目录
基于随机森林算法的FY-4A云底高度估计方法-谭仲辉 2019
基于多维卫星数据的云底高度估计方法研究-华中科技大学梁帅 2020?
激光雷达数据反演方法

用于反演云层高度的记忆式滑动窗口积分算法 2008
单点回波信号无法判断是否有云存在,因为噪声可能会产生比有效信号更大的回波。然而云层与气溶胶相比,明显增强的回波信号包含了足够的云层信息。云层回波信号比气溶胶回波信号大,与随机噪声产生的峰值信号相比,脉冲宽度大得多。因此,如果把云层所在区域的所有回波信号累积起来,噪声在累积的过程中大部分会自动消除,则可以明显看出云层信号与气溶胶信号的区别。该方法实际上是通过积分消除噪声信息,同时将云层信息叠加放大,从而将其与气溶胶回波信号区别开来。所以云层处的积分值C(ω)必将远大于气溶胶的积分值。通过适当选取阈值Cth(ω)可以通过窗口积分值将云层信息提取出来。
为了保证将测量范围内的所有云层都提取出来,窗口从地面开始移动,一直移到探测的最远距离处。窗口每移到一个新的区域,就对该区域的回波信号进行积分,然后判断该处是否有云。如果有云,则进一步判断云底和云顶的位置(另外的算法单独实现)。窗口从云顶处继续向上移动,直到信号结束。因为反演云层信息时,是通过窗口的移动并对窗口内信号进行积分计算来判断的,因此该算法称为移动窗口积分算法。
窗口的大小,即D=Wh ―Wl的值要适中,D 值不能太小,太小则阈值Cth(ω)的选取很困难,有些叠加了噪声的信号可能不能有效地排除。同时D 值也不能太大,因为确定了云层信息之后,还要进一步确定云底和云顶的位置,而云底和云顶的位置可能在窗口内,也可能在窗口外。一般来说,如果窗口是从下向上移动的,则云底通常在窗口内,云顶在窗口外。窗口太大,给云底的搜索带来一定的困难。一般窗口的大小选择与薄云的厚度相当,为几百 m。
激光雷达探测合肥云层高度方法研究及分析 2010
云层高度反演方法主要有阈值法[3]、Klett 法[4]、微分法等。阙值法采用脉冲前沿鉴别 , 认为当激光回波幅度大于某预定阈值时所对应的高度位置即云底,但如果所测云结构稀薄 , 同时存在大气强散射 , 该法有可能出现误测。Klett 方法通过分析气溶胶消光系数的特点确定云层高度 , 但 Klett 法在计算消光系数时需要预先假设雷达比[5], 不确定性较大 ; 本文中采用改进后的徽分法是先对回波信号进行传统微分 , 通过微分信号的零点位置确定云底、云顶位置 , 再通过一定的算法剔除干扰零点 , 最后达到准确识别云层的目的。
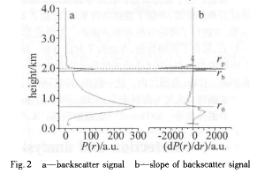
从激光雷达方程可以看出,在均匀大气中回波功率随距离呈指数递减。通常云的后向散射系数远大于气溶胶,所以,当激光传输遇到云层时,后向散射信号就有一个明显的峰值,随后信号会因为云颗粒的消光作用急剧衰减,经过一层较厚的云到达云顶时,信号幅度下降至和云底信号幅值类似,甚至更低[7]。 图2是典型的回波信号图。rb,rp分别是云底和云顶高度;r0是盲区点 , 从该点以后 , 激光出射的功率全部进入接收器的视野。图 2b 是图 2a 的导数图 , 图2a 中的云底rb 处对应图 2b 中从负到正的过零点 , 而云顶 rp 处则为从正到负的过零点。但通常所测信号图中常会出现多个峰值 , 如图 3 所示 , 这就有必要鉴别这些多峰值代表的是多层云或只是一个单层云的几个不连续部分。这里采用的判断依据是 : 若在两峰之间,回波信号因云层消光降至临界点 ( 这里的临界点通常选择云底信号 P(rb)) 或者比临界点更小的信号幅值,则判断为有多层云存在 ; 若信号虽下降但未至所选取的临界点 , 则可认为是这几个峰值属同一层云。

