Transformer P2_Decoder
Decoder ЈC Autoregressive (AT)
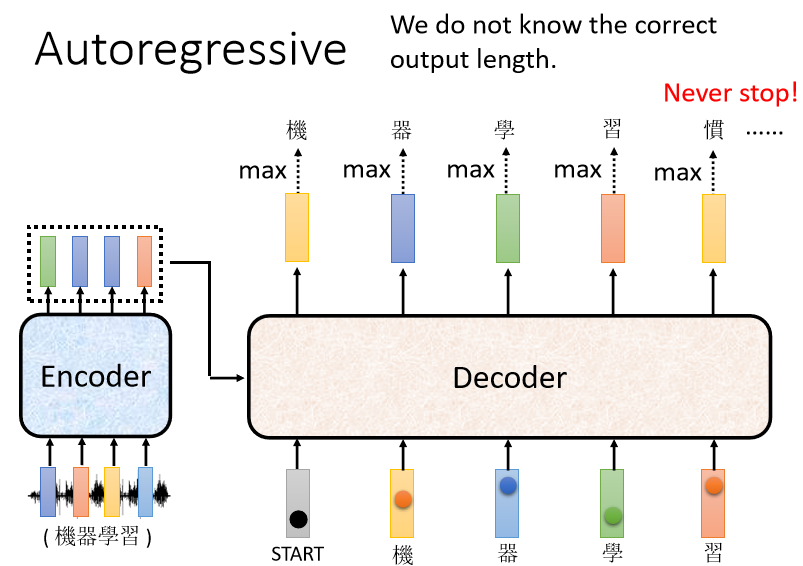
Autoregressive (AT )😗 РћгУЧАЦкШєИЩЪБПЬЕФЫцЛњБфСПЕФЯпадзщКЯРДУшЪівдКѓФГЪБПЬЫцЛњБфСПЕФЯпадЛиЙщФЃаЭЁЃМДвбжЊNИіЪ§Он,ПЩгЩФЃаЭЭЦГіЕкNЕуЧАУцЛђКѓУцЕФЪ§Он(ЩшЭЦГіPЕу)
DecoderЦфЪЕгаСНжж,НгЯТРДЛсЛЈБШНЯЖрЪБМфНщЩм,БШНЯГЃМћЕФ Autoregressive Decoder,етИі Autoregressive ЕФ Decoder,ЪЧдѕќNдЫзїЕФ
гУгявєБцЪЖ,РДЕБзїР§згРДЫЕУї,ЛђгУдкзївЕбeУцЕФЛњЦїЗвы,ЦфЪЕЪЧвЛФЃвЛбљЕФ,ФужЛЪЧАбЪфШыЪфГі,ИФГЩВЛЭЌЕФЖЋЮїЖјвб
гявєБцЪЖОЭЪЧЪфШывЛЖЮЩљвє,ЪфГівЛДЎЮФзж,ФуЛсАбвЛЖЮЩљвєЪфШыИј Encoder,БШШчЫЕФуЖдЛњЦїЫЕ,ЛњЦїбЇЯА,ЛњЦїЪеЕНвЛЖЮЩљвєбЖКХ,ЩљвєбЖКХ НјШы EncoderвдКѓ,ЪфГіЛсЪЧЪВќN,ЪфГіЛсБфГЩвЛХХ Vector
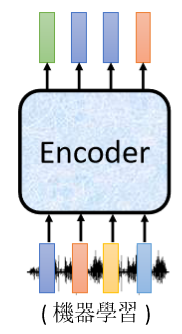
Encoder зіЕФЪТЧщ,ОЭЪЧЪфШывЛИі Vector Sequence,ЪфГіСэЭтвЛИі Vector Sequence
НгЯТРД,ОЭТжЕН Decoder дЫзїСЫ,Decoder вЊзіЕФЪТЧщОЭЪЧЎaЩњЪфГі,вВОЭЪЧЎaЩњгявєБцЪЖЕФНсЙћ, Decoder дѕќNЎaЩњетИігявєБцЪЖЕФНсЙћ
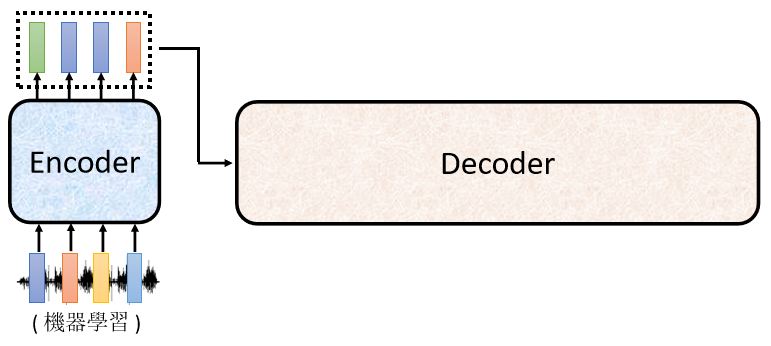
Decoder зіЕФЪТЧщ,ОЭЪЧАб Encoder ЕФЪфГіЯШЖСНјШЅ,жСьЖдѕќNЖСНјШЅ,етИіЮвУЧЕШвЛЯТдйНВ ЮвУЧЯШ,ФуЯШМйЩш Somehow ОЭЪЧгаФГжжЗНЗЈ,Аб Encoder ЕФЪфГіЖСЕН Decoder бeУц,етВНЮвУЧЕШвЛЯТдйДІРэ
Decoder дѕќNЎaЩњвЛЖЮЮФзж
ЪзЯШ,ФувЊЯШИјЫќвЛИіЬиЪтЕФЗћКХ,етИіЬиЪтЕФЗћКХ,ДњБэПЊЪМ,дкжњНЬЕФЭЖгАЦЌбeУц,ЪЧаД Begin Of Sentence,ЫѕаДЪЧ BOS
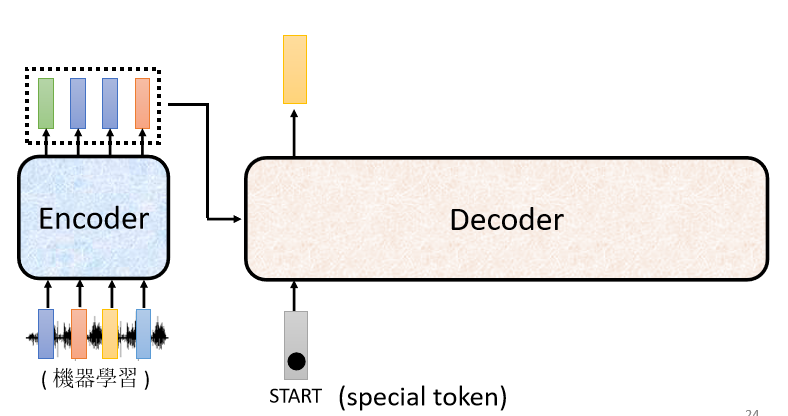
ОЭЪЧ Begin ЕФвтЫМ,етИіЪЧвЛИі Special ЕФ Token,ФуОЭЪЧдкФуЕФИі Lexicon бeУц,ФуОЭдкФуПЩФм,БОРД Decoder ПЩФмЎaЩњЕФЮФзжбeУц,ЖрМгвЛИіЬиЪтЕФзж,етИізжОЭДњБэСЫ BEGIN,ДњБэСЫПЊЪМетИіЪТЧщ
дкетИіЛњЦїбЇЯАбeУц,МйЩшФувЊДІРэ NLP ЕФЮЪЬт,УПвЛИі Token,ФуЖМПЩвдАбЫќгУвЛИі One-Hot ЕФ Vector РДБэЪО,One-Hot Vector ОЭЦфжавЛЮЌЪЧ 1,ЦфЫћЖМЪЧ 0,Ыљвд BEGIN вВЪЧгУ One-Hot Vector РДБэЪО,ЦфжавЛЮЌЪЧ 1,ЦфЫћЪЧ 0
НгЯТРДDecoder ЛсЭТГівЛИіЯђСП,етИі Vector ЕФГЄЖШКмГЄ,ИњФуЕФ Vocabulary ЕФ Size ЪЧвЛбљЕФ
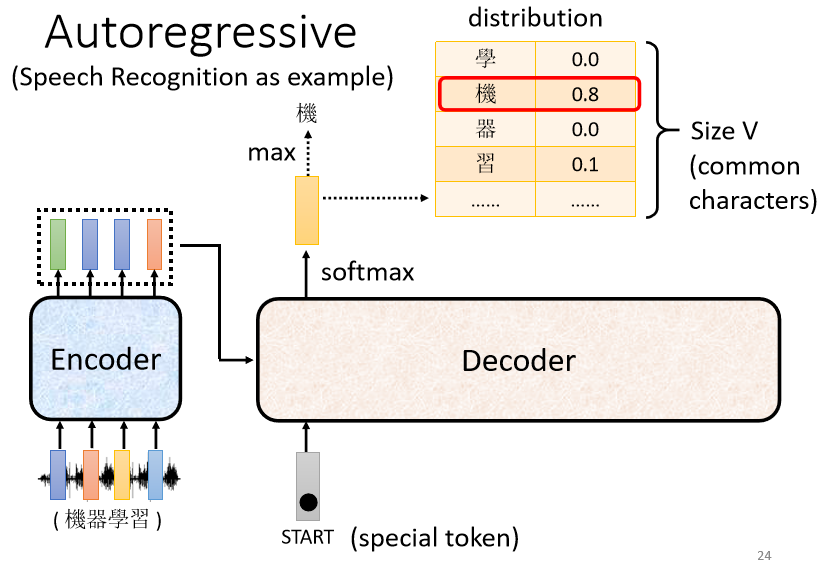
Vocabulary SizeдђЪЧЪВќNвтЫМ
ФуОЭЯШЯыКУЫЕ,ФуЕФ Decoder ЪфГіЕФЕЅЮЛЪЧЪВќN,МйЩшЮвУЧНёЬьзіЕФЪЧжаЮФЕФгявєБцЪЖ,ЮвУЧ Decoder ЪфГіЕФЪЧжаЮФ,ФуетБпЕФ Vocabulary ЕФ Size ,ПЩФмОЭЪЧжаЮФЕФЗНПщзжЕФЪ§ФП
ВЛЭЌЕФзжЕф,ИјФуЕФЪ§зжПЩФмЪЧВЛвЛбљЕФ,ГЃгУЕФжаЮФЕФЗНПщзж,ДѓИХСН Ш§ЧЇИі,вЛАуШЫ,ПЩФмШЯЕУЕФЫФ ЮхЧЇИі,дкИќЖрЖМЪЧКБМћзж РфЦЇЕФзж,ЫљвдФуОЭПДПДЫЕ,ФувЊШУФуЕФ Decoder,ЪфГіФФаЉПЩФмЕФжаЮФЕФЗНПщзж,ФуОЭАбЫќСадкетБп
