一、概述
意图识别是通过分类的办法将句子或者我们常说的query分到相应的意图种类。
举一个简单的例子,我想听周杰伦的歌,这个query的意图便是属于音乐意图,我想听郭德纲的相声便是属于电台意图。
做好了意图识别以后对于很多nlp的应用都有很重要的提升,比如在搜索引擎领域使用意图识别来获取与用户输入的query最相关的信息。
举个例子,用户在查询"生化危机"时,我们知道"生化危机"既有游戏还有电影,歌曲等等,如果我们通过意图识别发现该用户是想玩"生化危机"的游戏时,那我们直接将游戏的查询结果返回给用户,就会节省用户的搜索点击次数,缩短搜索时间,大幅提高用户的体验。
再进一步说,做好意图识别以后,我们可以将一个用户的query 限定到一个垂直领域比如通过意图识别以后发现该用户输入的生化危机就是想找"生化危机"的游戏进行下载,那么我们在游戏这个领域下进行搜索可以得到更高质量的搜索结果,进一步提高搜索体验。
我们再举一个目前最火热的聊天机器人来说明一下意图识别的重要性。目前各式各样的聊天机器人,智能客服,智能音箱所能处理的问题种类都是有限制的。
比如某聊天机器人目前只有30个技能,那么用户向聊天机器人发出一个指令,聊天机器人首先得根据意图识别将用户的query分到某一个或者某几个技能上去,然后再进行后续的处理。如果一开始的用户意图识别识别错了,那么后续的工作直接就是无用功了,会给用户带来非常不好的用户体验。
做好了意图识别以后,那种类似于电影场景里面人机交互就有了实现的可能,用户向机器发来的每一个query,机器都能准确的理解用户的意图,然后准确的给予回复。人与机器连续,多轮自然的对话就可以借此实现了。想起来真的是非常的激动。
二、意图识别的前提
1、意图的划分问题
在做这个工作之前,我们首先得想好意图的划分问题,这种划分业界有很多叫法,比如技能。
我们的聊天机器人有30个技能,潜在意思便是我们的意图有30类。
在2018年的CES上面,Google Assistant 号称有100万个技能,这个真的只能说太厉害了。
还有一种很通用的叫法叫领域 或者doamin。
搜索引擎中的垂域搜索的意思是把用户的query分为很多特定的领域比如电台领域,音乐领域。
搜索的时候根据意图识别认为这个query属于电台领域,于是便在电台领域进行搜索。如果意图识别的准确率比较高的话,这样便可以大大加快搜索的速度和准确性。
很多Google Assistant的技能也许只是简单的堆叠,但是对于聊天机器人来说,我们业界一直有个观点,意图识别虽然是聊天机器人非常重要的一个部分,但是解析用户的语义已经慢慢不再成为对话机器人的核心,识别用户的意图以后提供的服务开始成为对话机器人的产品差异化的核心。Goole Home 的100万个技能,绝对是这个领域杀手级别的竞争力。
2、意图识别的可扩展能力
其次是应该想好意图识别的可扩展能力,尤其是在搜索领域,对话系统领域,随着意图覆盖的范围急剧增加,如何保证意图的识别的准确率不下降甚至还能有提升其实是个很困难的事情,但是也非常的重要,甚至也许是意图识别最重要的一件事。不然你覆盖的技能数上去了,但是意图识别的准确率下来了,其实很多时候是没有什么意义的。
意图识别可扩展能力的另外一方面体现在简单技能的自动化生成,复杂技能的半自动化生成或者第三方开发者的开发技能的快速接入。
在可以预见的未来,对话机器人的技能增加速度会非常的快。类似于Google Assistant 的100万个技能,单凭人力或者某一家公司去开发100万个技能,得开发到猴年马月去了。自动化生成对话系统的技能,并且保持足够的开放性是每一家有追求的聊天机器人厂商应该严肃思考的问题。从业界来看,很多国内聊天机器人的公司这一块可能才刚刚起步,嘴上说着要开放,内心其实比较抗拒,工作排期排的很后。至于技能自动化生成也许还没有思考到这一步来。
3、技能的评价问题
当一个开发者开发完一个技能或者模型自动化生成一个技能以后如何评价一个技能生成的好坏也是非常重要的。简单一点来说虽然我们生成了一个技能,但是也不能生成一个技能就接入到我们的搜素引擎当中或者对话系统中来,必需得符合一定的标准。
比如我们在搜索引擎当中开发了音乐 domain的垂域搜索.
