PISE: Person Image Synthesis and Editing with Decoupled GAN(人的图像合成和编辑与解耦GAN文献总结)
PISE:两阶段人物图像合成和编辑生成模型。首先通过解析生成器合成与目标姿态对齐的人体解析图来表示服装的形状,然后由图像生成器生成最终图像。
为了解耦服装的形状和风格,提出了结合全局和局部的每个区域编码和标准化来预测隐形区域服装的合理风格。还提出了空间感知的归一化,以保留源图像中的空间上下文关系。
1.介绍
本文中没有直接学习源到目标的映射,而是以人体解析映射作为中间结果,提供语义指导来预测合理的服装形状。
本文提出了基于语义区域的全局和局部的纹理编码和归一化,具体而言,对于源图像中可见的区域,利用对应区域的局部特征来预测服装风格。对于源图像中不可见而目标图像中可见的区域,通过获取源图像的全局特征来预测合理的服装款式。由于人类解析地图和每个区域的纹理控制,服装的形状和风格被解开,更灵活的编辑。
本文提出了新的空间感知归一化方法,将源图像的空间信息传递到生成图像中,经过逐区域归一化和空间感知归一化后,生成的目标特征经过解码器输出最终图像。
2.方法
本文提出的方法由两个生成器组成:一个解析生成器和一个图像生成器。
解析生成器的输入为:源姿势Ps,目标姿势Pt,源解析映射Ss.解析生成器通过目标姿势Pt生成人类解析映射Sg。人体姿势表示包括有人体姿态估计器(HPE)提取的18个关键点,它有18个通道,编码人体18个关节的位置。源解析映射Ss由部分分组网络(PGN)从源图像Is中提取。
图像生成器的输入为:源图像Is,源解析映射Ss,生成的解析映射Sg和目标姿势Pt。
总体结构如下图所示:

2.1 解析生成器
解析生成器负责生成与目标姿势一致的人体解析映射,同时保持源图像中人物的服装风格和体型。将输入:源姿势Ps,目标姿势Pt,源解析映射Ss由编码器嵌入到由M个下采样卷积层组成的潜在空间中(M=4),如下如所示:

使用封闭的卷积方式将所有像素视为有效信息,公式如下:
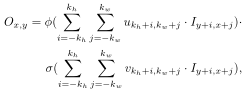
注:Ix,y和Ox,y表示(x,y)位置的输入和输出,kh=(ksh-1)/2,kw=(ksw-1)/2,ksh和ksw是核的尺寸。
该卷积方法可以学习每个空间位置的动态选择机制,适合于非对齐生成人物。
2.2图像生成器
图像生成器的目的是将源图像中各个区域的纹理传输到生成的解析映射。
首先用源人类解析映射Ps提取源图像Is的每个区域风格,然后使用规范化技术进行传输。本文中提出全局和局部区域平均池的联合提取源图像中区域的样式,然后将源图像Is、源解析映射Ss、生成的解析映射Sg和目标姿势Pt在深度维上进行拼接,提取其特征Fp。最后通过调节Fp的尺度和偏差来控制Fp的每个区域风格。本文提出了一种空间感知的归一化方法来保持源图像的空间上下文关系。经过空间感知归一化处理后,解码器将所需要的人物图像Ig发送出去。
2.2.1区域编码
给定源图像Is,首先使用4个下采样卷积层和两个转置卷积层的瓶颈结构提取其特征图。256通道的编码器的Fi输出包含源图像的空间上下文关系和样式。源解析地图Ss,解纠缠形式和样式通过提取样式信息,使用平均池来去除形状信息。
本文提出了全局和局部区域平均池联合提取源图像的样式公式如下:
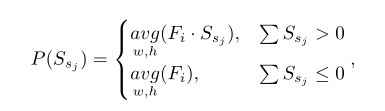
2.2.2区域标准化
从基本编码器生成的特征Fp包含输入信息,并与生成的解析映射Sg保持一致。使用每个区域的风格代码P(Ssj),通过调节其规模和偏差将风格转移到新生成的特征Fp,如下图所示:

2.2.3空间意识归一化
为了保持源图像的空间上下文关系,利用11卷积层从源图像代码Fi中提取空间尺度和偏置。
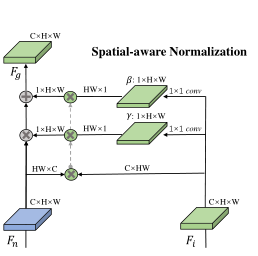
为了保留源图像的空间上下文关系,除了在空间使用11卷积层从源图像代码Fi中提取空间尺度(γ)和偏置(β)。使用γ和β来保留空间上下文关系。首先使用对应损失来约束Fn和目标图像的预训练的VGG-19特征之间的相似性,然后计算Fn与源图像Is的VGG-19特征的对应关系。这里使用通信层来计算矩阵:
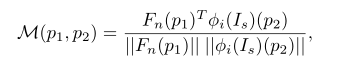
φ i表示VGG-19网络的第i层的激活映射,Fn(p1)和Fn(p2)分别表示位置p1和p2处Fn的信道方向几种特征。
表示每个位置的空间上下文关系的γ和β可以通过与相关矩阵M相乘从源图像转换到目标图像,然后通过调节比例和偏差,Fn进一步更新为Fg。最后,解码器输出最终图像Ig。