ОйР§РДЫЕ,ФуОѕЕУетИі Decoder,ФмЙЛЪфГіГЃМћЕФ 3000 ИіЗНПщзжОЭКУСЫ,ОЭАбЫќСадкетИіЕиЗН,ВЛЭЌЕФгябд,ЫќЪфГіЕФЕЅЮЛ ВЛМћВЛЛсВЛвЛбљ,етИіШЁОіьЖФуЖдИігябдЕФРэНт
БШШчЫЕгЂЮФ,ФуПЩвдбЁдёЪфГізжФИЕФ A ЕН Z,ЪфГігЂЮФЕФзжФИ,ЕЋФуПЩФмЛсОѕЕУзжФИетИіЕЅЮЛЬЋаЁСЫ,гаШЫПЩФмЛсбЁдёЪфГігЂЮФЕФДЪЛу,гЂЮФЕФДЪЛуЪЧгУПеАззїщМфИєЕФ,ЕЋШчЙћЖМгУДЪЛуЕБзїЪфГі,гжЬЋЖрСЫ
ЫљвдФуЛсЗЂЯж,ИеВХдкжњНЬЕФЭЖгАЦЌбeУц,жњНЬЫЕЫћЪЧгУ Subword ЕБзїгЂЮФЕФЕЅЮЛ,ОЭгавЛаЉЗНЗЈ,ПЩвдАбгЂЮФЕФзжЪззжИљЧаГіРД,ФУзжЪззжИљЕБзїЕЅЮЛ,ШчЙћжаЮФЕФЛА,ЮвОѕЕУОЭБШНЯЕЅДП,ЭЈГЃНёЬьФуПЩФмОЭгУжаЮФЕФетИіЗНПщзж,РДЕБзїЕЅЮЛ
УПвЛИіжаЮФЕФзж,ЖМЛсЖдгІЕНвЛИіЪ§жЕ,вђщдкЎaЩњетИіЯђСПжЎЧА,ФуЭЈГЃЛсЯШХмвЛИі Softmax,ОЭИњзіЗжРрвЛбљ,ЫљвдетвЛИіЯђСПбeУцЕФЗжЪ§,ЫќЪЧвЛИі Distribution,вВОЭЪЧ,ЫќетИіЯђСПбeУцЕФжЕ,ЫќШЋВПМгЦ№РД,змКЭ ЛсЪЧ 1
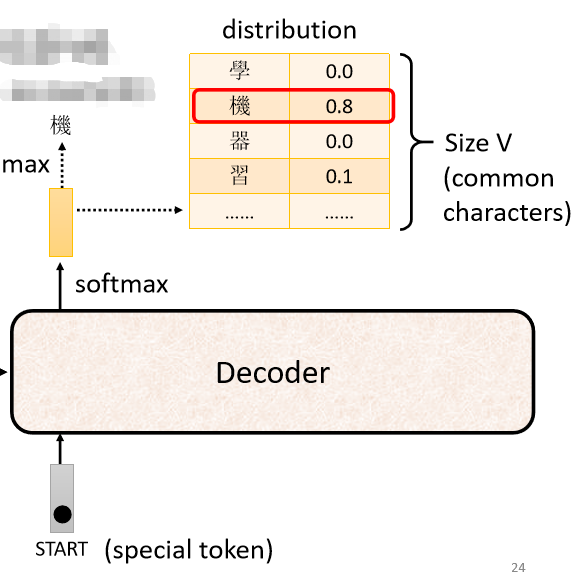
ЗжЪ§зюИпЕФвЛИіжаЮФзж,ЫќОЭЪЧзюжеЕФЪфГі
дкетИіР§згбeУц,ЛњЕФЗжЪ§зюИп,ЫљвдЛњ,ОЭЕБзіЪЧетИі Decoder ЕквЛИіЪфГі
ШЛКѓНгЯТРД,ФуАбЁАЛњЁБЕБзіЪЧ Decoder аТЕФ Input,дРД Decoder ЕФ Input,жЛга BEGIN етИіЬиБ№ЕФЗћКХ,ЯждкЫќГ§СЫ BEGIN вдЭт,ЫќЛЙгаЁАЛњЁБзїщЫќЕФ Input
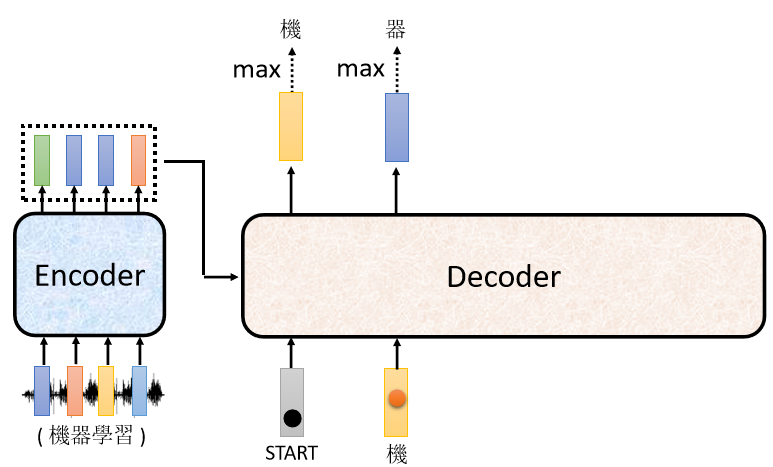
Ыљвд Decoder ЯждкЫќгаСНИіЪфШы
- вЛИіЪЧ BEGIN етИіЗћКХ
- вЛИіЪЧЁАЛњЁБ
ИљОнетСНИіЪфШы,ЫќЪфГівЛИіРЖЩЋЕФЯђСП,ИљОнетИіРЖЩЋЕФЯђСПбeУц,ИјУПвЛИіжаЮФЕФзжЕФЗжЪ§,ЮвУЧЛсОіЖЈЕкЖўИіЪфГі,ФФвЛИізжЕФЗжЪ§зюИп,ЫќОЭЪЧЪфГі,МйЩш"Цї"ЕФЗжЪ§зюИп,"Цї"ОЭЪЧЪфГі
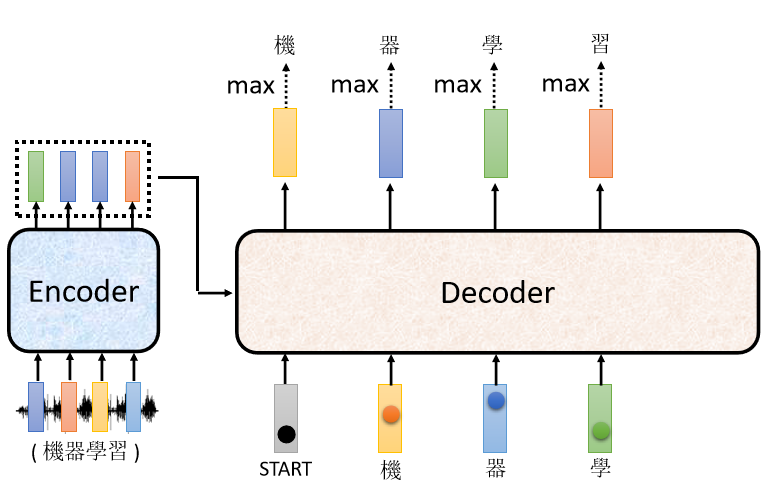
ШЛКѓЯждк Decoder
- ПДЕНСЫ BEGIN
- ПДЕНСЫ"Лњ"
- ПДЕНСЫ"Цї"
ЫќНгЯТРД,ЛЙвЊдйОіЖЈНгЯТРДвЊЪфГіЪВќN,ЫќПЩФм,ОЭЪфГі"бЇ",етвЛИіЙ§ГЬОЭЗДИВЕФГжајЯТШЅ
ЫљвдЯждк Decode
- ПДЕНСЫ BEGIN
- ПДЕНСЫ"Лњ"
- ПДЕНСЫ"Цї"
- ЛЙга"бЇ"
Encoder етБпЦфЪЕвВгаЪфШы,ЕШвЛЯТдйНВ Encoder ЕФЪфШы,Decoder ЪЧдѕќNДІРэЕФ,
Ыљвд Decoder ПДЕН Encoder етБпЕФЪфШы,ПДЕН"Лњ" ПДЕН"Цї" ПДЕН"бЇ",ОіЖЈНгЯТРДЪфГівЛИіЯђСП,етИіЯђСПбeУц,ЁАЯА"етИіжаЮФзжЕФЗжЪ§зюИпЕФ,ЫљвдЫќОЭЪфГі"ЯАЁБ
ШЛКѓетИі Process ,ОЭЗДИВГжајЯТШЅ,етБпгавЛИіЙиМќЕФЕиЗН,ЮвУЧЬиБ№гУКьЩЋЕФащЯпАбЫќБъГіРД
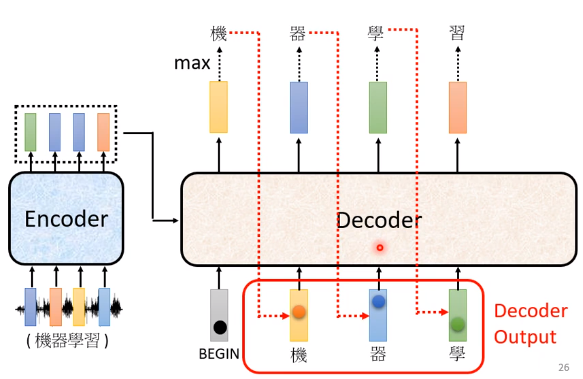
вВОЭЪЧЫЕ Decoder ПДЕНЕФЪфШы,ЦфЪЕЪЧЫќдкЧАвЛИіЪБМфЕу,здМКЕФЪфГі**,Decoder ЛсАбздМКЕФЪфГі,ЕБзіНгЯТРДЕФЪфШы**
ШчЙћDecoder ПДЕНДэЮѓЕФЪфШы,ШУ Decoder ПДЕНздМКЎaЩњГіРДЕФДэЮѓЕФЪфШы,дйБЛ Decoder здМКГдНјШЅ,ЛсВЛЛсдьГЩ Error Propagation ЕФЮЪЬт
Error Propagation ЕФЮЪЬтОЭЪЧ,вЛВНДэ ВНВНДэетбљ,ОЭЪЧдкетИіЕиЗН,ШчЙћВЛаЁаФАбЛњЦїЕФЁАЦїЁБ,ВЛаЁаФаДГЩЬьЦјЕФ"Цј",ЛсВЛЛсНгЯТРДОЭећИіОфзгЖМЛЕЕєСЫ,ЖМУЛгаАьЗЈдйЎaЩње§ШЗЕФДЪЛуСЫ?
