
摘要
对比学习的最新进展彻底改变了无监督表征学习。具体来说,来自同一图像的多个视图(增强)被鼓励映射到类似的嵌入,而来自不同图像的视图被分开。在本文中,通过可视化和诊断分类错误,我们观察到当前的对比模型在定位前景对象方面是无效的,限制了它们提取有区别的高层特征的能力。这是因为视图生成过程统一考虑图像中的像素。为了解决这个问题,我们提出了一种数据驱动的学习背景不变性的方法。它首先估计图像中的前景显著性,然后通过复制和粘贴前景到各种背景上来创建增强效果。学习仍然遵循实例辨别前文任务,因此,表征模型被训练为忽略背景内容,专注于前景。我们研究了各种显著性估计方法,发现大多数方法都能改善对比学习。通过这种方法(DiLo),ImageNet分类的自监督学习以及PASCAL VOC和MSCOCO上的目标检测都取得了显著的性能。
1、介绍
视觉识别已经被深度学习带来了革命性的变化,深度学习的方式是收集大量的标记数据(Deng等人,2009年)和训练非常深入的神经网络(Krizhevsky、Sutskever和Hinton,2012年)。然而,监控信号的收集,尤其是在非常大规模的情况下,受到预算和时间的限制。正因为如此,人们对无监督和自我监督学习越来越感兴趣,而这些学习并不面临这种实际限制。对于高级视觉识别,之前的自监督学习方法定义了代理任务,这些任务不需要人类标记,但编码了有用的先验信息(Zhang、Isola和Efros 2016;Doersch、Gupta和Efros 2015),用于对象识别。自我监督对比学习的最新进展依赖于实例辨别的代理任务(Dosovitskiy等,2015b;Wu等,2018), 其中不变性被编码并从低级图像增强中学习,例如空间裁剪和颜色抖动。

图1:动机:对于带有物体的自然图像,背景通常是跨类别共享的,而用于确定物体的独特区域是局部的。
在本文中,通过可视化和诊断最近的自我监督对比模型所产生的错误,我们发现了一个被以往工作忽略的强模式。具体来说,我们发现当前的自监督模型缺乏定位前景对象的能力,并且学习的表示主要由背景像素决定。这其实并不奇怪,因为自监督学习通常将每个空间位置视为同等重要,而且众所周知,神经网络容易利用意外信息进行“欺骗”(Zhang、Isola和Efros 2016)。因此,除非驱动网络发现对象,否则无法期望网络发现对象(Arandjelovi’c和Zisserman 2019)。
在监督视觉识别中,定位已被证明是图像级标签培训的一个重要副产品。使用像素空间中类分数的梯度显示了强大的对象定位性能(Simonyan、Vedaldi和Zisserman 2013)。还发现,当从ImageNet传输时,添加精确的定位信息不会为PASCAL对象分类带来显著收益(Oquab et al.2015)。此外,通过类激活映射方法,仅使用imagelevel标签估计对象段(Zhou等人,2016)。如图1所示,我们假设驱动本地化的学习信号来自分类智能监视器标签,因为背景内容(例如,草地、天空、水)通常在不同类别之间共享,而前景对象仅在同一类别内突出。
自监督模型和监督模型在定位能力上的差距促使我们探索提取自监督表示的定位方法。我们首先为每个训练图像估计一个前景显著性模板来研究这个问题。然后,通过将前景对象粘贴到各种背景上,使用训练图像及其相应的显著性映射创建增强。在表征学习过程中,我们遵循最近的对比表征学习方法,使用不同背景下相同对象的增强。这会鼓励表示对背景保持不变,从而实现前景对象的定位。
为了生成我们的增强,研究了几种显著性估计方法,包括传统的无监督技术(Zhu等人2014;Yan等人2013;Wei等人2012)和显著性网络(Qin等人2019)。我们的模型(DiLo)显示持续改善2%? 超过基线6%。这清楚地表明,目标识别受益于更好的定位,并且我们的方法对于解决定位问题是有效的。由于其更好的定位能力,我们还实现了在PASCAL VOC和MSCOCO上进行目标检测的最新转移学习结果。
我们的贡献总结如下:
1.基于可视化的对最近的自监督对比模型的研究,显示出其定位物体的能力有限。
2.数据驱动的方法提升了对比表征学习的定位能力,在图像分类和目标检测转移任务上都表现出了其有效性。
3.研究了用于改进定位的各种显著性估计方法,包括传统显著性和网络预测显著性。
2、相关工作
