AI编译器TVM部署示例解析
AI编译器TVM(一)――一个简单的例子
概述
什么是TVM?
TVM可以称为许多工具集的集合,这些工具可以组合起来使用,实现一些神经网络的加速和部署功能。这也是为什么叫做TVM Stack了。TVM的使用途径很广,几乎可以支持市面上大部分的神经网络权重框架(ONNX、TF、Caffe2等),也几乎可以部署在任何的平台,如Windows、Linux、Mac、ARM等等。
参考文献
https://oldpan.me/archives/the-first-step-towards-tvm-1
https://mp.weixin.qq.com/s?__biz=Mzg3ODU2MzY5MA==&mid=2247484929&idx=1&sn=3fcce36b5a50cd8571cf932a23083667&chksm=cf109e04f86717129c3381ebeec2d0c1f7baf6ed057c66310662f5935beea88baf23e99898f4&token=1276531538&lang=zh_CN#rd
https://mp.weixin.qq.com/s?__biz=Mzg3ODU2MzY5MA==&mid=2247484930&idx=1&sn=ddc3da7b72c900ce2f8e6aad99a9e788&source=41#wechat_redirect
以下面一张图来形容一下,这张图来源于(https://tvm.ai/about):
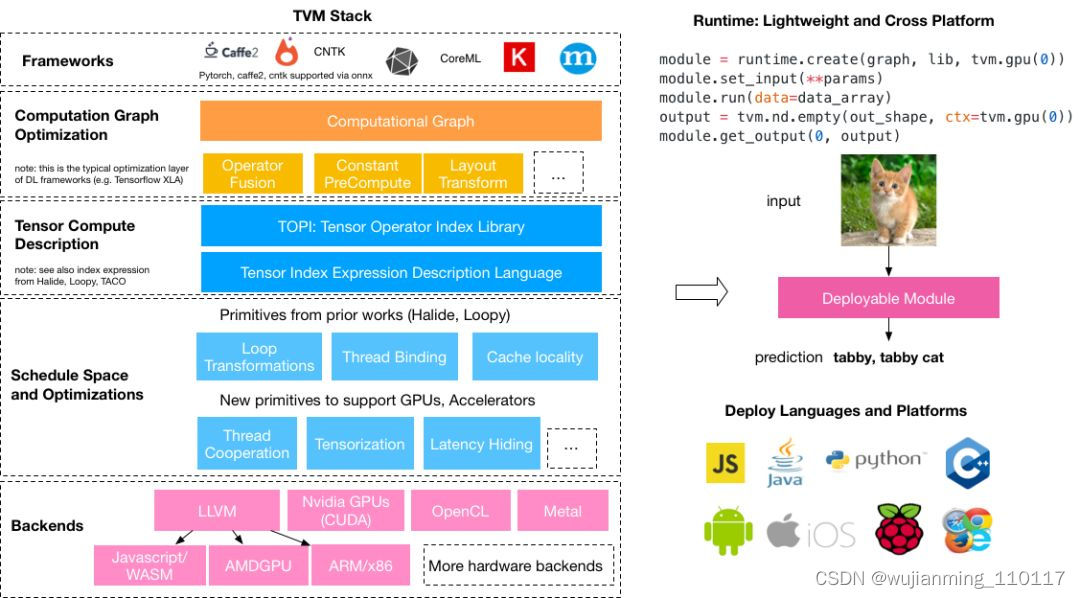
stack_tvmlang
只需要知道TVM的核心功能就可以:TVM可以优化的训练好的模型,将模型打包好,将这个优化好的模型放在任何平台去运行,可以说是与落地应用息息相关。
TVM包含的东西和知识概念都有很多,不仅有神经网络优化量化op融合等一系列步骤,还有其他更多细节技术的支持(Halide、LLVM),从而使TVM拥有很强大的功能。如果想多了解TVM的可以在知乎上直接搜索TVM关键字,那些大佬有很多关于TVM的介绍文章,大家可以去看看。
其实做模型优化这一步骤的库已经出现很多了,不论是Nvidia自家的TensorRT,还是Pytorch自家的torch.jit模块,都在做一些模型优化的工作,这里就不多说了,感兴趣的可以看看以下文章:
利用Pytorch的C++前端(libtorch)读取预训练权重并进行预测
利用TensorRT实现神经网络提速(读取ONNX模型并运行)
利用TensorRT对深度学习进行加速
开始使用
为什么要使用TVM?