当我们的意图识别准确的判别用户的query"我想听周杰伦的歌"属于音乐这个domain,并将query分过来到音乐领域进行垂域搜索。
如果音乐的垂域搜索做的很差给用户返回的都是陈奕迅的歌。用户体验也不会很好。
就我看来,技能评价应该至少包括两个方面评价。
- 第一个方面是效果上面的,如果我们用precision和recall来评价的话,每一个接入的domain或者技能 的F1值必需大于某个值才可以接入。
- 第二个方面是工程上面的,每个接入的技能都必须考虑到访问量大了以后不能宕机。这个对本公司开发的技能不会有大的问题,但是第三方开发的技能,很多时候只考虑了功能的实现和效果上面的问题,往往不会考虑访问量或者qps大了以后怎么处理,结果就会造成整体服务超时。所以这一点也是需要慎重考虑的。
三、意图识别的基本方法
意图识别本质上就是对意图进行分类。而文本的分类与其它领域的分类在本质上没有区别,其流程顺序都是先进行特征表达,再训练分类模型进行分类。主要区别在于文本分类的特征表达更为复杂,提取难度比较大。常见的文本分类实现方法主要有以下几种:
1、基于规则模板的意图识别方法
传统的意图识别方法是将意图识别视为语义话语分类的问题进行研究,多用于单轮对话系统中意图的检测,其主要包括:
- 基于规则模板的方法;
- 基于统计特征的方法;
基于规则模板的意图识别方法主要针对于简单场景下短对话文本的意图识别。它通常需要人工构建规则模板和类别信息,即什么关键词对应什么类别,然后根据匹配成功的规则模板进行语义解析与推理,识别出用户的意图[55]。如图2.2所示,例如对于“我查询一下上周办理的联名卡进度”这一段语句。它对应分词后的结果为“我/查询/一下/上周/办理/的/联名卡/进度”。则人工构建的规则模板可以定义为:“^$[Who]$查询 $[*]$[Time]$办理$[*]$[What]$进度$”。其中“^”是句首标识符,它标记着整个字符串 的开始位置。“*”是可以匹配任意个数的任意字符。“$”是字或词组结束的标识符,它代表着字或词组的结束位置。“查询、办理、进度”相当于是数学中的常量。“Who、 Time、What”则对应着是数学中的变量。根据上述定义的规则模板,手工将其映射为“办卡进度”。在意图检测过程中,只要符合上述规则模板的表述,则对应的意图可以标记为“办卡进度”。
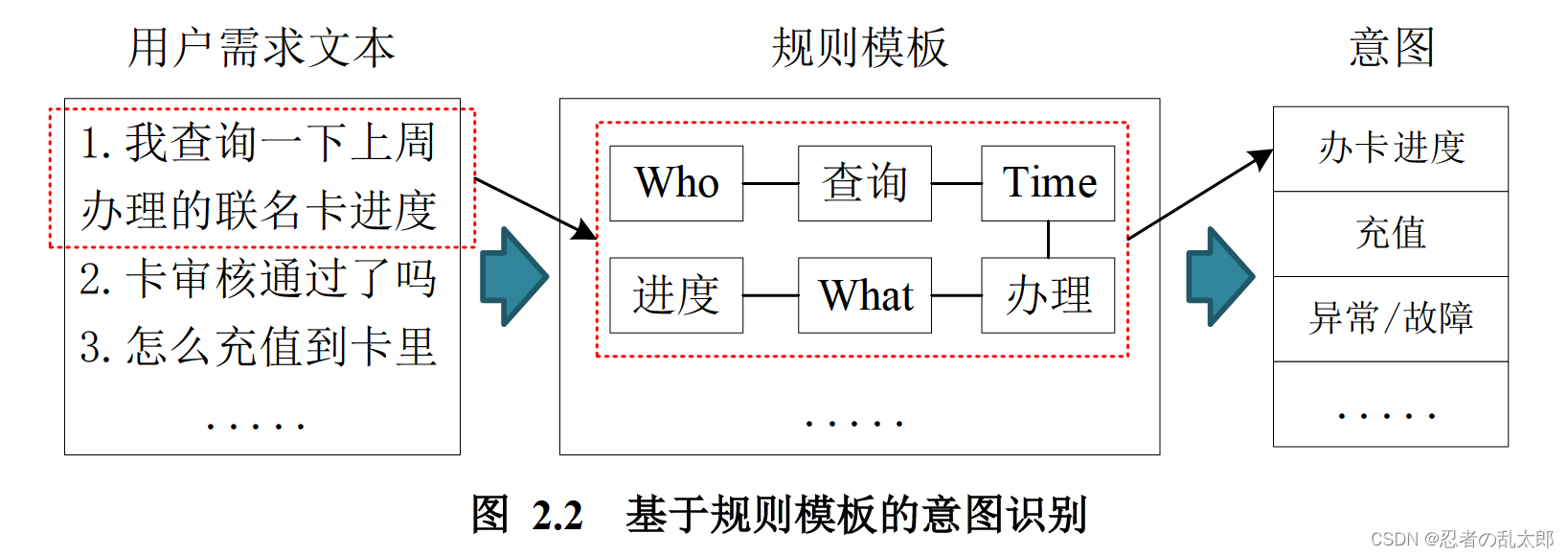
从图中样例可以看出,基于规则模板的意图识别方法虽然简单,但在规则模板定义时,比较繁杂,需要大量的人工干预,非常耗时,更为重要的是不方便在其它领域上的迁移使用。
早在二十世纪中期,就有国外学者开始了对于文本分类相关技术研究。