гаПЩФм,етИіЕШвЛЯТ,ЮвУЧзюКѓЛсЩдЮЂНВвЛЯТ,етИіЮЪЬтвЊдѕќNДІРэ,ЮвУЧЯждк,ЯШЮоЪгетИіЮЪЬт,МЬајзпЯТШЅ
ЮвУЧРДПДвЛЯТетИі DecoderФкВПЕФНсЙЙГЄЪВќNбљзг
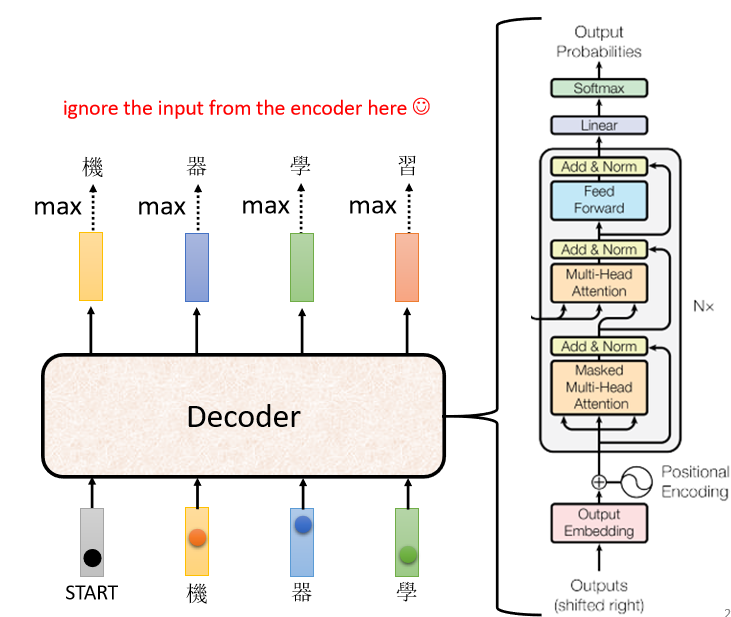
ФЧЮвУЧетБп,Аб Encoder ЕФВПЗжЯШднЪБЪЁТдЕє,ФЧдк Transformer бeУц,Decoder ЕФНсЙЙ,ГЄЕУЪЧетИібљзгЕФ,ПДЦ№РДгаЕуИДдг,БШ Encoder ЛЙЩдЮЂИДдгвЛЕу,
ФЧЮвУЧЯждкЯШАб Encoder Ињ Decoder ЗХдквЛЦ№
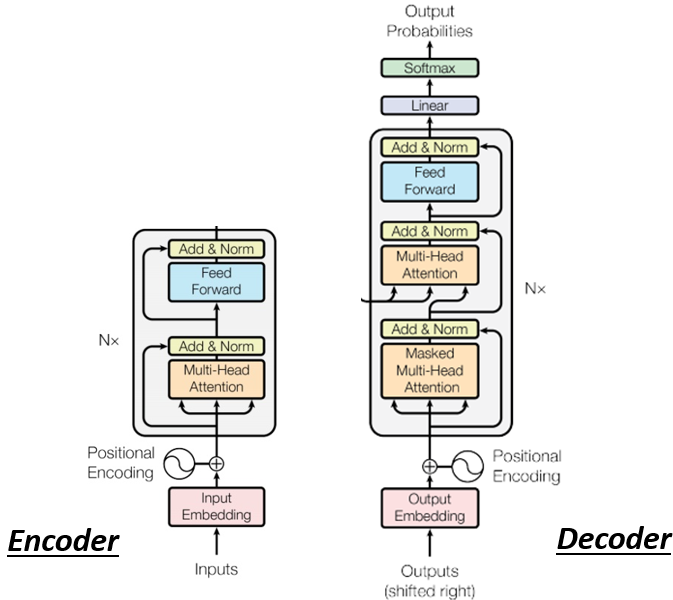
ЩдЮЂБШНЯвЛЯТЫќУЧжЎМфЕФВювь,ФЧФуЛсЗЂЯжЫЕ,ШчЙћЮвУЧАб Decoder жаМфетвЛПщ**,жаМфетвЛПщАбЫќИЧЦ№РД,ЦфЪЕ Encoder Ињ Decoder,ВЂУЛгаФЧќNДѓЕФВюБ№**
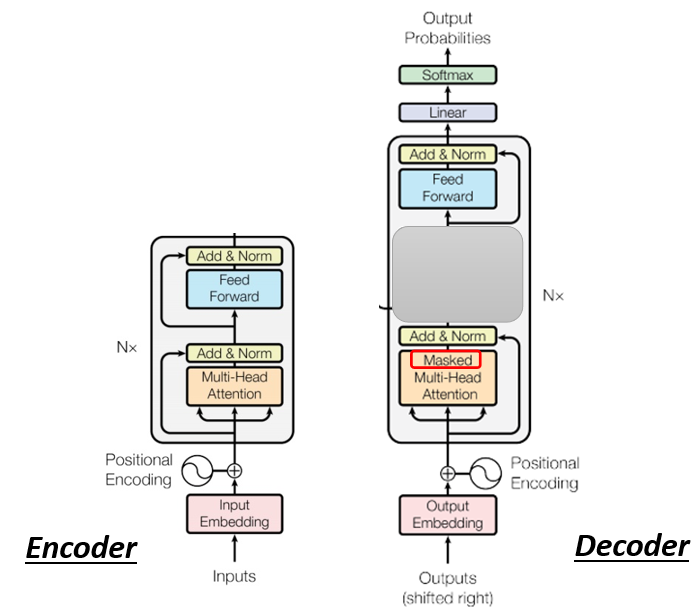
ФуПД Encoder етБп,Multi-Head Attention,ШЛКѓ Add & Norm,Feed Forward,Add & Norm,жиИД N ДЮ,Decoder ЦфЪЕвВЪЧвЛбљ
ЕБЮвУЧАбжаМфетвЛПщекЦ№РДвдКѓ,ЮвУЧЕШвЛЯТдйНВ,екЦ№РДетвЛПщбeУцзіСЫЪВќNЪТ,ЕЋЕБЮвУЧАбжаМфетПщекЦ№РДвдКѓ,G ФЧ Decoder вВЪЧ,гавЛИі Multi-Head Attention,Add & Norm,ШЛКѓ Feed Forward,ШЛКѓ Add & Norm,Ыљвд Encoder Ињ Decoder,ЦфЪЕВЂУЛгаЗЧГЃДѓЕФВюБ№,Г§СЫжаМфетвЛПщВЛвЛбљЕФЕиЗН,
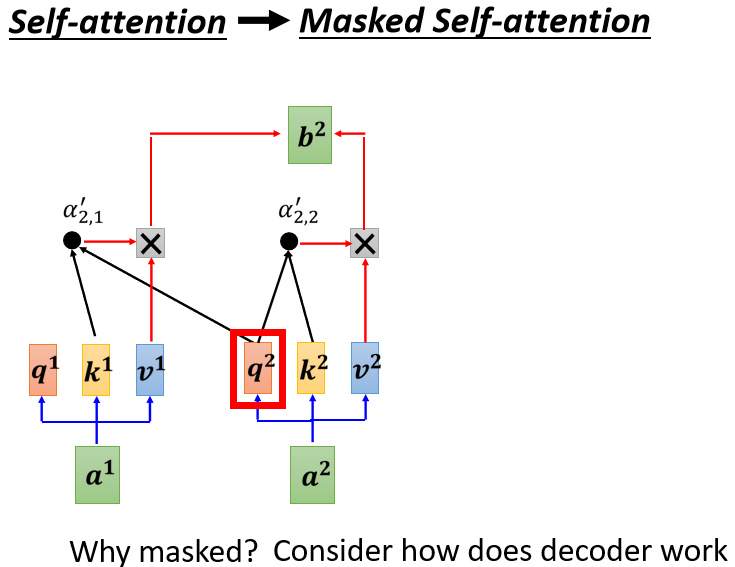
ФЧжЛЪЧзюКѓ,ЮвУЧПЩФмЛсдйзівЛИі Softmax,ЪЙЕУЫќЕФЪфГіБфГЩвЛИіЛњТЪ,ФЧетБпгавЛИіЩдЮЂВЛвЛбљЕФЕиЗНЪЧ,дк Decoder етБп,Multi-Head Attention етвЛИі Block ЩЯУц,ЛЙМгСЫвЛИі Masked,
етИі Masked ЕФвтЫМЪЧетбљзгЕФ,етЪЧЮвУЧдРДЕФ Self-Attention
Input вЛХХ Vector,Output СэЭтвЛХХ Vector,етвЛХХ Vector УПвЛИіЪфГі,ЖМвЊПДЙ§ЭъећЕФ Input вдКѓ,ВХзіОіЖЈ,ЫљвдЪфГі
b
1
b_1
b1? ЕФЪБКђ,ЦфЪЕЪЧИљОн
a
1
a_1
a1? ЕН
a
4
a_4
a4? ЫљгаЕФзЪбЖ,ШЅЪфГі
b
1
b_1
b1?
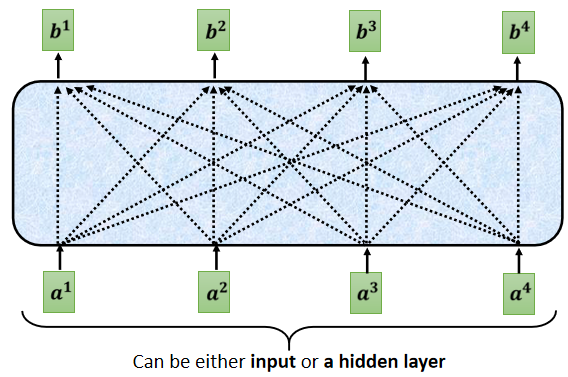
ЕБЮвУЧАб Self-Attention,зЊГЩ Masked Attention ЕФЪБКђ,ЫќЕФВЛЭЌЕуЪЧ,ЯждкЮвУЧВЛФмдйПДгвБпЕФВПЗж,вВОЭЪЧЎaЩњ b 1 b_1 b1? ЕФЪБКђ,ЮвУЧжЛФмПМТЧ a 1 a_1 a1? ЕФзЪбЖ,ФуВЛФмЙЛдйПМТЧ a 2 a_2 a2? a 3 a_3 a3? a 4 a_4 a4?
ЎaЩњ b 2 b_2 b2? ЕФЪБКђ,ФужЛФмПМТЧ a 1 a_1 a1? a 2 a_2 a2? ЕФзЪбЖ,ВЛФмдйПМТЧ a 3 a_3 a3? a 4 a_4 a4? ЕФзЪбЖ
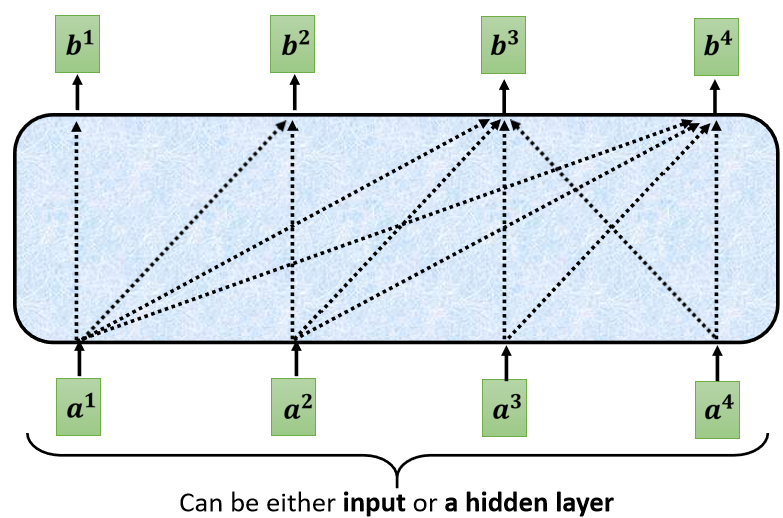
ЎaЩњ b 3 b_3 b3?ЕФЪБКђ,ФуОЭВЛФмПМТЧ a 4 a_4 a4? ЕФзЪбЖ,
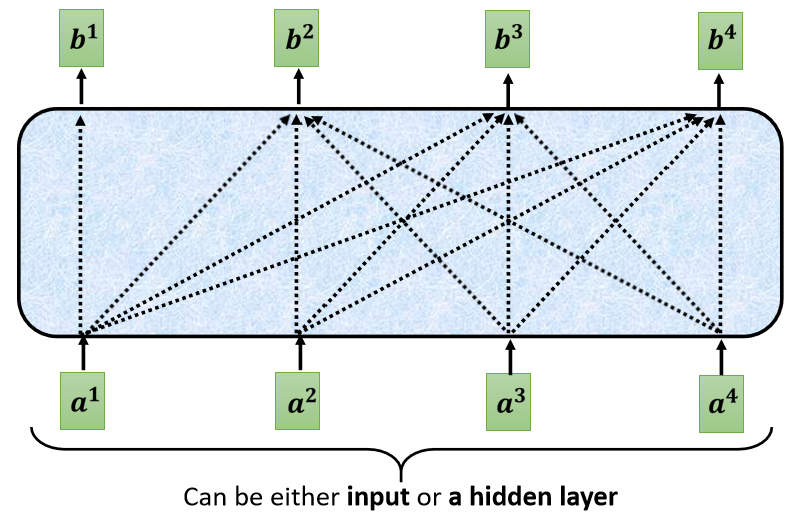
ЎaЩњ b 4 b_4 b4? ЕФЪБКђ,ФуПЩвдгУећИі Input Sequence ЕФзЪбЖ,етИіОЭЪЧ Masked ЕФ Self-Attention,
НВЕУИќОпЬхвЛЕу,ФузіЕФЪТЧщЪЧ,ЕБЮвУЧвЊЎaЩњ b 2 b_2 b2? ЕФЪБКђ,ЮвУЧжЛФУЕкЖўИіЮЛжУЕФ Query b 2 b_2 b2? ,ШЅИњЕквЛИіЮЛжУЕФ Key,КЭЕкЖўИіЮЛжУЕФ Key,ШЅМЦЫу Attention,ЕкШ§ИіЮЛжУИњЕкЫФИіЮЛжУ,ОЭВЛЙмЫќ,ВЛШЅМЦЫу Attention
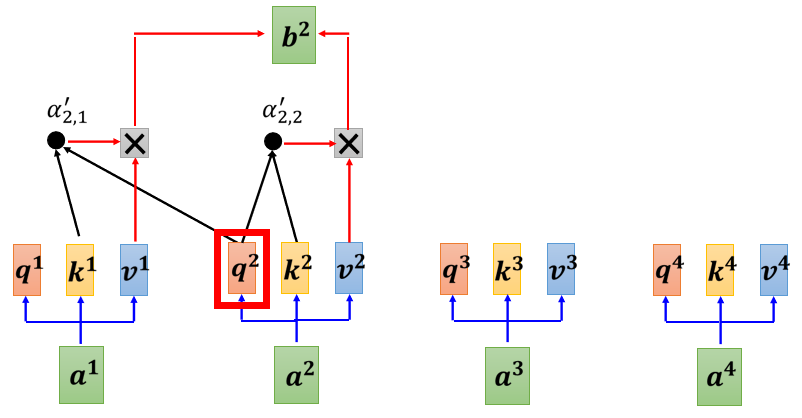
ЮвУЧетбљзгВЛШЅЙметИі a 2 a_2 a2? гвБпЕФЕиЗН,жЛПМТЧ a 1 a_1 a1? Ињ a 2 a_2 a2? ,жЛПМТЧ q 1 q^1 q1 q 2 q^2 q2,жЛПМТЧ k 1 k^1 k1 k 2 k^2 k2, q 2 q^2 q2 жЛИњ k 1 k^1 k1 Ињ k 2 k^2 k2 ШЅМЦЫу Attention,ШЛКѓзюКѓжЛМЦЫу Ињ ЕФ Weighted Sum
ШЛКѓЕБЮвУЧЪфГіетИі b 2 b_2 b2? ЕФЪБКђ, ОЭжЛПМТЧСЫ a 1 a_1 a1? Ињ a 2 a_2 a2?,ОЭУЛгаПМТЧЕН a 3 a_3 a3? Ињ a 4 a_4 a4?