如果想将训练模型移植到Window端、ARM端(树莓派、其他一系列使用该内核的板卡)或者其他的一些平台,利用其中的CPU或者GPU来运行,希望可以通过优化模型来使模型,在该平台运算的速度更快(这里与模型本身的算法设计无关),实现落地应用研究,那么TVM就是不二之选。另外TVM源码是由C++和Pythoh共同搭建,阅读相关源码也有利于程序编写方面的提升。
安装
安装其实没什么多说的,官方的例子说明的很详细。大家移步到那里按照官方的步骤一步一步来即可。
不过有两点需要注意下:
? 建议安装LLVM,虽然LLVM对于TVM是可选项,但是如果想要部署到CPU端,那么llvm几乎是必须的
? 因为TVM是python和C++一起的工程,python可以说是C++的前端,安装官方教程编译好C++端后,这里建议选择官方中的Method 1来进行python端的设置,这样就可以随意修改源代码,再重新编译,Python端就不需要进行任何修改就可以直接使用了。
(官方建议使用Method 1)
利用Pytorch导出Onnx模型
这里以一个简单的例子,演示一下TVM是怎么使用的。
首先要做的是,得到一个已经训练好的模型,这里选择这个github仓库中的mobilenet-v2,model代码和在ImageNet上训练好的权重都已经提供。将github中的模型代码移植到本地,然后调用并加载已经训练好的权重:
import torch
import time
from models.MobileNetv2 import mobilenetv2
model = mobilenetv2(pretrained=True)
example = torch.rand(1, 3, 224, 224) # 假想输入
with torch.no_grad():
model.eval()
since = time.time()
for i in range(10000):
model(example)
time_elapsed = time.time() - since
print(‘Time elapsed is {:.0f}m {:.0f}s’.
format(time_elapsed // 60, time_elapsed % 60)) # 打印出来时间
这里加载训练好的模型权重,设定了输入,在python端连续运行了10000次,这里所花的时间为:6m2s。
然后将Pytorch模型导出为ONNX模型:
import torch
from models.MobileNetv2 import mobilenetv2
model = mobilenetv2(pretrained=True)
example = torch.rand(1, 3, 224, 224) # 假想输入
torch_out = torch.onnx.export(model,
example,
“mobilenetv2.onnx”,
verbose=True,
export_params=True # 带参数输出
)
这样就得到了mobilenetv2.onnx这个onnx格式的模型权重。这里要带参数输出,因为之后要直接读取ONNX模型进行预测。
导出来之后,建议使用Netron来查看模型的结构,可以看到这个模型由Pytorch-1.0.1导出,共有152个op,以及输入id和输入格式等等信息,可以拖动鼠标查看到更详细的信息:
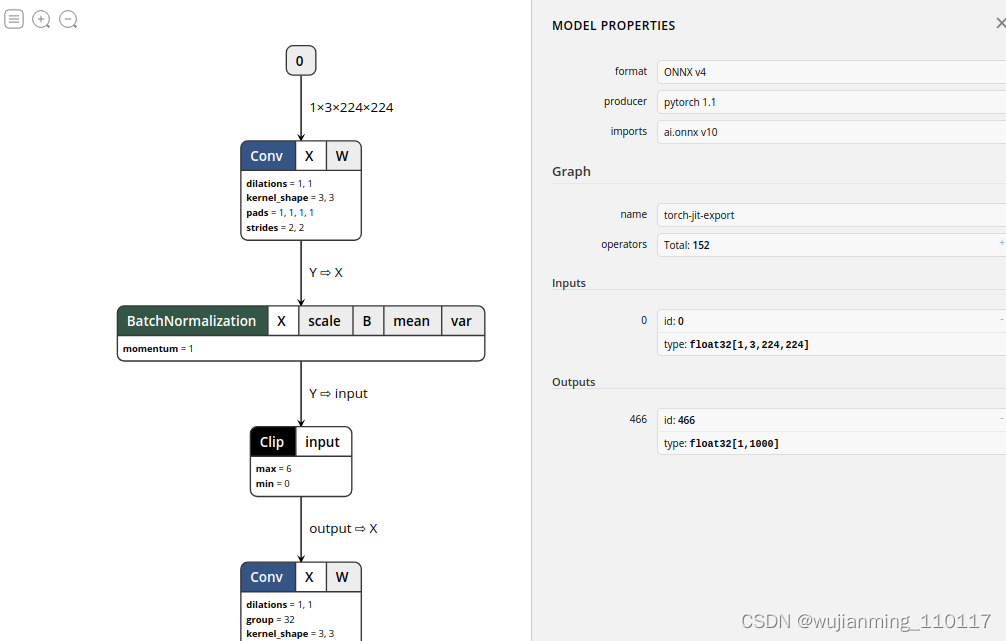
mobilenetv2-test
至此mobilenet-v2模型已经顺利导出了。
利用TVM读取并预测ONNX模型
在成功编译并且可以在Python端正常引用TVM后,首先导入onnx格式的模型。这里准备了一张飞机的图像:
tvm_plane

这个图像在ImageNet分类中属于404: ‘airliner’,也就是航空客机。
下面将利用TVM部署onnx模型并对这张图像进行预测。
import onnx
import time
import tvm
import numpy as np
import tvm.relay as relay
from PIL import Image
onnx_model = onnx.load(‘mobilenetv2.onnx’) # 导入模型
mean = [123., 117., 104.] # 在ImageNet上训练数据集的mean和std
std = [58.395, 57.12, 57.375]
def transform_image(image): # 定义转化函数,将PIL格式的图像转化为格式维度的numpy格式数组
image = image - np.array(mean)
image /= np.array(std)
image = np.array(image).transpose((2, 0, 1))
image = image[np.newaxis, :].astype(‘float32’)
return image
img = Image.open(’…/datasets/images/plane.jpg’).resize((224, 224)) # 这里将图像resize为特定大小
x = transform_image(img)
这样得到的x为[1,3,224,224]维度的ndarray。这个符合NCHW格式标准,也是通用的张量格式。
