ResNetЯъНтгыCIFAR10Ъ§ОнМЏЪЕеН
1ЁЂв§бд
гЩгкЩёОЭјТчЩюЖШдіМгЖјЕМжТЕФВЮЪ§СПМБОчдіДѓЪЙЕУЮвУЧЖдЦфбЕСЗдНРДдНРЇФб,ВЂЧвЫцзХЩюЖШдіМгЛсГіЯжЭјТчЭЫЛЏЯжЯѓЁЃетЪБЮвУЧОЭашвЊВЩШЁвЛжжЗНЗЈШЅгааЇЕиНтОіетИіЮЪЬтЁЃдк2015Фъ,КЮПУїДѓЩёЬсГіСЫresidual nets(ЩюЖШВаВюЭјТч,КѓУцМђГЦЮЊResNet)ФмЙЛгааЇЕиНтОіетИіЮЪЬт,ЭЌЪБЛЙФмгааЇНтОіЬнЖШЯћЪЇКЭЬнЖШБЌеЈЮЪЬтДгЖјИќНјвЛВНЬсИпЭјТчЕФбЇЯАаЇЙћЁЃ
2ЁЂResNetдРэ
ЩюЖШВаВюЩёОЭјТчВЛашвЊШЅФтКЯЕзВуЕФгГЩф,ЖјЪЧШЅФтКЯЯрЖдгкЪфШыЕФВаВюЁЃВаВюФЃПщШчЯТ:
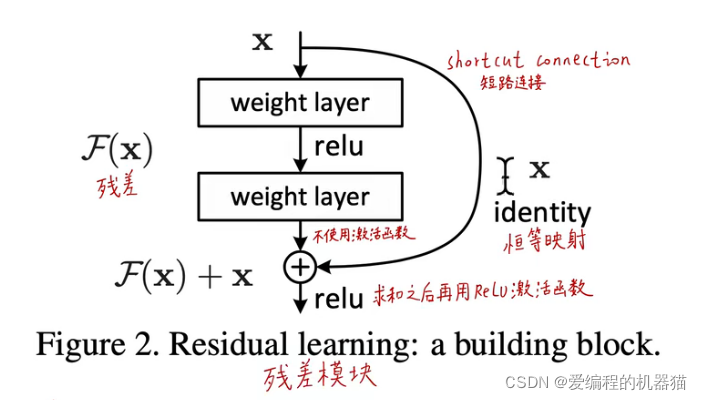
ЮвУЧЩш
x
x
xЮЊЪфШыЪ§Он,ЩшдРДЕФЕзВугГЩфЮЊ
H
(
x
)
H(x)
H(x),ЩшЯрЖдгк
x
x
xЕФВаВюЮЊ
F
(
x
)
F(x)
F(x),ЫљвдПЩвдЕУЕН
F
(
x
)
=
H
(
x
)
?
x
F(x)=H(x)-x
F(x)=H(x)?xЁЃОЙ§ВаВюФЃПщКѓЕзВугГЩфОЭЪЧ
F
(
x
)
+
x
F(x)+x
F(x)+xЁЃДгЩЯУцПЩвдПДГі,дкМЋЖЫЧщПіЯТ,ШчЙћЕзВугГЩфзуЙЛКУ,ФЧУДВаВюОЭЪЧ0,етЪБОЭВЛашвЊДгВаВюжабЇЯАСЫ,ДЫЪБЕзВугГЩфОЭЪЧКуЕШгГЩфЁЃ
3ЁЂResNetНтОіЭјТчЭЫЛЏЕФЛњРэ
(1)ЩюВуЬнЖШЛиДЋЫГГЉ
КуЕШгГЩфетвЛЬѕТЗЕФЬнЖШЮЊ1,ФмЙЛЭЈЙ§етЬѕТЗКмКУЕиАбЩюВуЬнЖШзЂШыЕзВу,ЗРжЙЬнЖШЯћЪЇ,УЛгаЯёsigmoidетбљжаМфЩЬЕФВуВуАўЖсЁЃ
(2)ЭјТчздЩэЙЙНЈЕФгХЪЦ
1)УПДЮЖМЪЧШЅФтКЯЩЯвЛВуЕФЮѓВю,етбљЛсШУЮѓВюИќОЁПЩФмБфаЁ
2)ВаВюРрЫЦгкLSTMЕФвХЭќУХ,ШчЙћФГИіаХЯЂгагУЕФ,дђМЧзЁ;ШчЙћУЛгагУ,дђЭќМЧ,зюКѓдйШУКѓУцЕФЙ§ГЬШЅФтКЯЁЃетбљФмИпаЇТЪЕУЕНгааЇаХЯЂ,МгПьФЃаЭЪеСВЁЃ
3)ЪЙгУReLuМЄЛюКЏЪ§,ВЛЛсЯёsigmoidетбљвђЮЊЖрДЮЕќДњЖјЪЙЬнЖШНќЫЦ0,вджСгкЮоЗЈИќМгБЦНќИќКУЕФНсЙћЁЃ
(3)ДЋЭГЕФЯпадЭјТчКмФбШЅФтКЯЁАКуЕШгГЩфЁБ,ЖјResNetПЩвд
гЩгкЩюЖШбЇЯАЕФашвЊ,ЮвУЧгаЪБашвЊдЗтВЛЖЏЕиБЃДцжЎЧАЕФаХЯЂЁЃResNetЕФВаВюФЃПщОЭФмИљОнашвЊздЖЏбЁдёЪЧЗёвЊИќаТФЧаЉаХЯЂЁЃ,етбљОЭУжВЙСЫИпЖШЗЧЯпаддьГЩЕФВЛПЩФцЕФаХЯЂЫ№ЪЇЁЃ
4ЁЂCIFAR10Ъ§ОнМЏЪЕеН
етРяЮвУЧбЁдёЙЙНЈResNet18,ОпЬхФЃаЭНсЙЙШчЯТ:
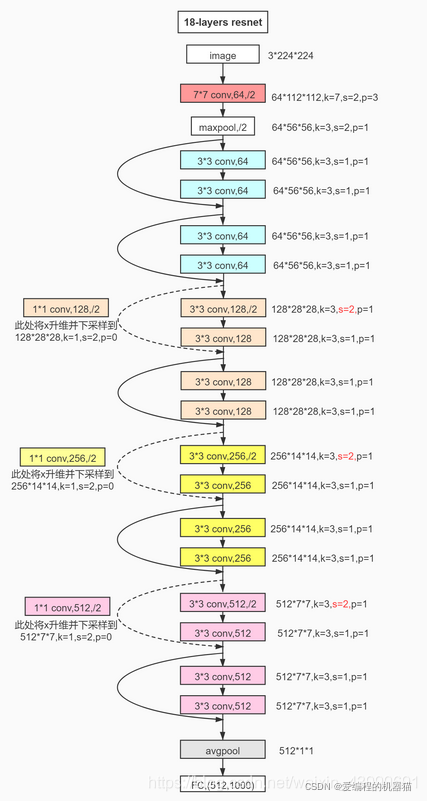
(1)ЕМШыЪ§Он
ЪЙгУdataloaderЕМШыЪ§Он,ВЂзЊЛЛГЩtensor
# ЕМШыбЕСЗМЏЪ§Он
train_data = dataloader.DataLoader(
datasets.CIFAR10(root='data/', train=True, transform=transforms.Compose([
transforms.Resize(32, 32), # жиаТЩшжУЭМЦЌДѓаЁ
transforms.ToTensor(), # НЋЭМЦЌзЊЛЏЮЊtensor
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]) # НјааЙщвЛЛЏ
]), download=True), shuffle=True, batch_size=batch_sz
)
# ЕМШыВтЪдМЏЪ§Он
train_test = dataloader.DataLoader(
datasets.CIFAR10(root='data/', train=False, transform=transforms.Compose([
transforms.Resize(32, 32),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
]), download=True), shuffle=True, batch_size=batch_sz
)
(2)ЖЈвхЭјТчНсЙЙ
ЪзЯШЮвУЧашвЊЯШЖЈвхВаВюЕФblock
ИљОнЩЯУцЕФВаВюФЃПщЭМЦЌВЛФбаДГі
# ЖЈвхВаВюПщ
class ResBlk(nn.Module):
def __init__(self, ch_in, ch_out, stride):
super(ResBlk, self).__init__()
self.conv1 = nn.Conv2d(ch_in, ch_out, kernel_size=3, stride=stride, padding=1)
self.bn1 = nn.BatchNorm2d(ch_out)
self.conv2 = nn.Conv2d(ch_out, ch_out, kernel_size=3, stride=1, padding=1)
self.bn2 = nn.BatchNorm2d(ch_out)
self.extra = nn.Sequential(
nn.Conv2d(ch_in, ch_out, kernel_size=1, stride=stride),
nn.BatchNorm2d(ch_out)
)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
out = self.extra(x) + out
out = F.relu(out)
return out
ШЛКѓдйИљОнЩЯЭМаДResNet18ЭјТчНсЙЙ,зЂвтЮЌЖШБфЛЛ
# ЖЈвхResNet18ЭјТчНсЙЙ
class ResNet18(nn.Module):
def __init__(self):
super(ResNet18, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, stride=3, padding=0),
nn.BatchNorm2d(64)
)
self.blk1 = ResBlk(64, 64, stride=2)
self.blk2 = ResBlk(64, 128, stride=2)
self.blk3 = ResBlk(128, 256, stride=2)
self.blk4 = ResBlk(256, 512, stride=2)
self.outlayer = nn.Linear(512*1*1, 10)
def forward(self, x):
x = F.relu(self.conv1(x))
x = self.blk1(x)
x = self.blk2(x)
x = self.blk3(x)
x = self.blk4(x)
x = F.adaptive_avg_pool2d(x, [1, 1])
x = x.view(x.size(0), -1)
x = self.outlayer(x)
return x
(3)ЖЈвхЫ№ЪЇКЏЪ§КЭгХЛЏЗНЪН
Ы№ЪЇКЏЪ§ЪЙгУCrossEntropyLoss(НЛВцьи),гХЛЏЗНЪНЪЙгУAdamЁЃжСгкЮЊЪВУДЪЙгУНЛВцьи,ЫќЛсЪЙЬнЖШБфЕУИќДѓ,гХЛЏЦ№РДИќПьЁЃШчЙћЪЙгУsigmoid+MSEЕФЛАЛсБШНЯШнвзГіЯжsigmoidБЅКЭЕФЧщПі,етЪБЛсГіЯжЬнЖШЯћЪЇЧщПіЁЃзюКѓжЛФмЫЕИљОнЪЕбщНЛВцьидкЗжРрЮЪЬтЩЯБэЯжаЇЙћЗЧГЃКУЁЃ
# ЖЈвхЫ№ЪЇКЏЪ§КЭгХЛЏЗНЪН
criteon = nn.CrossEntropyLoss().to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=learn_rate)
(4)бЕСЗВтЪдФЃаЭ
# бЕСЗФЃаЭ
for epoch in range(1):
model.train()
for batch_idx, (x, label) in enumerate(train_data):
x = x.to(device)
label = label.to(device)
logits = model(x) # ОЙ§ФЃаЭЕУЕНЕФЪ§Он
loss = criteon(logits, label)
print('logits:', logits[0])
print('label:', label[0])
# ЗДЯђДЋВЅ
optimizer.zero_grad()
loss.backward()
optimizer.step()
if batch_idx == len(train_data) - 1:
print(epoch, 'loss:', loss.item())
# НјааВтЪд
model.eval()
with torch.no_grad():
total_correct = 0
total_num = 0
for x, label in train_test:
x = x.to(device)
label = label.to(device)
logits = model(x)
pred = logits.argmax(dim=1)
correct = torch.eq(pred, label).float().sum().item()
total_correct += correct
total_num += x.size(0)
acc = total_correct / total_num
print(epoch, 'test acc:', acc)
зюКѓЕФЗжРрзМШЗТЪДѓдМФмДяЕНАйЗжжЎ90зѓгвЁЃ
githubЭъећДњТы:ResNetдДДњТы
аЁЛяАщЯВЛЖЮФеТЕФЛАМЧЕУ ЕудоМгЙизЂХЖ,КѓУцЛсИќаТЦфЫћЩюЖШбЇЯАЕФЮФеТЁЃ
ШчЙћгаЪВУДаДЕУгаЮЪЬтЕФЕиЗНЯЃЭћДѓМвФмжЕГі,аЛаЛЁЃ