ФЧщЪВќNЛсетбљ,щЪВќNашвЊМг Masked
етМўЪТЧщЦфЪЕЗЧГЃЕижБОѕ:ЮвУЧвЛПЊЪМ Decoder ЕФдЫзїЗНЪН,ЫќЪЧвЛИівЛИіЪфГі,ЫљвдЪЧЯШга
a
1
a_1
a1? дйга
a
2
a_2
a2? ,дйга
a
3
a_3
a3? дйга
a
4
a_4
a4?
етИњдРДЕФ Self-Attention ВЛвЛбљ,дРДЕФ Self-Attention,
a
1
a_1
a1?Ињ
a
4
a_4
a4? ЪЧвЛДЮећИіЪфНјШЅФуЕФ Model бeУцЕФ,дкЮвУЧНВ Encoder ЕФЪБКђ,Encoder ЪЧвЛДЮАб
a
1
a_1
a1?Ињ
a
4
a_4
a4?,ЖМећИіЖМЖСНјШЅ
ЕЋЪЧЖд Decoder Жјбд,ЯШга a 1 a_1 a1? дйга a 2 a_2 a2? ,дйга a 3 a_3 a3? дйга a 4 a_4 a4? ,ЫљвдЪЕМЪЩЯ,ЕБФуга a 2 a_2 a2? ,ФувЊМЦЫу b 2 b_2 b2? ЕФЪБКђ,ФуЪЧУЛга a 3 a_3 a3? Ињ a 4 a_4 a4?ЕФ,ЫљвдФуИљБООЭУЛгаАьЗЈАб a 3 a_3 a3? a 4 a_4 a4? ПМТЧНјРД
ЫљвдетОЭЪЧщЪВќN,дкФЧИі Decoder ЕФФЧИіЭМЩЯУц,Transformer дЪМЕФ Paper ЬиБ№ИњФуЧПЕїЫЕ,ФЧВЛЪЧвЛИівЛАуЕФ Attention,етЪЧвЛИі Masked ЕФ Self-Attention,втЫМжЛЪЧЯывЊИцЫпФуЫЕ,Decoder ЫќЕФ Tokent,ЫќЪфГіЕФЖЋЮїЪЧвЛИівЛИіЎaЩњЕФ,ЫљвдЫќжЛФмПМТЧЫќзѓБпЕФЖЋЮї,ЫќУЛгаАьЗЈПМТЧЫќгвБпЕФЖЋЮї
НВСЫ Decoder ЕФдЫзїЗНЪН,ЕЋЪЧетБп,ЛЙгавЛИіЗЧГЃЙиМќЕФЮЪЬт,Decoder БиаыздМКОіЖЈ,ЪфГіЕФ Sequence ЕФГЄЖШ
ПЩЪЧЕНЕзЪфГіЕФ Sequence ЕФГЄЖШгІИУЪЧЖрЩй,ЮвУЧВЛжЊЕР
ФуУЛгаАьЗЈЧсвзЕФДгЪфШыЕФ Sequence ЕФГЄЖШ,ОЭжЊЕРЪфГіЕФ Sequence ЕФГЄЖШЪЧЖрЩй,ВЂВЛЪЧЫЕ,ЪфШыЪЧ 4 ИіЯђСП,ЪфГівЛЖЈОЭЪЧ 4 ИіЯђСП
етБпдкетИіР§згбeУц,ЪфШыИњЪфГіЕФГЄЖШЪЧвЛбљЕФ,ЕЋЪЧФужЊЕРЪЕМЪЩЯдкФуеце§ЕФгІгУбeУц,ВЂВЛЪЧетбљ,ЪфШыИњЪфГіГЄЖШЕФЙиS,ЪЧЗЧГЃИДдгЕФ,ЮвУЧЦфЪЕЪЧЦкД§ЛњЦїПЩвдздМКбЇЕН,НёЬьИјЫќвЛИі Input Sequence ЕФЪБКђ,Output ЕФ Sequence гІИУвЊЖрГЄ
ЕЋдкЮвУЧФПЧАЕФетећИі DecoderЕФетИідЫзїЕФЛњжЦбeУц,ЛњЦїВЛжЊЕРЫќЪВќNЪБКђгІИУЭЃЯТРД,ЫќЎaЩњЭъЯАвдКѓ,ЫќЛЙПЩвдМЬајжиИДвЛФЃвЛбљЕФ Process,ОЭАбЯА,ЕБзіЪфШы,ШЛКѓвВаэ Decoder ,ОЭЛсНгвЛИіЙп,ШЛКѓНгЯТРД,ОЭвЛжБГжајЯТШЅ,гРдЖЖМВЛЛсЭЃЯТРД
етОЭШУЮвЯыЕНЭЦЮФНгСњ

ЮвВЛжЊЕРДѓМвжЊВЛЕНетЪЧЪВќN,етЪЧвЛИіетИіЙХРЯЕФУёЫзДЋЭГ,СїДЋдк PTT ЩЯУц,етИіУёЫзДЋЭГЪЧдѕќNдЫзїЕФ,ОЭгавЛИіШЫ,ЯШЭЦвЛИіжаЮФзж,ШЛКѓЭЦвЛИіГЌ,ШЛКѓНгЯТРД,ОЭЛсгаСэЭтвЛИіЯчУё,ШЅЭЦСэЭтвЛИізж,ШЛКѓПЩвдНгЩЯШЅЕФ,ЫљвдОЭПЩвдЎaЩњвЛХХЕФДЪЛуРВ,вЛХХзжРВ,ОЭЪЧГЌШЫе§ДѓжаЬьЭтЗЩЯЩВн,ВЛжЊЕРдкЫЕаЉЪВќN,етИіЪЧ Process ,ПЩвдГжајКУМИИідТ,ЖМВЛЭЃЯТРД,ЮввВВЛжЊЕРщЪВќN,ФЧдѕќNШУетИі Process ЭЃЯТРД,ФЧвЊдѕќNШУЫќЭЃЯТРД
вЊгаШЫУАЯеШЅЭЦвЛИіЖЯ,ЭЦИіЖЯ,ЫќОЭЭЃЯТРДСЫ
ЫљвдЮвУЧвЊШУ Decoder зіЕФЪТЧщ,вВЪЧвЛбљ,вЊШУЫќПЩвдЪфГівЛИіЖЯ,ЫљвдФувЊЬиБ№ЪБИвЛИіЬиБ№ЕФЗћКХ,етИіЗћКХ,ОЭНазіЖЯ,ЮвУЧетБп,гУ END РДБэЪОетИіЬиЪтЕФЗћКХ
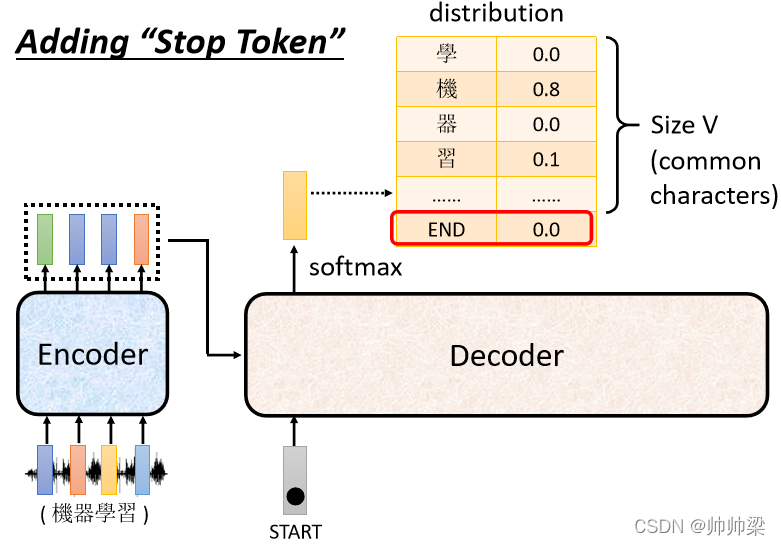
ЫљвдГ§СЫЫљгажаЮФЕФЗНПщзж,ЛЙга BEGIN вдЭт,ФуЛЙвЊЪБИвЛИіЬиЪтЕФЗћКХ,Назі"ЖЯ",ФЧЦфЪЕдкжњНЬЕФГЬЪНбeУц,ЫќЪЧАб BEGIN Ињ END,ОЭЪЧПЊЪМИњетИіЖЯ,гУЭЌвЛИіЗћКХРДБэЪО
ЗДе§етИі,етИі BEGIN жЛЛсдкЪфШыЕФЪБКђГіЯж,ЖЯжЛЛсдкЪфГіЕФЪБКђГіЯж,ЫљвддкжњНЬЕФГЬЪНбeУц,ШчЙћФузаЯИбаОПвЛЯТЕФЛА,ЛсЗЂЯжЫЕ END Ињ BEGIN,гУЕФЦфЪЕЪЧЭЌвЛИіЗћКХ,ЕЋФугУВЛЭЌЕФЗћКХ,вВЪЧЭъШЋПЩвдЕФ,вВЭъШЋУЛгаЮЪЬт
ЫљвдЮвУЧЯждк,ЕБАб"ЯА"ЕБзїЪфШывдКѓ,ОЭ Decoder ПДЕН Encoder ЪфГіЕФетИі Embedding,ПДЕНСЫ ЁАBEGINЁБ,ШЛКѓ"Лњ" ЁАЦїЁБ ЁАбЇЁБ "ЯА"вдКѓ,ПДЕНетаЉзЪбЖвдКѓ ЫќвЊжЊЕРЫЕ,етИігявєБцЪЖЕФНсЙћвбОНсЪјСЫ,ВЛашвЊдйЎaЩњИќЖрЕФДЪЛуСЫ
ЫќЎaЩњГіРДЕФЯђСПEND,ОЭЪЧЖЯЕФФЧИіЗћКХ,ЫќЕФЛњТЪБиаывЊЪЧзюДѓЕФ,ШЛКѓФуОЭЪфГіЖЯетИіЗћКХ,ФЧећИідЫзїЕФЙ§ГЬ,ећИі Decoder ЎaЩњ Sequence ЕФЙ§ГЬ,ОЭНсЪјСЫ
етИіОЭЪЧ Autoregressive Decoder,ЫќдЫзїЕФЗНЪН
Decoder ЈC Non-autoregressive (NAT)
гУСНвГЭЖгАЦЌ,ЗЧГЃМђЖЬЕиНВвЛЯТ,Non-Autoregressive ЕФ Model