接下来设置目标端口llvm,也就是部署到CPU端,这里使用的是TVM中的Relay IR,这个IR简单来说就是可以读取模型,按照模型的顺序搭建出一个可以执行的计算图,可以对这个计算图进行一系列优化。(现在TVM主推Relay而不是NNVM,Relay可以称为二代NNVM)。
target = ‘llvm’
input_name = ‘0’ # 注意这里为之前导出onnx模型中的模型的输入id,这里为0
shape_dict = {input_name: x.shape}
利用Relay中的onnx前端读取导出的onnx模型
sym, params = relay.frontend.from_onnx(onnx_model, shape_dict)
上述代码中导出的sym和params是接下来要使用的核心的东西,其中params就是导出模型中的权重信息,在python中用dic表示:
Screenshot from 2019-03-12 14-57-18
sym就是表示计算图结构的功能函数,这个函数中包含了计算图的流动过程,以及一些计算中需要的各种参数信息,Relay IR之后对网络进行优化就是主要对这个sym进行优化的过程:
fn (%v0: Tensor[(1, 3, 224, 224), float32],
%v1: Tensor[(32, 3, 3, 3), float32],
%v2: Tensor[(32,), float32],
%v3: Tensor[(32,), float32],
%v4: Tensor[(32,), float32],
%v5: Tensor[(32,), float32],
…
%v307: Tensor[(1280, 320, 1, 1), float32],
%v308: Tensor[(1280,), float32],
%v309: Tensor[(1280,), float32],
%v310: Tensor[(1280,), float32],
%v311: Tensor[(1280,), float32],
%v313: Tensor[(1000, 1280), float32],
%v314: Tensor[(1000,), float32]) {
%0 = nn.conv2d(%v0, %v1, strides=[2, 2], padding=[1, 1], kernel_size=[3, 3])
%1 = nn.batch_norm(%0, %v2, %v3, %v4, %v5, epsilon=1e-05)
%2 = %1.0
%3 = clip(%2, a_min=0, a_max=6)
%4 = nn.conv2d(%3, %v7, padding=[1, 1], groups=32, kernel_size=[3, 3])
…
%200 = clip(%199, a_min=0, a_max=6)
%201 = mean(%200, axis=[3])
%202 = mean(%201, axis=[2])
%203 = nn.batch_flatten(%202)
%204 = multiply(1f, %203)
%205 = nn.dense(%204, %v313, units=1000)
%206 = multiply(1f, %v314)
%207 = nn.bias_add(%205, %206)
%207
}
接下来需要对这个计算图模型进行优化,这里选择优化的等级为3:
with relay.build_config(opt_level=3):
intrp = relay.build_module.create_executor(‘graph’, sym, tvm.cpu(0), target)
dtype = ‘float32’
func = intrp.evaluate(sym)
最后,得到可以直接运行的func。
其中优化的等级分这几种:
OPT_PASS_LEVEL = {
“SimplifyInference”: 0,
“OpFusion”: 1,
“FoldConstant”: 2,
“CombineParallelConv2D”: 3,
“FoldScaleAxis”: 3,
“AlterOpLayout”: 3,
“CanonicalizeOps”: 3,
}
最后,将之前已经转化格式后的图像x数组和模型的参数输入到这个func中,返回这个输出数组中的最大值
output = func(tvm.nd.array(x.astype(dtype)), **params).asnumpy()
print(output.argmax())
这里得到的输出为404,与前文描述图像在ImageNet中的分类标记一致,说明TVM正确读取onnx模型并将其应用于预测阶段。
另外单独测试一下模型优化后运行的速度和之前直接利用pytorch运行速度之间比较一下,最后的运行时间为:3m20s,相较之前的6m2s快了将近一倍。
since = time.time()
for i in range(10000):
output = func(tvm.nd.array(x.astype(dtype)), **params).asnumpy()
time_elapsed = time.time() - since
print(‘Time elapsed is {:.0f}m {:.0f}s’.
