�������ѧϰ�����ĵ�������ݼ��ϵͳ

��Դ:��?�˹�������������о���?,���߷���
�ؼ���:?���ܵ��;���ݷ���;���ѧϰʱ��ģ��;
ժҪ:?�����ҹ��糧���Ϸ�չ,�ҹ����ܵ��װ������������,�������,�����ܵ���ļ��Խ��Խ��Ҫ������ͨ���Ե�����ݵIJɼ�����ϴ,������ݸ�ʽ��������Ƥ��ɭ���ϵ�������Լ�K�۽�����֤�ȷ���,�������ݷ�����ͨ���������ѧϰʱ��ģ�ͽ���Ԥ���о�,���մﵽ���������״̬��Ŀ�ġ�ͨ���������ܵ�������ݶԵ������״̬�ķ���,�����жϵ�������Ƿ�����,����쳣�����ڹ��ϻ�����͵©�緢��,�ж����λ��,�Ա��һ����ȡ�ж����ü��ϵͳ���о���Ӧ��,���Ա������ܵ�����������,���Դﵽ�ӳ����������ʹ������,��ʡ��������Դ��Ŀ�ġ�
1. ����
���ܵ����Ļ����Ǹ���˫������ͨ�����硣ͨ�����в��������Ƽ�����ʵ�ָ�Ч����ȫ�ĵ�������,��֤���������ܻ�����?[1]�����ܵ����Ϊ���ܵ�������Ҫ����,��Ҫ�漰���²���:������ͨ�š����ݴ�����Ԫ�� [2],��һ�����ܻ��DZ�,�ܹ���Ч�ز�����������������˫����� [3],�ܹ�ʵ��ʵʱ���ݽ���,�Ե��ܵ��������м��,ʵʩԶ�̼�ء�
���ܵ����ʹ��������µĿ�ѧ����,ͻ���˵���ʽ���ķ�չ,������оƬ��Ϊ����,�������ݿ⡢�������Լ�����ϵͳ��,ͨ�������ͨ��ƽ̨,ʵ���Զ����ĵ��������ͼƷ�,���ӿ�ݱ���?[4]�����ܵ�������ܵ����������ն˺��������,Ϊ����Ӧ���ܵ���,���ܵ������˫����ַ��ʼ������û���ʵʱ���ơ��������ݴ���ģʽ�����ܽ����ȶ���Ӧ�ù��ܡ����ܵ�������Ϊȫ�����ܵ�����õ���Ϣ�ɼ�������ϵͳ��Ʒ�����˹������г����� [5] [6]��Ԥ�Ƶ�2020��ȫ��װ��20��̨���ܵ��,���ܵ���������ȫ����80%���˿�,���ܵ�����ʴﵽ60% [7]��
Ŀǰ���ҹ涨�����ܵ��ʹ������һ��Ϊ8��,��ʵ���������ܵ��ʹ��8���,�ֿ�������ʹ��,����ǰ���õ�������ⷽʽʹ���µĵ������ȫ�������ˡ��������ֻ���쳣������и���,�����Ϊ���Һ��˽�ʡ���ÿ��ߴ�������ϵľ��óɱ��������о���Ŀ���Ǹ��ݲɼ����õ�С�����õ�����,����������ݷ���,�����ڲ��Ե�������������õ������ͨ���ھ���û�������쳣��Ϣ,���ִ����쳣�ĵ�� [8],Ϊ������������������ṩ��������뷽����
2. ���ݷ����봦��
2.1. �������������
2.1.1. ��������˼·