无监督和自我监督学习:无监督学习旨在提取没有人类标签的语义有意义的表示(de Sa 1994)。自监督学习是无监督学习的一个分支,它自动从数据本身生成学习信号。这些学习信号来源于涉及语义图像理解但不需要语义标签进行训练的代理任务。这些任务基于颜色预测(Zhang、Isola和Efros 2016)、背景预测(Doersch、Gupta和Efros 2015;Pathak等人2016)、旋转预测(Gidaris、Singh和Komodakis 2018)和运动预测(Pathak等人2017)。自动编码器(Vincent等人,2008年)和GANs(Goodfello等人,2014年;Donahue和Simonyan 2019年)也显示了通过重建图像进行表征学习的良好结果。
对比学习是自我监督学习的另一个有前途的方向。它通过图像增强以数据驱动的方式实现不变性。Exem plar CNN(Dosovitskiy等人,2015b)和instance discrimination(Wu等人,2018)通过颜色、空间位置和比例的变化来增强图像。PIRL(Misra和Maaten,2020年)和CPC(Oord,Li和Vinyals,2018年)制定了图像补丁中的对比学习。CMC(Tian、Krishnan和Isola 2019)考虑了不同视图的显式建模。MoCo(He et al.2019)和SimCLR(Chen et al.2020a)通过动量编码器和大批量进行对比学习。我们的论文与这些工作是一致的,我们提出了一种非平凡的增强方法来提取定位信息。
显著性估计:显著性估计是指根据人类的感知来估计感兴趣物体的位置。为了学习显著性,数据集(Bylinskii等人)通过跟踪图像上的眼睛注视来收集。以后的作品通常认为显著性是全前景对象。
以前的基于非学习的方法(Zhu等人2014;Yang等人2013)依赖于手工制作的特征,并使用先验来发现显著的对象区域。有用的先验值包括背景先验值(Han等人2014)、颜色对比先验值(Cheng等人2014)和客观先验值(Jiang等人2013b)。深度监督方法(Qin等人,2019年)训练分割网络回归前景遮罩,优于所有基于非学习的方法。最近关于显著性估计的研究也探索了无监督学习方法。它集成了多种非基于学习方法的噪声优化框架(张,韩,章2017),显示的结果与监督方法相媲美。
在网络中,显著区域对应于触发分类决策的像素。之前的工作通过梯度可视化(Simonyan、Vedaldi和Zisserman 2013)在输入空间和通过激活映射(Zhou等人,2016)在输出空间研究了这一点。之前的一项工作(Zhou等人,2014年)也通过优化决定分类响应的最小区域来发现显著区域。
复制和粘贴用于视觉识别:有几部作品以复制粘贴的方式创建数据,用于视觉识别。这种方法的一个关键洞见是,生成的数据看起来可能不现实,但经过训练的模型对真实数据的概括能力出奇地好。例如,飞椅(Dosovitskiy et al.2015a)将椅子渲染到各种背景上,以生成用于光流估计的数据。剪切粘贴学习(Dwibedi、Misra和Hebert 2017)在室内环境中随机放置家庭对象实例,用于实例检测和分割。Instaboost(Fang等人,2019)在空间上移动前景对象,作为数据增强的一种手段,例如分割。复制粘贴GAN(Arandjelovi’c和Zisserman 2019)使用复制粘贴的思想,以无监督的方式发现对象。然而,他们的实验是以玩具为例进行的,比如发现人造盒子。此外,他们没有展示发现物体如何帮助识别。我们的工作遵循这条路径,但与之前的工作相比,我们的方法针对的是自我监督表征学习。我们注意到,我们的增强图像非常不现实,但为学习识别模型提供了有用的信息。
图像增强:数据增强在视觉识别中起着关键作用。最近的作品设计了手工制作的增强(DeVries和Taylor 2017)或基于学习的方法(Cubuk等人2019;Ratner等人2017),以促进表征学习,尤其是在半监督学习中。我们的复制粘贴增强是首次引入自监督学习。从中,我们试图进一步了解自我监督学习中的无效定位问题。

图2:可视化和分析自我监督对比模型的错误模式。给定每个模型的输入,我们在嵌入空间中可视化其前3个最近邻,以及像素空间中相对于分类信号的梯度。与能够定位显著对象的监督模型相比,自监督模型(InstDisc、CMC、MoCo)从整体上观察图像,并且容易受到背景的干扰。附加的补充资料中提供了更多的可视化信息。