format(time_elapsed // 60, time_elapsed % 60)) # 打印出来时间
当然,这个比较并不是很规范,不过可以大概分析出TVM的一些可用之处了。
这里了解一下什么是TVM以及一个简单例子的使用,在接下来会涉及到部分TVM设计结构和源码的解析。可能涉及到的知识点有:
? 简单编译器原理
? C++特殊语法以及模板元编程
? 神经网络模型优化过程
? 代码部署
等等,随时可能会进行变化。
人工智能已经开始进入嵌入式时代,各式各样的AI芯片即将初始,将复杂的网络模型运行在廉价低功耗的板子上可能也不再是遥不可及的幻想,不知道未来会是怎么样,但TVM这个框架已经开始走了一小步。
AI编译器TVM(二)――利用TVM完成C++端的部署
前言
在上一节,简单介绍了什么是TVM以及如何利用Relay IR去编译网络权重然后并运行起来。
TVM
上述文章中的例子很简单,但是实际中更需要的是利用TVM去部署应用么,最简单直接的就是在嵌入式系统中运行起神经网络模型。例如树莓派。这才是最重要的是不是?所以嘛,在深入TVM之前还是要走一遍基本的实践流程的,也唯有实践流程才能让更好地理解TVM到底可以做什么。
本节主要介绍如果将神经网络使用TVM编译,导出动态链接库文件,最后部署在树莓派端(PC端),运行起来。
环境搭建
环境搭建?有什么好讲的?
废话咯,需要先把TVM的环境搭建出来才可以用啊,官方的安装教程最为详细,这里还是多建议看看官方的文档,很详细很具体重点把握的也很好。
但是还是要强调两点:
? 需要安装LLVM,因为这篇文章所讲的主要运行环境是CPU(树莓派的GPU暂时不用,内存有点小),所以LLVM是必须的
? 安装交叉编译器:
Cross Compiler
交叉编译器是什么,就是可以在PC平台上编译生成可以直接在树莓派上运行的可执行文件。在TVM中,需要利用交叉编译器在PC端编译模型并且优化,然后生成适用于树莓派(arm构架)使用的动态链接库。
有这个动态链接库,就可以直接调用树莓派端的TVM运行时环境去调用这个动态链接库,执行神经网络的前向操作了。
怎么安装呢?这里需要安装叫做/usr/bin/arm-linux-gnueabihf-g++的交叉编译器,在Ubuntu系统中,直接sudo apt-get install g+±arm-linux-gnueabihf即可,注意名称不能错,需要的是hf(Hard-float)版本。
安装完后,执行/usr/bin/arm-linux-gnueabihf-g++ -v命令就可以看到输出信息:
1prototype@prototype-X299-UD4-Pro:~/$ /usr/bin/arm-linux-gnueabihf-g++ -v
2Using built-in specs.
3COLLECT_GCC=/usr/bin/arm-linux-gnueabihf-g++
4COLLECT_LTO_WRAPPER=/usr/lib/gcc-cross/arm-linux-gnueabihf/5/lto-wrapper
5Target: arm-linux-gnueabihf
6Configured with: …/src/configure -v --with-pkgversion=‘Ubuntu/Linaro 5.4.0-6ubuntu1~16.04.9’ --with-bugurl=file:///usr/share/doc/gcc-5/README.Bugs --enable-languages=c,ada,c++,java,go,d,fortran,objc,obj-c++ --prefix=/usr --program-suffix=-5 --enable-shared --enable-linker-build-id --libexecdir=/usr/lib --without-included-gettext --enable-threads=posix --libdir=/usr/lib --enable-nls --with-sysroot=/ --enable-clocale=gnu --enable-libstdcxx-debug --enable-libstdcxx-time=yes --with-default-libstdcxx-abi=new --enable-gnu-unique-object --disable-libitm --disable-libquadmath --enable-plugin --with-system-zlib --disable-browser-plugin --enable-java-awt=gtk --enable-gtk-cairo --with-java-home=/usr/lib/jvm/java-1.5.0-gcj-5-armhf-cross/jre --enable-java-home --with-jvm-root-dir=/usr/lib/jvm/java-1.5.0-gcj-5-armhf-cross --with-jvm-jar-dir=/usr/lib/jvm-exports/java-1.5.0-gcj-5-armhf-cross --with-arch-directory=arm --with-ecj-jar=/usr/share/java/eclipse-ecj.jar --disable-libgcj --enable-objc-gc --enable-multiarch --enable-multilib --disable-sjlj-exceptions --with-arch=armv7-a --with-fpu=vfpv3-d16 --with-float=hard --with-mode=thumb --disable-werror --enable-multilib --enable-checking=release --build=x86_64-linux-gnu --host=x86_64-linux-gnu --target=arm-linux-gnueabihf --program-prefix=arm-linux-gnueabihf- --includedir=/usr/arm-linux-gnueabihf/include