虽然从理论上讲 , 根据图中的过零点不难分辨出云底云顶 , 但在实际应用中 , 过零点的形成有多种原因, 如由非均匀状态大气、探测系统噪声等造成的 , 因此 , 在保留有关云层相关信息之前,先要剔除一些干扰过零点。采取的方法是先通过大量的雷达数据,得出由于系统或当日天气等其它因素造成的噪声信号值P(r noise) , 然后判断以下条件是否成立:?P(rp) - P(rb)<=2P(r noise) , 若满足该条件 , 则该过零点是干扰点 ,?可以去除。

图4中 rb1 (约1.6km)处出现多个峰值,其中第1个较大峰值和紧邻的小峰之间出现了过临界点值rb1,因此,可判断这是多层云;而在 rb2 之上,出现两个峰值信号,但之间信号并未降至rb2(约 8.5km),所以 rb2 以上的峰值信号为同一层云,云层相对厚度为1.5km,运用(2)式和(3)式求得此云的透过率T=0.953,光学厚度为0.04。
为更好了解云层光学信息,获知云层透过率和光学厚度,采用CHEN[8]的平方根法计算rb2处云层的透过率T,分别对云顶上部和云底下部一段区域内的 P(r1),P(rb)进行最小二乘法线性拟合,从拟合直线的方程式中求出P(r1)和P(rb)并代入到云层透过率 (2)式中,再根据(3)式求出光学厚度。
总结:分析激光雷达后向散射信号 , 介绍了微分法识别云层法的运用 , 并着重分析了在出现多个峰值信号时 , 如何有效判断单层云和多层云 , 得出了云底、云顶 , 云峰和云层光学厚度等重要信息 , 并给出了 2008 年 5 月 ~6 月两月间合肥云层变化趋势图 . 云底高度厚度分布图 , 最后将结果与云高仪 Vaisala,SAGEⅡ数据进行了对比和验证 , 结果表明 , 和传统的阆值识别法和 Klett 消光系数法相比 , 微分识别云层法简便可行、可操作性强、判别误报率低 , 为今后利用多种雷达探测技术 ( 偏振雷达、拉曼雷达 ) 以获取更多的云层光学信息 , 如云粒子谱分布、云成分构成等研究提供了一定的理论基础和数据参考。
用于反演云底高度的峰值面积积分算法-杨成武-2012
微分零交叉法通过对激光雷达回波信号微分寻找微分信号的零点位置,不同零点位置分别对应了云底、云峰和云顶的位置。 然而实际上,在非均匀的云和气溶胶环境下,回波信号微分的过零点有很多,且信号中的噪声也会产生很多额外过零点。 为此,Shiv R. Pal[3]等人通过采用多点平滑拟合、 计算各个零微分点对应信号的噪声等措施来剔除那些虚假的零微分点, 而保留显著的含有云层信息的零微分点。 但从众多零点中提取出有效的零点非常复杂,且易造成误判。 另外,在较低高度有很强的雾霾或在云层底部有降水时, 利用该方法确定云底高度会很困难。 滑动窗口积分法[4]存在的问题是窗口大小的选择会对分选结果产生很大影响:窗口太大会给云底位置的确定带来一定困难;窗口太小则很难选取阈值,有些叠加了噪声的信号可能不会被有效排除。 文中根据半导体激光云高仪回波信号的特点提出了一种新的云底高度反演算法。
综合考虑云层回波信号特点[7-8]不难发现:一 方面, 云层处回波信号值要比其他处回波信号的均值要大;另一方面,云层与气溶 胶 和 随 机 噪 声 相 比 ,云层的后向散射回波信号值比气溶胶大, 与随机噪声产生的峰值信号比,脉冲宽度又大很多,因 此,可通过窗口积分值的大小明显 看 出 云 层 信 号 与 气 溶 胶 、噪声的区别。
峰值面积积分算法
反演云层信息时是通过窗口的移动并对窗口内信号进行积分,以峰值和面积积分值作为判断准则来提取云层信息,因此该算法称为峰值面积积分算法。