学者 Luhn 等人[22]提出了采用统计词频概率来确定文本类别标签。这种算法过于机械,效果并不明显。
到了六十年代,第一篇关于文本分类技术的学术论文由Maron等人[23]在ACM期刊 上发表,他们在文本分类任务中使用了关键字自动分类的技术,这种技术只能用于特定领域,适用度较低,费时费力。
到了八十年代,以知识工程为基础的文本分类算法被提出,这种算法需要专家根据预先定义好的类别标签制定类别规则,再套用这些规则对文本进行分类。
Ramanand[24]等人通过制作规则模板来识别用户的消费意向,在单个领域取 得了较好的分类效果。基于规则模板的方法虽然可读性强,但不能脱离人工制定规则的环节,难以扩展。
不同的意图会有的不同的领域词典,比如书名,歌曲名,商品名等等。当一个用户的意图来了以后我们根据意图和词典的匹配程度或者重合程度来进行判断,最简单一个规则是哪个domain的词典重合程度高,就将该query判别给这个领域。
这个工作的重点便是领域词典便须得做的足够好。
2、基于传统机器学习的意图分类方法
面对日益增长的海量的、多样化的文本数据,早期基于规则和关键词的分类方法逐渐到达了瓶颈。与此同时,AI技术的高速发展,使得许多学者开始探索将机器学习技术迁移应用到文本分类领域中。
传统的机器学习模型通常是利用统计学原理,从预先标记好的语料中学习其内在的分类规律,然后进行类别检测[25]。
基于传统机器学习的文本分类方法通常有很多。
例如Ogura等人[26]通过深入研究了不平衡文本分类问题,提出了用于改善样本不平衡情况下 分类性能的三种不同类型的指标。
Chen 等人[27]提出了一种能够有效减少样本数量,加快搜索的k-最近邻算法。
Rocha等人[28]在电影评论情感分析任务上研究集成了遗传算法 和支持向量机(SVM)[29]的特征选择方法,并且取得了很好的分类效果。
Fu 等人[30]应 用了隐含狄利克雷分布(LDA)模型来解决开放领域的文本分类问题。
李锋刚等人[31]充分结合了 SVM 算法和 LDA 算法的优点提出了一种高效的分类算法模型。
钟磊[32]提出了一种分类精度较高的以遗传算法为基础的朴素贝叶斯分类器。
沈晶磊等人[33]通过将实际问题转化为分类问题,实现了基于随机森林算法的推荐系统。
总之,虽然基于传统机器学习的方法在文本分类领域有了较为成熟的应用,但也存在着特征表达能力弱,不能解决稀疏矩阵的问题,依赖于大量标注好的训练语料,且具有昂贵的人工成本等缺点。
因此,探索更为优秀的分类算法就显得非常有必要了。
3、基于查询点击日志
如果是搜索引擎等类型业务场景,那么我们可以通过点击日志得到用户的意图。
4、基于深度学习的意图分类方法
深度学习技术最先起源于人工神经网络,其之所以能在图像和语音取得巨大成功:
- 一方面是因为深度学习模型具有强大的特征提取能力和建模优势;
- 另一方面是由于图像数据和语音数据具有共同的特点。它们通常是连续、稠密的,并且具有很强的局部相关性。
然而,为了解决传统基于机器学习的方法的不足,研究人员开始考虑在自然语言处理领域中融入深度学习技术。
难点:标注数据获取;(来源:一. 数据标注团队进行数据标注;二. 通过半监督自动生成标注数据)
四、数据增强
当前意图识别工作的难点有很多,在之前的介绍中也提到了一些,但是最大的难点其实是在于标注数据的获取。目前标注数据的获取主要来自两方面,一方面是专门的数据标注团队对数据进行标注,一方面是通过半监督的方式自动生成标注数据
数据增强是扩充数据样本规模的一种有效地且非常有用的方法。数据的规模越大、质量越高越好,模型才能够有着更好的泛化能力。对于不同类型的数据,其数据增强方法有着很大的区别。对于图像类的数据,将其进行简单的旋转或转为灰度,并不会改变其语义,而语义不变的增强方法是计算机视觉领域研究中的一个重要工具[67]。对于文本类数据的扩增则不能像图像那样进行简单旋转变换得到。
常见的文本增强技术有:
- 词汇替换;
- 随机噪声注入;
1、词汇替换
基于词汇替换的数据增强方法通过在不改变句子主旨的方式下替换原文本中的词组形成新的语料。常见的方法有以下三种。
1.1 基于词典的替换
基于词典的替换,即随机选取句子中一个词组替换成该词组的同义词。
Zhang 等人[68]提出的基于字符级 CNN 的文本分类方法中就使用了这项技术,通过实验 证明将词组替换为它的同义词进行数据增强的方法可以在很短的时间内生成大量的数据,且非常有效的。Wei 等人[69]在他们提出的 Easy Data Augmentation 中就采用了这种方法。
1.2 基于词向量的替换
第二种是基于词向量的替换,即采用向量空间中距离最近的词组替换原始句子中的词组。Tinybert[70]中采用的就是这种方法。Wang 等人[71]采用这种方式,通过对 Tweet 语 料进行数据增强来学习主题模型。如图 2.8 所示,他们通过在 Tweet 语料上训练的词向 量上找到单词awesome的三个同义词替换原始句子中的单词,即可得到原始句子的三个变体

最后一种是由 Xie 等人[72]提出来的基于 TF-IDF 的替换。在不影响句子的基本真值 标签的情况下,替换TF-IDF值较低的词组。
2、随机噪声注入
通过在文本中引入噪声来生成新的文本语料,使得所训练的模型对扰动具有鲁棒性。
常见的有:
- 拼写错误注入;
- Unigram噪声;
- 空白噪声;
- 随机插入、交换、删除等。