7Thread model: posix
8gcc version 5.4.0 20160609 (Ubuntu/Linaro 5.4.0-6ubuntu1~16.04.9)
树莓派环境搭建
因为是在PC端利用TVM编译神经网络的,所以在树莓派端只需要编译TVM的运行时环境即可(TVM可以分为两个部分,一部分为编译时,另一个为运行时,两者可以拆开)。
这里附上官方的命令,注意树莓派端需要安装llvm,树莓派端的llvm可以在llvm官方找到已经编译好的压缩包,解压后添加环境变量即可:
1git clone --recursive https://github.com/dmlc/tvm
2cd tvm
3mkdir build
4cp cmake/config.cmake build # 这里修改config.cmake使其支持llvm
5cd build
6cmake …
7make runtime
在树莓派上编译TVM的运行时并不需要花很久的时间。
完成部署
环境搭建好之后,就让开始部署任务。
首先依然需要一个自己的测试模型,在这里使用之前训练好的,识别剪刀石头布手势的模型权重,然后利用Pytorch导出ONNX模型出来。具体的导出步骤可以看下面这两篇文章。
? 利用Pytorch的C++前端(libtorch)读取预训练权重并进行预测
? Pytorch的C++端(libtorch)在Windows中的使用
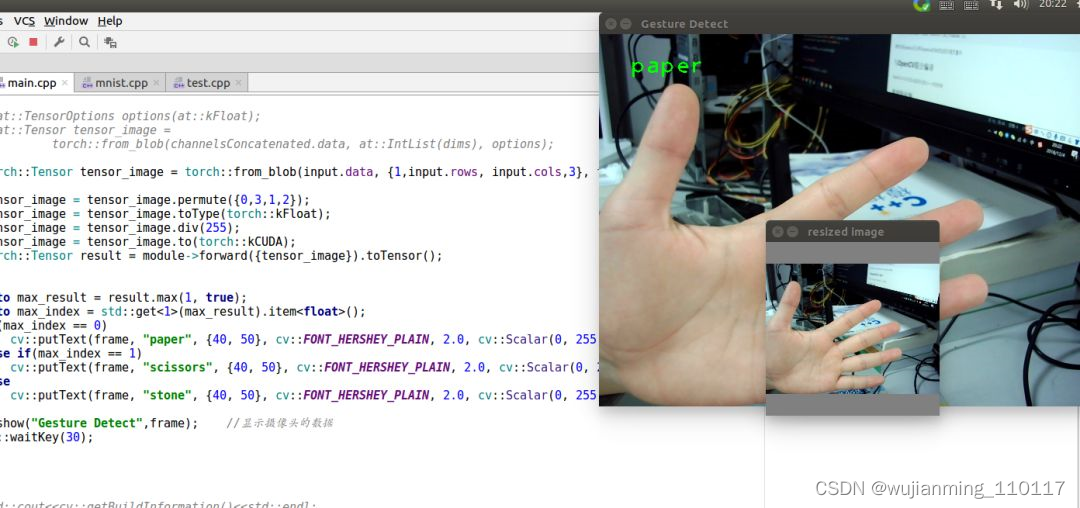
(上图是之前的识别剪刀石头布的一个权重模型)
OK,那拥有了一个模型叫做mobilenetv2-128_S.onnx,这个模型也就是通过Pytorch导出的ONNX模型,利用Netron瞧一眼:
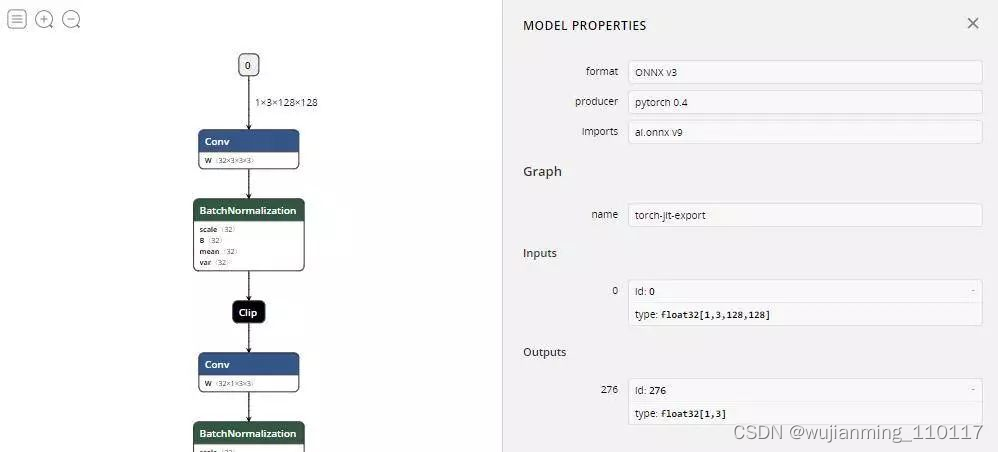
整个模型的输入和输出上图写的都很清楚了。
测试模型
拿到模型后,首先测试模型是否可以正确工作,同上一篇介绍TVM的文章类似,利用TVM的PYTHON前端去读取.onnx模型,然后将其编译并运行,最后利用测试图像测试其是否可以正确工作,其中核心代码如下:
1onnx_model = onnx.load(’…/test/new-mobilenetv2-128_S.onnx’)
2
3img = Image.open(’…/datasets/hand-image/paper.jpg’).resize((128, 128))
4
5img = np.array(img).transpose((2, 0, 1)).astype(‘float32’)
6img = img/255.0 # 注意在Pytorch中的tensor范围是0-1
7x = img[np.newaxis, :]
8
9target = ‘llvm’
10
11input_name = ‘0’ # 这里需要注意,因为生成的.onnx模型的输入代号是0,所以这里改为0
12shape_dict = {input_name: x.shape}
13sym, params = relay.frontend.from_onnx(onnx_model, shape_dict)
14
15with relay.build_config(opt_level=3):
16 intrp = relay.build_module.create_executor(‘graph’, sym, tvm.cpu(0), target)
17
18dtype = ‘float32’
19func = intrp.evaluate(sym)
20
21# 输出推断的结果
22tvm_output = intrp.evaluate(sym)(tvm.nd.array(x.astype(dtype)), **params).asnumpy()
23max_index = tvm_output.argmax()
24print(max_index)
这个模型输出的结果为三个手势的输出值大小(顺序分别为布、剪刀、石头),上述的代码打印出来的值为0,意味着可以正确识别paper.jpg输入的图像。说明这个转化过程是没有问题的。
导出动态链接库
上面这个步骤只是将.onnx模型利用TVM读取并且预测出来,如果需要部署的话就需要导出整个模型的动态链接库,至于为什么是动态链接库,其实TVM是有多种的导出模式的(也可以导出静态库),但是这里不细说了:
总之目标就是导出so动态链接库,这个链接库中包括了神经网络所需要的一切推断功能。
怎么导出呢?其实官方已经有很详细的导出说明。这里不进行赘述了,仅仅展示核心的代码加以注释即可。
请看以下的代码:
1#开始同样是读取.onnx模型
2
3onnx_model = onnx.load(’…/…/test/new-mobilenetv2-128_S.onnx’)
