Bidirectional Learning for Domain Adaptation of Semantic Segmentation����ָ�������Ӧ��˫��ѧϰ
0.ժҪ
����ͼ��ָ����������Ӧ�Ƿdz���Ҫ��,��Ϊ�����ؼ���ǩ�ֶ���Ǵ������ݼ��Ȱ����ֺ�ʱ�����е���������Ӧ����Ҫô���������ݼ��Ϲ���,Ҫô���мලѧϰ������ܲ��ѡ��ڱ�����,���������һ���µ�˫��ѧϰ���,������������Ӧ�ָͨ��˫��ѧϰ,ͼ����ģ�ͺͷָ���Ӧģ�Ϳ��Խ���ѧϰ����ٽ�������,���ǻ������һ���Լලѧϰ�㷨��ѧϰ���õķָ���Ӧģ��,�Ӷ��Ľ�ͼ����ģ�͡�ʵ�����,���ǵķ����ڷָ����������Ӧ��������еķ����кܴ�����ơ�
1.����
ͼ������ָ�����½�չ[18]�����ڴ������ݼ���ѵ��������������ƶ��ġ����ҵ���,������Ҫ��������,�ռ����ֶ�ע�;����ܼ����ؼ���ǩ�Ĵ������ݼ��ijɱ��dz��ߡ������ͼ��ѧ�����½�չʹ���ھ��м��������ע�͵���ʵ��Ƭ�ϳ�ͼ����ѵ��CNN��Ϊ����[27,28]���������,��ʵͼ��(Ŀ��)�ͺϳ�����(Դ)֮�����ƥ��������ģ�͵����ܡ�������Ӧ����������ת�����⡣������˵,���ǹ�ע���������Ӳ����,��Ŀ������û�п��õı�ǩ�����༼��ͨ������Ϊ�ල������Ӧ��
��ͳ��������Ӧ������Ҫ��С��Դ�ֲ���Ŀ��ֲ�֮��ľ��롣���ֳ��õĶ�����һ�غͶ���[2],�Լ�ʹ�öԿ��Է���ѧϰ�������[34,35]�������ַ����ڷ��������϶�ȡ���˺ܺõijɹ�(����,MNIST[16]��USPS[7]��SVHN[22]);Ȼ��,����[37]��ָ����,����������ָ������ϵ������൱����
������,����ָ���������Ӧ�����Ѿ�ȡ���˺ܴ��չ,��������ָ�ַ�Ϊ���������IJ��衣������ʹ��ͼ��ͼ��ת��ģ��(����CycleGAN[38])��ͼ���Դ��ת����Ŀ����,Ȼ���ڷָ�ģ�͵�����������һ��������,�Խ�һ����С����[12,36]����ǰһ����С����ʱ,��һ������ѧϰ,���Խ�һ��������ƫ�ơ����ҵ���,�ָ�ģ�ͷdz�������ͼ��ͼ��ת����������һ��ͼ��ͼ��ķ���ʧ��,�ڽ������Ľ��о����ֲ���
���������һ���µ�ͼ������ָ���������Ӧ˫��ѧϰ��ܡ���ϵͳ��������������ģ��:ͼ��ͼ��ķ���ģ�ͺ�������[12,36]�ķָ���Ӧģ��,��ѧϰ�����漰��������(�������뵽�ָ�͡��ָ���롱)������ϵͳ�γ�һ���ջ�ѧϰ��������ģʽ����������ٽ�,��������������С�����,���������ģ���е�һ������һ��ģ���ṩ���������dzɹ��Ĺؼ���
������(����translation-to - segmentation��,������[12,36])������,���������һ���Լලѧϰ(self-supervised learning, SSL)������ѵ�����ǵ�segmentation adaptive model��������ʵ������ѵ���ķָ�ģ�Ͳ�ͬ,�ָ�����Ӧģ�����ںϳ����ݼ�����ʵ���ݼ���ѵ����,����ʵ����û�б�ע�����κ�ʱ��,���Ƕ����Խ�����ʵ���ݾ��и����Ŷȵ�Ԥ���ǩ��Ϊground truth��ǩ�Ľ���ֵ,Ȼ��ֻʹ�����������·ָ�����Ӧģ��,�������ŶȽϵ͵�Ԥ���ǩ�ų���������̱���Ϊ���Ҽලѧϰ,������������������,�������з����й㷺ʹ�õ�һ�γ���ѧϰ���á�����,���õķָ�����Ӧģ�ͽ�����������ͨ������ѧϰ���õع�������ģ�͡�
�ڷ�������(����segmentation-totranslation��),���ǵ�ƽ��ģ�ͻ�ͨ��segmentation adaptiveģ�ͽ��е����Ľ�,����[12,36]��ѵ��ģ�ͺ�,ͼ��ͼ���ƽ�Ʋ�����²�ͬ��Ϊ��,���������һ���µĸ�֪��ʧ,ǿ��ͼ����ÿ�����ص����䷭��汾֮�������һ����,�Խ�������ģ����ָ�����Ӧģ��֮�������������ƽ��ģ�͵�Լ��,���Խ�һ����Сƽ�ƺ��ͼ������ʵ���ݼ�(Ŀ��)���Ӿ����(����ա���������)�ϵIJ�ࡣ���,���ǿ���ͨ������ѧϰ��һ���Ľ��ָ�ģ�͡�
����������������,ƽ��ģ�ͺͷָ�����Ӧģ�������,ʵ���˽����ģ��Ⱦͼ�����ݼ�SYNTHIA [28]/GTA5[27]���䵽��ʵͼ�����ݼ�cityscape[5]�ϵ���������,�����������������������,�÷��������ڲ�ͬ���͵ĹǸ���
��֮,���ǵ���Ҫ������:
- �����һ��˫������ָ�ѧϰϵͳ,��ϵͳ��һ���ջ�,�ɽ���ѧϰ�ָ�����Ӧģ�ͺ�ͼ����ģ�͡�
- ���������һ�ַָ�����Ӧģ�͵��Լලѧϰ�㷨,���㷨���ڷ�����,����������������Դ���Ŀ����
- ������ͼ��-ͼ��ת����������һ���µĸ�֪��ʧ,ͨ�����µķָ�����Ӧģ�����ලͼ���ת����
2.��ع���
������Ӧ