拼写错误注入是通过随机将一些单词拼写错误,如“is”转换成“id”,类似于中文 的形近字替换;Unigram 噪声和空白噪声是由 Xie 等人[73]提出的,Unigram 噪声的思想 是用从单字符频率(每个单词在训练语料库中出现的次数)分布中采样的单词进行替换,而空白噪声则是利用占位符随机替换单词;随机插入、交换、删除是Wei等人[69]提出的。 随机插入(Random Insert,RI),则在文本的句子中随机选择一个非停用词,然后找到其 对应的同义词,最后将同义词随机插入文本的句子中(位置不固定);随机交换(Random Swap,RS)和随机删除(Random Deletion,RD),则分别交换两个单词的顺序和以一定 的概率随机删除句子中的单词。考虑到由语音转录的对话文本可能出现漏字或错误转录的现象,故本文第二个工作内容则是采用的是随机删除、随机同音字替换以及同时进行删除和同音字替换方式来模拟现实对话场景进行数据增强,以构建出更具有鲁棒性的意图识别模型。
3、其他数据增强技术
Luque等人[74]在他们的论文中提出了一种实例交叉增强的技术,这项技术的灵感来 自于遗传学中发生的染色体交叉操作。在情感数据集中,两条语料各自被分成两部分,然后两个相同情绪的语料各自交换一半内容,如图2.9所示。
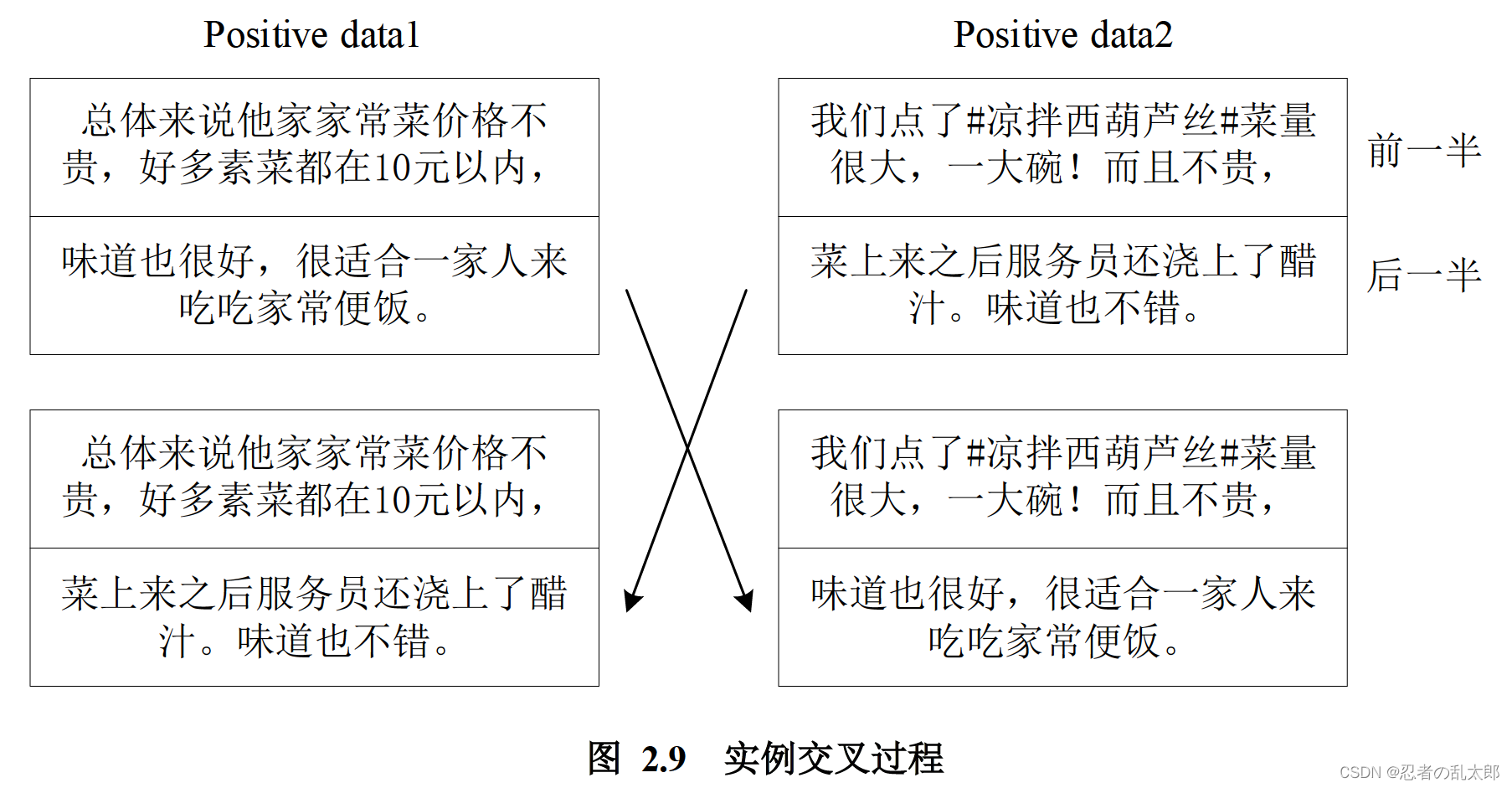
虽然结果在语法和语义上可能不健全,但新的文本仍将保留原来的情绪类别。这种方法对准确性没有影响,并且在F1-score上还有所提升,这表明它帮助了分类模型提升了在罕见类别上的判断能力。Guo等人[75]提出了应用Mixup到文本中的方法,分别是基 于单词和基于句子的混合,首先随机选取两个句子(单词),其次进行向量化,为保证向量等长,使用 0 填充;然后将两个句子(单词)的 word embeddings 按比例进行合并; 最后将合并后的向量传入到神经网络中进行学习权重,交叉熵loss用于给定比例的原始 文本的类别。这个方法最初被 Zhang 等人[76]提出来应用在图像上,即随机挑两张图片, 然后按比例合成新的图片,这些图片就合并了两个类别的信息,在训练过程中起到正则
化的作用。Kumar 等人[77]提出了基于生成模型的技术,即使用 transformer 模型来扩展训 练数据。总之,这些文本数据增强的方法,对基于数据驱动的模型来说,是非常有效的,特别是数据稀少的领域。
五、总结
本次介绍了意图识别是什么,意图识别的重要性,意图识别的难点以及后续的博客计划,本质上来说意图识别是属于文本分类的一种,和情感分析这类工作没有什么很大的区别。但是相比于情感分析,意图识别的分类种类要比之前多了很多,准确性以及可扩展性的要求也高了不少。敬请期待后续博客的更新。