基于深度学习的磁环表面缺陷检测算法

来源:《?人工智能与机器人研究》?,作者罗菁等
关键词:?缺陷检测;深度学习;磁环;YOLOv3;
摘要:?在磁环的生产制造过程中,常常由于生产环境、制造工艺等因素,难免会使磁环表面出现各种类型的缺陷。针对传统人工检测低效、耗时、检测精度低的缺点,本文提出了一种基于YOLOv3的磁环表面缺陷检测方法。实验结果表明,YOLOv3的平均识别精度达到了96.19%,单张图片检测速度达到了24.46 ms,该方法在磁环缺陷检测上有一定的先进性和有效性。
1. 引言
磁环是呈圆柱形的径向磁体,生活中广泛应用在电子定时器、汽车制造以及仪表器件等行业的各类电器装置,它的质量直接影响所在装置的性能。但是在目前的生产过程中,由于原料组成、加工工艺和设备条件的影响,磁环表面不可避免地会出现一些加工缺陷,如缺口、污点等,这些缺陷会影响到磁环的使用寿命和性能。目前,磁环表面一些常见的缺陷主要由有一定经验的工人检测,用肉眼观察磁环的表面是否有缺陷。这种检测方法效率低,容易出现视觉疲劳,造成误差?[1]。
为了克服人工缺陷检测的不足,很多人提出了各种表面缺陷检测方法,可以分为两类:传统的机器视觉检测方法和深度学习检测方法。李雪琴等?[2] 提出了一种非下采样轮廓域自适应阈值表面的磁瓦缺陷自动检测方法。林丽君等 [3] 提出了一种结合图像加权信息熵和小波模极大值的磁瓦表面裂纹检测算法。这些方法对于特定缺陷具有速度快、精度高的优点,但受光照和人工的影响较大。
近年来,随着深度学习的广泛应用,已在目标检测?[4] 领域取得了一系列成果,在工业检测领域得到了很大的应用。目前,广泛应用的深度学习目标检测算法可分为单阶段检测算法和两阶段检测算法。单阶算法直接生成对象的类别概率和位置坐标值,其代表性算法为SSD [5] 和YOLO [6] [7] [8] 网络。两阶段算法将检测分为两个阶段,首先生成候选区域,然后对候选区域进行分类。代表性算法有R-CNN [9] 及其改进算法Fast R-CNN [10] 和Faster R-CNN [11] 等。
一般情况下,两阶段算法在准确度上有优势,而单阶段算法在检测的速度上有优势。由于单阶段算法在速度上更有优势,所以更受到工程化的青睐。本文也将使用YOLOv3网络对磁环表面缺陷进行检测,为了提升检测速度和精度使用k-means聚类方法重新选取先验框,保证检测的实时性。
2. 检测算法
2.1. YOLOv3网络
YOLOv3是在YOLO和YOLOv2算法的改进基础上,主要用于图像目标检测、视频目标检测、摄像机实时目标检测等方面。它将目标检测问题转化为逻辑回归问题,首先将输入图像划分为S ′ S个网格,若待检测图片中的目标中心点落在某个网格内,则该网格负责对应的目标,从而达到更快的检测速度。之后每个网格将会预测B个边界框及其本身的置信度,并且该网格需要给出负责预测的边界框是属于第i个类别的概率。
YOLOv3使用Darknet53网络结构作为提取图像特征的骨干网络,其主要由一系列的1 ′ 1、3 ′ 3卷积层构成。它借鉴了ResNet (Residual Network)的做法,在各层之间建立快捷链路,通过适当的跃层连接,解决了网络逐步深化时模型难以优化的问题,这样做可以利用到更多的图像浅层特征信息。YOLOv3摒弃了在YOLOv2中采用的pass-through结构,而是使用了特征金字塔网络(Feature Pyramid Network, FPN)的多尺度检测方法,然后结合残差网络将图像转换为三种不同尺度的特征图,分别来检测大、中、小三个类型的物体,在此基础上进行分类和位置回归,这大大改善了原始YOLO网络的检测准确率。YOLOv3的具体架构如图1所示。
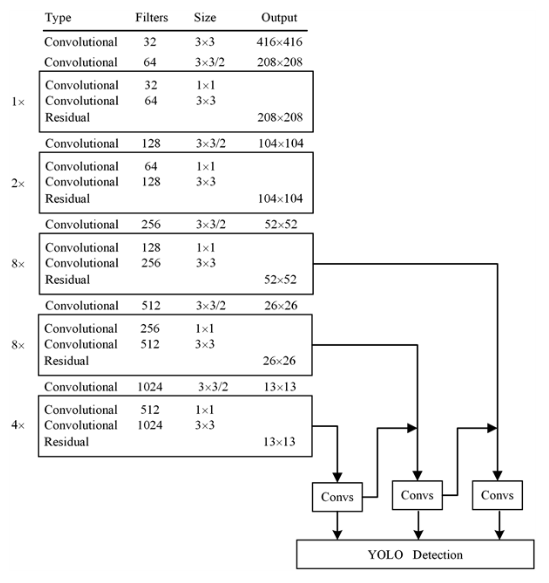