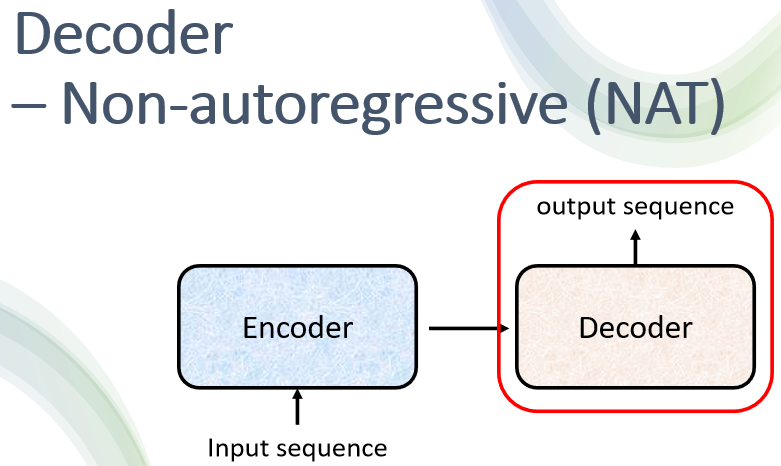
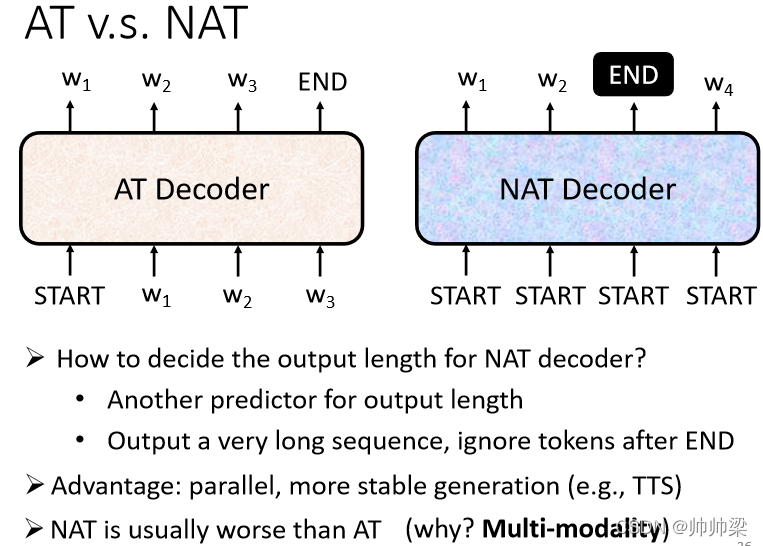
Non-Autoregressive ,ЭЈГЃЫѕаДГЩ NAT,ЫљвдгаЪБКђ Autoregressive ЕФ Model,вВЫѕаДГЩ AT,Non-Autoregressive ЕФ Model ЪЧдѕќNдЫзїЕФ
AT v.s. NAT
етИі Autoregressive ЕФ Model ЪЧ
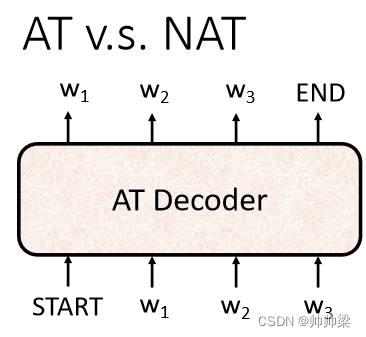
ЯШЪфШы BEGIN,ШЛКѓГіЯж w1,ШЛКѓдйАб w1 ЕБзіЪфШы,дйЪфГі w2,жБЕНЪфГі END щжЙ
ФЧ NAT ЪЧетбљ,ЫќВЛЪЧвРДЮЎaЩњ
ОЭМйЩшЮвУЧЯждкЎaЩњЪЧжаЮФЕФОфзг,ЫќВЛЪЧвРДЮЎaЩњвЛИізж,ЫќЪЧвЛДЮАбећИіОфзгЖМЎaЩњГіРД
NAT ЕФ DecoderПЩФмГдЕФЪЧвЛећХХЕФ BEGIN ЕФ Token ,ФуОЭАбвЛЖбвЛХХ BEGIN ЕФ Token ЖМЖЊИјЫќ,ШУЫќвЛДЮЎaЩњвЛХХ Token ОЭНсЪјСЫ
ОйР§РДЫЕ,ШчЙћФуЖЊИјЫќ 4 Иі BEGIN ЕФ Token,ЫќОЭЎaЩњ 4 ИіжаЮФЕФзж,БфГЩвЛИіОфзг,ОЭНсЪјСЫ,ЫљвдЫќжЛвЊвЛИіВНжш,ОЭПЩвдЭъГЩОфзгЕФЩњГЩ
етБпФуПЩФмЛсЮЪвЛИіЮЪЬт:ИеВХВЛЪЧЫЕВЛжЊЕРЪфГіЕФГЄЖШгІИУЪЧЖрЩйТ№,ФЧЮвУЧетБпдѕќNжЊЕР BEGIN вЊЗХЖрЩйИі ,ЕБзі NAT Decoder ЕФЪеШы?

УЛДэ етМўЪТУЛгаАьЗЈКмздШЛЕФжЊЕР,УЛгаАьЗЈКмжБНгЕФжЊЕР,ЫљвдгаМИИі,ЫљвдгаМИИізіЗЈ
- вЛИізіЗЈЪЧ,ФуСэЭтlearnвЛИі Classifier,етИі Classifier ,ЫќГд Encoder ЕФ Input,ШЛКѓЪфГіЪЧвЛИіЪ§зж,етИіЪ§зжДњБэ Decoder гІИУвЊЪфГіЕФГЄЖШ,етЪЧвЛжжПЩФмЕФзіЗЈ
- СэвЛжжПЩФмзіЗЈОЭЪЧ,ФуОЭВЛЙмШ§ЦпЖўЪЎвЛ,ИјЫќвЛЖб BEGIN ЕФ Token,ФуОЭМйЩшЫЕ,ФуЯждкЪфГіЕФОфзгЕФГЄЖШ,ОјЖдВЛЛсГЌЙ§ 300 Иізж,ФуОЭМйЩшвЛИіОфзгГЄЖШЕФЩЯЯо,ШЛКѓ BEGIN ,ФуОЭИјЫќ 300 Иі BEGIN,ШЛКѓОЭЛсЪфГі 300 ИізжТя,ШЛКѓ,ФудйПДПДЪВќNЕиЗНЪфГі END,ЪфГі END гвБпЕФ,ОЭЕБзіЫќУЛгаЪфГі,ОЭНсЪјСЫ,етЪЧСэЭтвЛжжДІРэ NAT ЕФетИі Decoder,ЫќгІИУЪфГіЕФГЄЖШЕФЗНЗЈ
ФЧ NAT ЕФ Decoder,ЫќгаЪВќNбљЕФКУДІ,
- ЫќЕквЛИіКУДІЪЧ,ВЂааЛЏ,етИі AT ЕФ Decoder,ЫќдкЪфГіЫќЕФОфзгЕФЪБКђ,ЪЧвЛИівЛИівЛИізжЎaЩњЕФ,ЫљвдФугаФуЕФ,МйЩшвЊЪфГіГЄЖШвЛАйИізжЕФОфзг,ФЧФуОЭашвЊзівЛАйДЮЕФ Decode
ЕЋЪЧ NAT ЕФ Decoder ВЛЪЧетбљ,ВЛЙмОфзгЕФГЄЖШШчКЮ,ЖМЪЧвЛИіВНжшОЭЎaЩњГіЭъећЕФОфзг,ЫљвддкЫйЖШЩЯ,NAT ЕФ Decoder ЫќЛсХмЕУБШ,AT ЕФ Decoder вЊПь,ФЧФуПЩвдЯыЯёЫЕ,етИі NAT Decoder ЕФЯыЗЈЯдШЛЪЧдк,гЩетИі Transformer вдКѓ,гаетжж Self-Attention ЕФ Decoder вдКѓВХгаЕФ
вђщвдЧАШчЙћФуЪЧгУФЧИіLSTM ,гУ RNNЕФЛА,ФЧФуОЭЫуИјЫќвЛХХ BEGIN,ЫќвВУЛгаАьЗЈЭЌЪБЎaЩњШЋВПЕФЪфГі,ЫќЕФЪфГіЛЙЪЧвЛИівЛИіЎaЩњЕФ,ЫљвддкУЛгаетИі Self-Attention жЎЧА,жЛга RNN,жЛга LSTM ЕФЪБКђ,ИљБООЭВЛЛсгаШЫЯывЊзіЪВќN NAT ЕФ Decoder,ВЛЙ§здДггаСЫ Self-Attention вдКѓ,ФЧ NAT ЕФ Decoder,ЯждкОЭЫуЪЧвЛИіШШУХЕФбаОПЕФжїЬтСЫ
- ФЧ NAT ЕФ Decoder ЛЙгаСэЭтвЛИіКУДІОЭЪЧ,ФуБШНЯФмЙЛПижЦЫќЪфГіЕФГЄЖШ,ОйгявєКЯГЩщР§,ЦфЪЕдкгявєКЯГЩбeУц,NAT ЕФ Decoder ЫуЪЧЗЧГЃГЃгУЕФ,ЫќВЂВЛЪЧвЛИіЪВќNЯЁКБ КБМћЕФеаЪ§
БШШчЫЕга,ЫљвдгявєКЯГЩНёЬьФуЖМПЩвдгУ,Sequence To Sequence ЕФФЃаЭРДзі,ФЧзюжЊУћЕФ,ЪЧвЛИіНазі Tacotron ЕФФЃаЭ,ФЧЫќЪЧ AT ЕФ Decoder
ФЧгаСэЭтвЛИіФЃаЭНа FastSpeech,ФЧЫќЪЧ NAT ЕФ Decoder,ФЧ NAT ЕФ Decoder гавЛИіКУДІ,ОЭЪЧФуПЩвдПижЦФуЪфГіЕФГЄЖШ,ФЧЮвУЧИеВХЫЕдѕќNОіЖЈ,NAT ЕФ Decoder ЪфГіЖрГЄ
ФуПЩФмгавЛИі Classifier,ОіЖЈ NAT ЕФ Decoder гІИУЪфГіЕФГЄЖШ,ФЧШчЙћдкзігявєКЯГЩЕФЪБКђ,МйЩшФуЯждкЭЛШЛЯывЊШУФуЕФЯЕЭГНВПьвЛЕу,МгЫй,ФЧФуОЭАбФЧИі Classifier ЕФ Output Г§вдЖў,ЫќНВЛАЫйЖШОЭБфСНБЖПь,ШЛКѓШчЙћФуЯывЊетИіНВЛАЗХТ§ЫйЖШ,ФЧФуОЭАбФЧИі Classifier ЪфГіЕФФЧИіГЄЖШ,Ыќ Predict ГіРДЕФГЄЖШГЫСНБЖ,ФЧФуЕФетИі Decoder ,ЫЕЛАЕФЫйЖШОЭБфСНБЖТ§
ЫљвдФуПЩвдШчЙћгаетжж NAT ЕФ Decoder,ФЧФуга Explicit ШЅ Model,Output ГЄЖШгІИУЪЧЖрЩйЕФЛА,ФуОЭБШНЯгаЛњЛсШЅПижЦ,ФуЕФ Decoder ЪфГіЕФГЄЖШгІИУЪЧЖрЩй,ФуОЭПЩвдзіжжжжЕФБфЛЏ