�ڽ�֪ʶ������ͼ��ת�Ƶ���ʵ��Ƭ�Ĺ�����,��������ִ�ѵ�������Խδ���һ������������������Ӧ��ּ�ھ������ֲ�ƥ��,���ڲ���[24]ʱ��ģ�͵���Ϊ���õķ��������е���������Ӧ�о���Ҫ������ͼ�����[30]�ϡ������о���Ŀ����ͨ����С����ֲ�������ѧϰ���ʾ�����ƽ������(MMD)��ʧ[8],�����ʾ��ƽ��ֵ,��������֮��Ĺ��������������ΪMMD����չ,һЩ�����ֲ���ͳ�������ֵ��Э����[2,21]������ƥ��������ͬ�����ҵ���,���ֲ����Ǹ�˹�ֲ�ʱ,��ƥ���ֵ��Э������Ժܺõض���������ͬ����
�Կ�ѧϰ[9]�ǽ��������е�һ����������Ӧ��������ͨ��ǿ�����Բ�ͬ�����������ƭ��������������Ư�ơ�[34]�Ǹ÷������ȷ�,����������ĸ������Ļ����������˶Կ���ʧ��Դ���ݼ��ķ�����ʧ,ȡ���˱�ͳ��ƥ�䷽�����õ����ܡ����˶Կ������,һЩ�о��������һЩ�������ĺ�������һ����С���ƶ�,���ÿ����[4]����Ȩ����,�Լ��Է���ƥ��[35]�Ľ������ʾ��������Щ�����������ڼ�С�͵ķ������ݼ�(��MNIST[16]��SVHN[22]),�ڸ�����ս�Ե�����(��ָ�)�п������൱�������ܡ�
����ָ����������Ӧ
������,�������ָ�ģ������˸������������Ӧ����,��Ϊ�Դ���ͼ����б�ע��Ҫ�������Ͷ��ܼ�����,����Щ��������Ҫѵ�����������ķָ����硣�����������һ�����ܵĽ�����������Զ���ǵ�����������ѵ�����硣����,GTA5[27]��SYHTHIA[28]���������еij��нֵ��ϳ����ݼ�,���Ǿ����ص������,����ʵ���ݼ�����ͼ����(����,CITYSCAPE [5], CamVid[1])��������Ӧ�Կ�����������ϳ����ݼ���ʵ�����ݼ���
Ϊ����ָ�������������Ӧ�ĵ�һ��������[13],�����������������������ȫ�ֺ;ֲ����롣�γ�������Ӧ[37]���Ƴ����ص�ȫ�ֲַ��ͱ�ǩ,Ȼ��ѧϰ��ϸ���صķָ�ģ�͡���[33]��,�Բ�ͬ�IJ������ʹ�ö������������������졣��[31]��,�ֱ��ǰ����ͱ�������д���,�Լ�С��λ�ơ�������Щ������Ŀ�궼��ֱ�Ӷ���������֮������������ҵ���,�ϳ����ݺ���ʵ����֮����Ӿ�(����ۡ���ģ��)������ͨ��ʹ��������ѧϰ��ת�Ƶ�֪ʶ��
�ܽ���δ���ͼ��ͼ��ת������(��CycleGAN [38], UNIT [17], MUNIT[14])�Ľ�չ�ƶ�,�������ʵ���ݵ�ӳ�䱻��Ϊͼ��ϳ����⡣��ѵ���ָ�ģ��֮ǰ,������Ч�ؼ���������졣���ڷ�����,Cycada[12]��DCAN[36]��һ��������������������֮���������ͨ���ֱ����ѧϰ�е�����ת��,��Щ������������Ƚ������ܡ�Ȼ��,ͼ��ͼ��ת�������������������ܡ�һ��ʧ��,�������IJ����ʲôҲ�������ˡ�Ϊ�˽���������,����������һ��˫��ѧϰ���,����������,����ͷָ������Ӧģ�Ϳ�����һ���ջ�����ٽ���
����������صĹ�������[6]��,�ָ�ģ��Ҳ����������ͼ���ƽ��,��������ֻ����Դ�����Ͻ���ѵ��,���Բ���ʹԴ����ӦĿ����[39]�������һ����ѵ������,�Էָ�ģ�ͽ��е���ѵ����Ȼ��,�ָ�ģ��ֻ��Դ���ݽ���ѵ��,û��ʹ���κ�ͼ��ƽ�Ƽ�����
˫��ѧϰ
���༼�����类�����Ϊ�˽��������������,��[10,23],����������ԶԵ���������ѵ�����Է���ģ�͡��뵥��ѧϰ���,�÷��������ѧϰ����,�����˶Դ������ݵ�������˫��ѧϰ����Ҳ����չ��ͼ����������[25],�����ϵ��º��µ�����������ѵ����������ķ����ͼ����������������صĹ���[29]�����˫��ͼ��ƽ��(��Դ��Ŀ���Ŀ�굽Դ),Ȼ��ֱ�����������ѵ������������,����ںϷ������������ǵ�˫��ѧϰָ���Ƿ���ٽ��˷ָ�ı���,��֮��Ȼ���÷������ڴ�������ָ�����
3.����
����Դ���ݼ�S�зָ��ǩYS(������ͼ��ѧ���ɵĺϳ�����),��Ŀ�����ݼ�Tû�б�ǩ(����ʵ����),������ѵ��һ����������ָ������,�����Ŀ�����ݼ�T�Ͻ��в��ԡ����ǵ�Ŀ����ʹ�������ܾ����ܽӽ�Tѵ����ģ�͵õ�������ʵ��ǩYT���������ල��������Ӧ����ָ��һ��������,��ΪS��T֮����Ӿ�(������������������������)������ʹ���������һ����ѧϰ��ת��֪ʶ��
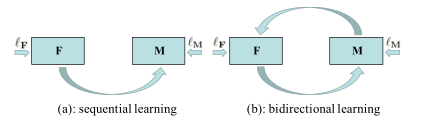
ͼ1:˳��ѧϰvs˫��ѧϰ
Ϊ�˽���������,����Ĺ���[12]��������������������һ����ͼ��ͼ���ƽ��������F,��ѧϰ��û�гɶ�ʾ��������½�ͼ���Sת����T����һ�����ָ�����Ӧ������M,�Է�����F(S)����ѵ��,������F(S)���к�S��ͬ�ı�ǩYS,Ŀ��ͼ��Tû�б�ǩ�������������ǰ�ͼ1(a)��ʾ��˳��ѧϰ�ġ����������ν�������������ŵ�:1)F��������С�Ӿ���IJ��;2)���������Сʱ,M������ѧϰ,���ܸ�����Ȼ��,�ý��������һЩ�����ԡ�һ��ѧϰF,���̶��ˡ�Mû�з��������F�ļ�Ч,���Ҷ�M��˵,һ�γ���ѧϰ�ƺ�ֻѧϰ�����Ŀ�ת��֪ʶ��
�ڱ�����,���������һ���µ�ѧϰ���,���Ժܺõؽ�������������⡣���Ǽ̳��˷���������ķ�ʽ,��������˫��ѧϰ(3.1��),˫��ѧϰʹ�ñջ���������F��M������,����������һ�����Ҽලѧϰ,����M��ѵ�������Ҽ���(3.2��)������ṹ����ĺ����ڵ�3.3���н��ܡ�
3.1.˫��ѧϰ
���ǵ�ѧϰ��ͼ1(b)��ʾ������������ɡ�
����(��F��M)������֮ǰ��˳��ѧϰ[12]����Ϊ��������������T��S��ͼ��ѵ��ͼ��ͼ�������ģ��F,Ȼ��õ�������S��= F(S)��ע��F����ı�S���ı�ǩ,���YS (S�ı�ǩ)��һ����,������,������S����YS��Tѵ���ָ���Ӧģ��M��ѧϰM����ʧ�������Զ���Ϊ:

����ladvΪ�Կ���ʧ,ʹS����������ʾ��T��������ʾ(��S��, T����M��õ�)֮��ľ��뾡����С��lseg������������ָ����ʧ������ֻ��S���б�ǩ,��������ֻ�Է�����Դͼ��S�����о���������
������(��M��F)�������ġ�������ʹ�ø��µ�M������F����[35,14]��,��ͼ����������ʹ����һ����֪��ʧ,�������˴�һ��Ԥ��ѵ���������л�õ�����������ʶ���ϵľ���,�����ƽ�ƽ����������������,����ʹ��M����������������֪����ʧ����GAN��ʧ��ͼ���ؽ���ʧ���,ѧϰF����ʧ�������Զ���Ϊ:
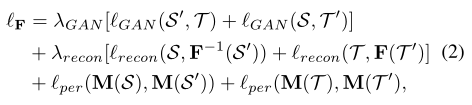
����,�ԳƼ���S��T��T��S�������,�Ա�֤ͼ��ͼ���ƽ��һ����GAN��ʧlGAN��S����T֮��ִ���������Ƶķֲ���T�� = F?1 (T),����F?1��F�ķ�����,����ͼ���Tӳ�䵽S����ͼ���S��ת����Sʱ,lrecon�����ؽ���lper�����ǽ��鱣��S��S��֮���T��T��֮������һ���Եĸ�֪��ʧ��Ҳ����˵,һ�����ǻ����һ������ķָ���Ӧģ��M,������S��S��,����T��T����Ӧ������ͬ�ı�ǩ,��ʹS��S��֮��,����T��T��֮������Ӿ���϶��
- GAN:ϣ��S����T��T����S֮��������Ƶķֲ�
- Reconstruction:ϣ��S��F(S)=S����F?1(S��)= (F?1 (F(S))=S,T��F(T)=T����F?1(T��)= (F?1 (F(T))=T��Ҳ����˵ϣ�������ȥ�ٷ������,���ݱ���һ��
- Perception:ϣ��S��S����T��T��,�ھ���M����������ȡ֮��,�������Ƶ�����,��ͬ�ı�ǩ
3.2. ���Ҽලѧϰ���M
��ǰ������(��F�� M) ���Դ��S��Ŀ����T���б�ǩ,��ȫ�ල�ָ���ʧlsegʼ���Ǽ������������ѡ�������ǵ�������,Ŀ�����ݼ��ı�ǩ��ʧ�ˡ�����������֪,�Լලѧϰ(SSL)��ǰ�Ѿ������ڰ�ලѧϰ,�����ǵ����ݼ��ı�ǩ�����������ʱ��������,����ʹ��SSL�������ƹ�ָ���Ӧģ��M��
����T��Ԥ�����,���ǿ��Ի��һЩ�����Ŷȵ�α��ǩ��һ����������α��ǩ,��Ӧ�����ؿ��Ը��ݷָ���ʧֱ����S���롣���,���ǽ�����ѧϰM(����ʽ1)������ʧ������Ϊ:
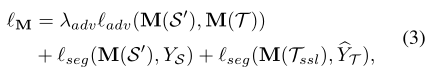
����Tssl?T��Ŀ�����ݼ����Ӽ�,�������ؾ���α��ǩY��T��һ��ʼ�����ǿյġ���ʵ���˽Ϻõķָ�����Ӧģ��Mʱ,���ǿ���ʹ��M��Ԥ��T���߶����ŵı�ǩ,�Ӷ�����Tssl�Ĵ�С����������Ĺ���[39]Ҳʹ��SSL���зָ���Ӧ�����֮��,�����ǵĹ�����ʹ�õ�SSL��Կ�ѧϰ����,����Ը��õع����ڷָ���Ӧģ�͡�
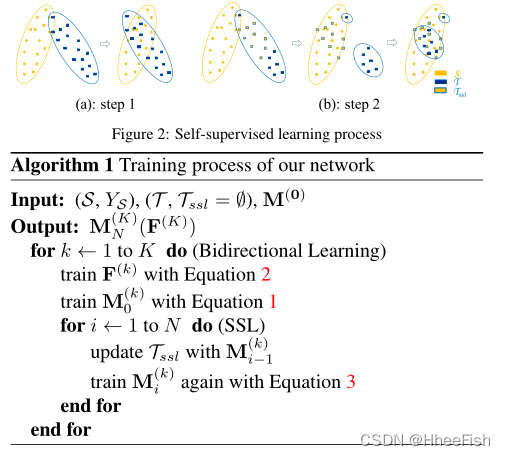
����ʹ��ͼʾ(��ͼ2��ʾ)������������̵�ԭ���������ǵ�һ��ѧϰ�ָ���Ӧģ��ʱ,TsslΪ��,S��T֮��������϶���Լ�С,����繫ʽ1��ʾ�����������ͼ2 (a)��ʾ��Ȼ��������Ŀ����T��ѡȡ��S�ܺö���ĵ��������Ӽ�Tssl���ڵڶ�����,���ǿ��Ժ����ؽ�Tssl�Ƶ�S,������α��ǩ�ṩ�ķָ���ʧʹ���DZ��ֶ��������������ͼ2 (b)�м���ʾ�����,T����Ҫ��S����������������ˡ������ܼ���ʣ�������ת�Ƶ�����1һ��,��ͼ2 (b)���ұߡ�ֵ��ע�����,SSL�������Կ�ѧϰ����,�öԿ�ѧϰ��ע���������û����ȫ�����ÿһ��,��Ϊladv���ѽ�����S��Tssl�����ݸı�ֱ������
3.3.����ܹ�����ʧ����
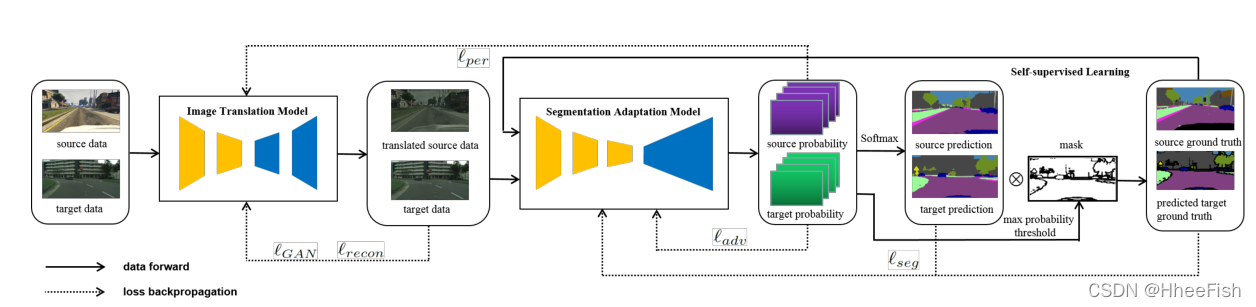
ͼ3:����ģ�ͺ���ʧ����
����һ����,���ǽ���������Ľṹ(��ͼ3��ʾ),��ʧ������ϸ�ں�ѵ������(��ͼ�㷨1��ʾ)��������Ҫ��ͼ����ģ�ͺͷָ�����Ӧģ����������ɡ�
��ѧϰƽ��ģ�͵Ĺ�����,���Խ�lGAN��lrecon(��ͼ3�ͷ���2��ʾ)����Ϊ:
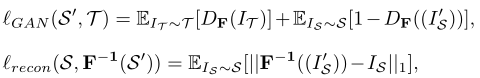
