Ъ§ОнзМБИ
torch.utils.data.DatasetsЪЧPyTorchгУРДБэЪОЪ§ОнМЏЕФРр,ЫќЪЧгУPyTorchНјааЪжаДЪ§зжЪЖБ№ЕФЙиМќЁЃ
ЯТУцЪЧМгдиmnistЪ§ОнМЏВЂЖдЦфПЩЪгЛЏЕФДњТы
from torchvision import datasets
from torchvision.datasets import MNIST
from matplotlib import pyplot as plt
import numpy as np
mnist = datasets.MNIST(root='C:/Users/WSY/Desktop/гУpytorchНјааЪжаДЪ§зжЪЖБ№',
train=True,download=True)
for i, j in enumerate(np.random.randint(0,len(mnist),(10,))):
data, label = mnist[j]
plt.subplot(2,5,i+1)
plt.imshow(data)
етЖЮДњТыжа,ЪзЯШЪЕР§ЛЏСЫDatasetsЖдЯѓmnist ,datasets.MNISTФмЙЛздЖЏЯТдиЪ§ОнМЏБЃДцЕНБОЕиДХХЬЕФrootЮЛжУ(здМКЩшжУ),ВЮЪ§trainФЌШЯЮЊTrue,гУгкПижЦМгдиЕФЪ§ОнМЏЪЧбЕСЗМЏЛЙЪЧВтЪдМЏЁЃforбЛЗжа,ЪЙгУlen(mnist)ЕїгУСЫ__len__ЗНЗЈ,ЪЙгУmnist[j]ЕїгУСЫ__getitem__ЗНЗЈ(дкЮвУЧздМКНЈСЂЪ§ОнМЏЪБ,ашвЊМЬГаDataset,ВЂЧвИВаД__len__КЭ__getitem__СНИіЗНЗЈ)ЁЃзюКѓСНааДњТыЛцжЦСЫMNISTЪжаДЪ§зжЪ§ОнМЏЁЃ
дЫааДњТы,ВщПДЪ§ОнМЏЕФВПЗжЪ§ОнПЩЪгЛЏНсЙћ

дкБфСПфЏРРЦїжаПЩвдПДЕНгаЙиБфСПЕФФкШн,ЦфжаmnistОЭЪЧЪЕР§ЛЏЕФЪ§ОнМЏЖдЯѓ,ЫќАќКЌ6000еХЭМЯёФкШн,дкforбЛЗЙ§ГЬжа,dataЖСШЁЕФЪЧ28ЁС28ЕФImageРраЭЭМЯё,labelЪЧИУЭМЯёЖдгІЕФБъЧЉ,вВОЭЪЧЭМЯёЩЯБэЪОЕФЪ§зжЁЃ
гЩгкЪ§ОндЄДІРэЪЧЗЧГЃживЊЕФВНжш,ЫљвдPyTorchЬсЙЉСЫtorchvision.transformsгУгкДІРэЪ§ОнМАЪ§ОндіЧПЁЃдкетРяЮвУЧЪЙгУСЫtorchvision.transforms.ToTensorНЋPIL ImageЛђепnumpy.ndarrayРраЭЕФЪ§ОнзЊЛЛЮЊTensor,ВЂЧвЫќЛсНЋЪ§ОнДгЁО0,255ЁПгГЩфЕНЁО0,1ЁПЁЃtorchvision.transforms.NormalizeЛсНЋЪ§ОнБъзМЛЏ,МгЫйФЃаЭдкбЕСЗжаЕФЪеСВЫйТЪЁЃдкЪЙгУжа,ПЩРћгУtorchvision.transforms.ComposeНЋЖрИіtransformsзщКЯдквЛЦ№,БЛАќКЌЕФtransformsЛсЫГађжДааЁЃ
Ъ§ОнСїГЬДІРэзМБИЭъЩЦКѓПЊЪМЖСШЁгУгкбЕСЗЕФЪ§Он,torch.utils.data.DataLoaderЬсЙЉСЫЕќДњЪ§ОнЁЂЫцЛњГщШЁЪ§ОнЁЂХњСПЛЏЪ§ОнЁЃ
ЯТУцЕФДњТыжаЪЕР§ЛЏСЫmnistЖдЯѓ,ЖЈвхСЫtransformsЗНЗЈtransВЂНЋЦфЪЙгУЕНЪ§ОнМЏЕФЪЕР§ЛЏЙ§ГЬжа,гУгкЖдЪ§ОнМЏНјааДІРэЁЃШЛКѓЖЈвхСЫКЏЪ§imshow,КЏЪ§ЬхЕФЕФЕквЛааДњТыНЋЪ§ОнДгБъзМЛЏЕФЪ§ОнжаЛжИД,ЕкЖўааДњТыНЋTensorРраЭзЊЛЛЮЊndarray,етбљВХПЩвдгУmatplotlibЛцжЦГіРД,ЛцжЦЕФНсЙћШчЯТЭМЫљЪОЁЃКЏЪ§ЬхзюКѓвЛааЪЙгУtransposeКЏЪ§НЋОиеѓЮЌЖШДг(C,W,H)зЊЛЛЮЊ(W,H,C),етбљВХЗћКЯе§ГЃЕФЭЈЕРЫГађЁЃ
import torchvision
from torchvision import datasets,transforms
from torchvision.datasets import MNIST
from matplotlib import pyplot as plt