4img = Image.open(’…/…/datasets/hand-image/paper.jpg’).resize((128, 128))
5
6# 以下的图片读取仅仅是为了测试
7img = np.array(img).transpose((2, 0, 1)).astype(‘float32’)
8img = img/255.0 # remember pytorch tensor is 0-1
9x = img[np.newaxis, :]
10
11# 这里首先在PC的CPU上进行测试 所以使用LLVM进行导出
12target = tvm.target.create(‘llvm’)
13
14input_name = ‘0’ # change ‘1’ to ‘0’
15shape_dict = {input_name: x.shape}
16sym, params = relay.frontend.from_onnx(onnx_model, shape_dict)
17
18# 这里利用TVM构建出优化后模型的信息
19with relay.build_config(opt_level=2):
20 graph, lib, params = relay.build_module.build(sym, target, params=params)
21
22dtype = ‘float32’
23
24from tvm.contrib import graph_runtime
25
26# 下面的函数导出需要的动态链接库 地址可以自己定义
27print(“Output model files”)
28libpath = “…/tvm_output_lib/mobilenet.so”
29lib.export_library(libpath)
30
31# 下面的函数导出神经网络的结构,使用json文件保存
32graph_json_path = “…/tvm_output_lib/mobilenet.json”
33with open(graph_json_path, ‘w’) as fo:
34 fo.write(graph)
35
36# 下面的函数中导出神经网络模型的权重参数
37param_path = “…/tvm_output_lib/mobilenet.params”
38with open(param_path, ‘wb’) as fo:
39 fo.write(relay.save_param_dict(params))
40# -------------至此导出模型阶段已经结束--------
41
42# 接下来加载导出的模型去测试导出的模型是否可以正常工作
43loaded_json = open(graph_json_path).read()
44loaded_lib = tvm.module.load(libpath)
45loaded_params = bytearray(open(param_path, “rb”).read())
46
47# 这里执行的平台为CPU
48ctx = tvm.cpu()
49
50module = graph_runtime.create(loaded_json, loaded_lib, ctx)
51module.load_params(loaded_params)
52module.set_input(“0”, x)
53module.run()
54out_deploy = module.get_output(0).asnumpy()
55
56print(out_deploy)
上述的代码输出[[13.680096 -7.218611 -6.7872353]],因为输入的图像是paper.jpg,所以输出的三个数字第一个数字最大,没有毛病。
执行完代码之后就可以得到需要的三个文件
? mobilenet.so
? mobilenet.json
? mobilenet.params
得到三个文件之后,接下来利用TVM的C++端读取并运行起来。
在PC端利用TVM部署C++模型
如何利用TVM的C++端去部署,官方也有比较详细的文档,这里利用TVM和OpenCV读取一张图片,并且使用之前导出的动态链接库去运行神经网络对这张图片进行推断。
需要的头文件为:
1#include
2#include <dlpack/dlpack.h>
3#include <opencv4/opencv2/opencv.hpp>
4#include <tvm/runtime/module.h>
5#include <tvm/runtime/registry.h>
6#include <tvm/runtime/packed_func.h>
7#include
其实这里只需要TVM的运行时,另外dlpack是存放张量的一个结构。其中OpenCV用于读取图片, fstream则用于读取json和参数信息:
1tvm::runtime::Module mod_dylib =
2 tvm::runtime::Module::LoadFromFile("…/files/mobilenet.so");
3
4std::ifstream json_in("…/files/mobilenet.json", std::ios::in);
5std::string json_data((std::istreambuf_iterator(json_in)), std::istreambuf_iterator());