如 图 2 所 示 ,由 于 云 层 信 号 的 值 为 正 ,只 考 虑基线右侧的值。将基线右侧的激光雷达回波信号划分 为 一 个 个 小 窗 口 ,窗 口 大 小 的 划 分 如 下 :从 图 形最 下 面 的 第 一 个 过 零 点 开 始 向 上 寻 找 相 邻 的 过 零点 , 如 果 这 两 个 相 邻 过 零 点 之 间 的 曲 线 在 基 线 右侧,那么该曲线和这两个相邻 过零点就组成了一个窗 口 ;如 果 该 曲 线 在 基 线 左 侧 ,则 去 掉 第 一 个 过 零点,以第二个过零 点为起点继续向上寻找相邻的过零 点 , 然 后 再 以 这 两 个 过 零 点 为 起 点 重 复 以 上 方法,就可以找到位于基线右侧的所有的窗口。 以 WH和 WL分别表示窗口的上下边沿, 对窗口内的回波信号进行积分为S(w),窗口内噪 声 的 积 分 ,在 一 段 区 间 内 趋 近 于 0。云层处的 S(w) 必将远大于气溶胶的积分值。 通过选取适当面积积分阈值 Sw和峰值阈值 Pw就可将云层信息提取出来。
峰值面积积分算法的流程如下:
(1) 取 激 光 雷 达 回 波 信 号 数 据 ;
(2) t =0;
(3) WL=0,WH=0,t=t+1, 以地面作为起点 ; t=t+1 中 的 “1”表 示下一条回波记录, 两条回波记录之间的时间差由激光雷达时间分辨率确定。
(4) 向上找到回波信号 值 等 于 或 大 于 0 的 点 WL, 以 该 点 为 起 点 , 继 续 向上 寻 找 回 波 信 号 值 第 一 个 等 于 或 小 于 0 的 点 WH;
(5) 利 用 公 式 (5) 计 算 积 分 St(w);
(6) 若 WH-WL≥length,计算此窗口内回波信号的最大值及其对应位置,其 中 length 为 窗 口 阈 值 ;
(7) WL=WH+1,以点 WL作为新的起点,若 WL超出探测范围,转 (11),否则转(4);WL=WH+1 中 的“1”表示下一个信号点所在位置 , 两个信号点之间距离由激光雷达距离 分 辨 率 确 定 ;
(8) 将以上计算的 St(w) 值从大到小排序,分别求出前 k 个窗口对应的面积积分和峰值的均值;(k 值是个经验值,一般取 10即可),
(9)选取合适的阈值, 以面积积分和峰值作为判断准则提取云层信息,若有云转(10),否则转(11);
(10) 判定云底位置,WL= 云底 ;
(11) 判 断 回 波 信 号 是 否 处 理 完毕,若没有,转 (2),否则退出。
实 验 表 明 , 该 算 法 对 不 同 类 型 的 云 均 能 有 效 反 演出 云 底 高 度 ,尤 其 对 高 度 较 低 、厚 度 较 薄 的 云 层 检测具有独特能力。 然而,实验中 也发现有些云层由于 中 间 叠 加 了 非 常 大 的 反 向 噪 声 信 号 , 导 致 中 间出 现 了 过 零 点 , 利 用 该 算 法 易 将 一 层 云 判 读 为 两层 云 , 因 此 应 对 该 算 法 反 演 出 的 云 层 结 果 进 行 必要 的 处 理 , 对 于 距 离 非 常 近 的 两 层 云 进 行 合 并 处理 ,或 者 与 其 他 算 法 反 演 结 果 进 行 比 对 ,综 合 处 理结果将更加准确。
卫星遥感-基于机器学习
基于随机森林算法的FY-4A云底高度估计方法-谭仲辉 2019
卫星遥感云底高度可分为主动遥感和被动遥感. 主动遥感如美国 A-Train 系列卫星中的 CloudSat 和 CALIPSO,利用星载毫米波雷达和激光雷达,能获取全球云廓线信息,但都只能沿轨进行垂直探测,覆盖区域十分有限[2];
被动遥感器如 MODIS( Moderate Resolution Ima-ging Spectroradiometer) 、VIIRS ( Visible Infrared Ima-ging Radiometer Suite) 等多通道辐射成像仪,已经有很多方法对云顶高度( CTH) 进行有效的反演[5-7],但星载多通道辐射成像仪只能获取云顶的可见光通道反射率、红外通道亮温以及垂直空间的水汽总含量等信息,无法准确得到云底信息,因此对云底高度的反演仍然是一个难题[8]。