�����о�����ҪĿ���Ǹ��ݵ��������Ԥ���������Ƿ��쳣,�쳣������������ϻ���͵©��ȡ�
Ŀǰ����Ҳ��һЩ��ط�����о��Ѿ������ڽ��С�������ͨ��������ͬ�û��ĵ�����������,�ó���ͬʱ�������µ��û�����ģ�Ͳ��졣����֧������������,������õ��쳣�����ַ�������ѵ��ʱ�����,������˹��쳣���ݽ��з���,����Ч���ͷ�����Ӧ�óɱ�?[9]��
���л����ܹ��������ܵ��CPU�����ʺ�����ͨ�������쳣����,���AMI�л��ڴ����ݵļ�ⷽ�����ɸ����ܵ����¼��CPU�����ʼ�����ͨ������,���������������������һ���ϴ����õ�����������ݷ�����,�����쳣���ϵͳ����ͬ�ͺ����ܵ����CPU�����ʼ�����ͨ���������жԱ�,�������ô����������ݵ�ͳ������,ʶ���CPU�����ʺ�ͨ����������ƫ�ߵ��쳣��� [10]��
����������ܵ���˵��о����еý�Ϊ����,Ŀǰ��Ҫ���Ե硢�����������ȷ��档
Babu V,Nicol D M����Զ��������AMI�����еĴ�������,�������������Ӧ�ò㲿���µ�Э��,ͨ���Ա����������ļ��,ʹ�ö������ļ�⾫�ȴﵽ��99.72%��99.96% [11]��
Depuru S S R��ͨ���Ե������ݷ���,����SVM����ѵ������,ʹ�öԸ������ļ�⾫�ȴﵽ��98.4%��
���ܵ�������Ϣ�ɼ���������Ҫ���������豸�Ͻ��вɼ��ͻ���,��Ҫ��������״̬����ϵͳ�����û�����ϵͳ���ࡣ��ͼ1��ʾ?[12]��

Figure 1. Smart grid testing system classification
ͼ1. ���ܵ�������ϵͳ����
��Ա���ĿС��������о�,�����ݷ���Ĵ���Ӧ��ѭ:1) ͨ���������̸��ַ���,��������ȡӰ������������;2) ͨ�����������Ĺ�ϵ�����ع�ģ��,Ԥ����Լ���һ����/һ��ʱ������,����Ϊ����Ƿ��ڵ��������Χ��,����������Χ���ж�С������Ƿ����쳣����;3) ������쳣���,����ݵ�������õ�������Ϊģ��,�ҳ��쳣����Ĵ��ڡ�
2.1.2. ���ݸ�ʽ����
��Ի�ȡ��С���������,�趨��ز�������:
ÿ15���ӵ�С���ܱ���ѹU_super_15;
ÿ15���ӵ�С���ܱ�����I_super_15;
ÿ60���ӵ��û�����ѹU_sub_60;
ÿ60���ӵ��û�������I_sub_60;
ÿ24Сʱ�û�������W_sub;
ÿ24СʱС���ܱ�����W_super;
�ܱ����û����ܺ�֮��ΪE��

UI��������Ƚϵõ����E,ʱ������Ϊһ�졣
2.1.3. ������ϴ
ͨ�����(�ܱ��C�ֱ���)����ͼ2����,�����д����������ֵ:�ظ�ֵ�ͷǷ�ֵ��
�۲�����,���ֱַ����ܱ��ķ�ʱ������ѹ���Ȳ�ͬ,�ֱ����ִ���ȱʧֵ����ȡ�Ľ���취Ϊ�����������ѹ����ȱʧֵ������,ͨ��ɾ������ֵ,�ȱʧֵ���������ϴ��
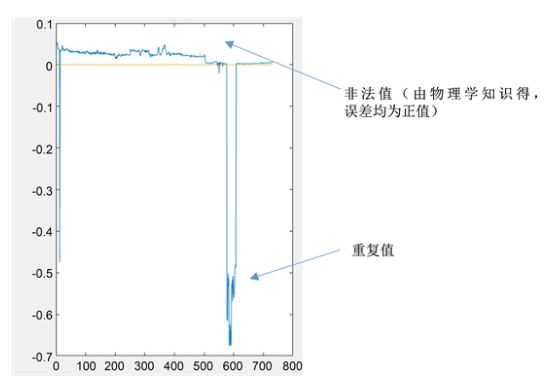
Figure 2. Huayuan community error curve
ͼ2. ��С���������
2.1.4. �������Է���
ͨ�����Ƶ���������ͼ3��ʾ,ѡȡ��Ϊ��������ݡ���������,�϶���С��2016�����ݼ����Ի�ȫ�����ݽ�Ϊ���롣

Figure 3. Electric quantity of Huayuan community
ͼ3. ��С����������
Ϊ�˷������������Ĺ�ϵ,�������ܱ���ֱ���ɢ��ͼ��ͼ4��ʾ�������������ͼ��ͼ5��ʾ�Լ�����������ͼ��ͼ6��ʾ��
�������ķֲ����з�������ͼ�ֱ�Ϊ��С��2016.1.1~3.1���ֲ���ͼ7��ʾ��2016.3.1~5.1���ֲ���ͼ8��ʾ��2016.5.1~7.1���ֲ���ͼ9��ʾ�Լ�2016.1.1~2016.7.1���ֲ���ͼ10��ʾ��
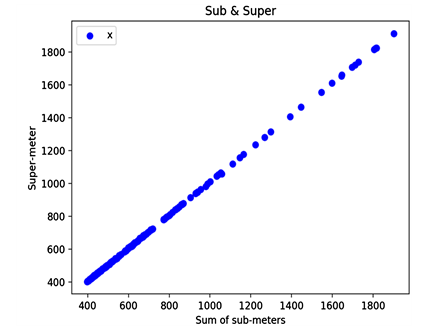
Figure 4. Sub total & super of Huayuan community
ͼ4. ��С���ܱ���ֱ���


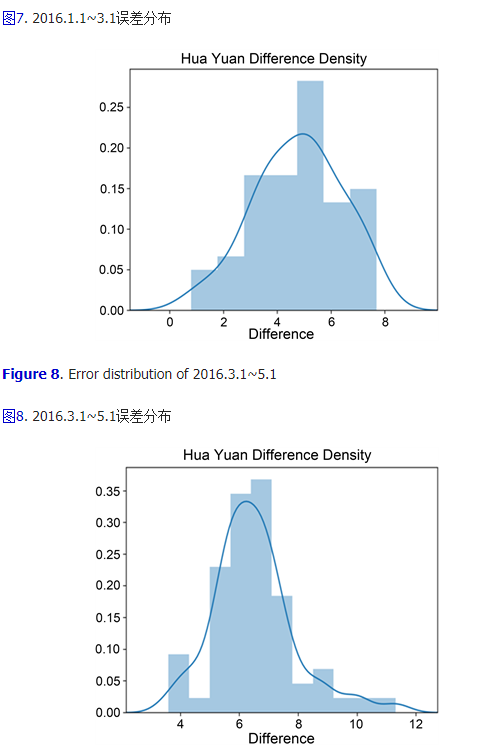
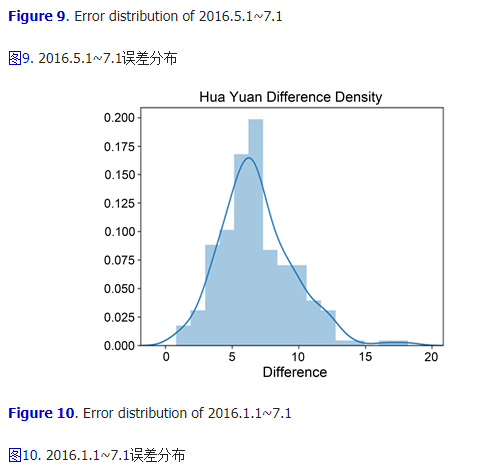
ͼ10. 2016.1.1~7.1���ֲ�
������������,����������̬�ֲ�,���Ƿֲ������̶�,��ͨ���۲�ֲ���ȷ���쳣�㡣
2.2. ���ݽ�һ������
2.2.1. ���ݸ�ʽ��
Ϊ���ڽ��л���ѧϰ����,���ݵ�ÿ�����������������������1��ʾ��
| ���� | ���� |
| �ܱ�����(super) | �ܱ��ĵ���ֵ |
| ���(error) | �ܱ��C�ֱ��� |
| �������(com_date) | ��ij����0,������������� |
| ��(week) | ��һ��Ϊ7ά���� |
| ��(month) | ��һ��Ϊ12ά���� |
| ��(year) | ��һ��Ϊ3ά���� |
| ����ֵ(log) | �ܱ���2Ϊ�Ķ���ֵ |
| ����(numbers) | ���յ��ܻ��� |
| ƽ������(A_mean) | ����ƽ������ |
| ƽ����ѹ(V_mean) | ����ƽ����ѹ |
Table 1. Add data characteristics
��1. ������������
2.2.2. Ƥ��ɭ���ϵ������
Ϊ�˸������ѧϰ������Խ���,��ÿ��ά��֮����������ϵ������?[13]��
2.2.3. K�۽�����֤
�����ݲ�ȡ5�۽�����֤��ʽ,�������֮һ���������ڲ���,������������ѵ��,���Եõ����鲻ͬ��ѵ��������Լ� [14]��
3. �������������
3.1. ���ݿɿ��Է���
�õ������ݺ���Ҫ����ɿ��Խ��з�����������ѡ��С���в�ͬ�û�������ͬһʱ�����ͬһʱ��ĵ�ѹ�������������������ͬһʱ��,��ͬ�����ĵ�ѹ����Ǵ���һ�µ�,���Ҹ��ݲ�ͬ������,��ѹ�ı仯����Ҳ�������ơ�
�����ٷ��������仯����������ѡȡһ���û��ĵ��,�������ڲ�ͬʱ�̵���������ͼ��ͼ11��ʾ�����ߴ������賿3��,���ߴ����峿6��,�����ߴ�������6�㡣���Կ���,3���ǵ�����ֵ�����������,������6��ʱ��������,������6��ʱ�ﵽ��ߡ�������������Ϊ�賿3��ʱ�õ�������,������˶���˯��,������6���õ������ࡣ

Figure 11. Electricity consumption of same user
ͼ11. ͬһ�û����õ����
�����������ڰ��·�ʱ��������,���Ҳ���С,��˵����������Ϊ���·����������ȵ�ʱ��,�����¶�����,�û���ʼƵ��ʹ�ÿյ������õ�����,����ҹ��Ҳ���ֿյ����ڴ�״̬���Ӷ����Խ����ڰ��·�����ʱ���ĵ�����������ԭ��
�����0.2 A��Ϊ��,����0.2 A����Ϊ���û������õ�״̬������0�㵽24���õ继����ͼ����ͼ12��ʾ����ͼ��֪,6���18���ȷ�õ������϶�,���賿3�����,˵����ǰ������ȷ��
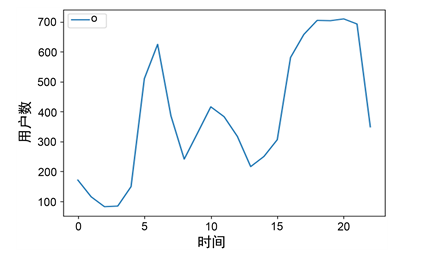
Figure 12. Number of users in different time at same day
ͼ12. ͬһ���ڲ�ͬʱ���õ继��
3.2. �쳣�����
�����е��쳣ֵ��Ҫ�����ע����������쳣ֵ���м������,������Խ����������Ӱ�졣������������ͼ��ʶ���������е��쳣ֵ,��python�����û����ڵ�ѹ������ͼ [15]��ȫ���û�5�����ڵĵ�ѹ������ͼ��ͼ13��ʾ�����Է���0�㵽6��֮���쳣�㼫��,��֮�����ڿ��ܴ����ص�����,�����Ƿ������쳣��������������жϡ�
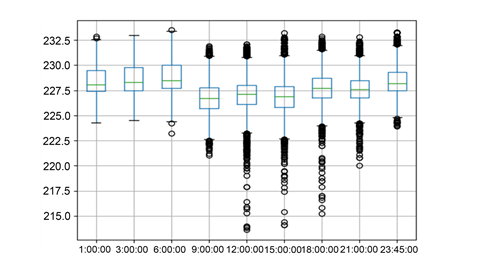
Figure 13. Voltage box diagram
ͼ13. ��ѹ����ͼ
����������ͼ��ͼ14��ʾ,���Ƿ����쳣�㶼����������Ϸ�����Ϊ�����ʱ��ܶ�������ڹر�״̬,���Ե��¾�ֵ�ϵ�,���������Ϸ������쳣�㡣��������ͼ14ȷ������0.2 A��Ϊ�ж��û��Ƿ��õ�ı���
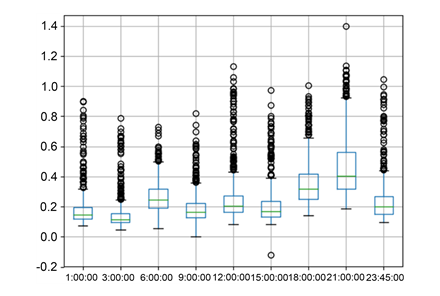
Figure 14. Current box diagram
ͼ14. ��������ͼ
3.3. ����ʽ���
���ù�ʽ?W=U?I?tW=U?I?t?Ȼ�����,���Եõ��зֻ���������ĵ���ֵ�������ܱ���õĵ���ֵ��֮���,��ɵõ������ⶨ�����ֵ������poly0fit����ǰ��õ����ֵ�������,���������� [16] [17]������ѡȡʱ����Ϊ����7����209�졣ͨ���ı����ʽ������������������ͬ�����ͼ,��������ͼ����ߴ��ݷֱ�Ϊ4��8�����ͼ,��ͼ15��ͼ16��ʾ����4��8��ϳ̶��������,��ʵ��֤ʵ��ߴ�����8��ߵ�10��Ч����̫���ԡ�
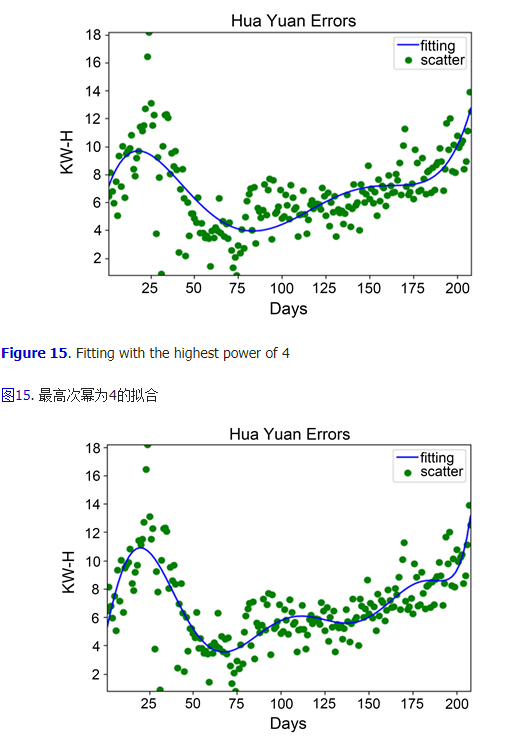
Figure 16. Fitting with the highest power of 8
ͼ16. ��ߴ���Ϊ8�����
4. ���ѧϰʱ��ģ��
����ǰ��ķ���,Ϊ�����ܱ������ͷֱ��͵�����ʱ����,ʹ����һЩģ����������������ݺ��ļ������IJ�����ģ����Ҫ��������ϢԴ������:�ֲ�������ȫ������������ʱ����(LSTM)ѭ����������ΪRNN��һ����Ҫ����,���������콨ģ�߱�����������������,��Ϊʱ������Ԥ����������洦,��Ϊ�������Է���������Ӧ������������Ԥ�����⡣������Tensorflow��Keras���ѧϰ���д���ڶ����ʱ������Ԥ���LSTMģ�͡�
����о�����,LSTMģ���ڴ���ʱ������ʱ��һ������:��Ϊ����ڹ�ȥֵ��ȥֵ��Ԥ��ֵ��Ԥ��δ��ֵ�����ǽ���ʹ�ü��ڵ���ɢ���������,ʹ�ù�ȥֵ��Ԥ��ֵ��ʹģ�����ȶ���ѵ��������ÿһ���Ĵ����ۻ�,��ijһ�������˼��˴���,���ܾͻ�ٻ����������ʱ����Ԥ������ [18] [19]��
���ѧϰʱ��ģ�͵Ĺ�������:1) ��ԭʼ���ݼ�ת����������ʱ������Ԥ������ݼ�;2) �������ݲ�ʹ����Ӧ���ڶ����ʱ������Ԥ�������LSTMģ��;3) ����Ԥ�Ⲣ���������
4.1. ʱ������Ԥ����
����֮ǰ���������̺����ݴ���,�Ѿ���ȡ�������������������صı���,������ΪRNN������������ȡ�����㹻ǿ��ģ��ʹ�õ������������������2��ʾ��
| ���� | ���� |
| ��sub��: ��float�� | ��Ԫ�û��ֱ��͵��� |
| ��super��: ��float�� | �ܱ���������ֵ,ʵ��xֻȡsuper��sub��һ�Ա�֤ģ�͵ķ������� |
| ��error��: ��float�� | �ܱ���ֱ�������õ�����ĵ����������,��ģ������yֵ,��������Ϊxֵ |
| ��com_date��: ��int�� | �������,ԭʼ���ݵĵ�һ����Ϊ0,֮��ÿ����� |
| ��week��: ��list�� | ʱ����������,7άone-hot����; |
| ��month��: ��list�� | ʱ����������,12άone-hot����; |
| ��year��: ��list�� | ʱ����������,3άone-hot����; |
| ��numbers��: ��int�� | �õ继��,��Ϊ3���ﻧ���б仯(�°����û��Ͱ����) |
Table 2. Deep learning time model characteristics and data type
��2. ���ѧϰʱ��ģ����������������
��������(����one-hot���������,����x��y)�����ɾ�ֵΪ�㡢��λ���������,ÿһ���������ж��ǶԱ��е������ġ����õ��������б��������ֵ��������Standardization��ָ���������ݵķֲ������ɱ���̫�ֲ�,Ҳ�и�˹�ֲ�,Ҳ����ʹ�����ݵľ�ֵΪ0,����Ϊ1��������ԭ�����������Щ�����ķ������,�������Ŀ�꺯���Ӷ�ʹ��������������ȷ��ȥѧϰ�������������ֵ����MaxAbsScalerʹ�������ֲ�����һ��������Сֵ�����ֵ�ķ�Χ�ڵġ�һ�����������[0, 1]֮�䡣���ֵ������ר��Ϊϡ�����ݵĹ�ģ������Ƶġ�֮���ʵ����Ҳ��֤�˱���,����������ֵ���������ʵ�鷢�ֱ���Standardization��ʱ���������,��ѵ�������ݷ���ʱ��Ҫ����ע�� [20] [21]��
ģ�ʹ�ԭʼʱ�������������ȡ�̶����ȵ���������ѵ��������,���ԭʼʱ�����еij���Ϊ600��,��ô��ѵ��������ʱ�䲽����Ϊ200��,�Ϳ�����400�ֲ�ͬ����ʼ�㡣���ֲ��������൱��һ����Ч��������ǿ���ơ���ÿһ��ѵ����,ѵ���������ѡ��ʱ��Ŀ�ʼ��,�൱�������������ġ��������ظ���ѵ�����ݡ�ʱ�䲽���DZ�ģ������Ҫ�ij�����,��ѧϰ����Ԥ������ʱ,LSTMͨ��ʱ�䲽���з�����֮�����ΪLSTMģ����ר�õ�ʱ�����ݼ�,����漰�����ݼ������ලѧϰ���⡣�ලѧϰ��������趨Ϊ:1) ������һ��ʱ��ε��ܱ�����������,Ԥ�ǰʱ��(t)�ĵ�����;2) ���ݹ�ȥһ��ĵ������Լ���һ��Сʱ��Ԥ�����,Ԥ������һ��Сʱ�ĵ����������
������5��������,��ʹ�õ�1������������ģ��,Ȼ��������4������ݽ���������1) �����ݼ��ֳ�ѵ�����Ͳ��Լ�;2) ��ѵ�����Ͳ��Լ��ֱ�ֳ�������������;3) ������(X)�ع�ΪLSTMԤ�ڵ�3D��ʽ,��[������,ʱ�䲽,����]��
4.2. ʱ����������ѵ��
ʱ��������,����ѵ��������֤���ķ�����������ͼ17��ʾ��
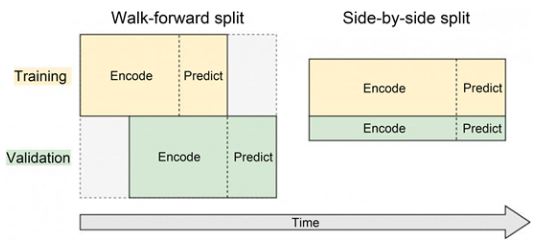
Figure 17. Classification of training set and verifying set
ͼ17. ѵ��������֤���Ļ��ַ���
4.2.1. Walk-Forward Split����
Walk-forward split������ʵ�ϲ�������ڻ������ݡ��������ݼ���ȫ��ͬʱ��Ϊѵ��������֤��,����֤�����˲�ͬ��ʱ��������ѵ������ʱ���,��֤����ʱ�������ǰ��һ��Ԥ�����ڡ�
4.2.2. Side-by-Side Split����
Side-by-side split������һ�������Ļ��ַ�ʽ,�����ݼ��з�Ϊ�����IJ�ͬ�Ӽ�,һ������ȫ����ѵ��,��һ������ȫ������֤��
Walk-forward split�����Ľ�����ɹ�,�ȽϷ����о�������Ŀ��:����ʷֵԤ��δ��ֵ���������зַ��������,��Ϊ����Ҫ��ʱ������ĩ��ʹ����ȫֻ����Ԥ������ݵ�,������ʱ��������ѵ�������ݵ��Ԥ������ݵ����ϳ�,��ҪȷԤ��δ�������ݾͻ������ѡ�������300�����ʷ����,��ҪԤ���������100�졣���ѡ��Walk-forward split���ַ���,���ʹ�õ�ǰ100����Ϊѵ������,������100����Ϊѵ�������е�Ԥ������,������100�������������֤��������Ҳ����ʵ��������1/3�����ݵ���ѵ��,�����һ��ѵ�����ݵ�͵�һ��Ԥ�����ݵ�֮����200��ļ�����������ϳ�,����һ���뿪ѵ���ij���,Ԥ�������������½������ֻ��100��ļ��,Ԥ��������������������Side-by-side split������ĩ�������ϲ��ᵥ���������ݵ���ΪԤ������ݼ�,��ģ������֤���ϵ����ܾͻ��ѵ�����������к�ǿ�Ĺ�����,ȴ��δ��ҪԤ�����ʵ����û���κ������,����,������������û��ʵ��������,ֻ���ظ�����ѵ�����Ϲ۲쵽��ģ����ʧ��
��ģ����ʹ��walk-forward split�������ֵ���֤��ֻ���������Ų���,����Ԥ��ģ�ͱ�Ȼ������ѵ��������֤����ȫ����ص����������еġ�
ʵ���о��ǽ��ڵ�һ�����ز��ж������40����Ԫ��LSTM,��������ж���1������Ԥ��������Ԫ����������ά�Ƚ���1������22��������ʱ�䲽��Ϊ40���������
ʵ���о���ʹ���˾��������(RMSE)��ʧ������Ч������ݶ��½���Adam�汾����ģ�ͽ�������1000��epoch,��СΪ128��ѵ����ѡ��epoch����Ŀʱ,��Ϊ�����ģ��ѵ������һ�������ʺ�����Ԥ��δ��ֵ��(��Ϊ���ڵ�ǰ���ݵ���֤����δ�����ݵĹ����Ժ���),���Բ��ܹ���ֹͣѵ��������ʵ������ѡ��1000��Ϊepoch����Ŀ��
ģ����Ϻ�,����Ԥ�������������ݼ�����Ԥ����������ݼ�����,�������������ݼ��Ĺ�ģ����ʹ����Ԥ�ڵ�����������������ݼ��Ĺ�ģ��ͨ����ʼԤ��ֵ��ʵ��ֵ,���Լ���ģ�͵��������������������,���Լ�����������ͬ�ĵ�Ԫ���ľ��������(RMSE)��RMSE�dz��õĻع��������ʧ����,��ͬ�ڽ�������ʧ�����ڷ�������,�ڱ������������Կ��ٵõ���ʧ���ҵõ��Ľ��ÿһ������ƽ����
4.3. ����������쳣���
ʵ�������˫��LSTM�͵���LSTM��Ԥ����,���㵥Ԫ�����ֱ�Ϊ20��40�������ͼ18��ͼ19��ʾ��
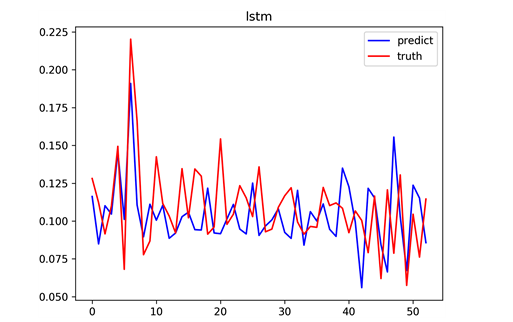
Figure 18. Predicted value and real value of LSTM model
ͼ18. LSTMģ��Ԥ��ֵ����ʵֵ

Figure 19. Scatter diagram of LSTM model
ͼ19. LSTMģ��ɢ��ͼ
ʱ��ά���ϵ�Ԥ��ֵ����ʵֵ�Ƚ�,���Կ������������Ԥ���Ϊȷ,ͬʱ���Է���Ԥ��ֵ��һ�����ͺ�ɢ��ͼ��,Խ����y = xֱ�߱�ʾģ��Ԥ��Խȷ��
�û��������쳣���,����һ������Ϊl�Ļ���,������ֵΪt��
����ÿһ�λ���:���������ÿһ��Ԥ��ֵ��ʵ��ֵ֮�������ֵ,����Ϊ����һ�쿪ʼ�����������ڿ���Ϊ4,��ֵΪ0.5ʱ,�����ͼ20��ʾ������65�쿪ʼ,���ݳ��ֿ��Լ����쳣,ͨ���Կ�������ֵ�ĵ���,���Եõ����߾��ȵĽ����
������û���쳣ʱ,�����ͼ21��ʾ��
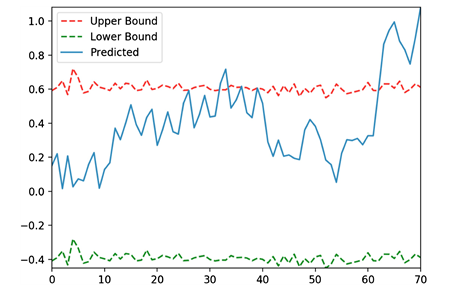
Figure 20. Abnormal date of calculation
ͼ20. ��������쳣�������
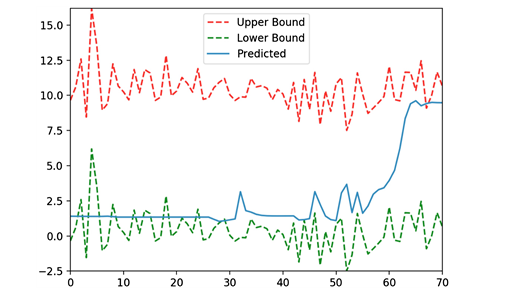
Figure 21. Predicated value within range
ͼ21. Ԥ��ֵ�ڷ�Χ֮��
5. ����
���������ܵĻ������ѧϰģ�͵Ķ�Ԥ�������Ƿ��쳣�ķ�������֮��Ч�ġ������ҹ����ܵ�����ռ���Ӧ��,�ڸ�������ݵ�֧����,�����ܵ����Ԥ��������ȷ,Ҳ������δ��ʹ�ҹ����ܵ����ʹ�����������������Բ����������ؼ��,��֤���ϵ����������ʹ��,�Ӷ�ʹ�����ʵ��ʹ��������������,�Ӷ���ʡ��������Դ��

���ǵķ�������
�����γ�
�˹����ܡ������ݡ�Ƕ��ʽ? ? ? ? ? ? ??? ?? ?
��ѵ�γ�
��ͨ��ѵ��������ѵ? ? ? ? ? ? ? ?? ??? ? ??
��Ŀ��ѯ
����·����ơ��㷨�����ʵ��(ͼ��������Ȼ���Դ���������ʶ��)