import numpy as np
import torch
trans = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
mnist = datasets.MNIST(root='C:/Users/WSY/Desktop/гУpytorchНјааЪжаДЪ§зжЪЖБ№',
train=True,download=True,transform=trans)
def imshow(img):
img = img * 0.3081 + 0.1307
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1,2,0)))
dataloader = torch.utils.data.DataLoader(mnist, batch_size=4, shuffle=True, num_workers=0)
images, labels = next(iter(dataloader))
imshow(torchvision.utils.make_grid(images))
дЫааДњТыЕУЕНЕФБфСПЧщПіМАЛцжЦНсЙћШчЯТЭМ
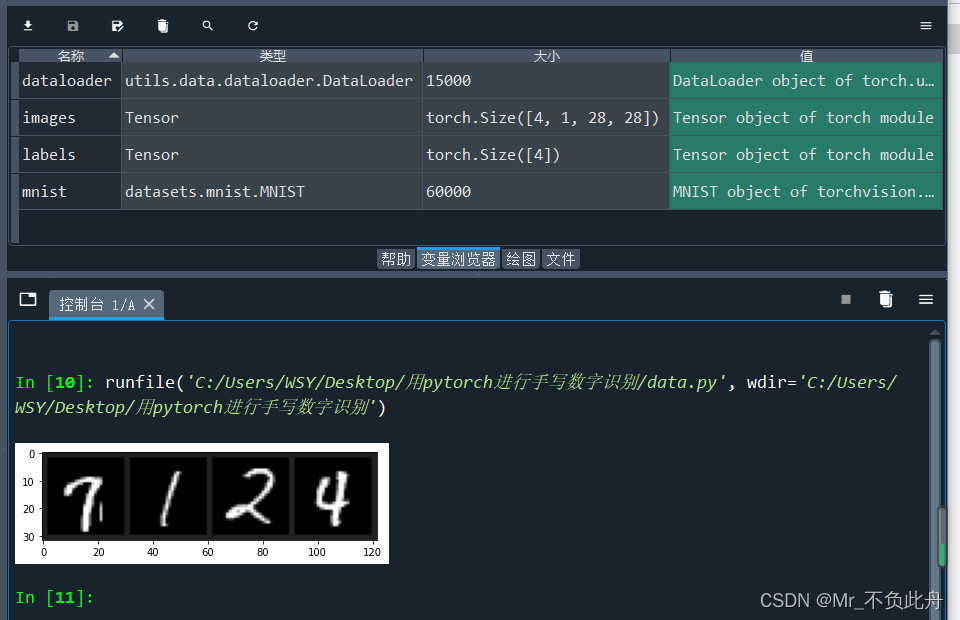
ЭјТчФЃаЭ
ЯТУцЙЙНЈгУгкЪЖБ№ЪжаДЪ§зжЕФЩёОЭјТчФЃаЭ
import torch.nn as nn
class MLP(nn.Module):
def __init__(self):
super(MLP, self).__init__()
self.inputlayer = nn.Sequential(nn.Linear(28*28, 256),
nn.ReLU(),
nn.Dropout(0.2))
self.hiddenlayer = nn.Sequential(nn.Linear(256, 256),
nn.ReLU(),
nn.Dropout(0.2))
self.outlayer = nn.Sequential(nn.Linear(256, 10))
def forward(self, x):
#НЋЪфШыЭМЯёРЩьЮЊвЛЮЌЯђСП
x = x.view(x.size(0), -1)
x = self.inputlayer(x)
x = self.hiddenlayer(x)
x = self.outlayer(x)
return x
ЭЈЙ§nn.ModuleЖдЯѓПДЕНЦфЭјТчНсЙЙ,ШчЯТ
In [12]: print(MLP())
MLP(
(inputlayer): Sequential(
(0): Linear(in_features=784, out_features=256, bias=True)
(1): ReLU()
(2): Dropout(p=0.2, inplace=False)
)
(hiddenlayer): Sequential(
(0): Linear(in_features=256, out_features=256, bias=True)
(1): ReLU()
(2): Dropout(p=0.2, inplace=False)
)
(outlayer): Sequential(
(0): Linear(in_features=256, out_features=10, bias=True)
)
)
ЭъећЪЕЯж
зМБИКУЪ§ОнКЭФЃаЭКѓ,ОЭПЩвдНјаабЕСЗФЃаЭСЫЁЃЯТУцЗжБ№ЖЈвхСЫЪ§ОнДІРэКЭМгдиСїГЬЁЂФЃаЭЁЂгХЛЏЦїЁЂЫ№ЪЇКЏЪ§вдМАгУзМШЗТЪЦРЙРФЃаЭФмСІЁЃбЕСЗЙ§ГЬГжај10Иіepoch
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
from torch import optim
from tqdm import tqdm
from torchvision import datasets,transforms
import matplotlib.pylab as plt
#Ъ§ОнДІРэКЭМгди
trans = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
mnist_train = datasets.MNIST(root='C:/Users/WSY/Desktop/гУpytorchНјааЪжаДЪ§зжЪЖБ№',
train=True,download=True,transform=trans)
mnist_val = datasets.MNIST(root='C:/Users/WSY/Desktop/гУpytorchНјааЪжаДЪ§зжЪЖБ№',