随机森林算法训练
Breiman 等 建 立 的 随 机 森 林 ( Random Forest,RF) 算法[11]是一种用于分类和回归的集成学习方法,适 合 处 理 预 测 值 与 非 线 性 输 入 间 的 复 杂 关系[12].?
本文基于FY-4A与CloudSat 和 CALIPSO 在 2017 年 8 月至 10 月的匹配数据建立训练集. 首先进行数据预处理: 先进行云检测,然后基于 FY-4A 云分类产品,将有云样本分为6 类;
针对水云( water) 、过冷云( supercool) 和混合云( mixed) ,由于毫米波雷达对非透明云探测能力较强,以云顶高度( CTH) 、云光学厚度( COT) 、云有效粒子半径( CER) 、云液态水路径( LWP) 以及样本点的经纬度作为输入特征,以 CloudSat 最顶层云的云底高度作为目标输出,对每种云分别建立样本集.针对冰云( ice) 、卷云( cirrus) 和重叠云( overlap) ,考虑到激光雷达对光学厚度较小的冰云敏感性更好,以CALIPSO 最顶层云的云底高度作为目标输出.建立训练集后,对 6 类云分别进行随机森林的训练,并将训练过的模型输入到云底高度估计算法中.

云底高度估计算法,FY-4A 仅依赖自身上游产品和训练过的随机森林算法即可得到对最上层云云底高度的估计.算法的主要步骤如下:
A. 输入上游产品. 读取 FY-4A 的云检测、云分类、云顶高度以及云光学和微物理性质等产品;
B. 云检测. 对数据进行云检测,只针对有云样本点进行云底高度估计;
C. 云分类. 将云分为 6 类,对每类云提取相应的输入数据;
D. 输入随机森林算法. 将每类云的输入数据代入随机森林算法,得到云底高度估计结果;
E. 质量控制. 对估计的云底高度进行筛选,剔除无效值和异常值;
F. 输出。输出 FY-4A 对最上层云云底高度的估计结果.
此方法能对单层云云底高度进行有效反演,但对多层云的效果还有待提升。
星载激光雷达云和气溶胶分类反演算法研究 2019
云/气溶胶区分
(1) CALIOPV 算法以三参数 (532nm 后向散射系数、色度比和特征层中间高度 ) 的概率密度函数构建置信函数进行云 / 气溶胶分类 :
(2) Chen 等提出主被动遥感相结合的方法(CLIM) , 即引人 CALIPSO 卫星红外成像辐射计IIR红外波段数据以解决沙尘气溶胶的误判问题;
(3) Liu 等加入退偏比和纬度参数优化构建的置信函数提高分类精度
(4) Ma 等利用支持向量机来解决在有限样本数据条件下,实现云/气溶胶分类[8];
(5) Naeger 等利用 CALIOP 结合 MODIS 的红外波段数据解决云和沙尘气溶胶的误判
云相态分类
(1)CALIOP以云层顶温度,层底温度以及层积分退偏比构建云相态分类置信函数,将云粗略分为冰云、水云以及混合相态的云;
(2) Hu 等基于多年 CALIOP 观测数据的云相态特征综合分析结果,利用层积分散射系数和层积分退偏比,并参考云顶温度将云分为水云以及水平朝向冰晶粒子(HOD)、随机朝向冰晶粒子(ROI)的冰云,提高了云相态反演精度[10]
本工作针对中国地区,通过直接应用现有CALIOP观测结果来选择类别明确的大气特征层作为样本数据以提高分类精度,并将支持向量机和决策树方法引入云和气溶胶类型反演算法,该算法可以在保证分类精度的同时降低验证样本的需求数量,简化算法。
基于多维卫星数据的云底高度估计方法研究-华中科技大学梁帅 2020?

