�ο�:
һ�����ݼ�
���ص�ַ:����:
����:https://pan.baidu.com/s/1xBph3IBXKnArVtMSckLeMA ��ȡ��:1111
����3523��ѵ��ͼƬ��882�Ų���ͼƬ,��ǩ��ʽΪtxt�ļ�,ÿ��ͼƬ��Ӧһ��txt�ļ���
��ǩ��ʽ <���><xcenter><ycenter><box_width><box_height>
����ģ������
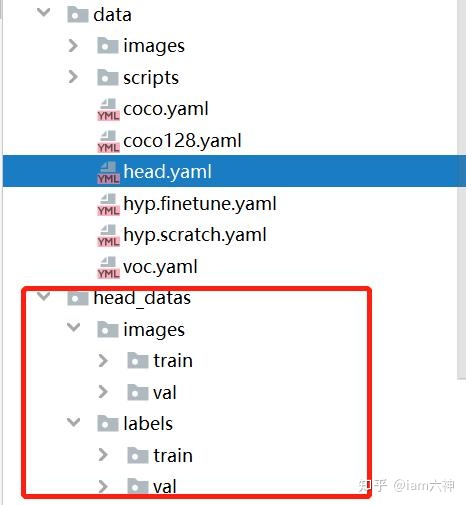
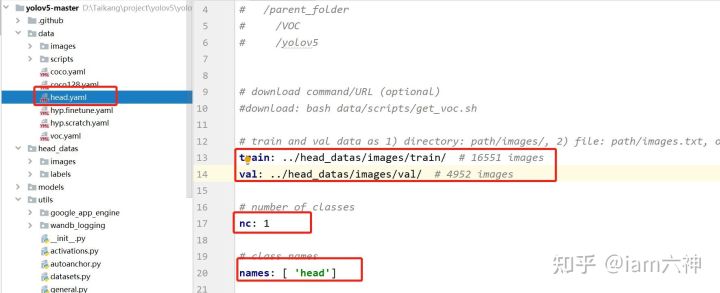
2.1. ���ݼ�Ŀ¼����
��data�ļ����´���head.yaml,���ļ������������,��������Լ����ݼ���·������������ͼ��ʾ:
 ?
?
head.yaml
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Example usage: python train.py --data head.yaml
# parent
# ������ yolov5
# ������ data
# ������ head_datas
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
# path: ../datasets/Objects365 # dataset root dir
# train: images/train # train images (relative to 'path') 1742289 images
# val: images/val # val images (relative to 'path') 80000 images
# test: # test images (optional)
train: ./data/head_datas/images/train/ # 16551
val: ./data/head_datas/images/val/ # 4952
# Classes
# nc: 365 # number of classes
nc: 1
names: ['Head']
2.2. Ԥѵ��ģ��
�� yolov5 github Դ���ַ����Ԥѵ�� yolov5s.pt��yolov5m.pt��yolov5l.pt��yolov5x.pt������ weightsĿ¼��,ѵ��ǰ��Ҫ��modelsĿ¼��yolov5.yaml�ļ����������,ʹ���ĸ�ģ��Ȩ�ؾ��Ķ�Ӧ��yaml�ļ���
 ?
?
weights
��. ѵ��ģ��
�μ�:
python train.py
�������Լ���·��������ͼ��ʾ����Ϣ,����epochs��batch-sizeҲ���Ը����Լ����Կ����ý����ġ�
 ?
?
train.py
def parse_opt(known=False):
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default=ROOT / 'weights/yolov5s.pt', help='initial weights path')
parser.add_argument('--cfg', type=str, default='models/yolov5s.yaml', help='model.yaml path')
parser.add_argument('--data', type=str, default=ROOT / 'data/head.yaml', help='dataset.yaml path')
parser.add_argument('--hyp', type=str, default=ROOT / 'data/hyps/hyp.scratch-low.yaml', help='hyperparameters path')
parser.add_argument('--epochs', type=int, default=300)
parser.add_argument('--batch-size', type=int, default=16, help='total batch size for all GPUs, -1 for autobatch')
parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='train, val image size (pixels)')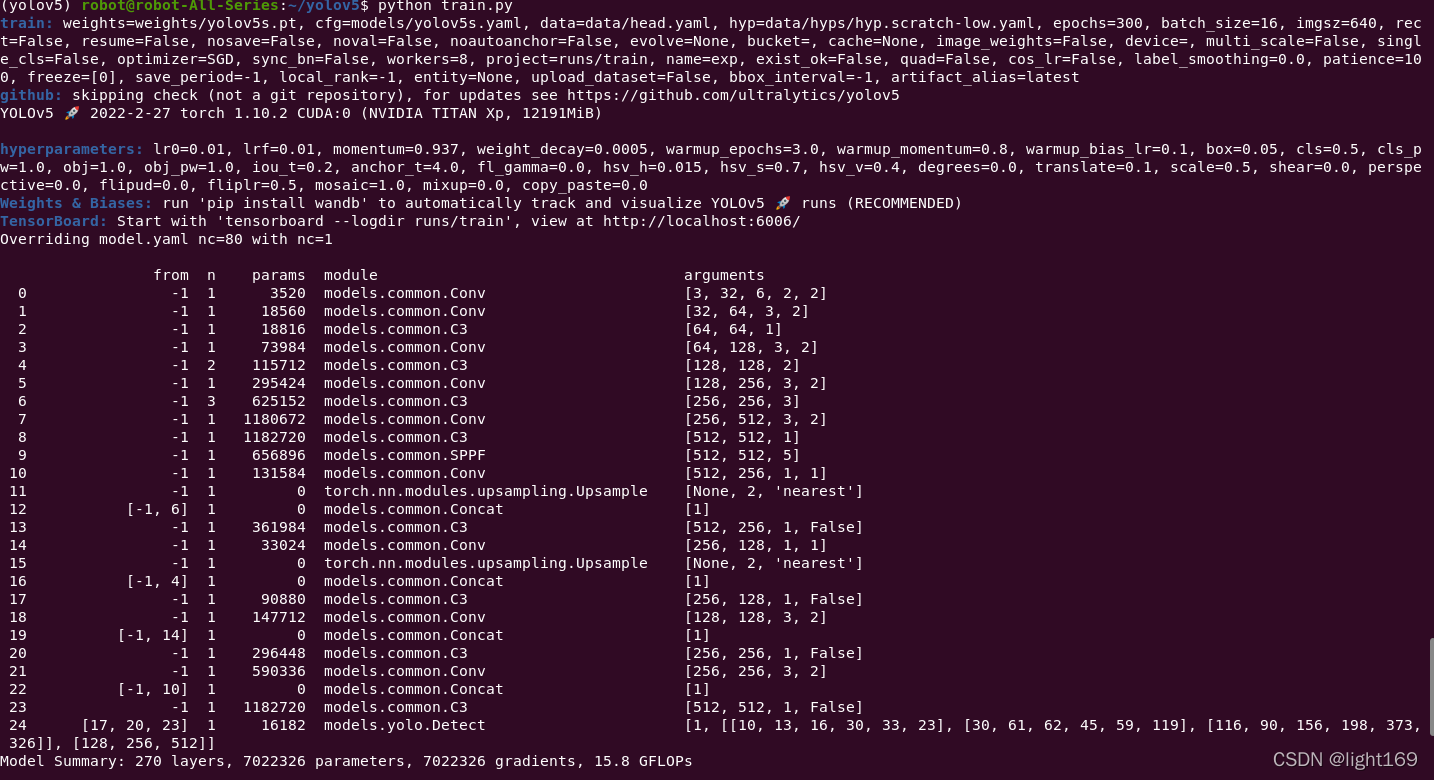
(yolov5) robot@robot-All-Series:~/yolov5$ python train.py
train: weights=weights/yolov5s.pt, cfg=models/yolov5s.yaml, data=data/head.yaml, hyp=data/hyps/hyp.scratch-low.yaml, epochs=300, batch_size=16, imgsz=640, rect=False, resume=False, nosave=False, noval=False, noautoanchor=False, evolve=None, bucket=, cache=None, image_weights=False, device=, multi_scale=False, single_cls=False, optimizer=SGD, sync_bn=False, workers=8, project=runs/train, name=exp, exist_ok=False, quad=False, cos_lr=False, label_smoothing=0.0, patience=100, freeze=[0], save_period=-1, local_rank=-1, entity=None, upload_dataset=False, bbox_interval=-1, artifact_alias=latest
github: skipping check (not a git repository), for updates see https://github.com/ultralytics/yolov5
YOLOv5 🚀 2022-2-27 torch 1.10.2 CUDA:0 (NVIDIA TITAN Xp, 12191MiB)
hyperparameters: lr0=0.01, lrf=0.01, momentum=0.937, weight_decay=0.0005, warmup_epochs=3.0, warmup_momentum=0.8, warmup_bias_lr=0.1, box=0.05, cls=0.5, cls_pw=1.0, obj=1.0, obj_pw=1.0, iou_t=0.2, anchor_t=4.0, fl_gamma=0.0, hsv_h=0.015, hsv_s=0.7, hsv_v=0.4, degrees=0.0, translate=0.1, scale=0.5, shear=0.0, perspective=0.0, flipud=0.0, fliplr=0.5, mosaic=1.0, mixup=0.0, copy_paste=0.0
Weights & Biases: run 'pip install wandb' to automatically track and visualize YOLOv5 🚀 runs (RECOMMENDED)
TensorBoard: Start with 'tensorboard --logdir runs/train', view at http://localhost:6006/
Overriding model.yaml nc=80 with nc=1
from n params module arguments
0 -1 1 3520 models.common.Conv [3, 32, 6, 2, 2]
1 -1 1 18560 models.common.Conv [32, 64, 3, 2]
2 -1 1 18816 models.common.C3 [64, 64, 1]
3 -1 1 73984 models.common.Conv [64, 128, 3, 2]
4 -1 2 115712 models.common.C3 [128, 128, 2]
5 -1 1 295424 models.common.Conv [128, 256, 3, 2]
6 -1 3 625152 models.common.C3 [256, 256, 3]
7 -1 1 1180672 models.common.Conv [256, 512, 3, 2]
8 -1 1 1182720 models.common.C3 [512, 512, 1]
9 -1 1 656896 models.common.SPPF [512, 512, 5]
10 -1 1 131584 models.common.Conv [512, 256, 1, 1]
11 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
12 [-1, 6] 1 0 models.common.Concat [1]
13 -1 1 361984 models.common.C3 [512, 256, 1, False]
14 -1 1 33024 models.common.Conv [256, 128, 1, 1]
15 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
16 [-1, 4] 1 0 models.common.Concat [1]
17 -1 1 90880 models.common.C3 [256, 128, 1, False]
18 -1 1 147712 models.common.Conv [128, 128, 3, 2]
19 [-1, 14] 1 0 models.common.Concat [1]
20 -1 1 296448 models.common.C3 [256, 256, 1, False]
21 -1 1 590336 models.common.Conv [256, 256, 3, 2]
22 [-1, 10] 1 0 models.common.Concat [1]
23 -1 1 1182720 models.common.C3 [512, 512, 1, False]
24 [17, 20, 23] 1 16182 models.yolo.Detect [1, [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], [128, 256, 512]]
Model Summary: 270 layers, 7022326 parameters, 7022326 gradients, 15.8 GFLOPs
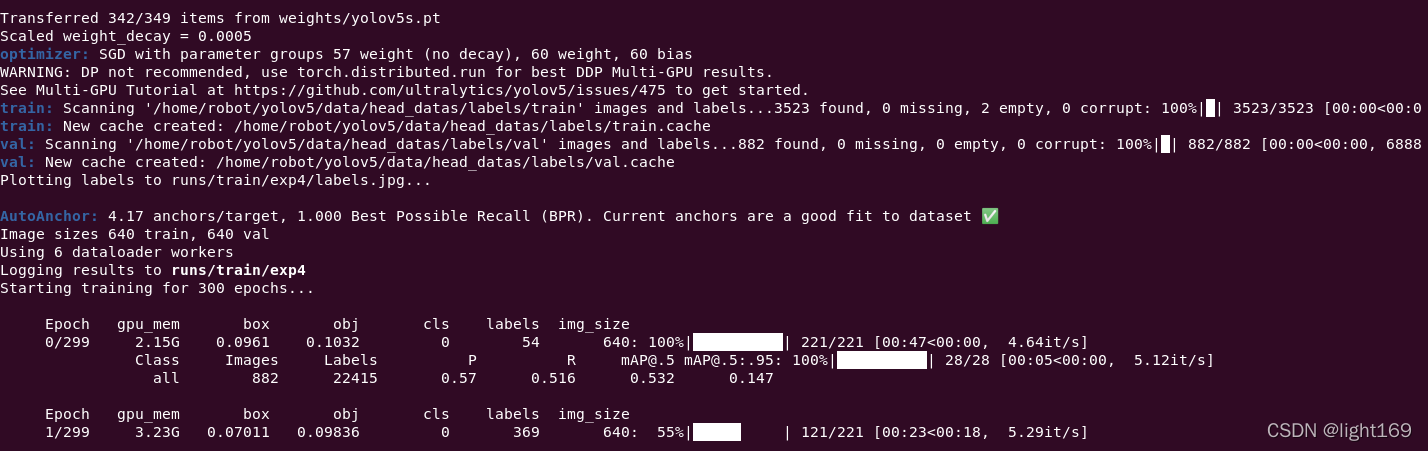
Transferred 342/349 items from weights/yolov5s.pt
Scaled weight_decay = 0.0005
optimizer: SGD with parameter groups 57 weight (no decay), 60 weight, 60 bias
WARNING: DP not recommended, use torch.distributed.run for best DDP Multi-GPU results.
See Multi-GPU Tutorial at https://github.com/ultralytics/yolov5/issues/475 to get started.
train: Scanning '/home/robot/yolov5/data/head_datas/labels/train' images and labels...3523 found, 0 missing, 2 empty, 0 corrupt: 100%|��| 3523/3523 [00:00<00:0
train: New cache created: /home/robot/yolov5/data/head_datas/labels/train.cache
val: Scanning '/home/robot/yolov5/data/head_datas/labels/val' images and labels...882 found, 0 missing, 0 empty, 0 corrupt: 100%|��| 882/882 [00:00<00:00, 6888
val: New cache created: /home/robot/yolov5/data/head_datas/labels/val.cache
Plotting labels to runs/train/exp4/labels.jpg...
AutoAnchor: 4.17 anchors/target, 1.000 Best Possible Recall (BPR). Current anchors are a good fit to dataset ?
Image sizes 640 train, 640 val
Using 6 dataloader workers
Logging results to runs/train/exp4
Starting training for 300 epochs...
Epoch gpu_mem box obj cls labels img_size
0/299 2.15G 0.0961 0.1032 0 54 640: 100%|��������������������| 221/221 [00:47<00:00, 4.64it/s]
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|��������������������| 28/28 [00:05<00:00, 5.12it/s]
all 882 22415 0.57 0.516 0.532 0.147
Epoch gpu_mem box obj cls labels img_size
1/299 3.23G 0.0693 0.09994 0 115 640: 100%|��������������������| 221/221 [00:43<00:00, 5.13it/s]
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|��������������������| 28/28 [00:05<00:00, 5.57it/s]
all 882 22415 0.733 0.718 0.754 0.267
Epoch gpu_mem box obj cls labels img_size
2/299 3.23G 0.0649 0.1023 0 45 640: 100%|��������������������| 221/221 [00:42<00:00, 5.20it/s]
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|��������������������| 28/28 [00:04<00:00, 5.70it/s]
all 882 22415 0.371 0.343 0.246 0.0488
Epoch gpu_mem box obj cls labels img_size
3/299 3.23G 0.0571 0.09583 0 161 640: 100%|��������������������| 221/221 [00:42<00:00, 5.23it/s]
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|��������������������| 28/28 [00:05<00:00, 5.56it/s]
all 882 22415 0.889 0.782 0.852 0.376
device����,��Ϊ�������鿨,���Ա��Ϊ0,1
ѵ������Сʱ,��ɡ�
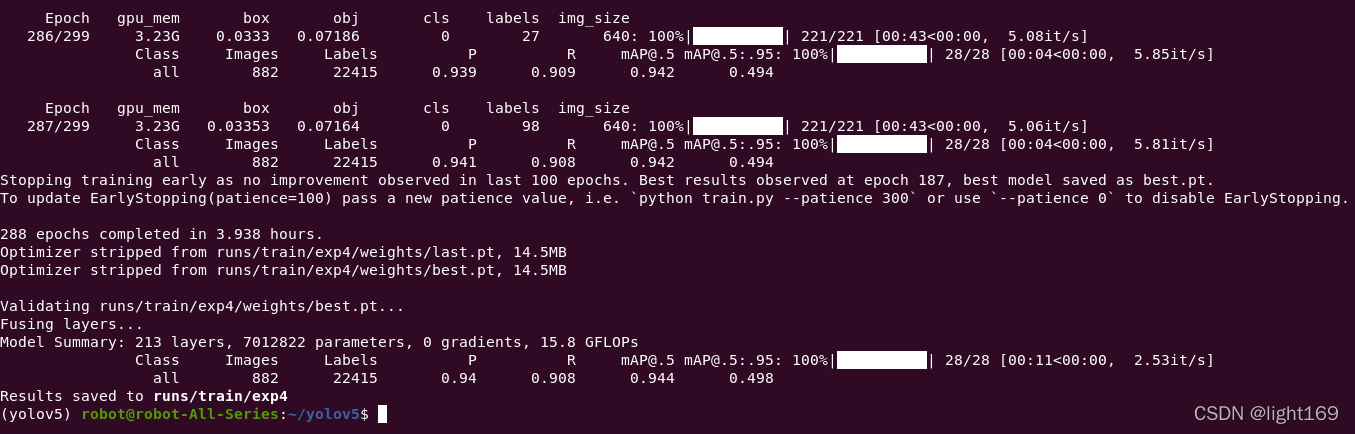
Epoch gpu_mem box obj cls labels img_size
287/299 3.23G 0.03353 0.07164 0 98 640: 100%|��������������������| 221/221 [00:43<00:00, 5.06it/s]
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|��������������������| 28/28 [00:04<00:00, 5.81it/s]
all 882 22415 0.941 0.908 0.942 0.494
Stopping training early as no improvement observed in last 100 epochs. Best results observed at epoch 187, best model saved as best.pt.
To update EarlyStopping(patience=100) pass a new patience value, i.e. `python train.py --patience 300` or use `--patience 0` to disable EarlyStopping.
288 epochs completed in 3.938 hours.
Optimizer stripped from runs/train/exp4/weights/last.pt, 14.5MB
Optimizer stripped from runs/train/exp4/weights/best.pt, 14.5MB
Validating runs/train/exp4/weights/best.pt...
Fusing layers...
Model Summary: 213 layers, 7012822 parameters, 0 gradients, 15.8 GFLOPs
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|��������������������| 28/28 [00:11<00:00, 2.53it/s]
all 882 22415 0.94 0.908 0.944 0.498
Results saved to runs/train/exp4
ѵ���õ�ģ�ͻᱻ������weights/last.pt��best.pt
�ġ�ģ�Ͳ���
python detect.py
python detect.py --source=data/images/test0.png --weights=weights/last.pt

ģ��ѵ���õ���Ȩ�ر�����runsĿ¼��,���ж�Ӧ��bese.pt��last.pt,��detect.py�ļ�����ģ��Ȩ��·��������ͼƬ��·�����ɡ�
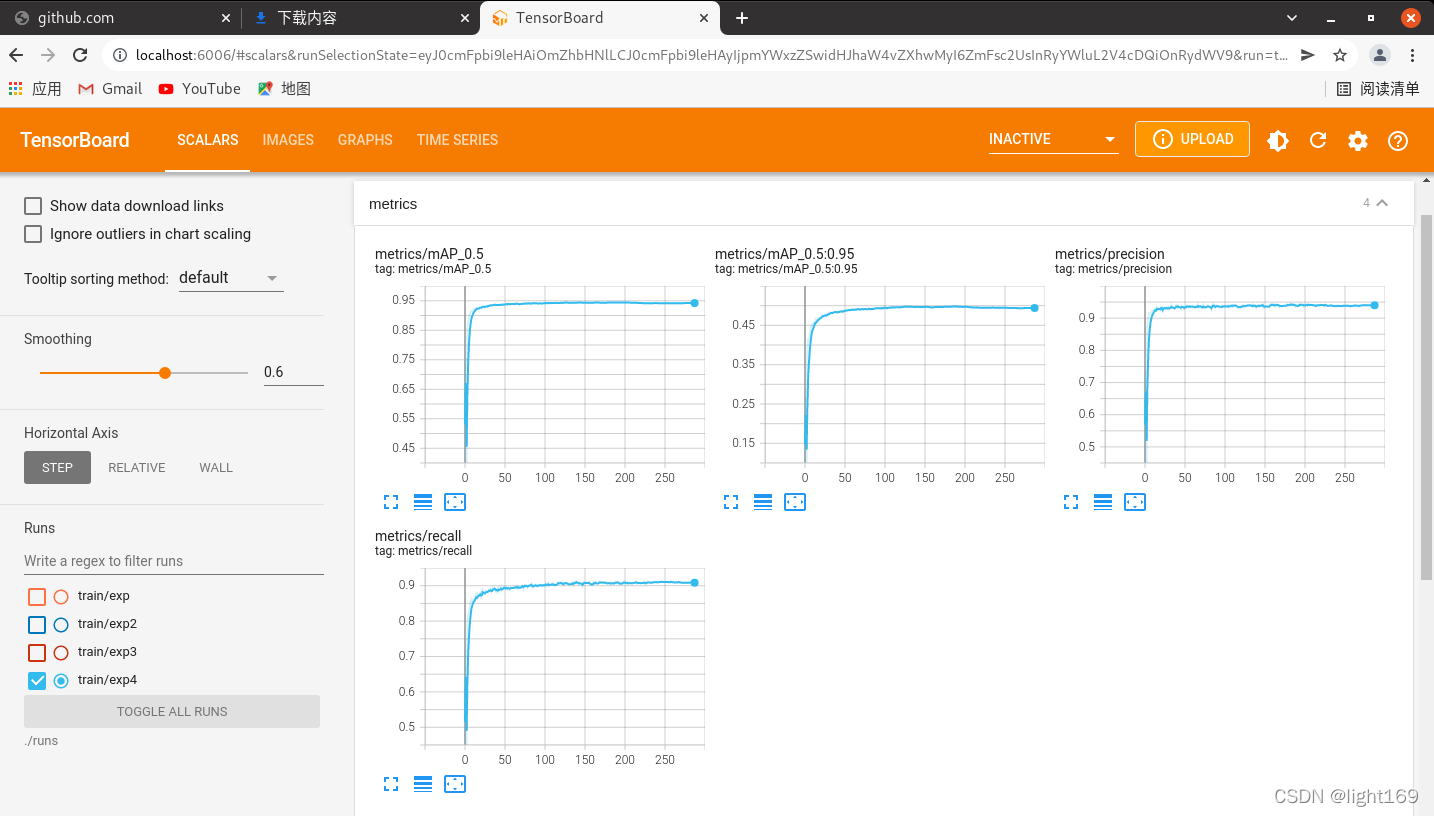
�塢ѵ�����̵Ŀ��ӻ�
����������tensorboard�����ӻ�ѵ�����̵�,ѵ����ʼ������Ŀ¼����һ��runs�ļ�.����tensorboard����
tensorboard --logdir=./runs(yolov5) robot@robot-All-Series:~/yolov5$ tensorboard --logdir=./runs
TensorFlow installation not found - running with reduced feature set.
NOTE: Using experimental fast data loading logic. To disable, pass
"--load_fast=false" and report issues on GitHub. More details:
https://github.com/tensorflow/tensorboard/issues/4784
Serving TensorBoard on localhost; to expose to the network, use a proxy or pass --bind_all
TensorBoard 2.8.0 at http://localhost:6006/ (Press CTRL+C to quit)