����IS��IT������Դ���ݼ���Ŀ�����ݼ�������ͼ��I��S��F.�����ľ��������ͼ��,DF��Ϊ�˼�СIT��I��S֮��IJ�������ӵ��������������ع���ʧ,��F?1��F���溯��ʱ,ʹ��L1����������IS��F?1(I��S)֮���ѭ��һ��������������ֻ������һ��������������,lGAN(S, T��),lrecon(T, F(T��))�Ķ������ơ�
��ͼ3��ʾ,֪����ʧlper�����˷���ģ�ͺͷָ���Ӧģ����������ѧϰ����ģ�͵���֪��ʧʱ,���˱���IS���䷭����I��S֮�������һ������,���ǻ���������һ���Ԧ�per_recon��Ȩ����,�Ա���IS�����Ӧ���ع�F?1(I��S)֮�������һ�����������µ���,ƽ��ģ�����ȶ�,�������ع����֡�lper������Ϊ:
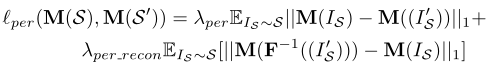
���ڶԳ���,lper(M(T), M(T��))(��ʽ2��ʾ)Ҳ���������Ƶķ������塣
��ѵ���ֶ���Ӧģ��ʱ,����Ҫʹ��ladv���жԿ���ѧϰ,ʹ��lseg�������Ҽලѧϰ(���ʽ3��ʾ)�����ڶԿ���ѧϰ,����������һ��������DM,�Լ���ͼ3��ʾ��Դ���ʺ�Ŀ�����֮��IJ��졣ladv���Զ���Ϊ:
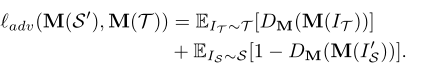
�ָ���ʧ��lsegʹ�ý�������ʧ������Դͼ��,seg���Զ���Ϊ:
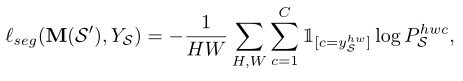
����,YS��Is�ı�ǩӳ��,C������,H��W���������ӳ��ĸ߶ȺͿ��ȡ�PS�Ƿָ���Ӧģ�͵�Դ����,���Զ���ΪPS=M(I��S)������Ŀ��ͼ��,������Ҫ�������Ϊ��ѡ��α��ǩӳ��y��T������ѡ��ʹ��һ�����dz�֮Ϊ**����������ֵ(MPT)���ij��÷��������˾��и�Ԥ�����Ŷȵ�����**�����,���ǿ��Խ�y��T����Ϊy��T=argmax M(IT),��y��T������ӳ�䶨��ΪmT=1 [argmax M(IT)>threshold]�����,���ķָ���ʧ���Ա�ʾΪ:
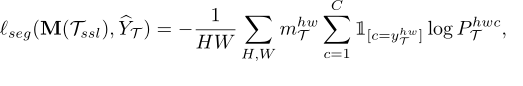
ʽ��,PT��M��Ŀ�������
�������㷨1�н�����ѵ�����̡���ѵ���̰�������ѭ�������Ҫ��ͨ��ǰ��ͺ���ѧϰ����ģ�ͺͷֶ���Ӧģ�͡��ڲ�ѭ����Ҫ����ʵ��SSL����������һ����,���ǽ��������ѡ��ѧϰF,M�ĵ�������,�Լ���ι���SSL��MPT��

4.����
Ϊ���˽�˫��ѧϰ�����Ҽලѧϰ�����M����Ч��,���ǽ�����һЩ�о�������ʹ��GTA5[27]��ΪԴ���ݼ�,���о���[5]��ΪĿ�����ݼ�������ģ��ΪCycleGAN[38],�ָ���Ӧģ��ΪDeepLab V2[3],����ΪResNet101[11]����������ʵ���ʹ����ͬ��ģ��,�������й涨��
������,���������ṩ���������о��ͱ�����ʹ�õķ���˵����M(0)������˫��ѧϰ����ʼģ��,��ʹ��Դ���ݽ���ѵ����M(1)ʹ��Դ���ݺ�Ŀ�����ݽ��жԿ���ѧϰ������M(0)(F(1)),ʹ�÷���ģ��F(1)����Դ����,Ȼ����ڷ�����Դ����ѧϰ�ָ�ģ��M(0)������k=1,2��i=0,1,2,M(k)i(F(k))��ʾ�㷨1����ĵ�k�ε������ڻ��ĵ�i�ε�����ģ����

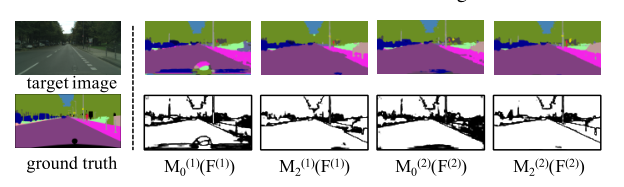
ͼ4:˫��ѧϰ��ÿһ���ķָ���
4.1. ��SSL��˫��ѧϰ
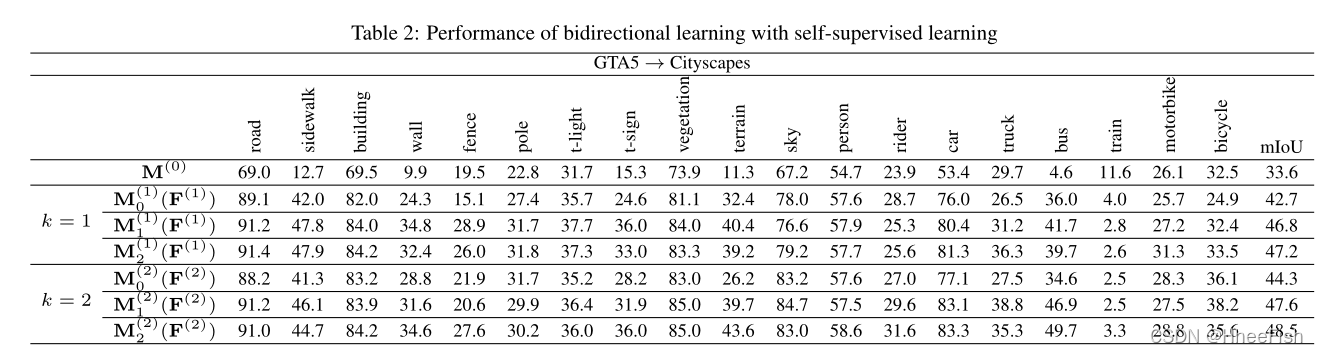
����չʾ����û��SSL��˫��ѧϰϵͳ��ѵ����ģ�͵õ��Ľ�����ڱ�1��,M(0)�����ǵĻ���ģ��,��������mIoU�����ޡ����Ƿ���ģ��M(1)��M(0)(F(1))����������,���߶���M(0)�����7%����,M(1)(F(1))��һ�������Լ1.6%������ζ�ŷָ���Ӧģ�ͺͷ���ģ�Ϳ��Զ�������,�����ǽ����һ��ʱ,��������˫��ѧϰ��һ������,���ǿ�������䡣���ǽ�һ��֤��,ͨ������ѵ��˫��ѧϰϵͳ,�����������,��M(1)(F(1))����M(0)��Ϊ�����,��ģ��M(2)0(F(2))�����ṩ���õ����ܡ�
4.2. ʹ��SSL����˫��ѧϰ
�ڱ�����,���ǽ�չʾSSL��ν�һ����߷ֶ�����Ӧģ�͵�����,��������Ӱ��˫��ѧϰ���̡��ڱ�2��,����չʾ�˻����㷨1�����ε���(k=1,2)�����Ľ������ͼ4��,����չʾ�˷ָ���������������ֵ(MPT)��������Ӧ��ģͼ,����ֵΪ0.9����ͼ4��,��ɫ������Ԥ�����Ŷȸ���MPT������,��ɫ�����ǵ����Ŷ�����
��k=1ʱ,��ʹ��SSL��ģ��M(1)0(F(1))����ΪM(1)2(F(1))ʱ,mIoU�������4.5%�����ǿ��Է���,����ÿ�����,��IoU����50ʱ,���Դ�M(1)0(F(1))��M(1)2(F(1))�õ��ܴ�ĸĽ���������֤������֮ǰ�ڵ�3.2���еķ���,��ʹ��SSL���Ա�������Դ���Ŀ����Ķ�������,���ҿ���ͨ���Կ���ѧϰ���̽�һ�������������ݡ�
��k=2ʱ,����������M(1)2(F(1))�滻M(0)����ʼ���ķ�����û��SSL�������,mIoUΪ44.3,���1��ʾ�Ľ�����,����һ������ĸĽ��������Խ�һ��֤�������ڵ�4.1���й��ڷֶ���Ӧģ������������������Ҫ���õ����ۡ�����,���ǿ��Դӱ�2�з���,�����ڵڶ��ε�����ʼʱ,mIoU��47.2�½���44.3,��������SSLʱ,mIoU����������48.5 ,��ȵ�һ�ε����Ľ��Ҫ�á���ͼ4��ʾ�ķָ������Խ�һ��֤ʵ���ǵķ���,����Ҫ����,����������߷ָ�����,�ָ�����Ӧģ�Ϳ����ṩ���ɿ���Ԥ��,�����ͨ��������ģͼ�еİ�ɫ�������۲졣���������ж���ʹ������ӳ��Ϊ�㷨1�е�SSL����ѡ����ֵ�͵���������
4.3. ������ѧϰ
���ǽ�����������㷨1��ѡ����ֵ�Ը����Ŷȹ�������,�Լ���������N��
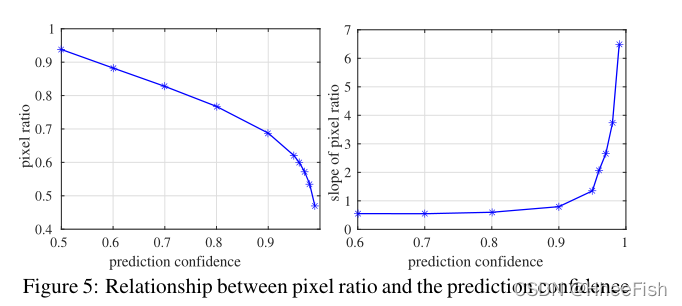
������ѡ����ֵʱ,���DZ���������֮�䱣��ƽ�⡣һ����,����ϣ��Ԥ��ı�ǩ���о����ܶ�ĸ����Ŷ�(��ͼ4����ʾΪ��ɫ����)����һ����,����ϣ���������ڴ����Ԥ����������������,����ֵӦ�����ܸߡ�������ͼ5�����չʾ��Ԥ�����Ŷ�(M��ÿ���ص����������)��ѡ�����غ���������֮��ı���(��ͼ4����ʾ�����а�ɫ����İٷֱ�)֮��Ĺ�ϵ,Ȼ����ͼ5���Ҳ�չʾ��б�ʡ����ǿ��Է���,��Ԥ�����Ŷȴ�0.5���ӵ�0.9ʱ,���ʼ����������½�,б�ʼ������ֲ��䡣����0.9��0.99,�����½��ø��졣���ݹ۲���,����ѡ��յ�0.9��Ϊ��ֵ,��Ϊ��ѡ��ǩ����������֮���Ȩ��
Ϊ�˽�һ��֤�����ǵ�ѡ��,�ڱ�3��,����չʾ�˵��㷨1�е�K=1��N=1ʱ,ʹ�ò�ͬ��ֵ��MKN�����Լලѧϰ�ķָ�������Ϊ��һ��ѡ��,����Ҳ��������ֵ������Ӳ��ֵ,��ÿ�����ر����������ʼ�Ȩ��������������һ����ʾ��������еĽ����֤ʵ�����ǵķ���������ֵ����0.9ʱ,δ������Ԥ���ΪӰ��SSL���ܵĹؼ����⡣�����ǽ���ֵ���ӵ�0.95ʱ,SSL���̶Կ���ʹ�õ������������С�������ʹ������ֵʱ,������㡣���������Ϊ�漰�������ı�ǩ����,���Ҳ���ͨ��Ϊ������ǩ����ϵ͵�Ȩ�����ܺõؼ����Ӱ�졣���,�ڽ�������ʵ����,0.9�ƺ���һ���ܺõ���ֵѡ��
���ڵ�������N,����Ҳ����Ԥ��ı�ǩѡ���ʵ���ֵ����N����ʱ,�ֶ���Ӧģ�ͱ�ø�ǿ,���¸����ǩ����SSL��һ��SSL�����ر�ֹͣ����,����ζ�ŷָ�����Ӧģ�͵�ѧϰ����,����û�и��ơ����ǿ϶�������K��ֵ����ʼ��һ���������ڱ�4��,����չʾ�˵���������N��ֵʱ,����0.9��һЩ�ָ��������ǿ��Է���,����N������,mIoU��ø��á���N=2��3ʱ,mIoU����ֹͣ����,���ر��ʱ��ֲ��䡣����ܱ���N=2��һ��������ѡ��,�����ڹ�����ʹ������
5.ʵ��
�ڱ�����,���ǽ��Ƚ����ǵķ��������Ƚ��ķ���֮���õĽ����
5.1.����ܹ�
�����ǵ�ʵ����,����ѡ��ʹ�ô���ResNet101[11]��DeepLab V2[3]�ʹ���VGG16[32]��FCN-8s[18]��Ϊ�ָ�ģ�͡�����ͨ��ImageNetԤ��ѵ����������г�ʼ��[15]������Ϊ�ֶ�����Ӧģ��ѡ��ļ�����������[26],����5��������,�ں�Ϊ4��4,ͨ����Ϊ{64��128��256��512��1},����Ϊ2�����ڳ����һ��֮���ÿ��������,�����Dz�����Ϊ0.2��й©ReLU[20]������ͼ����ģ��,������ѭCycleGAN[38]����ϵ�ṹ,����9����,�����ӷָ���Ӧģ����Ϊ��֪��ʧ��
5.2.ѵ��
��ѵ��CycleGAN[38]ʱ,ͼ������ü�Ϊ452��452�Ĵ�С,��ѵ��20��ʱ��������ǰ10����,ѧϰ��Ϊ0.0002,10���κ������½���0�������ڷ���3�����æ�GAN=1,��recon=10,�����æ�per=0.1,��~per recon~=10,���ڸ�֪��ʧ����ѵ���ָ�����Ӧģ��ʱ,ͼ��ij��ߵ���Ϊ1024,���ұ������ֲ��䡣DeepLab V2[3]��FCN-8s[18]ʹ���˲�ͬ�IJ��������ڴ���ResNet 101��DeepLab V2,����ʹ��SGD��Ϊ�Ż�������ʼѧϰ��Ϊ2.5��10?4,���š�poly��ѧϰ�����ߵ�ʵʩ������,����Ϊ0.9�����ڴ���VGG16��FCN-8s,����ʹ��Adam��Ϊ�Ż���,����Ϊ0.9��0.99����ʼѧϰ��Ϊ1��10?5,�����Ų���Ϊ5000�Ҧ�=0.1�ġ�������ѧϰ�ʲ��Զ����͡�����DeepLab V2��FCN-8s,����ʹ�õļ�������Adam optimizerѵ���ļ�������ͬ,��ʼѧϰ��Ϊ1��10?4������DeepLab V2��1��10?6������FCN-8s����������Ϊ0.9��0.99�����ڷ���ʽ1,����ΪResNet101���æ�adv=0.001��ΪFCN-8s���æ�adv=1��10?4��
5.3.���ݼ�
��������֮ǰ�ᵽ��,�����ϳ����ݼ�����GTA5[27]��SYNTHIA[28]������Դ���ݼ�,���о���[5]������Ŀ�����ݼ�������GTA5[27],������24966�ŷֱ���Ϊ1914��1052��ͼ��,����ʹ��GTA5��Cityscapes���ݼ�֮���19��������𡣶���SYNTHIA[28],����ʹ��SYNTHIA-RAND-CITYSCAPES����,���а���9400�ŷֱ���Ϊ1280��760��ͼ��,�Լ�16�ֳ����ij��о������[5]�����ڳ��о���[5],������Ϊѵ��������֤���Ͳ��Լ�����ѵ��������2975���ֱ���Ϊ2048��1024��ͼ�����ǽ���ѵ��������Ŀ�����ݼ������ڲ��Լ��ĵ�����ֵ��ǩȱʧ,���DZ���ʹ�ð���500��ͼ�����֤����Ϊ����ʵ���еIJ��Լ���
5.4.�����¼����ıȽ�
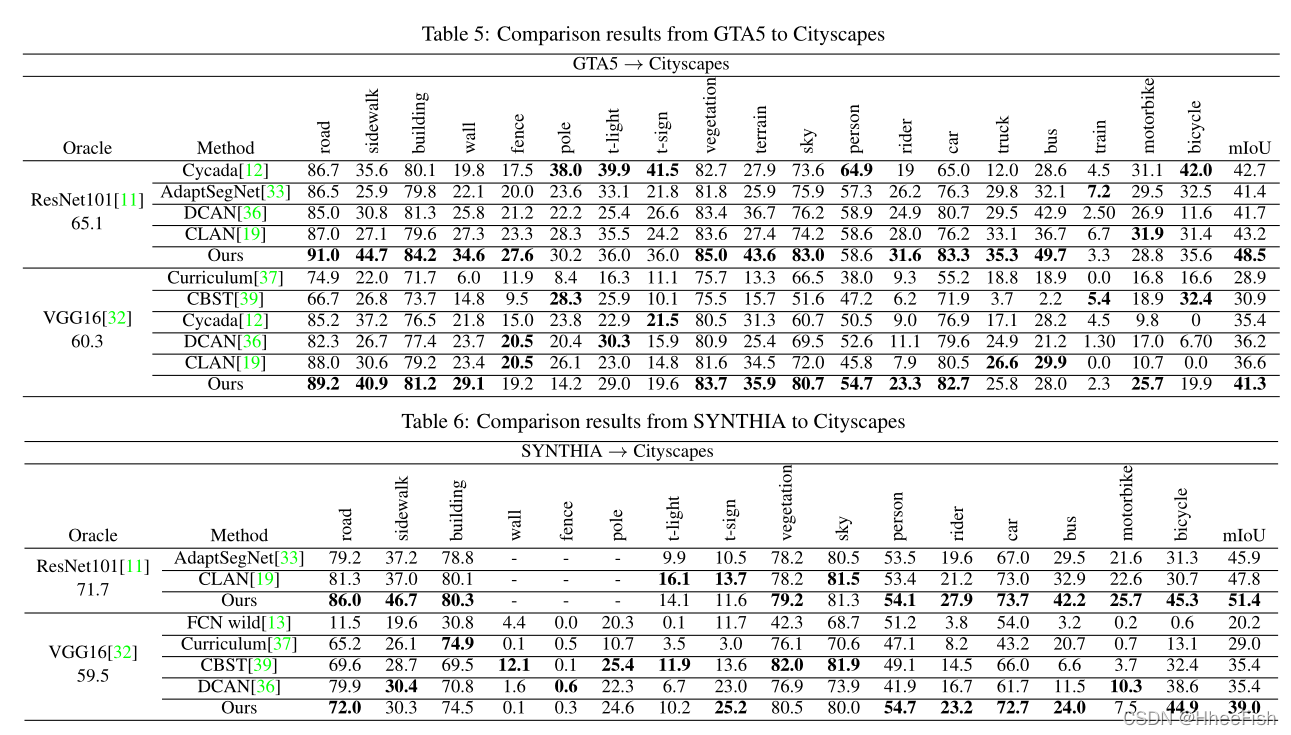
���ǽ����ǵķ��������Ƚ��ķ�����������ͬ����������(�ֱ���ResNet101��VGG16)�ϵĽ�������˱Ƚϡ����������������Ͻ��бȽ�:��GTA5�����о��ۡ��͡�SYNTHIA�����о��ۡ����ڱ�5��,������ResNet101��VGG16չʾ������GTA5�����о��ۡ�����Ӧ��������ǿ��Թ۲쵽����������������Ӧ�����е�����,��ResNet101��VGG16��ø��õĽ������[37,33,19]��,������Ҫ��ע���в�ͬ�Կ���ʧ���ܵ����������롣�������ڹ��ܲ����Ϲ����Dz�����,����������õĽ��[36]��Ȼ�����ǵĽ����5%���ҡ�Cycada[12](����ʹ��ResNet101���������ǵĴ���)��DCAN[36]ʹ�÷���ģ�ͺͷֶ���Ӧģ�ͽ�һ����С���Ӿ�����IJ��,���߶�ʵ���˷dz����Ƶ����ܡ���Cycada[12]���,����ʹ�������Ƶ���ʧ����,��ͨ��һ���µ�˫��ѧϰ����,����ʵ��6%�ĸĽ���CBST[39]�����һ����ѵ������,�����ÿռ�������Ϣ��һ����������ܡ�Ϊ�˹�ƽ�Ƚ�,����չʾ��ֻʹ������ѵ���Ľ����ʹ��VGG16,���ǿ��Ի��10.4%�ĸ��ơ����,���ǿ��Է���,û��˫��ѧϰ,����ѵ���ķ����Dz�����,��ʵ�����õı��֡�
�ڱ�6��,����չʾ�����ResNet101��VGG16�ġ�SYNTHIA�����о��ۡ��������Ӧ�����SYNTHIA��Cityscapes֮���������Զ����GTA5��Cityscapes֮��IJ��,�������ǵ����û����ȫ�ص�������ΪResNet101ѡ��Ļ��߽��[33,19]��ʹ��13�����,���ǻ��г���13�����Ľ��,�Խ��й�ƽ�Ƚϡ����ǿ��Դӱ�6�з���,���������������,���о��۵���Ӧ����ȱ�5�еĽ����öࡣ����,��·���������е����͡����������������Ҫ��10%���ϡ�����Ԥ�����ŶȽϵ�,������⽫��SSL��������Ӱ�졣��������Ȼ���Ա�[37,39,36,33]�����Ĵ��������������ٺ�4%��
5.5.���ܲ��ﵽ����
����ʹ�ô��е�����ֵ��ǩ��Ŀ�����ݼ���ѵ���ָ�ģ��,��ģ��������ʹ�õ�������ͬ,�Ի���Ͻ���������19�����ġ�GTA5�����о��ۡ�,ResNet101��VGG16�����ֱ�Ϊ65.1��60.3�����ڡ�SYNTHIA to Cityscapes��,ResNet101��13�����,VGG16��16�����,���ֱ�Ϊ71.7��59.5���������ǵķ���,��Ȼ���ܲ������Ϊ16.6,���������������,�����������͡�Ȼ��,����ζ�����кܴ�ĸĽ��ռ䡣���ǰ��������Ժ�Ĺ����С�
6.����
�ڱ�����,���������һ�ֻ����Լලѧϰ��˫��ѧϰ����������ָ�����Ӧ���⡣����ͨ��������ʵ�����,��ģ�ͽ���˫��ѵ��ʱ,���������ʵ���ݼ��ķָ�����,���ڲ�ͬ����Ķ�������дﵽ���Ƚ��Ľ����
�����
[1] G. J. Brostow, J. Shotton, J. Fauqueur, and R. Cipolla. Segmentation and recognition using structure from motion point clouds. In ECCV (1), pages 44�C57, 2008. 2
[2] F. M. Carlucci, L. Porzi, B. Caputo, E. Ricci, and S. R. Bul��. Autodial: Automatic domain alignment layers. In ICCV, pages 5077�C5085, 2017. 1, 2
[3] L.-C. Chen, G. Papandreou, I. Kokkinos, K. Murphy, and A. L. Y uille. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE transactions on pattern analysis and machine intelligence, 40(4):834�C848, 2018. 5, 7
[4] Q. Chen, Y . Liu, Z. Wang, I. Wassell, and K. Chetty. Reweighted adversarial adaptation network for unsupervised domain adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 7976�C 7985, 2018. 2
[5] M. Cordts, M. Omran, S. Ramos, T. Rehfeld, M. Enzweiler, R. Benenson, U. Franke, S. Roth, and B. Schiele. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3213�C3223, 2016. 2, 5, 7
[6] A. Dundar, M.-Y . Liu, T.-C. Wang, J. Zedlewski, and J. Kautz. Domain stylization: A strong, simple baseline for synthetic to real image domain adaptation. arXiv preprint arXiv:1807.09384, 2018. 3
[7] J. Friedman, T. Hastie, and R. Tibshirani. The elements of statistical learning, volume 1. Springer series in statistics New Y ork, NY , USA:, 2001. 1
[8] B. Geng, D. Tao, and C. Xu. Daml: Domain adaptation metric learning. IEEE Transactions on Image Processing, 20(10):2980�C2989, 2011. 2
[9] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y . Bengio. Generative adversarial nets. In Advances in neural information processing systems, pages 2672�C2680, 2014. 2
[10] D. He, Y . Xia, T. Qin, L. Wang, N. Y u, T. Liu, and W.-Y . Ma. Dual learning for machine translation. In Advances in Neural Information Processing Systems, pages 820�C828, 2016. 3
[11] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770�C778, 2016. 5, 7, 8
[12] J. Hoffman, E. Tzeng, T. Park, J.-Y . Zhu, P . Isola, K. Saenko, A. A. Efros, and T. Darrell. Cycada: Cycle-consistent adversarial domain adaptation. arXiv preprint arXiv:1711.03213, 2017. 1, 2, 3, 8
[13] J. Hoffman, D. Wang, F. Y u, and T. Darrell. Fcns in the wild: Pixel-level adversarial and constraint-based adaptation. arXiv preprint arXiv:1612.02649, 2016. 2, 8
[14] X. Huang, M.-Y . Liu, S. Belongie, and J. Kautz. Multimodal unsupervised image-to-image translation. arXiv preprint arXiv:1804.04732, 2018. 2, 3
[15] A. Krizhevsky, I. Sutskever, and G. E. Hinton. Imagenet classification with deep convolutional neural networks. In Advances in neural information processing systems, pages 1097�C1105, 2012. 7
[16] Y . LeCun, L. Bottou, Y . Bengio, and P . Haffner. Gradientbased learning applied to document recognition. Proceedings of the IEEE, 86(11):2278�C2324, 1998. 1, 2
[17] M.-Y . Liu, T. Breuel, and J. Kautz. Unsupervised image-toimage translation networks. In Advances in Neural Information Processing Systems, pages 700�C708, 2017. 2
[18] J. Long, E. Shelhamer, and T. Darrell. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3431�C3440, 2015. 1, 7
[19] Y . Luo, L. Zheng, T. Guan, J. Y u, and Y . Yang. Taking a closer look at domain shift: Category-level adversaries for semantics consistent domain adaptation. arXiv preprint arXiv:1809.09478, 2018. 8
[20] A. L. Maas, A. Y . Hannun, and A. Y . Ng. Rectifier nonlinearities improve neural network acoustic models. In Proc. icml, volume 30, page 3, 2013. 7
[21] M. Mancini, L. Porzi, S. R. Bul��, B. Caputo, and E. Ricci. Boosting domain adaptation by discovering latent domains. arXiv preprint arXiv:1805.01386, 2018. 2
[22] Y . Netzer, T. Wang, A. Coates, A. Bissacco, B. Wu, and A. Y . Ng. Reading digits in natural images with unsupervised feature learning. In NIPS workshop on deep learning and unsupervised feature learning, volume 2011, page 5, 2011. 1, 2
[23] X. Niu, M. Denkowski, and M. Carpuat. Bi-directional neural machine translation with synthetic parallel data. arXiv preprint arXiv:1805.11213, 2018. 3
[24] V . M. Patel, R. Gopalan, R. Li, and R. Chellappa. Visual domain adaptation: A survey of recent advances. IEEE signal processing magazine, 32(3):53�C69, 2015. 2
[25] S. Pontes-Filho and M. Liwicki. Bidirectional learning for robust neural networks. arXiv preprint arXiv:1805.08006, 2018. 3
[26] A. Radford, L. Metz, and S. Chintala. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv preprint arXiv:1511.06434, 2015. 7
[27] S. R. Richter, V . Vineet, S. Roth, and V . Koltun. Playing for data: Ground truth from computer games. In European Conference on Computer Vision, pages 102�C118. Springer, 2016. 1, 2, 5, 7
[28] G. Ros, L. Sellart, J. Materzynska, D. V azquez, and A. M. Lopez. The synthia dataset: A large collection of synthetic images for semantic segmentation of urban scenes. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3234�C3243, 2016. 1, 2, 7
[29] P . Russo, F. M. Carlucci, T. Tommasi, and B. Caputo. From source to target and back: symmetric bi-directional adaptive gan. arXiv preprint arXiv:1705.08824, 3, 2017. 3
[30] K. Saenko, B. Kulis, M. Fritz, and T. Darrell. Adapting visual category models to new domains. In European conference on computer vision, pages 213�C226. Springer, 2010. 2
[31] F. S. Saleh, M. S. Aliakbarian, M. Salzmann, L. Petersson, and J. M. Alvarez. Effective use of synthetic data for urban scene semantic segmentation. In European Conference on Computer Vision, pages 86�C103. Springer, Cham, 2018. 2
[32] K. Simonyan and A. Zisserman. V ery deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556, 2014. 7, 8
[33] Y .-H. Tsai, W.-C. Hung, S. Schulter, K. Sohn, M.-H. Yang, and M. Chandraker. Learning to adapt structured output space for semantic segmentation. arXiv preprint arXiv:1802.10349, 2018. 2, 8
[34] E. Tzeng, J. Hoffman, K. Saenko, and T. Darrell. Adversarial discriminative domain adaptation. In Computer Vision and Pattern Recognition (CVPR), volume 1, page 4, 2017. 1, 2
[35] H. T. Vu and C.-C. Huang. Domain adaptation meets disentangled representation learning and style transfer. CoRR, 2017. 1, 2, 3
[36] Z. Wu, X. Han, Y .-L. Lin, M. G. Uzunbas, T. Goldstein, S. N. Lim, and L. S. Davis. Dcan: Dual channel-wise alignment networks for unsupervised scene adaptation. arXiv preprint arXiv:1804.05827, 2018. 1, 2, 3, 8
[37] Y . Zhang, P . David, and B. Gong. Curriculum domain adaptation for semantic segmentation of urban scenes. In The IEEE International Conference on Computer Vision (ICCV), volume 2, page 6, 2017. 1, 2, 8
[38] J.-Y . Zhu, T. Park, P . Isola, and A. A. Efros. Unpaired imageto-image translation using cycle-consistent adversarial networks. arXiv preprint, 2017. 1, 2, 5, 7
[39] Y . Zou, Z. Y u, B. V . Kumar, and J. Wang. Unsupervised domain adaptation for semantic segmentation via classbalanced self-training. In Proceedings of the European Conference on Computer Vision (ECCV), pages 289�C305, 2018.