基于地基观测站的云底高度获取方法
激光雷达测云仪向空中发射不同光谱波段激光,当激光在传输过程中遇到云层时,会产生非常明显的后向散射信号,此信号与大气气溶胶散射信号以及噪声都有明显区别[7]。
2019 年,黄亚乔提出基于激光雷达测云仪的反演计算容易受到人的主观意识影响,为了使计算更加智能化、准确化,将机器学习算法应用到基于激光雷达测云仪的云底高度反演计算中[13]。
基于天基遥感的云底高度获取方法?
1980 年,美国国家航空航天局为改进气象服务工作,适应航空发展的需要,以及研究地球环境的动态变化,与加拿大、日本等国家合作,建立了地球观测系统(Earth Observing System? ,EOS)。2002 年 5 月,EOS 又发射了 Aqua 探测卫星,这两颗卫星均搭载有中分辨率成像光谱仪(MODIS)用于对云层进行研究。MODIS传感器根据可见光到长波红外等 36 个波段的信息,获取云顶高度、云顶温度等云物理性质及云光学性质[22]。2006 年 4 月 28 日,NASA 发射了 CloudSat 和 CALIPSO 主动遥感卫星,用于获取云层三维立体结构信息,完善天气和气候模式。如下图 1-3 所示,主动遥感卫星 CloudSat、CALIPSO 和被动遥感卫星 Aqua 运行轨道一致,且运行时间间隔区别较小,因此常用于基于天基主被动遥感的云底高度反演研究之中。
基于天基遥感的云底高度获取方法主要有两种,其一是同类型云云底高度外推技术,其二是先对云层厚度进行估测,再使用卫星成熟云产品获取的云顶高度与其相减对云底高度进行计算。同类型云云底高度外推技术使用主动遥感直接探测获取的云底高度,对被动遥感探测范围内的同类型云云底高度进行估计。这是由于 CloudSat/CALIPSO 等主动遥感卫星的观测重复周期较长,且观测轨道很窄,无法获得较大范围、高时间分辨率的云垂直分布特征[24]。但与其协同探测的被动遥感卫星观测范围较大,可以获得较大范围、高时间分辨率的云水平分布特征[25-26]。因此,可以利用主被动卫星资料,将有限点的云底高度扩展到其他区域。?

如上图 1-5 所示,宏观上的云分类方法可分为基于遥感卫星云图进行分类和基于云光学物理特征进行分类两大类。
基于云层厚度反演的云底高度估计方法首先对云层厚度进行估测,再使用卫星成熟云产品获取的云顶高度与其相减对云底高度进行计算。基于云层厚度反演的云底高度估计方法原理如下图 1-7 所示。?
2019 年,谭仲辉、马烁等研究人员以静止气象卫星的云光学性质、云物理特征作为模型输入,以 CloudSat 卫星探测的云底高度作为模型输出,使用 Random Forest机器学习算法训练建立云底高度反演模型,不再需要对液态水含量及云层厚度进行估计即可直接得到云底高度。实验结果表明,此方法能对单层云云底高度进行有效反演,但对多层云的效果还有待提升[53]。
基于主被动遥感特征融合的云底高度外推方法
第四章:基于主被动遥感特征融合的云底高度外推方法【1.3】
本章对以往的同类型云云底高度外推技术进行了改进,本章对以往的同类型云云底高度外推技术进行了改进,使用 Aqua 卫星MYD06_L2 数据产品中的云光学物理特征、地理特征、传感器位置特征等多维数据作为模型输入特征,以 CloudSat 云层类别作为输出,使用 XGBoost分类算法训练建立云层分类模型,将云分类为 Cirrus(卷云)、Altostratus(高层云)、Altocumulus(高积云)、Stratus(层云)、Stratocumulus(层积云)、Cumulus(积云)、Nimbostratus(雨层云)、Deep Convection(深对流云)。然后根据 CloudSat 卫星数据统计的各类型云云底高度,对待测点云底高度进行估计。

本文使用的数据来源于 Aqua 卫星和 CloudSat 卫星遥感,这是因为 Aqua 卫星与 CloudSat 卫星飞行轨道一致,对地观测时间接近,可以得到高精度的匹配数据集。针对其数据特征,本文进行了数据匹配,缺失值处理,异常样本处理,数据标准化,特征选择等数据预处理用于构建数据集。
本文所使用的 XGBoost(Extreme Gradient Boosting)算法是一种集成算法,它在梯度提升决策树(GBDT:Gradient Boosting Decision Tree)的基础上进行了改进和完善,是数据挖掘和机器学习中最常用的算法之一。而在处理表格数据方面,基于树模型的 XGBoost 算法则更适用。与深度学习相比,XGBoost 算法还具有更易于调参、模型可解释性好、输入数据的不变性等优点。?
梯度提升决策树首先使用初始训练集训练一个树模型,然后利用这个树模型对训练集进行预测,得到每个样本的预测值,再将预测值和真实值相减,得到“残差”。然后以残差作为学习目标训练下一个树模型,以此类推,通过设置树的总数或者某些指标(例如验证集上的误差)来停止训练。在对新样本进行预测时,将每棵树的输出值相加,即得到样本最终的预测值。?XGBoost 算法在梯度提升决策树的基础上进行优化改进,梯度提升决策树以传统分类回归决策树 CART 作为基分类器,而 XGBoost 算法还支持线性分类器。XGBoost 算法支持满足二阶连续可导的自定义损失函数,通过对其泰勒展开,引入一阶导数和二阶导数,而梯度提升决策树仅使用一阶导数。XGBoost 算法在损失函数中引入正则化项,有助于控制模型复杂度。XGBoost 算法在进行完一次迭代后,会将叶子节点的权重乘上衰减系数,削弱每棵树的影响,和梯度提升决策树的学习率类似。XGBoost 算法还支持列抽样来减少计算,降低过拟合,这也是 XGBoost 算法优于传统梯度提升决策树的一个特点。XGBoost 算法还支持并行,在进行节点的分裂时,需要选择增益最大的特征,而在计算各个特征的增益时可以并行计算[72]。
此方法的优点在于,只要云层分类的准确性足够高,对于低云的反演效果会比较好。此方法的缺点在于,对高云的反演效果较差,且不适用于对多层云体系下的云底高度进行估计。这是因为 MODIS 是被动遥感传感器,其难以穿透较厚的云层,不能很好地观测到多层云体系中的下层云,而根据 CloudSat 卫星数据产品统计得到的各类云云底高度,是单层云情况下此类云的云底高度。?因此,同类型云云底高度外推法并不适用于多层云体系下的最下层云云底高度估计。而对基于云层厚度反演的云底高度估计方法而言,需要先对云层厚度进行估计,然后由云顶高度减去云层厚度来得到云底高度。多层云体系下,根据被动遥感卫星获取的云顶高度是最上层云的云顶高度,从而无法根据该公式得到最下层云的云底高度。
特征优化的高维卫星数据云底高度反演方法
本章提出了一种特征优化的高维卫星数据云底高度反演方法,用以对多层云体系下的最下层云云底高度进行反演。?