NAT ЕФ Decoder,зюНќЫќжЎЫљвдЪЧвЛИіШШУХбаОПжїЬт,ОЭЪЧЫќЫфШЛБэУцЩЯПДЦ№РДгажжжжЕФРїКІжЎДІ,гШЦфЪЧЦНааЛЏЪЧЫќзюДѓЕФгХЪЦ,ЕЋЪЧ NAT ЕФ Decoder ,ЫќЕФ Performance,ЭљЭљЖМВЛШч AT ЕФ Decoder
ЫљвдЗЂЯжгаКмЖрКмЖрЕФбаОПЪдЭМШУ,NAT ЕФ Decoder ЕФ Performance дНРДдНКУ,ЪдЭМШЅБЦНќ AT ЕФ Decoder,ВЛЙ§НёЬьФувЊШУ NAT ЕФ Decoder,Ињ AT ЕФ Decoder Performance вЛбљКУ,ФуБиаывЊгУЗЧГЃЖрЕФ Trick ВХФмЙЛАьЕН,ОЭ AT ЕФ Decoder ЫцБу Train вЛЯТ,NAT ЕФ Decoder ФувЊЛЈКмЖрСІЦј,ВХгаПЩФмИњ AT ЕФ Performance ВюВЛЖр
щЪВќN NAT ЕФ Decoder Performance ВЛКУ,гавЛИіЮЪЬтЮвУЧНёЬьОЭВЛЯИНВСЫ,Назі Multi-Modality ЕФЮЪЬт,ФЧШчЙћФуЯывЊетИіЩюШыСЫНт NAT,ФЧОЭАбжЎЧАЩЯПЮ,жњНЬетИіЩЯПЮВЙГфЕФФкШн,СЌНсhttps://youtu.be/jvyKmU4OM3cЗХдкетБпИјДѓМвВЮПМ

Encoder-Decoder
НгЯТРДОЭвЊНВEncoder Ињ DecoderЫќУЧжаМфЪЧдѕќNДЋЕнзЪбЖЕФСЫ,вВОЭЪЧЮвУЧвЊНВ,ИеВХЮвУЧПЬвтАбЫќекЦ№РДЕФФЧвЛПщ
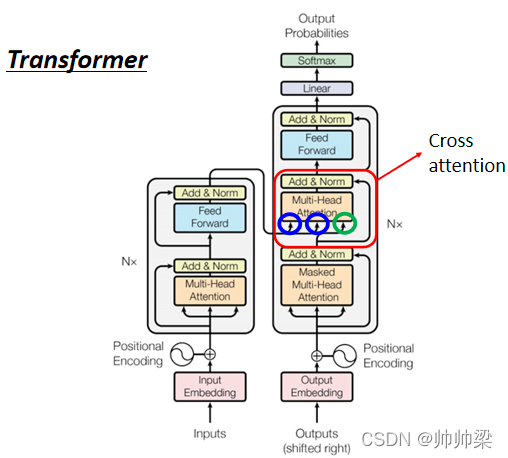
етПщНазі Cross Attention,ЫќЪЧСЌНг Encoder Ињ Decoder жЎМфЕФЧХХ,ФЧетвЛПщбeУцАЁ,ЛсЗЂЯжгаСНИіЪфШыРДздьЖ Encoder,Encoder ЬсЙЉСНИіМ§ЭЗ,ШЛКѓ Decoder ЬсЙЉСЫвЛИіМ§ЭЗ,ЫљвдДгзѓБпетСНИіМ§ЭЗ,Decoder ПЩвдЖСЕН Encoder ЕФЪфГі
ФЧетИіФЃзщЪЕМЪЩЯЪЧдѕќNдЫзїЕФФи,ФЧЮвУЧОЭЪЕМЪАбЫќдЫзїЕФЙ§ГЬИњДѓМвеЙЪОвЛЯТ
етИіЪЧФуЕФ Encoder
ЪфШывЛХХЯђСП,ЪфГівЛХХЯђСП,ЮвУЧНаЫќ
a
1
,
a
2
,
a
3
a_1,a_2,a_3
a1?,a2?,a3?
НгЯТРД ТжЕНФуЕФ Decoder,ФуЕФ Decoder Фи,ЛсЯШГд BEGIN ЕБзі,BEGIN етИі Special ЕФ Token,ФЧ BEGIN етИі Special ЕФ Token ЖСНјРДвдКѓ,ФуПЩФмЛсОЙ§ Self-Attention,етИі Self-Attention ЪЧгазі Mask ЕФ,ШЛКѓЕУЕНвЛИіЯђСП,ОЭЪЧ Self-Attention ОЭЫуЪЧгазі Mask,ЛЙЪЧвЛбљЪфШыЖрЩйГЄЖШЕФЯђСП,ЪфГіОЭЪЧЖрЩйЯђСП
ЫљвдЪфШывЛИіЯђСП ЪфГівЛИіЯђСП,ШЛКѓНгЯТРДАбетИіЯђСПФи,ГЫЩЯвЛИіОиеѓзівЛИі Transform,ЕУЕНвЛИі Query Назі q
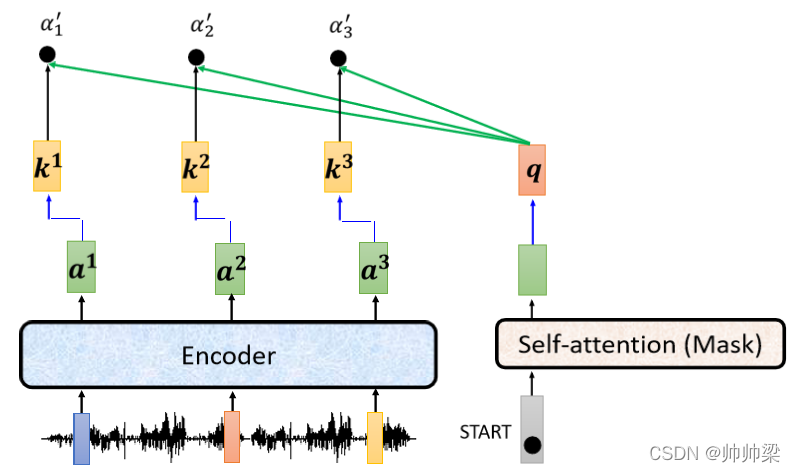
ШЛКѓетБпЕФ a 1 , a 2 , a 3 a_1,a_2,a_3 a1?,a2?,a3? Фи,вВЖМЎaЩњ Key,Key1 Key2 Key3,ФЧАбетИі q Ињ k 1 , k 2 , k 3 k_1,k_2,k_3 k1?,k2?,k3?,ШЅМЦЫу Attention ЕФЗжЪ§,ЕУЕН ІС 1 ІС 2 ІС 3 {\alpha _1} {\alpha _2} {\alpha _3} ІС1?ІС2?ІС3? ,ЕБШЛФуПЩФмвЛбљЛсзі Softmax,АбЫќЩдЮЂзівЛЯТ Normalization,ЫљвдЮветБпМгвЛИі ',ДњБэЫќПЩФмЪЧзіЙ§ Normalization
НгЯТРДдйАб ІС 1 ІС 2 ІС 3 {\alpha _1} {\alpha _2} {\alpha _3} ІС1?ІС2?ІС3? ,ОЭГЫЩЯ v 1 , v 2 , v 3 v_1,v_2,v_3 v1?,v2?,v3? ,дйАбЫќ Weighted Sum МгЦ№РДЛсЕУЕН v
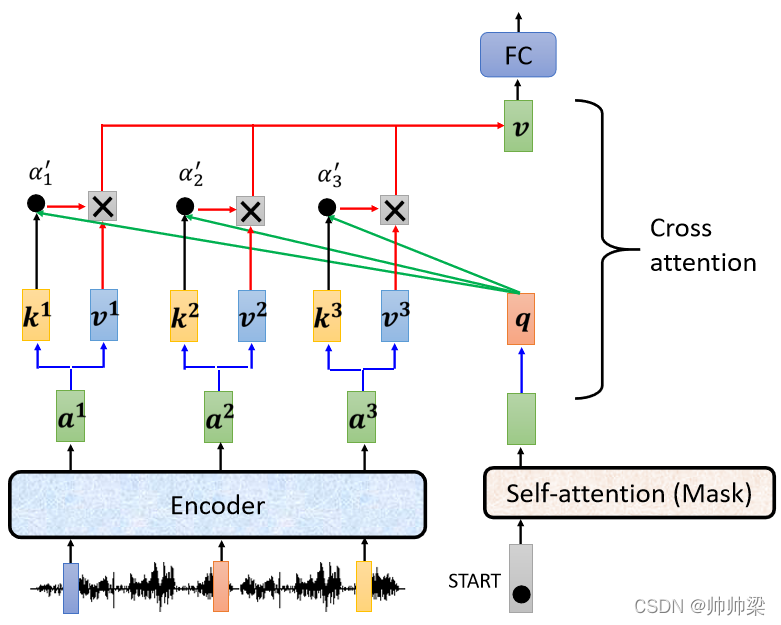
ФЧетвЛИі V,ОЭЪЧНгЯТРДЛсЖЊЕН Fully-Connected ЕФ,Network зіНгЯТРДЕФДІРэ,ФЧетИіВНжшОЭЪЧ q РДздьЖ Decoder,k Ињ v РДздьЖ Encoder,етИіВНжшОЭНазі Cross Attention
Ыљвд Decoder ОЭЪЧЦОНхжјЎaЩњвЛИі q,ШЅ Encoder етБпГщШЁзЪбЖГіРД,ЕБзіНгЯТРДЕФ Decoder ЕФ,Fully-Connected ЕФ Network ЕФ Input
ЕБШЛетИі,ОЭЯждкМйЩшЎaЩњЕкЖўИі,ЕквЛИіетИіжаЮФЕФзжЎaЩњвЛИіЁАЛњЁБ,НгЯТРДЕФдЫзївВЪЧвЛФЃвЛбљЕФ
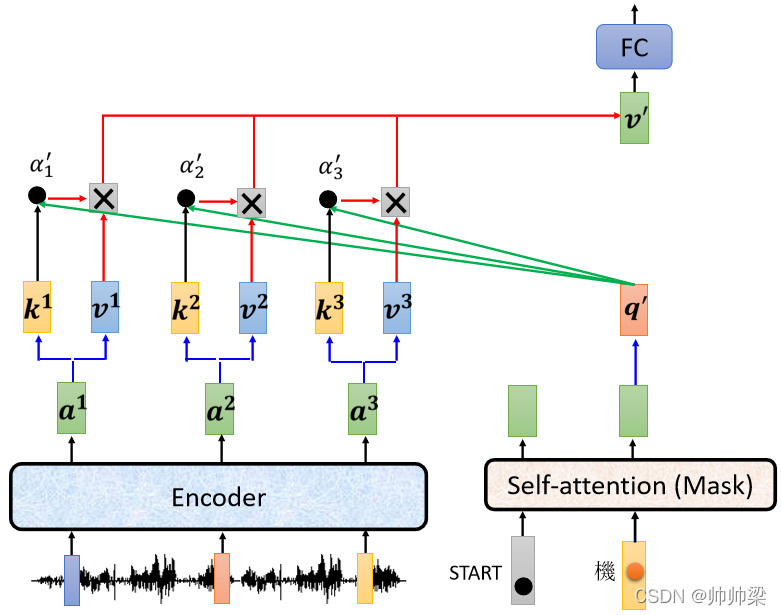
ЪфШы BEGIN ЪфШыЛњ,ЎaЩњвЛИіЯђСП,етИіЯђСПвЛбљГЫЩЯвЛИі Linear ЕФ Transform,ЕУЕН qЁЏ,ЕУЕНвЛИі Query,етИі Query вЛбљИњ ,ШЅМЦЫу Attention ЕФЗжЪ§,вЛбљИњ зі Weighted Sum зіМгШЈ,ШЛКѓМгЦ№РДЕУЕН vЁЏ,НЛИјНгЯТРД Fully-Connected Network зіДІРэ
ЫљвдетОЭЪЧCross Attention ЕФдЫзїЕФЙ§ГЬ
вВаэгаШЫЛсгавЩЮЪ:ФЧетИі Encoder гаКмЖрВуАЁ,Decoder вВгаКмЖрВуАЁ,ДгИеВХЕФНВНтбeУцКУЯёЬ§Ц№РД,етИі Decoder ВЛЙмФФвЛВу,ЖМЪЧФУ Encoder ЕФзюКѓвЛВуЕФЪфГіетбљЖдТ№?
Жд,дкдЪМ Paper бeУцЕФЪЕзіЪЧетбљзг,ФЧвЛЖЈвЊетбљТ№
ВЛвЛЖЈвЊетбљ,ФугРдЖПЩвдздМКЖЕвЛаЉаТЕФЯыЗЈ,ЫљвдЮветБпОЭЪЧв§гУвЛЦЊТлЮФИцЫпФуЫЕ,вВгаШЫГЂЪдВЛЭЌЕФ Cross Attension ЕФЗНЪН
Training (decoder бЕСЗ)
вбОЧхГўЫЕ Input вЛИі Sequence,ЪЧдѕќNЕУЕНзюжеЕФЪфГі,ФЧНгЯТРДОЭНјШыбЕСЗЕФВПЗж
ИеВХНВЕФЖМЛЙжЛЪЧ,МйЩшФуФЃаЭбЕСЗКУвдКѓЫќЪЧдѕќNдЫзїЕФ,ЫќЪЧдѕќNзі Testing ЕФ,ЫќЪЧдѕќNзі Inference ЕФ,Inference ОЭЪЧ Testing ,ФЧЪЧдѕќNзібЕСЗЕФФи?
НгЯТРДОЭвЊНВдѕќNзібЕСЗ,ФЧШчЙћЪЧзігявєБцЪЖ,ФЧФувЊгабЕСЗзЪСЯ,ФувЊЪеМЏвЛДѓЖбЕФЩљвєбЖКХ,УПвЛОфЩљвєбЖКХЖМвЊгаЙЄЖСЩњРДЬ§ДђвЛЯТ,ДђГіЫЕЫќЕФетИіЖдгІЕФДЪЛуЪЧЪВќN

ЙЄЖСЩњЬ§етЖЮЪЧЛњЦїбЇЯА,ЫћОЭАбЛњЦїбЇЯАЫФИізжДђГіРД,ЫљвдОЭжЊЕРЫЕФуЕФетИі Transformer,гІИУвЊбЇЕН Ь§ЕНетЖЮЩљвєбЖКХ,ЫќЕФЪфГіОЭЪЧЛњЦїбЇЯАетЫФИіжаЮФзж
ФЧдѕќNШУЛњЦїбЇЕНетМўЪТФи
ЮвУЧвбОжЊЕРЫЕЪфШыетЖЮЩљвєбЖКХ,ЕквЛИігІИУвЊЪфГіЕФжаЮФзжЪЧЁАЛњЁБ,ЫљвдНёЬьЕБЮвУЧАб BEGIN,ЖЊИјетИі Encoder ЕФЪБКђ,ЫќЕквЛИіЪфГігІИУвЊИњЁАЛњЁБдННгНќдНКУ
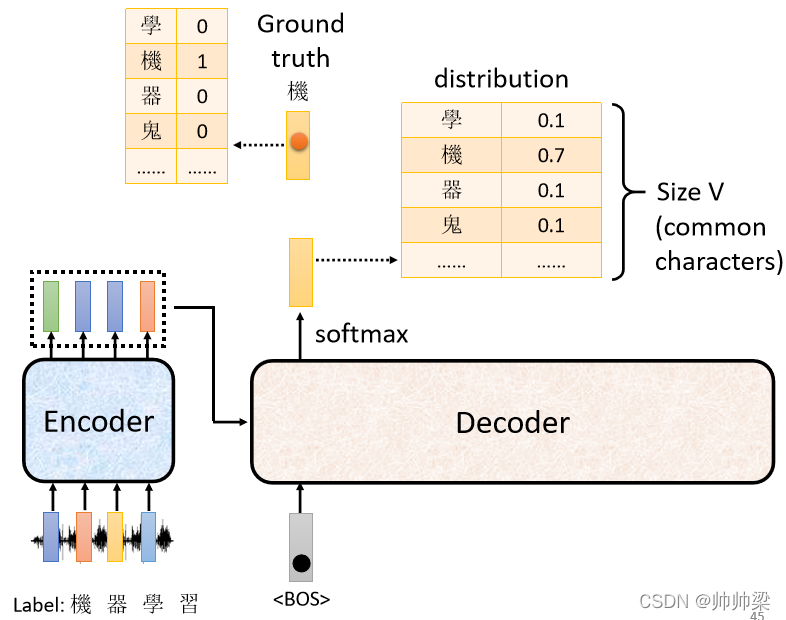
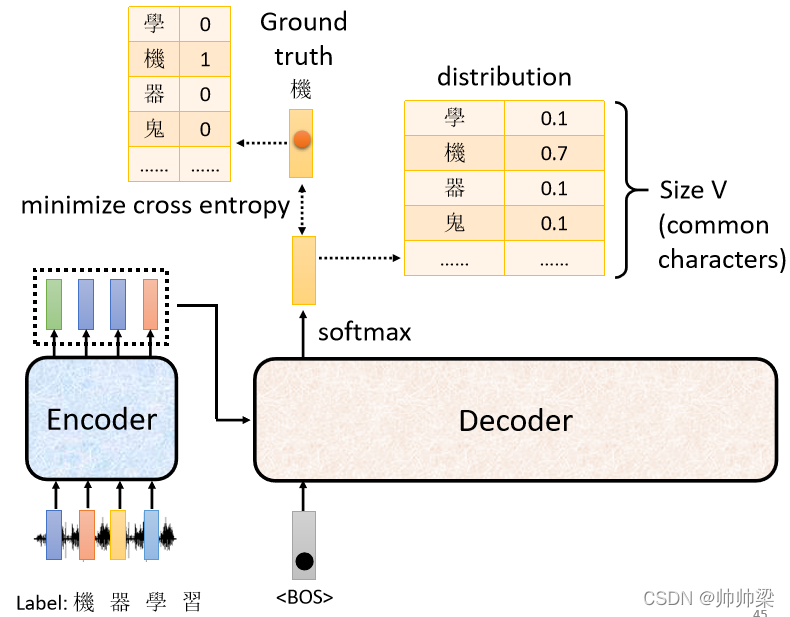
ЁАЛњЁБетИізжЛсБЛБэЪОГЩвЛИі One-Hot ЕФ Vector,дкетИі Vector бeУц,жЛгаЛњЖдгІЕФФЧИіЮЌЖШЪЧ 1,ЦфЫћЖМЪЧ 0,етЪЧе§ШЗД№АИ,ФЧЮвУЧЕФ Decoder,ЫќЕФЪфГіЪЧвЛИі Distribution,ЪЧвЛИіЛњТЪЕФЗжВМ,ЮвУЧЛсЯЃЭћетвЛИіЛњТЪЕФЗжВМ,ИњетИі One-Hot ЕФ Vector дННгНќдНКУ
ЫљвдФуЛсШЅМЦЫуетИі Ground Truth,ИњетИі Distribution ЫќУЧжЎМфЕФ Cross Entropy,ШЛКѓЮвУЧЯЃЭћетИі Cross Entropy ЕФжЕ,дНаЁдНКУ
ЫќОЭИњЗжРрКмЯё,ИеВХжњНЬдкНВНтзївЕЕФЪБКђвВгаЬсЕНетМўЪТЧщ,ФуПЩвдЯыГЩУПвЛДЮЮвУЧдкЎaЩњ,УПвЛДЮ Decoder дкЎaЩњвЛИіжаЮФзжЕФЪБКђ,ЦфЪЕОЭЪЧзіСЫвЛДЮЗжРрЕФЮЪЬт,жаЮФзжМйЩшгаЫФЧЇИі,ФЧОЭЪЧзігаЫФЧЇИіРрБ№ЕФЗжРрЕФЮЪЬт
ЫљвдЪЕМЪЩЯбЕСЗЕФЪБКђетИібљзг,ЮвУЧвбОжЊЕРЪфГігІИУЪЧЁАЛњЦїбЇЯАЁБетЫФИізж,ОЭИцЫпФуЕФ Decoder ,ЯждкФуЕквЛДЮЕФЪфГі ЕкЖўДЮЕФЪфГі,ЕкШ§ДЮЕФЪфГі ЕкЫФДЮЪфГі,гІИУЗжБ№ОЭЪЧЁАЛњЁБ ЁАЦїЁБ ЁАбЇЁБИњЁАЯАЁБ,етЫФИіжаЮФзжЕФ One-Hot Vector,ЮвУЧЯЃЭћЮвУЧЕФЪфГі,ИњетЫФИізжЕФ One-Hot Vector дННгНќдНКУ
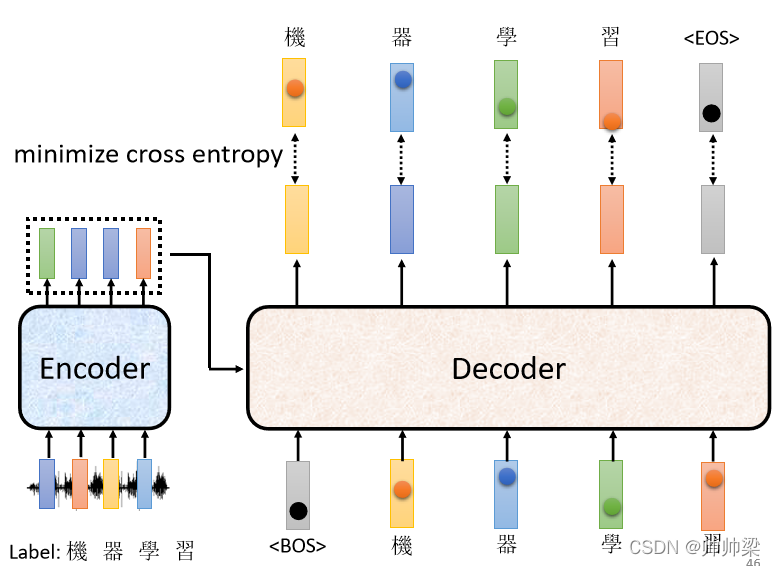
дкбЕСЗЕФЪБКђ,УПвЛИіЪфГіЖМЛсгавЛИі Cross Entropy,УПвЛИіЪфГіИњ One-Hot Vector,ИњЫќЖдгІЕФе§ШЗД№АИЖМгавЛИі Cross Entropy,ЮвУЧвЊЯЃЭћЫљгаЕФ Cross Entropy ЕФзмКЭзюаЁ,дНаЁдНКУ
ЫљвдетБпзіСЫЫФДЮЗжРрЕФЮЪЬт,ЮвУЧЯЃЭћетаЉЗжРрЕФЮЪЬт,ЫќзмКЯЦ№РДЕФ Cross Entropy дНаЁдНКУ,ЛЙга END етИіЗћКХ
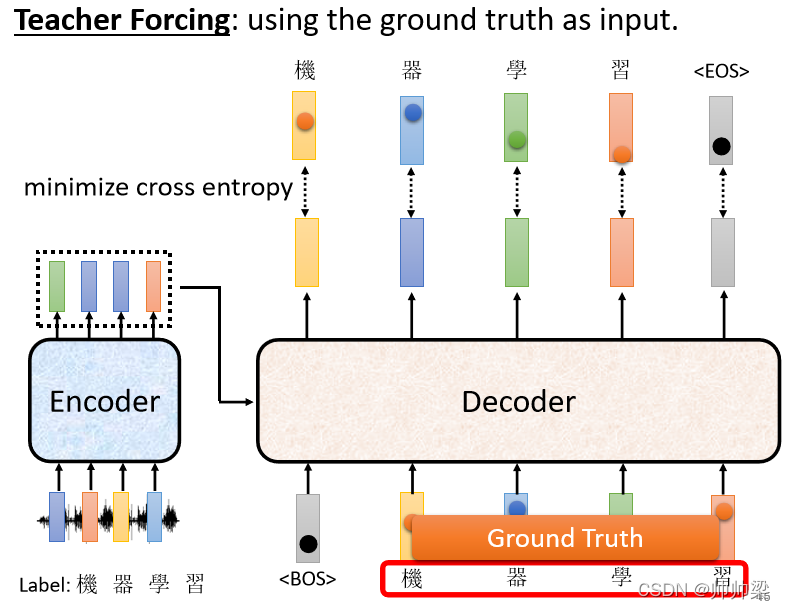
ФЧетИіОЭЪЧ Decoder ЕФбЕСЗ:Аб Ground Truth ,е§ШЗД№АИИјЫќ,ЯЃЭћ Decoder ЕФЪфГіИње§ШЗД№АИдННгНќдНКУ
ФЧетБпгавЛМўжЕЕУЮвУЧзЂвтЕФЪТЧщ,дкбЕСЗЕФЪБКђЮвУЧЛсИј Decoder ПДе§ШЗД№АИ,вВОЭЪЧЮвУЧЛсИцЫпЫќЫЕ
- дквбОга ЁАBEGINЁБ,дкга"Лњ"ЕФЧщПіЯТФуОЭвЊЪфГі"Цї"
- га ЁАBEGINЁБ га"Лњ" га"Цї"ЕФЧщПіЯТЪфГі"бЇ"
- га ЁАBEGINЁБ га"Лњ" га"Цї" га"бЇ"ЕФЧщПіЯТЪфГі"ЯА"
- га ЁАBEGINЁБ га"Лњ" га"Цї" га"бЇ" га"ЯА"ЕФЧщПіЯТ,ФуОЭвЊЪфГі"ЖЯ"
дк Decoder бЕСЗЕФЪБКђ,ЮвУЧЛсдкЪфШыЕФЪБКђИјЫќе§ШЗЕФД№АИ,ФЧетМўЪТЧщНазі Teacher Forcing
ФЧетИіЪБКђФуТэЩЯОЭЛсгавЛИіЮЪЬтСЫ
- бЕСЗЕФЪБКђ,Decoder гаЭЕПДЕНе§ШЗД№АИСЫ
- ЕЋЪЧВтЪдЕФЪБКђ,ЯдШЛУЛгае§ШЗД№АИПЩвдИј Decoder ПД
ИеВХвВгаЧПЕїЫЕдкеце§ЪЙгУетИіФЃаЭ,дк Inference ЕФЪБКђ,Decoder ПДЕНЕФЪЧздМКЕФЪфШы,етжаМфЯдШЛгавЛИі Mismatch,ФЧЕШвЛЯТЮвУЧЛсгавЛвГЭЖгАЦЌЕФЫЕУї,гаЪВќNбљПЩФмЕФНтОіЗНЪН
Tips
ФЧНгЯТРД,ВЛIЯоьЖ Transformer ,НВвЛаЉбЕСЗетжж Sequence To Sequence Model ЕФTips
Copy Mechanism
дкЮвУЧИеВХЕФЬжТлбeУц,ЮвУЧЖМвЊЧѓ Decoder здМКЎaЩњЪфГі,ЕЋЪЧЖдКмЖрШЮЮёЖјбд,вВаэ Decoder УЛгаБивЊздМКДДдьЪфГіГіРД,ЫќашвЊзіЕФЪТЧщ,вВаэЪЧДгЪфШыЕФЖЋЮїбeУцИДбuвЛаЉЖЋЮїГіРД
ЯёетжжИДбuЕФаащдкФФаЉШЮЮёЛсгУЕУЩЯФи,вЛИіР§згЪЧзіСФЬьЛњЦїШЫ

- ШЫЖдЛњЦїЫЕ:ФуКУ ЮвЪЧПтТхТх,
- ЛњЦїгІИУЛиД№ЫЕ:ПтТхТхФуКУ КмИпаЫШЯЪЖФу
ЖдЛњЦїРДЫЕ,ЫќЦфЪЕУЛгаБивЊДДдьПтТхТхетИіДЪЛу,етЖдЛњЦїРДЫЕвЛЖЈЛсЪЧвЛИіЗЧГЃЙжвьЕФДЪЛу,ЫљвдЫќПЩФмКмФб,дкбЕСЗзЪСЯбeУцПЩФмвЛДЮвВУЛгаГіЯжЙ§,ЫљвдЫќВЛЬЋПЩФме§ШЗЕиЎaЩњетЖЮДЪЛуГіРД
ЕЋЪЧМйЩшНёЬьЛњЦїЫќдкбЇЕФЪБКђ,ЫќбЇЕНЕФЪЧПДЕНЪфШыЕФЪБКђЫЕЮвЪЧФГФГФГ,ОЭжБНгАбФГФГФГ,ВЛЙметБпЪЧЪВќNИДбuГіРДЫЕФГФГФГФуКУ
ФЧетбљзгЛњЦїЕФбЕСЗЯдШЛЛсБШНЯШнвз,ЫќЯдШЛБШНЯгаПЩФмЕУЕНе§ШЗЕФНсЙћ,ЫљвдИДбuЖдьЖЖдЛАРДЫЕ,ПЩФмЪЧвЛИіашвЊЕФММЪѕ ашвЊЕФФмСІ
Summarization
ЛђепЪЧдкзіеЊвЊЕФЪБКђ,ФуПЩФмИќашвЊ Copy етбљзгЕФММФм
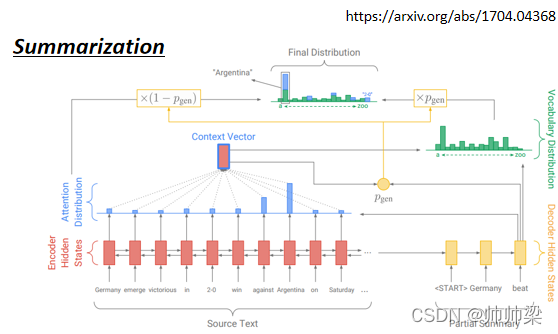
еЊвЊОЭЪЧ,ФувЊбЕСЗвЛИіФЃаЭ,ШЛКѓетИіФЃаЭШЅЖСвЛЦЊЮФеТ,ШЛКѓЎaЩњетЦЊЮФеТЕФеЊвЊ
ФЧетИіШЮЮёЭъШЋЪЧгаАьЗЈзіЕФ,ФуОЭЪЧЪеМЏДѓСПЕФЮФеТ,ФЧУПвЛЦЊЮФеТЖМгаШЫаДЕФеЊвЊ,ШЛКѓФуОЭбЕСЗвЛИі,Sequence-To-Sequence ЕФ Model,ОЭНсЪјСЫ
ФувЊзіетбљЕФШЮЮё,жЛгавЛЕуЕуЕФзЪСЯЪЧзіВЛЦ№РДЕФ,гаЕФЭЌбЇЪеМЏИіМИЭђЦЊЮФеТ,ШЛКѓбЕСЗвЛИіетбљЕФ,Sequence-To-Sequence Model,ЗЂЯжНсЙћгаЕуВю
ФувЊбЕСЗетжж,ФувЊНаЛњЦїЫЕКЯРэЕФОфзг,ЭЈГЃетИіАйЭђЦЊЮФеТЪЧашвЊЕФ,ЫљвдШчЙћФугаАйЭђЦЊЮФеТ,ФЧаЉЮФеТЖМгаШЫБъЕФеЊвЊ,ФЧгаЪБКђФуЛсАб,жБНгАбЮФеТБъЬтЕБзїеЊвЊ,ФЧетбљОЭВЛашвЊЛЈЬЋЖрШЫСІРДБъ,ФуЪЧПЩвдбЕСЗвЛИі,жБНгПЩвдАяФуЖСвЛЦЊЮФеТ,зіИіеЊвЊЕФФЃаЭ
ЖдеЊвЊетИіШЮЮёЖјбд,ЦфЪЕДгЮФеТбeУцжБНгИДбuвЛаЉзЪбЖГіРД,ПЩФмЪЧвЛИіКмЙиМќЕФФмСІ,ФЧ Sequence-To-Sequence Model,гаУЛгаАьЗЈзіЕНетМўЪТФи,ФЧМђЕЅРДЫЕОЭЪЧга,ФЧЮвУЧОЭВЛЛсЯИНВ
зюдчгаДгЪфШыИДбuЖЋЮїЕФФмСІЕФФЃаЭ,Назі Pointer Network

ФЧетИіЙ§ШЅЩЯПЮЪЧгаНВЙ§ЕФ,ЮвАбТМгАЗХдкетБпИјДѓМвВЮПМ,КУ ФЧКѓРДЛЙгавЛИіБфаЮ,Назі Copy Network,ФЧФуПЩвдПДвЛЯТетвЛЦЊ,Copy Mechanism,ОЭЪЧ Sequence-To-Sequence,гаУЛгаЮЪЬт,ФуПД Sequence-To-Sequence Model,ЪЧдѕќNзіЕНДгЪфШыИДбuЖЋЮїЕНЪфГіРДЕФ
Guided Attention
ЛњЦїОЭЪЧвЛИіКкКазг,гаЪБКђЫќбeУцбЇЕНЪВќNЖЋЮї,ФуЪЕдкЪЧИуВЛЧхГў,ФЧгаЪБКђЫќЛсЗИЗЧГЃЕЭМЖЕФДэЮѓ
етБпОйЕФР§згЪЧгявєКЯГЩ
ФуЭъШЋПЩвдОЭЪЧбЕСЗвЛИі,Sequence-To-Sequence ЕФ Model,Transformer ОЭЪЧвЛИіР§зг
- ЪеМЏКмЖрЕФЩљвє,ЮФзжИњЩљвєбЖКХЕФЖдгІЙиS
- ШЛКѓНгЯТРДИцЫпФуЕФ,Sequence-To-Sequence Model ,ПДЕНетЖЮжаЮФЕФОфзг,ФуОЭЪфГіетЖЮЩљвє
- ШЛКѓОЭУЛгаШЛКѓ,ОЭгВ Train вЛЗЂОЭНсЪјСЫ,ШЛКѓЛњЦїОЭПЩвдбЇЛсзігявєКЯГЩСЫ
ЯёетбљЕФЗНЗЈзіГіРДНсЙћ,ЦфЪЕЛЙВЛДэ,

ОйР§РДЫЕЮвНаЛњЦїСЌЫЕ 4 ДЮЗЂВЦ,ПДПДЫќЛсдѕќNНВ,ЛњЦїЪфГіЕФНсЙћЪЧ:ЗЂВЦ ЗЂВЦ ЗЂВЦ ЗЂВЦ
ОЭЗЂЯжКмЩёЦц,ЮвЪфШыЕФЗЂВЦЪЧУїУїЪЧЭЌбљЕФДЪЛу,жЛЪЧжиИД 4 ДЮ,ЛњЦїОгШЛздМКгавