Bendale A , Boult T . Towards Open Set Deep Networks[C]// 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2016
����Ŀ¼
ժҪ
��������ڸ����Ӿ�ʶ�������ϲ�������������,������ѧ������ҵӦ�á�������������Ĺ���ǿ��,����������������Զ���Ὣ�����Ϊ�ض������ͼ��,������������Щͼ�����Ϊ����������ŶȺܸ�,�����������ױ�������Ϊû�������ͼ����Ū���������ķ�ռ�������ʹ���Ǵ���֪���н���ѡ��,���´����¼�������ʵ������ʶ���ǿ��ż�,��ʶ��ϵͳ�ڲ���ʱ�ܾ�δ֪/���������ࡣ���������һ����Ӧ���������п��ż�ʶ��ķ���,ͨ������һ���µ�ģ�Ͳ�OpenMax,������һ����������δ֪��ĸ��ʡ�����δ֪���ʵ�һ���ؼ������ǽ�Ԫʶ�����Ӧ�������絹���ڶ���ļ���ģʽ��OpenMax�����ܾ����ָ�ϵͳ�ġ���ƭ���Ͳ���صĿ��ż�ͼ��;OpenMax�������������������ɵ����Դ����������֤����OpenMax�����ṩ���н翪�ռ����,�Ӷ���ʽ�ṩ��һ������ʶ��������������ʹ������ImageNet2012����֤�����ϵ�Caffe Model-zoo��Ԥѵ������,�Լ���ǧ�š���ƭ���Ϳ��ż�ͼ��,���������õ��Ŀ��ż�������硣�������OpenMaxģ���������ڻ����������;���softmax������ֵ���õ��������Ŀ��ż�ʶ�ȡ�
1 ����
�������Ӿ���ѧϰ���о���չ,������Ӿ����ݼ��Ѿ��Ӽ�����ͼ����������������ͼ��,���Ӽ��������������ǧ����𡣽����������������о������������Ӿ�ʶ��[26,3,11]������档�ḻ�ı�ʾ���������ķ�����ʹ������ݼ��Ĺ�ͬ�����Ѿ�������������ҵӦ��[5,28,16,6]��Ȼ��,�ڶ�̬�Ͳ��ϱ仯����ʵ�����в���ʶ��ϵͳʱ,�㷺�IJ�����ս���������������ʶ��ϵͳ��Ϊ��̬���������Ƶ�,������Ҫ�ļ����������������֪�ġ��������,�������ྭ��Ļ���ѧϰ����һ��,���������ִ�з�ռ�ʶ��
����ڿ��ż�ʶ��[20,21]�Ϳ�������ʶ��[1]����Ĺ���,�Ѿ���ʽ�����ڲ���ʱ��Ҫ�ܾ�δ֪����������н���ʶ��Ĺ��̡���Ȼ�������ǿ�����һ��������������ѵ���Ա�ʾ������Ȥ����(��֪��δ֪KU),����������������δ֪����Ŀ���������ѵ�������,��Ҫ����Ӿ�ʶ��,��ʽ���͡�δ֪��δ֪��[18]����Ȼ�Ѿ�������һϵ�е��㷨������������[4,20,21,25,2],���������������п��ż�ʶ����Ȼ��һ��δ��������⡣
�ڴ�����������[11,26,3]��,���һ��ȫ���Ӳ������������SoftMax����,�Ӷ���N����֪���ǩ�ϲ������ʷֲ�����Ȼ�������������һ������ܵ���,�����ǿ���ϣ��,����δ֪����,������ĸ��ʶ��ǵ͵�,��ֵ����ȷ���Խ��ܾ�δ֪�ࡣ���������չʾ����β�������ƭ��[14]����������[8]ͼ��,��Щͼ�����Ӿ���Զ����������,�������߸���/���Ŷȷ���������ǿ����Ϊ,�Բ�ȷ���Ե���ֵ��������ȷ��ʲô��δ֪�ġ��ڵ�3����,���DZ���,�����������չ����SoftMax����������ֵ��һ���̶�������˿��ż�ʶ��,�������ܽ����ƭͼ�����������������������/ʵ����,��ʹ����ֵ����,Ҳ��������[20]���ᵽ�Ŀ���ʶ�����ʽ���塣��������˱���������ĵ�һ������:�����ʹ���������Ӧ��֧�ֿ��ż�ʶ��?��
SoftMax���������һ����Ҫ��ɲ��֡������������һ���������,OpenMax,ͨ��������Ԥ��δ֪������չSoftMax�㡣OpenMax������ʶ��ϵͳ���ϵĿ����ԡ����ֿ��������ڹ�������һ��δ֪��ĸ�������ĸ��ʡ������������,���ǽ�Ԫʶ��[22,32,9]�ĸ���Ӧ����������硣����ʹ�������������ĵ����ڶ���(��SoftMax֮ǰ��ȫ���Ӳ�,����,FC8)�ķ��������������Ƿ�����֪��ѵ�����ݡ���Զ�������ǽ��ò��еķ�����Ϊ��������(AV)����Щ��Ϣ�����뵽���ǵ�OpenMaxģ����,����������ʶ��ϵͳ�Ĺ��ϡ�ͨ����ȥ��֪�����֮��Ϊ1�����Ʋ��ܾ�Զ����֪���������,OpenMax�����ڲ�����������ʽ����δ֪/���ɼ����ࡣ���ǵ�ʵ�����,�������OpenMax��Ԫʶ��˼�����Ϻ�������������Ŀ��ż�ʶ��,���ܾ������Ŷ���ƭͼƬ��
��Ȼ��ƭ/����ͼ��,������۲�����˵,��Ȼ���������ڸ���Ȥ��һ��,�Կ���ͼ��[8,27]�����һ�������ѵ���ս����Щ�Կ���ͼ�����Ӿ�����ѵ��������������,������Ƴ�ʹ�����������߿��Ŷȵ�����ȷ�Ĵ𰸡�������Ŀ��ſռ���ղ�ͬ,��Ϊ�����κθ����������,�Կ���ͼ��������ռ��С��ӽ���һ��ѵ��������
�����ǵĿ�����������е�һ���ؼ�������,�����ſռ���ա�Ӧ���������ռ��в���,�����������ؿռ��в�������֮ǰ�Ĺ�����,���������[20,21,1]�Ŀ��ſռ���ղ������ؿռ��в��������,�����ʡ��Ƿ����һ�������ռ�,���������������������е�һ����,ʹ��Щ�Կ�ͼ��Զ��ѵ������,���������δ֪�ġ���ƭ�ĺͶԿ���ͼ���ڿ��ż�ʶ�������л��Ϊ�쳣ֵ?����2.1����,�����о�������������в������ſռ���յ������ռ�/���ѡ������֤��,�ڵ����ڶ������������弤��ģʽ��,��ֵԪʶ�����������һ������Ϊδ֪ͼ����ƭͼ����������Կ�ͼ���OpenMax��һ���ṩ�˾ܾ���������ͼ1��,����չʾ������ģ�͵ļ���ģʽ��һЩ����,����ͼ����ƭͼ�Կ���ͼ��(ϵͳ�ܾܾ���)�Ϳ��ż�ͼ��
�ܽ��˱��ĵĹ���:
1.���ü��������Ķ���Ԫʶ�����������������ϵĸ��ʡ�
2.����Ԫʶ���OpenMax�γɿ��ż��������,��֤����������ķ������Թ����������Ŀ��ſռ���ա�
3.ʵ��������ż���������ڱ��ֲ���ͼ��ȷ�Ե�ͬʱ,�ܾ�δ֪�ࡢ��ƭͼ���ɶԿ�ͼ����������Դ������Ч�ԡ�
����:
- ��softmax�������������ֵ��һ���̶�������˿���ʶ��,���Dz��ܽ����ƭͼƬ�����⡣
- ���������ĵ����ڶ���(softmaxǰ��ȫ���Ӳ�)�����������������,�������һЩ���������������Ƿ�����֪��ѵ�����ݡ���Զ����
- openmax��Ԫʶ�����������������翪��ʶ�����⡣
- �ڵ����ڶ������������弤��ģʽ��,��ֵԪʶ�����������һ������Ϊδ֪ͼ����ƭͼ����������Կ�ͼ���OpenMax��һ���ṩ�˾ܾ����ʡ�
2 ���ż��������
����������һ����Ȼ�����Ƕ��������Ӧ��һ����ֵ��������Ϊ���Ǿܾ���ȷ����Ԥ��,�����Ǿܾ�δ֪�������Ԥ������δ֪���ͼ���нϵ͵ĸ���,���dz���ȷ������ֻ������һС����δ֪���롣�ڵ�3�����ǵ�ʵ�����,��ֵ����ȷ�����������а�����,����Ȼ�����ڿ��ż�ʶ�����Խ����Ĺ��ߡ�Scheirer����[20]�����ſռ���ն���Ϊ����Ǿ���֪ѵ����������Զ����������صķ��ա������ֻ�ṩ��һ��һ��Ķ���,��û�й涨��β�������,Ҳû�й涨Ҫ�������־���Ŀռ䡣Ϊ��ʹ��������ܹ��������ż�ʶ��,���DZ���ȷ�������ܹ�����/��С���俪�ſռ����,�����оܾ�δ֪�����������
����[21,1]�еĸ���,����Ѱ��ѡ��һ����(�����ռ�),���������ǿ��Խ���һ�����նȼ�������ģ��,����ͨ����ֵ�����ƿ��ſռ�ķ��ա����Ƿ�չ�����ģ����Ϊһ����������ѧϰģ�͵ľ����˥������ģ�͡��ڽ��������½���,���ǽ���ϸ�������ƴ���֪ѵ�����ݾ���Ŀռ��Ԫʶ��,Ȼ����һ�ֽ����־����������������ߺ����ķ��������dz����ǵķ���ΪOpenMax,��ΪSoftMax���������Ʒ,��Ϊ��������һ�㡣���,����֤��������ģ����һ�����նȼ�������ģ��,���,������һ������ʶ��Ķ��塣
2.1 ����Ԫʶ��(Alg.1����MAV��Weibull��ϲ���)
���ǵĵ�һ����ȷ����ʱһ������ܿ��ܲ�������һ����֪����,Ҳ����˵,������Ҫ����һ��Ԫʶ���㷨[22,32]����������,��ʶ���������������Ƿ���ܲ���ȷ����ǰ��Ԫʶ����ʹ�������յ�ϵͳ����,���ڼ�ֵ����(EVT)���������ǵķֲ�,������Щ�ֲ���ѭ�������ֲ�����Ȼ���ǿ��Զ���ʹ��ÿ����ķ�����ʹ��EVT�������ǵķֲ�,���ⲻ�����һ�����նȼ�������,��Ϊ��ƭ��ͼ����ʾ����������������һ���ӽ���֪����ѵ�����ݵĽ��տռ䡣����,�����ʶ�����(SoftMax��)�ļ���ֱ�ӽ���EVT��϶����������û������,��Ϊ���յ�SoftMax�㱻���������������ѭ���ֲ������,���Ƿ��������ڶ���,��ͨ������Ϊÿ��Ĺ��ơ����ÿ��Ĺ��Ʊ�SoftMax����ת��Ϊ���յ�������ʡ�
���Dz��õķ�����,���Ե����ڶ��������ֵ(���¼����������(AV))����һ��������ÿ���������,�����ṩ����Щ���ǡ���ء��ķֲ�����2.2�����������˻���ͼ1��һ��ʾ����
���ǵ�����EVTԪʶ���㷨�ܽ���Alg 1.�С� Ϊ��ʹ��AVsʶ����Ⱥֵ,���Dz���������ֵ[29,12]���������Ⱥֵ[1]�ĸ���,��������Ӧ���ڼ��������е�ÿ����,��Ϊ��һ���ơ���Ȼ�����ӵ�ģ��,������������(NCMC)[13]��NCMɭ��[17],�����ṩ��ȷ�Ľ�ģ,��Ϊ�˼����,����ֻ��עʹ�õ�һ��ƽ��ֵ��ÿ���౻��ʾΪһ����,һ��ƽ����������(MAV),ֻ������ȷ�����ѵ��������ƽ��(Alg 1 �ĵ�2��).
����MAV��һ������ͼ��,���Dz�������֮��ľ��롣���ǿ���ֱ�ӶԾ���������ֵ,����,ʹ��[1]�� cross-class��֤����������һ����ŵ���������ֵ����[1]��,��Щ����ͨ������ѧϰ��ʹ���ǹ淶��,��ʹ��һ����һ�Ĺ�����ֵ���С�Ȼ��,��ͬ����AVȱ��һ���Դ����˸������ս,���,����Ѱ��ÿ������Ԫʶ��ģ�͡���Alg 1 �ĵ�3��,����ʹ��libMR[22]FitHigh������������ȷ����ѵ��ʵ������صĦ�i֮��������������������ϡ���õ���һ��������i,�����ڹ���һ����������ڵ�i����쳣ֵ�ĸ�����
������i,һ���ľܾ�ģ�ͽ�Ϊ�û�����һ����ֵ,����һ�������Ƿ�Ӧ�ñ��ܾ�,����,ȷ��90%��ѵ�����ݱ��ܾ��ĸ��ʽӽ����㡣��Ȼʵ�������ܼ�,������Уһ�����Ե�Ԫʶ����ֵ,��Ϊ��������δ֪��δ֪�������,����ѡ��ʹ����Sec2��������OpenMax�㷨,���ܹ�����������
����ע�,���ǵ�У����ֻʹ������ȷ���������,������j������1���ڲ�����,��������x,������j�������ĸ���,��ô��j(x)�ṩ��x��һ����Ⱥֵ����Ӧ�ñ��ܾ���Mr���Ƹ��ʡ����ǶԸ�����(����,ǰ10��)ʹ��һ��У,����Ϊһ����չ,�Բ�ͬ����ĵ���У�ǿ��ܵġ�ע��,��ÿ�������ж��ͨ��ʱ,���Ǽ���ÿ��ͨ��,ÿ�����ƽ��������j,c��������������j,c��ֵ�ü�ס����,���ǵ�Ŀ�겻��ȷ���������ĸ���,����һ��Ԫʶ�����,����ȷ�������������Ƿ�����δ֪��,���Ӧ�ñ��ܾ���
2.2 ��������( activation vector)�Ľ���
�ڱ�����,���ǻ���ͼ1˵������������Ԫʶ��ĸ��
 ��ռ�:�ٶ�������һ����ͷ�����Ч����,��ͼ1�еĵڶ��鼤���¼������������ʾ����������ص�AVά�ȵĸ߷֡����е����㶼���������㡢����ʹ�������������ֱ�ӵ��Ӿ����������������ĵ��Ӿ�����,�����Ϊʲôͼ1��ʾ����ЩȺ��������ImageNet���Ķ�����ߵļ���ֵ(������ɫ)�����Ǽ���,���ڴ�������,����һ�����һ�µ���ؼ���ģʽ��MAV���÷ֲ�����Ϊ�����㡣AV�ṩ��һ���ռ�,���������Ǹ���ÿ�����ļ���ֵ������������ͼ��ľ���;����Ǵ����,����ҲԤ�ƻ��衢��ͷ���Լ�����ļ���ֵ�����,�����������dz�����û�м���ֵ��ֱ�۵ؿ�,���ƺ�����ѵ�������в�������ĺ��ʿռ䡣
��ռ�:�ٶ�������һ����ͷ�����Ч����,��ͼ1�еĵڶ��鼤���¼������������ʾ����������ص�AVά�ȵĸ߷֡����е����㶼���������㡢����ʹ�������������ֱ�ӵ��Ӿ����������������ĵ��Ӿ�����,�����Ϊʲôͼ1��ʾ����ЩȺ��������ImageNet���Ķ�����ߵļ���ֵ(������ɫ)�����Ǽ���,���ڴ�������,����һ�����һ�µ���ؼ���ģʽ��MAV���÷ֲ�����Ϊ�����㡣AV�ṩ��һ���ռ�,���������Ǹ���ÿ�����ļ���ֵ������������ͼ��ľ���;����Ǵ����,����ҲԤ�ƻ��衢��ͷ���Լ�����ļ���ֵ�����,�����������dz�����û�м���ֵ��ֱ�۵ؿ�,���ƺ�����ѵ�������в�������ĺ��ʿռ䡣
���ż�:���������ǿ���һ�����ż�ͼ��,��һ������δ֪������ʵͼ����Щ���ݽ����DZ��������ӳ�䵽SoftMax�ṩ�����Ӧ����,����,ͼ1����ʾ����ʯͼ��ӳ�䵽����,�ұߵ��㱻ӳ�䵽һ����ͷ�㡣��ʱ���ż�ͼ������ŶȽϵ�,����������������Ӧ���ࡣ�Ƚ������AV����������������Ӧ�����MAV,���ǹ۲쵽��ͨ��Զ��ƽ��ֵ��Ȼ��,����һЩ���ż�ͼ��,�ṩ����Ӧ�ӽ�AV,����Ȼ��һ������ĵͼ���ˮƽ�����������һ������֪��������صġ�δ֪����,������������㹻С,�����ܺܺõ�����,�ͻᷢ���������������,����������Բ�ͬ���͵�������������,�������ṩһ���ͼ���ֵ,��AV����û���㹻�IJ�ͬ�����ܾ������,����ֱ�ӹ���һ�����Ƿ�δ֪��,����Ҫ�Բ�ȷ����������ֵ���п��ż�ʶ����
��ƭ��:����һ����ƭ����ͼ��,������Ϊ�����,ʹһ���ض�����(����,�����ͷ��)���кܸߵļ������,���,�����ԺܸߵĿ��ŶȽ��м�⡣��Ȼ��Ϊ���������˸���Ȥ��ĸ���,��ͼ�����ɹ��̲�û��ͬʱ�������������ķ���,����AV��ģ��AV����Զ�������ͼ1��ÿ������ĵ�����Ԫ��,������ʾ��������ƭͼ��ļ���ֵ��������ƭͼ�����Ӿ�������ȫ��ͬ��,���ǵļ�������Ҳ�Dz�ͬ�ġ����༤��ȷdz��͵�����(����ɫ/��ɫ)��������Ϊ���ǿ���ͨ������������ļ���ֵ�����Ӹ������SoftMax�����,�ⷴ�����ּ�����SoftMax����ķ�ĸ��
�Կ���:���,����һ���Կ��Ե�����ͼ��[8,27,31],��������Ϊ�ӽ���һ����,��������ر��Ϊ��һ���ࡣͼ1�����½���ʾ��һ�����ӡ�����Կ���ͼ���쵽һ����������,����,�Ӵ�ͷ�赽�����,��ô��������ķ�����������������MAV��û�в���ϸ���ȵ������졣Ȼ��,�Կ���ͼ��������κ�һ��ͼ����֮�乹��,�μ�[27]����Ŀ������㹻Զʱ,����,����Ĵ�ͷ��ˮ�ε�����,���߸�Զ,�紸ͷ�Ͱ���,�Կ���ͼ���ڼ�������������������,��˿��Ա��ܾ��������ǵ�ʵ����,���Dz����ǶԿ�ͼ��,��Ϊ��������������ѡ�����ɵĶԿ�ͼ��ĺ�����������֪������û������ķֲ�������,�������ѡ��������(a,b)����a��b���ɶԿ���ͼ��,���д�������кܴ�IJ�ξ���,�ܿ��ܱ��ܾ����������ѡ����ӽ��ĶԿ���ͼ��,�ܿ������Ը�������,�����ܽӽ�,���ǽ����ᱻ�ܾ���
OpenMax���̵Ľ����,���ż��Լ���ƭ��Կ���ͼ��ͨ���ᱻ�ܾ�������һ�������ܾ�����ƭ��Կ���ͼƬ������ζ�Ÿ���Ȥ�������� �߷�,����ζ�ű���999�����������Է���������,��ЩԼ�����������˶Կ�/��ƭͼ��Ŀռ䡣ϣ���κ���������Լ����������һ��Ҳ�õ�������֧�����ǩ��ͼ��,��[14]��ͼ3���һЩ��ƭ��ͼ��,���ڶԿ�ͼ�����ϸ���ȷ�������繫ţ�ʹ���衣
���ǿ��ܻ���֪��,����MAV�Ƿ�����Ա�ʾ���в�ͬ����/��ͼ�ĸ��Ӷ���δ���Ĺ���Ӧ�ü����Բ���ͬ����ͼ/�����ĸ����ӵ�ģ��,����,NCMC[13]��NCMɭ��[17]������������ʵ�����Ѿ�ʵ������ͼ����ʶ���Ŀ��,��ô�����ڶ������������ķֲ�Ӧ�ü�������ͼ�����ġ���Ȼ������ſ��Ͳ���ͼ���Ӿ�������ȫ��ͬ��,���ģ�Ϳ��ܸ���Ч�ز���ͬ�ӽ��в�ͬ������,����ͬ������ſ����Ȼ�dz�����,���ǵIJ���ͼҲ����ˡ����,ÿ����ͼ���ܳ���һ�����һ�µ�AV,��������MAV�������ߡ�ֱ�۵ؿ�,��Ȼͼ��������������ͼ���仯�ܴ�,����AV�������ġ�����ࡱ�����ǿ��Ӧ�ø���������ͼ��
2.3 OpenMax(Alg.2)
����SoftMax�����������ʷֲ����ݶȶ�����һ��������������ͨ����������������һ����ȫ���Ӳ����Ҫԭ��ͳ�Ķ����ڼ��������ÿ���ڵ���Ȩֵ������caffe���������[10]�ĵ����ڶ��������ķ���,���dz�֮Ϊ��������,�����ڲ������ľ�����ִ�еļ�Ȩ(Ҳ����˵�����ǰ��������Ȩ�õ���)����v(x)=v1(x),��,vN(x)��ÿ����ļ����,y=1,��,N�������������ѵ����,����ͼ��x���ɼ�������v(x),SoftMax�����:
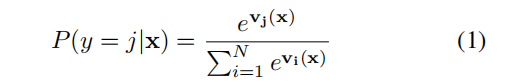 ����,��ĸ�����������,��ȷ����������ĸ������Ϊ1��Ȼ��,�ڿ��ż�ʶ����,�ڲ���ʱ�������һЩδ֪����,���,Ҫ�����֮��Ϊ1�Dz����ʵġ�
����,��ĸ�����������,��ȷ����������ĸ������Ϊ1��Ȼ��,�ڿ��ż�ʶ����,�ڲ���ʱ�������һЩδ֪����,���,Ҫ�����֮��Ϊ1�Dz����ʵġ�

Ϊ��ʹSoftMax��Ӧ�ڿ���,���ΪAlg.1 ���Ƶ�ÿ�����Ԫʶ��ģ�͵������� ��Alg.2�������ܽ���OpenMax����IJ��衣Ϊ�������,���ǽ�δ֪δ֪�ඨ��Ϊ����0������ʹ����x�ͦ�i������ϵ�������CDF����(Alg.2�ĵ�3��),��Ϊ�ܾ����Ƶĺ��ġ���i��ʹ������� i ��ص�ͼ������,��ѵ����������ȷ�����ͼ��(��һ��)���������������EVT����ֻΪ�������������ṩһ��������ĸ��ʡ����,��Alg.2�ĵ�3��,���Ǽ������������Ȩֵ,��ʹ����������������CDF���ʡ�Ȼ��,���Ǽ���������ļ�����������ߵķ����ĸı䡣����Ϊδ֪��δ֪�����һ��α����ֵ,�Ա����ܼ���ˮƽ���䡣����δ֪��δ֪��,�µ���������ֵ����OpenMax����,���ڵ�ʽ2�С�
��δ֪δ֪��(y=0)�������ĸ���ʱ,OpenMax�ṩ��֧����ʽ�ܾ��ĸ��ʡ�����Ԫʶ����ȷ��δ֪δ֪��ĵ�һ��,���ǵ�ʵ�����,����MAV�ڼ����ƭͼ�����൱��Ч,���ұȽ����Բ�ȷ�����趨��ֵ���á�Ȼ��,���κβ���ȷ���Թ��Ƶ�ϵͳ��,�Բ�ȷ����������ֵ��Ȼ��һ����Ч��Ԫʶ������,��Ӧ�������������Alg2�ĵ�9��,���յ�OpenMax����Ҳ�ܾ���δ֪�ĺͲ�ȷ���������С�
Ϊ��ѡ������,�Ǻͦ�,���ǿ���ʹ��һ��ѵ��ͼ����Ͽ��ż�ͼ��IJ���������������У,�Ż�F measure�������Ŀ���������ģ/������ѡ��Ļ���У,�������Ż�δ֪δ֪���ռ��ϵ���ֵ,�ⲻ��ͨ��ʵ������ɡ�
ע��,δ֪δ֪��ĸ��ʵļ��㱾���ϸı������й��Ƶĸ��ʡ�����һ���̶�����ֵ����δ֪�Ŀ����Ժ�С������,OpenMax����SoftMax�ܾ���������롣ͼ2��ʾ��100��ʾ��ͼ��50��ѵ��ͼ���50�����ż�ͼ���Լ���ƭͼ���OpenMax��SoftMax�ĸ��ʡ��ǶԽ�����Խ��,OpenMax�ı�ĸ��ʾ�Խ���ڲ�ȷ���Եľܾ�����ֵѡ��,���ڱ���ѵ��ʾ���;ܾ����ż�ʾ��֮���ҵ�ƽ�⡣��ƭͼ��û��������ֵѡ��
��Ȼ�ⲻ�����ǵ�ʵ��������һ����,����ע��,OpenMaxҲͨ������Ƶĸ����ṩ��������ĵȼ��������,OpenMaxֱ��֧��һ�����ܾ���ǰ5�������ͬ����Ҫ����Ҫע��,���ڼ������v?i(x)������У,OpenMaxͨ�����������ͬ�ķ����ȼ�����
2.4 OpenMax���նȼ�С����
��Ȼ��ֵ���IJ�ȷ����ȷʵ�ṩ�˾ܾ�ijЩ���������,������û�б�֤���Ѿ���ʽ���������������Ŀ��ſռ���ա���������,�ڼ�����������,SoftMax������ǿռ䲻������ѵ���ռ丽��,��Ϊ�����������κ����Ӷ������������,ͬʱ������������ĸ��ʡ����������ij������,��ʹ������ά�ȵĴ�仯,��Ȼ��Ϊ�������ṩ��ļ���ֵ����Ȼ�����Ͽ��ܻ�˵������缤��ֵ������,��[14]�е���ƭͼ���������ŷ���֤��:SoftMax���ܹ������ſռ���ա�
����1(���ż��������):һ���ڼ���������ʹ��Ԫʶ�������չ(������Alg2��)��ͬʱSoftMax���ı�ΪOpenMax(�����ڹ�ʽ2)���������,�ṩһ�����ż�ʶ���ܡ�
֤��:Ԫʶ�����(��������CDF)��||��i?x||�ĵ�����������,���1?��i(x)�ǵ����ݼ��ġ����,���ǹ�������[21]��������Ľ��¼������ʵĻ���������OpenMax�任��Ԫʶ����ʵļ�Ȩ�����任,Ӧ��[1]�Ķ���1��2,�õ���:��δ֪��OpenMax����������ֵ�ܹ�������AV�����ռ��в����Ŀ��ſռ���ա����,����һ������ʶ������
����:
- Ԫʶ���ܹ�����һ��������i,�����ڹ���һ����������ڵ�i�����쳣ֵ�ĸ���,����Ҫ����һ����ֵ����һ�������Ƿ�Ӧ�ñ��ܾ���openmax��������Ԫʶ����ֵ��
- Alg2���һ�б���ģ����˫�ر���,�����־ܾ�����,����������Ϊδ֪��(index=0)����������С����ֵ�ʡ�
3 ʵ�����
���ǵ������ǻ���ImageNet���ģ�Ӿ�ʶ����(ILSVRC)2012�����ݼ�,����1K���Ӿ���𡣸����ݼ�������Լ130��(1.3M)������ѵ����ͼ��(ÿ������Լ��1K��1.3K��ͼ��),50K��ͼ��������֤,150K��ͼ�����ڲ��ԡ�����ILSVRC2012�IJ��Ա�ǩ������,������������������,���DZ���������֤����[11,14,23]�����ܡ�����ʹ����Caffe������[10]�ṩ��Ԥ��ѵ���õ�AlexNet(BVLCAlexNet)������������ݱ���,BVLCAlexNet��ILSVRC2012��֤���ϻ����Լ57.1%��ǰ��һ��ȷ�ʡ�ѡ��Ԥ��ѵ������BVLCAlexNet�Ǿ�����˼���ǵ�,��Ϊ���ǿ�Դ��,Ҳ�����ѧϰ��ʹ����㷺��������֮һ��
Ϊ��ȷ���ʵ��Ŀ��ż�����,����Ӧ����һ����������[21,1]�и����IJ���Э�顣�ڲ��Խ�,����ϵͳʹ����:ILSVRC2012��֤��������1000���������ƭ������ǰ��δ�����������ǰδ����������Ǵ�ILSVRC2010��ѡ���������˹���Ʒ�˹������[19]ָ��,2010��ILSVRC����Լ��360�����������,��û����2012��ILSVRC��ʹ�á�������360������ͼ����Ϊ���ż�ͼ��,����������δ֪�����
��ƭͼ��ͨ����������ȫ��ʶ��Ϊ���ڸ��������������籨�漸��ȷ�����������ض����������ʹ��Nguyen����[14]�ṩ���ɽ����㷨�������ؿռ��е��ݶ��������ɵ���ƭͼ�����յIJ��Լ���������ILSVRC2012��50K��ռ�ͼ��(ÿ�������50��ͼƬ),15K���ż�ͼ��(����ILSVRC2010��360����ͬ���)��15K��ƭͼ��(ÿ��ILSVRC2012������15��ͼ��)��
ѵ����:��Alg.1����,���ǿ��ǵ����ڶ���(ȫ���Ӳ�8,��FC8),���ڼ���ƽ����������(MAV)��ͨ��������������ܹ���ȷ�����ѵ��ʵ��������ÿ�����MAV�������ֱ����ÿ��crop/ͨ����MAV������ÿ����ȷ�����ѵ��ʵ�����ض����MAV֮��ľ���,�õ��ض���ľ���ֲ���������Щʵ��,����ʹ�õľ����DZ���ŷ����þ�������Ҿ���ļ�Ȩ��ϡ����������ʾ:ʹ�ô�ŷ����ú����������õ��Ľ��,����������ơ�����Щ�����Ϲ������������ֲ��IJ�����������̶�ILSVRC2012�е�1000�����ظ�������̡���һ��С�ı������ݵIJ������ƽ�,�����������ֲ�������β���ߴ�ľ�ȷ���ȡ���������ظ����,�Ի��һ�������β�ʹ�СΪ20��
���Խ�:�ڲ����ڼ�,ÿ������ͼ������Alg2�����۵�OpenMax����У���̡�����������һ������ͼ���FC8���е�ֵ,�ò���ͼ����ÿ�����ÿ��ͨ����Ӧ��1000x10άֵ��ɡ�����ÿ�����е�ÿ��ͨ��,ʹ��ÿ�����MAV��ÿ�������������������������д�����Ƚϡ��ڲ��Թ�����,������MAV��صľ���,�����������OpenMax����ֵ,�����µ�δ֪��(��Alg2�ĵ�5�͵�6��).OpenMax������ÿ��ͨ������,ʹ��������ļ�������(Eq.2)����1001x10ά�ĸ������������ÿ����,10��ͨ����ƽ��ֵ�������ܵ�OpenMax���ʡ����,1001�����и�����������Ԥ����ࡣȻ��,�������ʷ����ڲ�ȷ������ֵ(��9��)�����������,����רע���ϸ�ĵ�1��Ԥ�⡣
����:ͨ�����ٴ���ķ���,���Լ������ռ�ϵͳ�Ķ�����������ڿ��ż�����,�����������������֪����ϵı��������������Ĵ���,�Լ���֪����δ֪���֮��Ĵ���������[25,20]�������������,����ʹ��f-measure���������ż������������ڿ��ż�ʶ�����,f�Cmeasure����ȷ��,��Ϊ��û�б�ture negative�����
��OpenMax/SoftMax����ֵ���ø�����ֵ,�������������ݼ��ϼ���TP��FP��FN������,ʹ����֤������ƭ���Ϳ��ż�(��ͼ3)��ϵͳ���в���ʱ,������TP����Ϊ��֤������ȷ����,������FPΪ��֤���Ĵ������,������FNΪ��ƭ���Ϳ��ż�����ͼ��ϵͳ�������Ϊ��֪�����ӡ�ͼ3��ʾ��OpenMax��SoftMax�ڲ�ͬ��ֵ�µ����ܡ�ʵ�����,�������OpenMax�����ڿ��ż�������ʼ�ջ�ø��ߵ�f-measure��
��1-vs-set�㷨�ıȽ�:���������ѧϰ�������Խ��µ�������ȱ�����õĻ���,���ǿ�����һ�����ż����ߵ�����ģ�͡����ǽ�1-vs-set���ż��㷨[20]Ӧ����FC8���ݡ�����ʹ��liblinear��1000�����ѵ������ѵ������SVM�����ǻ�ʹ��[1]�����õ�liblinear��չѵ����1-vs-set����,��1000�����ѵ�������Ͻ����˸��ơ�1-Vs-Set�㷨������f-measure��Ϊ0.407,Զ����OpenMax������0.595��
4 ����
�����Ѿ�����,�����ǵ�OpenMax�ܹ���,���ǿ����Զ��ܾ�����δ֪�Ŀ��ż�����ƭͼ��,�Լ��ܾ�һЩ�Կ��Ե�ͼ��,������ʵ�ķ�����ֻ���ʶȵ�Ӱ�졣��ʹ��Ԫʶ��ʱ,һ�����Ե������ǡ�������δ������ܾ�������?����Ȼ������ɲ���ϵͳ���ʦ������,�����ж��ֿ����ԡ�**OpenMax������Ϊһ���ڿ�������ʶ��[1]�ij����е���ӱ�����,֮����������ݴ��ǩȻ��ϵͳ����ѧϰ�µ���𡣻���������Ϊһ����־����������ģʽ[24,7]��**����,���ǻ�����Ӧ�ü�ͼ��������(���˹ģ����ƽ����)��������,�������ܻᵼ�´�����ࡣ������1��,OpenMax�ܾ�������������ͼƬ,�����������ĸ�˹ģ��,ͼ�����´�������0.79�ĸ��ʱ�����Ϊ��ͷ�衣
����ʹ�÷Dz������ݽ��в�������,Ϊ�˼�����,����ֻ��ʾ��SoftMax��OpenMax�湲���IJ�ȷ������ֵ�����ܱ仯�����������ʾ�˸���Χ��OpenMax�����ı仯����δ���Ĺ�����,���������ܾ������ӿ��ܻ�ͨ������AVģ�͵ı�����������,����ÿ������ж��MAVs����������������õز�ͬһ����IJ�ͬ������,����,�����ϵİ����в�ͬ��������,���,��AV�п����в�ͬ�ġ���ء����,������Ͷ��Ͷ����
��Ȥ����,���ǹ۲쵽OpenMax�ܾ����̾���ʶ��/�ܾ���������������ImageNetͼ��,�ر����ж�������ͼ�����Ƶ�,����Զ��ѵ�����ݵ������ڳ�����Ҳ�ж���������,OpenMax�ܾ���������;�����ǸĽ�ѵ������,�������������õĶ�λ����[30,15]�����е�һ��������ͼ5��ʾ��