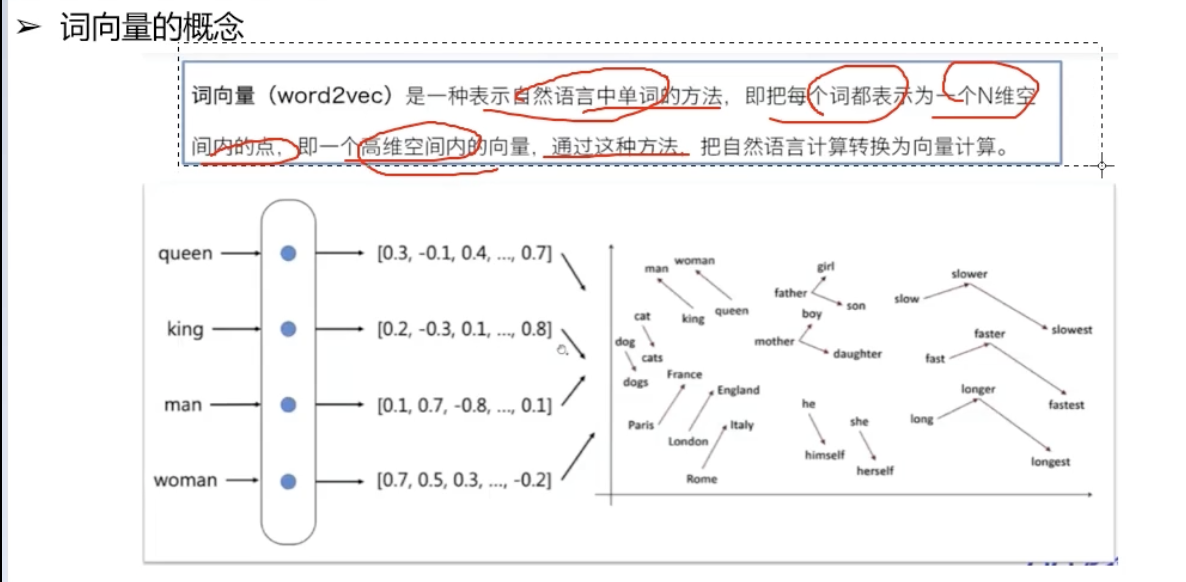
文本的离散表示(2022-03-07)
- one-hot表示
- 词袋模型
- TF-IDF
- N-gram

one-hot表示
"""
oneHotencoder举例
"""
from sklearn import preprocessing
enc = preprocessing.OneHotEncoder()
enc.fit([[0,0,3],[1,1,0],[0,2,1],[1,0,2]])#fit来学习编码
res=enc.transform([[0,1,3]]).toarray()#结果转化为数组
print(res)

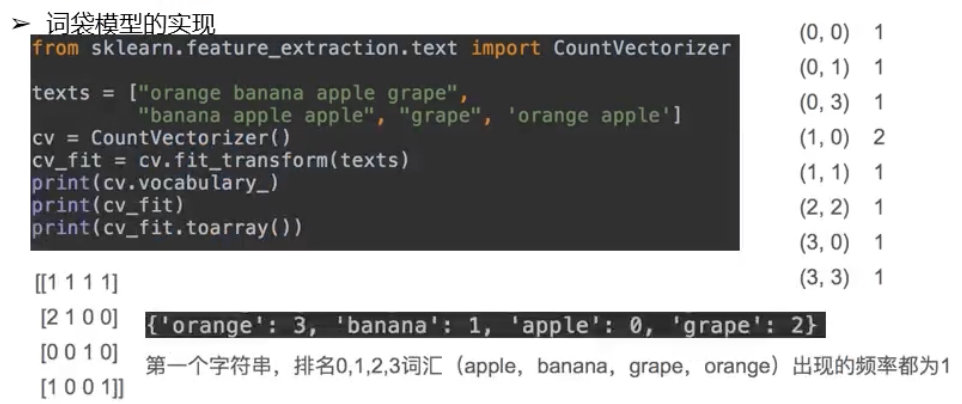
词袋模型


"""
词袋模型
"""
from sklearn.feature_extraction.text import CountVectorizer
texts = ["orange banana apple grape","banana apple apple","grape","orange apple"]
cv =CountVectorizer()#统计词频(词袋模型)
cv_fit = cv.fit_transform(texts)# 训练文本
print(cv.vocabulary_)
print(cv_fit)#训练后的结果在矩阵中有值内容
print(cv_fit.toarray())#以后在做模型训练时,我们应该使用数组的模
TF-IDF


"""
词频逆文档频率
"""
from sklearn.feature_extraction.text import TfidfVectorizer
texts = ["orange banana apple grape","banana apple apple","grape","orange apple"]
cv = TfidfVectorizer()
cv_fit = cv.fit_transform(texts)#训练样本
print(cv.vocabulary_)#打印词汇表:4个单词,apple,banana,grape,orange
print(cv_fit)#非零的词权重
print(cv_fit.toarray)#数组形式
N-gram
N-Gram是一种基于统计语言模型的算法。它的基本思想是将文本里面的内容按照字节进行大小为N的滑动窗口操作,形成了长度是N的字节片段序列。
"""
n_garm
"""
from sklearn.feature_extraction.text import CountVectorizer
texts = ["orange banana apple grape",
"banana apple apple",
"grape",
"orange apple"]
ngram_vectorizer =CountVectorizer(ngram_range=(1,3),
decode_error="ignore",
token_pattern=r'\b\w+\b',
min_df=1)
x1 = ngram_vectorizer.fit_transform(texts)
print(x1.toarray())
print(ngram_vectorizer.vocabulary_)