。
上面real_batch已经可以输入到神经网络里面了,还要这个函数干嘛?现在出发点是想要节省运算量,不想要让那些填充值进行RNN传播。
seq_len=[4,1]#第一个句子长度为4,第二个句子长度为1.
packed_real_batch = pack_padded_sequence(real_batch, seq_len, batch_first=True)
packed_real_batch

上面的这个对象也是pytorch官方RNN所支持的输入!!所以我们之前一头雾水就在这,我们一直以为RNN只支持格式为real_batch这样的对象作为输入。
我们先来分析一下这个对象先,第一个data就是我们的所有有效数据。batch_sizes指出,在RNN的第一个时间步里,data中的前两个要同时放到RNN里面作为输入,得到隐向量之后来到第2个时间步,batch_sizes指出,只需要将data中的1个输入到RNN中,…,依次类推。如下:

接下来,我们将上面这个对象输入到RNN中如下:
rnn=nn.RNN(input_size=1,hidden_size=3)
all_hidden,last_hidden=rnn(packed_real_batch)
print(all_hidden)
print(last_hidden)

可以看到!官方支持PackedSequence这种对象作为RNN的输入!并且和标准RNN一样,返回了两个结果(懂得都懂),但又有些不同。
- 第一个是PackedSequence对象,而标准RNN返回的是所有序列,每个位置的隐向量输出,形状是[batch_size,seq_len,hidden_size]。
- 第二个一模一样,是RNN每一个序列的最后一个位置的隐向量输出,形状是[batch_size,hidden_size]。
显然,如果我们只用RNN返回的第二个结果做业务的话,后面可以不用管了,但是如果要用到RNN返回的第一个结果,上面这种PackedSequence对象对后续处理不是很友好,于是有:
pad_packed_sequence
作用:对压缩的序列进行填充,哈哈,上面不就是压缩的序列PackedSequence吗?所以这就是一个逆操作:
all_hidden_real_batch,seq_len = pad_packed_sequence(all_hidden, batch_first=True)
print(all_hidden_real_batch)
print(seq_len)
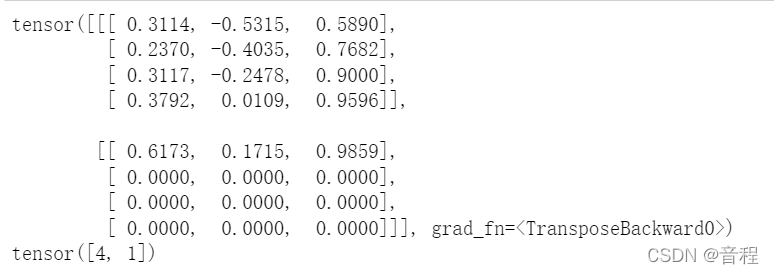
回来了。
注意
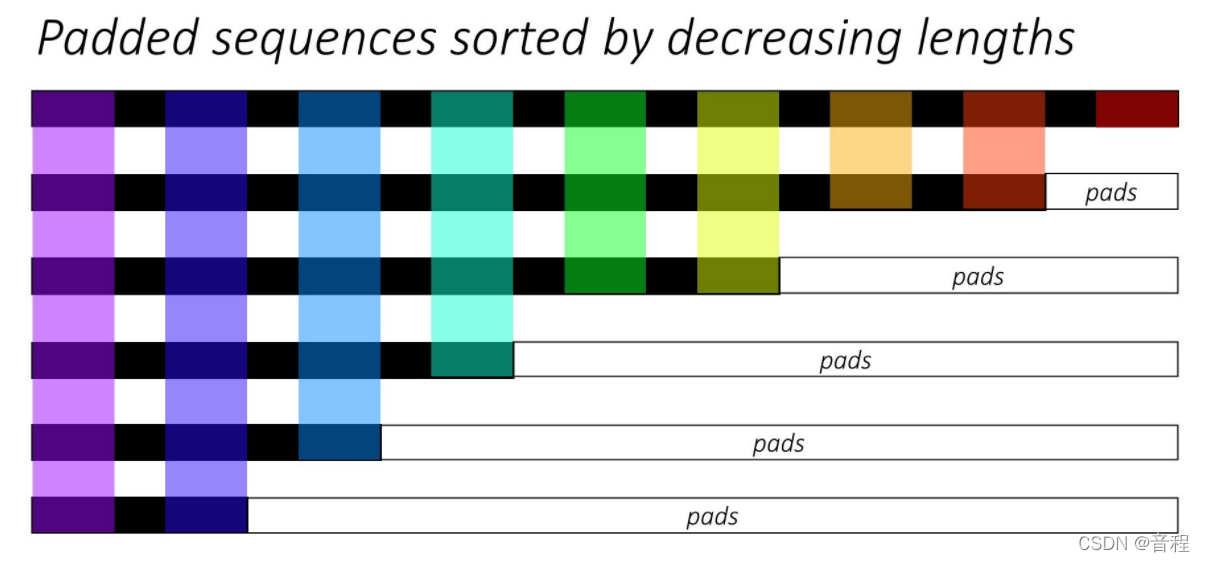
唯一一个要注意的点就是在一个batch中你的数据要按照序列长度降序排列,即长的在前面,短的在后面。
a=torch.tensor([1,2,3,4],dtype=torch.float32).unsqueeze(1)
b=torch.tensor([5],dtype=torch.float32).unsqueeze(1)
batch=[a,b]#正确。
batch=[b,a]#错误,依次带入前几个章节的函数可能出问题。
只要按照这个原则,你使用上面函数都不会有bug。如果不希望自己来排序,pack_padded_sequence有一个参数,你指定一下即可。