3、重新审视对比学习
我们的工作建立在无监督学习的最新对比学习方法的基础上,其中大多数工作遵循实例歧视的pretext任务。该算法首先在空间域、尺度空间和颜色空间生成图像增强,然后鼓励相同图像的增强具有相似的特征嵌入,并鼓励不同图像的增强具有不同的嵌入。
设x表示图像,v=f(x)为特征嵌入,其中f(・)为作为卷积神经网络实现的嵌入函数。设~x=T(x)表示图像x的增广,其中T是一个随机增广函数。增广x被归类为第i个恒等式的概率表示为
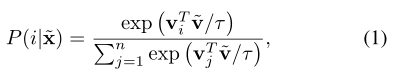
其中τ是温度参数,n是数据集中的图像总数。~V= F(~x),Vi= f(xi)是图像xi和~x的嵌入。学习目标是最小化数据集上的负对数似然:
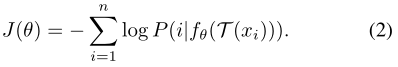
最近的自我监督学习方法,如InstDisc(Wu等人2018年)、CMC(Tian、Krishnan和Isola 2019年)、MoCo(He等人2019年)、SimCLR(Chen等人2020a)都有类似的公式。这种无监督学习方法的有效性在很大程度上取决于增强T(・)的类型,即不改变对象身份的图像变换先验。在表1中,我们总结了典型的自监督MoCo ResNet50模型(He等人,2019年)和监督模型中数据驱动增强的作用。我们逐渐将每种类型的转换添加到扩充集。性能在1000个类的ImageNet验证集上进行测量,并通过线性分类器进行评估。
我们发现,与有监督表示相比,无监督表示从增广中获得了更高的分类精度。这表明增广中存在的先验知识与语义标签中的建模线索强烈重叠。添加强烈的颜色抖动会改善无监督表示,但会损害有监督表示。这表明之前的颜色抖动超出了原始数据分布。尽管如此,添加一个只与语义部分相关的先验知识可以显著改善自我监督学习。
4、可视化/诊断对比学习
基于反卷积(Zeiler and Fergus 2014),已经提出了多种方法来可视化有监督卷积神经网络的行为, 类依赖梯度(Simonyan、V edaldi和Zisserman 2013)和类激活映射(Zhou等人2016;Selvaraju等人2017)。然而,很少有研究可视化和分析自监督模型的错误模式,尤其是在理解代理任务和语义标签之间的关系方面。
在下文中,我们将展示一些有代表性的对比学习模型,重点是了解自监督网络做出错误预测时的显著区域。

图3:显著性估计方法示例。我们展示了6种显著性估计,包括传统方法(GS(Wei et al.2012)、MC(Jiang et al.2013a)、RBD(Zhu et al.2014)、网络预测显著性BASNet(Qin et al.2019)和从预训练网络(CAM(Zhou et al.2016)、梯度(Simonyan、Vedaldi和Zisserman 2013)可视化的类特定方法。
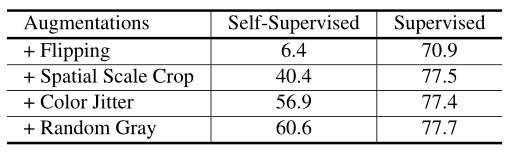
表1:数据增强在学习自我监督和监督表征中的作用的比较研究。详情请参阅正文。
可视化方法:我们采用两种可视化方法来实现我们的目标。
1.最近邻方法。诊断特征所学内容的一种简单方法是在特征空间中找到最近的邻居。通过识别吸引邻居们彼此靠近的模式,我们可以了解这些特征代表了什么。
2.类依赖梯度。像素空间中类分数梯度的大小提供了有关像素对分类的重要性的信息。事实证明,这种方法对于弱监督对象定位非常有效(Simonyan、Vedaldi和Zisserman 2013)。由于自监督模型没有针对对象的分类器,我们在提取特征的基础上训练线性分类器。然后通过线性分类器和其他自监督网络进行反向传播,计算像素空间中的梯度。
调查模型:我们研究了三个自监督模型,包括InstDist、CMC和MoCo。
InstDist(Wu et al.2018)将每个实例视为一个类,并使用内存库实现通过非参数分类学习表示。
CMC(Tian、Krishnan和Isola 2019)明确地将图像解耦为两个视图,即亮度和颜色通道。学习是为了最大化视图之间的相互信息。
MoCo(He et al.2019)遵循InstDist,并进一步提出了动量编码器,以修复正数据和基于队列的内存之间的一致性,从而实现可伸缩性。