train=False,download=True,transform=trans)
trainloader = DataLoader(mnist_train, batch_size=16, shuffle=True, num_workers=0)
valloader = DataLoader(mnist_val, batch_size=16, shuffle=True, num_workers=0)
#ЖЈвхЭјТчФЃаЭ
class MLP(nn.Module):
def __init__(self):
super(MLP, self).__init__()
self.inputlayer = nn.Sequential(nn.Linear(28*28, 256),
nn.ReLU(),
nn.Dropout(0.2))
self.hiddenlayer = nn.Sequential(nn.Linear(256, 256),
nn.ReLU(),
nn.Dropout(0.2))
self.outlayer = nn.Sequential(nn.Linear(256, 10))
def forward(self, x):
#НЋЪфШыЭМЯёРЩьЮЊвЛЮЌЯђСП
x = x.view(x.size(0), -1)
x = self.inputlayer(x)
x = self.hiddenlayer(x)
x = self.outlayer(x)
return x
model = MLP()
#гХЛЏЦї
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
#Ы№ЪЇКЏЪ§
celoss = nn.CrossEntropyLoss()
#МЦЫузМШЗТЪ
def accuracy(pred, target):
pred_label = torch.argmax(pred, 1)
correct = sum(pred_label == target).to(torch.float)
return correct, len(pred)
acc = {'train':[], 'val':[]}
loss_all = {'train':[], 'val':[]}
for epoch in tqdm(range(10)):
#ЩшжУЮЊбщжЄФЃЪН
model.eval()
numer_val, denumer_val, loss_tr = 0., 0., 0.
with torch.no_grad():
for data, target in valloader:
output = model(data)
loss = celoss(output, target)
loss_tr += loss.data
num, denum = accuracy(output, target)
numer_val += num
denumer_val += denum
#ЩшжУЮЊбЕСЗФЃЪН
model.train()
numer_tr, denumer_tr, loss_val = 0., 0., 0.
for data, target in trainloader:
optimizer.zero_grad()
output = model(data)
loss = celoss(output, target)
loss_val += loss.data
loss.backward()
optimizer.step()
num, denum = accuracy(output, target)
numer_tr += num
denumer_tr += denum
loss_all['train'].append(loss_tr/len(trainloader))
loss_all['val'].append(loss_val/len(valloader))
acc['train'].append(numer_tr/denumer_tr)
acc['val'].append(numer_val/denumer_val)
дЫааЭъГЩ,ШчЯТ

ЩшМЦЕНЕФБфСПЧщПіШчЯТ
ВщПДФЃаЭбЕСЗЕќДњЙ§ГЬЕФЫ№ЪЇЭМЯё
plt.plot(loss_all['train'])
plt.plot(loss_all['val'])
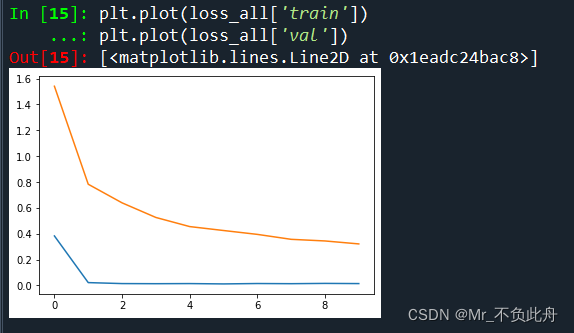
ВщПДбЕСЗЕќДњЙ§ГЬЕФзМШЗТЪЭМ
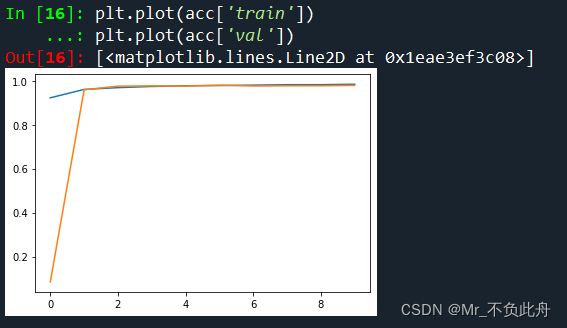
plt.plot(acc['train'])
plt.plot(acc['val'])
O V E R !