6json_in.close();
7
8// parameters in binary
9std::ifstream params_in("…/files/mobilenet.params", std::ios::binary);
10std::string params_data((std::istreambuf_iterator(params_in)), std::istreambuf_iterator());
11params_in.close();
12
13TVMByteArray params_arr;
14params_arr.data = params_data.c_str();
15params_arr.size = params_data.length();
在读取完信息之后,要利用之前读取的信息,构建TVM中的运行图(Graph_runtime):
1int dtype_code = kDLFloat;
2int dtype_bits = 32;
3int dtype_lanes = 1;
4int device_type = kDLCPU;
5int device_id = 0;
6
7tvm::runtime::Module mod = (tvm::runtime::Registry::Get(“tvm.graph_runtime.create”))
8 (json_data, mod_dylib, device_type, device_id);
然后利用TVM中函数建立一个输入的张量类型并且分配空间:
1DLTensor x;
2int in_ndim = 4;
3int64_t in_shape[4] = {1, 3, 128, 128};
4TVMArrayAlloc(in_shape, in_ndim, dtype_code, dtype_bits, dtype_lanes, device_type, device_id, &x);
其中DLTensor是个灵活的结构,可以包容各种类型的张量,而在创建了这个张量后,需要将OpenCV中读取的图像信息传入到这个张量结构中:
1// 这里依然读取了papar.png这张图
2image = cv::imread("/home/prototype/CLionProjects/tvm-cpp/data/paper.png");
3
4cv::cvtColor(image, frame, cv::COLOR_BGR2RGB);
5cv::resize(frame, input, cv::Size(128,128));
6
7float data[128 * 128 * 3];
8// 在这个函数中 将OpenCV中的图像数据转化为CHW的形式
9Mat_to_CHW(data, input);
需要注意的是,因为OpenCV中的图像数据的保存顺序是(128,128,3),所以这里需要将其调整过来,其中Mat_to_CHW函数的具体内容是:
1void Mat_to_CHW(float data, cv::Mat &frame)
2{
3 assert(data && !frame.empty());
4 unsigned int volChl = 128 * 128;
5
6 for(int c = 0; c < 3; ++c)
7 {
8 for (unsigned j = 0; j < volChl; ++j)
9 data[cvolChl + j] = static_cast(float(frame.data[j * 3 + c]) / 255.0);
10 }
11
12}
当然别忘了除以255.0因为在Pytorch中所有的权重信息的范围都是0-1。
在将OpenCV中的图像数据转化后,将转化后的图像数据拷贝到之前的张量类型中:
1// x为之前的张量类型 data为之前开辟的浮点型空间
2memcpy(x->data, &data, 3 * 128 * 128 * sizeof(float));
然后设置运行图的输入(x)和输出(y):
1// get the function from the module(set input data)
2tvm::runtime::PackedFunc set_input = mod.GetFunction(“set_input”);
3set_input(“0”, x);
4
5// get the function from the module(load patameters)
6tvm::runtime::PackedFunc load_params = mod.GetFunction(“load_params”);
7load_params(params_arr);
8
9DLTensor y;
10int out_ndim = 2;
11int64_t out_shape[2] = {1, 3,};
12TVMArrayAlloc(out_shape, out_ndim, dtype_code, dtype_bits, dtype_lanes, device_type, device_id, &y);
13
14// get the function from the module(run it)
15tvm::runtime::PackedFunc run = mod.GetFunction(“run”);
16
17// get the function from the module(get output data)
18tvm::runtime::PackedFunc get_output = mod.GetFunction(“get_output”);
可以运行了:
1run();
2get_output(0, y);
3
4// 将输出的信息打印出来
5auto result = static_cast<float>(y->data);
6for (int i = 0; i < 3; i++)
7 cout<<result[i]<<endl;
最后的输出信息是
113.8204
2-7.31387
3-6.8253
可以看到,成功识别出了布这张图片,到底为止在C++端的部署就完毕了。
在树莓派上的部署
在树莓派上的部署其实也是很简单的,与上述步骤中不同的地方是需要设置target为树莓派专用:
1target = tvm.target.arm_cpu(‘rasp3b’)
点进去其实可以发现rasp3b对应着-target=armv7l-linux-gnueabihf:
1trans_table = {
2 “pixel2”: ["-model=snapdragon835", “-target=arm64-linux-android -mattr=+neon”],
3 “mate10”: ["-model=kirin970", “-target=arm64-linux-android -mattr=+neon”],
4 “mate10pro”: ["-model=kirin970", “-target=arm64-linux-android -mattr=+neon”],
5 “p20”: ["-model=kirin970", “-target=arm64-linux-android -mattr=+neon”],
6 “p20pro”: ["-model=kirin970", “-target=arm64-linux-android -mattr=+neon”],
7 “rasp3b”: ["-model=bcm2837", “-target=armv7l-linux-gnueabihf -mattr=+neon”],
8 “rk3399”: ["-model=rk3399", “-target=aarch64-linux-gnu -mattr=+neon”],
9 “pynq”: ["-model=pynq", “-target=armv7a-linux-eabi -mattr=+neon”],
10 “ultra96”: ["-model=ultra96", “-target=aarch64-linux-gnu -mattr=+neon”],
11}
还有一点改动的是,在导出.so的时候需要加入cc="/usr/bin/arm-linux-gnueabihf-g++",此时的/usr/bin/arm-linux-gnueabihf-g++为之前下载的交叉编译器。
1path_lib = ‘…/tvm/deploy_lib.so’
2lib.export_library(path_lib, cc="/usr/bin/arm-linux-gnueabihf-g++")
这时就可以导出来树莓派需要的几个文件,之后将这几个文件移到树莓派中,随后利用上面说到的C++部署代码去部署就可以了。
关心的问题
看到这里想必大家应该还有很多疑惑,限于篇幅(写的有点累呀),这里讲几个比较重点的东西:
速度
这里可以毫不犹豫地说,对于这个模型来说,速度提升很明显。在PC端部署中,使用TVM部署的手势检测模型的运行速度是libtorch中的5倍左右,精度还没有测试,但是在用摄像头进行演示过程中并没有发现明显的区别。当然还需要进一步的测试,就不在这里多说了。
在树莓派中,这个模型还没有达到实时(53ms),但是无论对TVM,依然还有很大的优化空间,实时只是时间关系。
层的支持程度
当然因为TVM还处于开发阶段,有一些层时不支持的,上文中的mobilenetv2-128_S.onnx模型一开始使用Relay IR前端读取的时候提示,TVM中没有flatten层的支持,mobilenetv2-128_S.onnx中有一个flatten层,所以提示报错。
但是这个是问题吗?只要仔细看看TVM的源码,熟悉熟悉结构,就可以自己加层了,但其实flatten的操作函数在TVM中已经存在了,只是ONNX的前端接口没有展示出来,onnx前端展示的是batch_flatten这个函数,其实batch_flatten就是flatten的特殊版,于是简单修改源码,重新编译一下就可以成功读取自己的模型了。
参考文献
https://oldpan.me/archives/the-first-step-towards-tvm-1
https://mp.weixin.qq.com/s?__biz=Mzg3ODU2MzY5MA==&mid=2247484929&idx=1&sn=3fcce36b5a50cd8571cf932a23083667&chksm=cf109e04f86717129c3381ebeec2d0c1f7baf6ed057c66310662f5935beea88baf23e99898f4&token=1276531538&lang=zh_CN#rd
https://mp.weixin.qq.com/s?__biz=Mzg3ODU2MzY5MA==&mid=2247484930&idx=1&sn=ddc3da7b72c900ce2f8e6aad99a9e788&source=41#wechat_redirect