错误模式。图2展示了我们的主要发现。我们观察到,对于相当多的错误情况,查询与其最近邻之间的相似性主要存在于它们的背景中。基于梯度的显著性可视化证实了这些发现,因为自监督模型的显著区域分布在背景中,而不是前景中。为了进行比较,我们还展示了监督模型的相应结果,这些结果显示了前景之间的相似性。
由于这些自监督方法在很大程度上依赖于增强来学习不变性,并且这些增强平等地对待前景和背景像素,因此它们不会强制执行驱动模型发现对象的损失。这种定位能力的缺乏要求在自监督学习中建立显著区域模型。
5、DiLo:通过背景不变性提取定位
我们的目标是学习一种表示法,从中前景对象可以自动定位,这样可以集中在有区别的区域,以提高识别能力。我们提出通过学习背景不变性来提取目标定位能力。我们首先描述了通过显著性估计提取前景区域的方法,然后介绍了通过复制和粘贴操作增强背景的方法。
5.1显著性估计
在提取自监督方法的定位能力时,我们的方法首先估计显著性模板。显著性遮罩应该描述与对象分类最相关的区域。通常,它与前景对象区域一致,如大多数显著性数据集所示(Wang等人,2017年)。
值得注意的是,最近关于无监督显著性估计的研究显示了有希望的进展。然而,这些模型(Zhang et al.2018;Nguyen et al.2019)严重依赖ImageNet和语义分割预训练,这违反了我们的无监督实验协议。在本文中,我们避免了这些方法,而是考虑以下技术。
传统方法。传统的显著性估计方法使用手工制作的特征,并依赖先验和启发式来找到图像中的主要对象。有用的先验包括背景先验(图像边界上的像素更有可能是背景)和颜色对比先验(高对比度的边缘往往属于前景)。我们研究了几种高性能的方法:RBD(Zhu et al.2014)、MC(Jiang et al.2013a)和GS(Wei et al.2012)。
显著性网络。最近的显著性估计方法通常采用带注释的显著性数据集上的深度学习(Wang等人,2017)。这些深度模型的性能大大优于传统方法。调查中包括了一个最先进的显著性网络BASNet(Qin等人,2019年),它从零开始在少量10K图像上进行训练。
类依赖显著性。上述方法将显著性估计为前景对象区域。然而,目前尚不清楚这是否代表了图像的区别部分(例如,只有人脸可能对识别人类很重要)。为了保持问题的开放性,我们还通过特定于类的可视化与CAM(Zhou et al.2016)和基于梯度的方法(Simonyan、V edaldi和Zisserman 2013)进行了比较。对于(Simonyan、Vedaldi和Zisserman 2013),我们使用分割算法将梯度转换为掩模(Gulshan等人,2010)。
总结。图3显示了显著性可视化的示例。传统方法被认为是有噪声的,而网络产生的显著性要干净得多。可以注意到,来自预训练网络的特定于类的显著性倾向于在区分区域周围更紧密。这表明使用完全前景显著性可能并不理想。
5.2复制-粘贴用于背景增强
基于以前的发现,我们建议复制根据先验知识中的显著性方法估计的前景部分, 并将其粘贴到各种背景上,作为学习本地化的数据驱动增强手段。

图4:使用三种背景图像生成的复制粘贴增强。
背景数据集。为了增强效果,我们去除了三种背景。
具有随机灰度级别的均匀灰度图像。
来自麻省理工视觉纹理数据集(MediaLab 1995)的纹理图像。
使用RBD对ImageNet中无显著性反应的作物进行成像(Zhu等人,2014)。
图4显示了使用各种背景图像复制和粘贴的示例。
混合。对于粘贴,我们研究了三种技术:直接将前景对象复制到背景上,在对象边界上使用高斯混合进行复制,以及这两种方法的混合。
联系上下文。语境在识别物体中起着重要作用(Torralba 2003)。虽然对象周围的环境可能不是识别的最具辨别力的区域,但它可能有助于删减候选集。例如,一棵树不太可能被天空完全包围。为了在增强过程中考虑这一点,我们设置了在不进行复制粘贴增强的情况下保留原始完整图像的概率。
集成其他增强功能。由于复制粘贴增强与之前的其他增强是正交的,即随机缩放、裁剪、颜色抖动,因此复制粘贴增强相对于其他增强的顺序并不重要。在我们的实现中,我们首先运行复制粘贴增强来替换背景,然后执行其他增强。
6、实验
我们对自我监督表征学习的模型设计及其迁移学习能力进行了一系列实验。
6.1消融实验
在本节中,我们首先在ImageNet上通过一系列用于图像分类的烧蚀实验来验证我们的数据驱动的提取定位方法。
…后文见原文