Figure 1. YOLOv3 network structure
图1. YOLOv3结构图
2.2. K-Means聚类初始化锚框
初始的YOLO算法采用的是回归的方式来预测边界框的坐标值。为高效地预测不同尺度目标的边界框,Faster R-CNN算法中最先提出了锚框机制,即事先选取一组大小各异的矩形框作为选取目标时的参照物,之后通过预测目标框的偏移量来代替直接预测出的坐标,合适的anchor取值能够有效地提高检测任务的精度与速度。受该思想启发,YOLOv3中也引入了锚框机制,通过k-means聚类的方法获得锚框集合。YOLOv3算法中默认的anchor是通过VOC20类与COCO80类数据集聚类得到的,锚点框维度的比例并不适用于磁环缺陷检测。由于磁环图像中缺陷区域的大小不同,为了使检测算法能够更快、更准确地进行检测,本文使用k-means聚类方法针对磁环数据集生成初始锚框。与通常使用的K均值的欧式距离不同,在目标检测任务中,聚类的目的是使锚框与标注真值的IOU值尽可能大,因此将IOU用作测量标准。度量函数的公式如下:
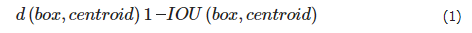
centroid表示簇的中心,box表示样本,IOU (box, centroid)表示簇的中心框和聚类框的交并比。IOU越大,距离越小。按照上述方法,在磁环数据集中使用k-means算法重新对标签信息进行聚类分析,得到的9组anchor值为:(28, 27)、(27, 54)、(53, 30)、(43, 55)、(68, 45)、(46, 87)、(64, 69)、(99, 56)、(84, 98)。这些锚点按从小到大的顺序分配给三个尺度的特征图,其中尺度较大的使用较小的锚点框,并且每个网格都需要计算三个预测框。
2.3. 检测过程
YOLOv3提出了一种新的特征提取网络Darknet53,它的主要优点是用步幅为2的卷积层代替了池化层来完成对特征图的下采样,同时在每个卷积层后面增加了批量归一化处理,激活函数采用LeakyRelu,避免了梯度消失和过拟合问题。在对磁环图像进行检测的过程中,采用了3个不同尺度的特征图来进行位置与类别预测,有效地提高了目标检测的准确率。
首先,YOLOv3网络将输入图片缩放到416 ′ 416大小,再将原图像划分为S ′ S个网格。每个网格负责预测中心落入该网格的对象,然后计算出3个预测框。将待检测的目标类别数记为C,则每个预测框会输出5 + C个值,其中5表示了预测边界框的信息属性:中心点坐标(x, y)、框的宽高尺寸(w, h)以及置信度(confidence)。预测时采用直接预测相对位置的方法,边界框坐标计算公式为:

Figure 2. The position and size of the actual target box relative to the preset box
图2. 实际目标框相对于预设框的位置和大小
YOLOv3算法首先将输入图片缩放到固定大小,然后利用Darknet53网络对图片的特征进行提取,接着将特征向量送往特征金字塔结构中进行多尺度预测,最后根据置信分数的大小,对预测出的边界框采用非极大值抑制(NMS)进行筛选,以消除重复检测获得最终的预测结果。
3. 实验结果及分析
3.1. 实验平台
本文实验在Window10环境下完成,计算机内存为16G,CPU为Inter Core i7 9700 3.0GHz,GPU为GTX2070,显存为8GB,深度学习框架为Darknet,编译环境为Visual Studio 2019 C/C++语言。并同时安装了CUDA10.0和cudnn7.5以支持GPU的使用。
3.2. 数据集
本文数据集由工业相机对磁环进行拍摄,每张图片包含一个磁环,每个磁环上有一到多处缺陷。图片采集设备为维视图像技术有限公司产出的型号为MV-EM500M/C的CMOS工业相机,通过设备共采取1080张磁环图像。
实验一共使用了800张图像进行训练,280张图像作为测试集,其中400张训练图为缺口图像,400张训练图为污点图像,140张测试图为缺口图像,140张测试图为污点图像。缺陷图像的检测任务与分类任务不同,需要手动标注出图片中缺陷位置的坐标,本文中通过labelImg软件来进行缺陷位置的标注。
3.3. 模型训练
在模型训练阶段,将动量(Momentum)设置为0.9、权值衰减系数设置(Decay)为0.0005、批尺寸(Batch size)为64,使用小批量随机梯度下降进行优化,学习率(Learning rate)为0.001,在训练过程中保存训练日志和训练权重,从训练日志中提取出loss值画图,将loss稳定时的权重作为最终权重对磁环图像进行缺陷检测。
损失函数图如图3所示,横坐标代表迭代次数,在训练次数达到7000次时,各参数变化基本稳定,损失函数收敛曲线也趋于平缓,网络的训练结果比较理想。
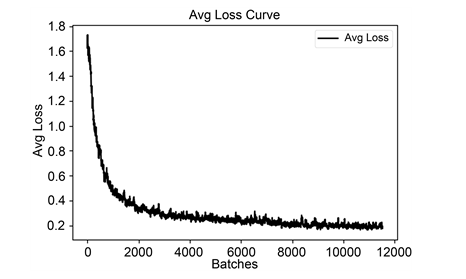
Figure 3. The convergence of the loss function
图3. 损失函数曲线图
3.4. 测试结果及分析
为验证本文方法有效性,需要分析检测的结果。检测效果的评价指标主要有单类精确率(Precision, P)、召回率(Recall, R)、平均精确率(mean average precision, mAP)和单张图片平均检测时间(time),具体公式如下:

上式中,TP表示将缺陷目标预测为缺陷目标,FP表示将其他缺陷或背景预测为缺陷目标,FN表示将缺陷目标预测为其他缺陷或背景,gap和stain分别代表对于缺口和污点的检测精确率,实验所获得的结果如表1所示。
由表1的实验检测结果可以看出,使用YOLOv3网络训练之后,在磁环缺陷测试集上的平均检测精度达到了96.19%。在使用相同的训练模型进行检测时,测试数据集中不同缺陷类别的测试效果也有一定的差别。当采用训练好的模型进行检测时,每张图片的检测时间平均需要花费24.46 ms,且识别的准确率较高。实验结果表明,YOLOv3网络模型可以有效地对磁环表面缺陷进行快速和准确的检测,可满足工业现场的实时性需求。采用YOLOv3算法训练完毕之后,部分磁环缺陷检测的结果如图4所示。
| 方法 | Class | P | mAP | R | Time/ms |
| YOLOv3 | gap | 0.9464 | 0.9619 | 0.95 | 24.46 |
| Stain | 0.9774 |
Table 1. Statistical table of experimental results
表1. 实验结果统计表
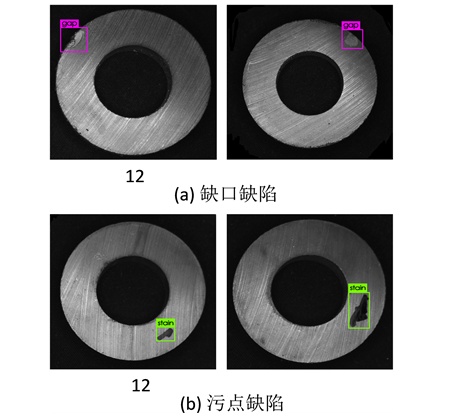
Figure 4. Magnetic ring defect detection results
图4. 磁环检测效果图
4. 结论
随着深度学习的不断发展和广泛应用,一些目标检测算法在工业检测领域取得很大成果。本文将YOLOv3算法应用到磁环的表面缺陷检测中,实验结果表明,YOLOv3的检测准确率和检测速度均能满足工业需求,具有实际的应用价值。未来的研究工作将会集中在两个方面:一是优化YOLOv3算法模型,使之降低计算量从而提升检测速度,以方便嵌入式设备上的使用需求;二是增加学习样本的数量,并提高样本图片的质量,进一步提高缺陷的检测精度。

我们的服务类型
公开课程
人工智能、大数据、嵌入式? ? ? ? ? ? ??? ?? ?
内训课程
普通内训、定制内训? ? ? ? ? ? ? ?? ??? ? ??
项目咨询
技术路线设计、算法设计与实现(图像处理、自然语言处理、语音识别)

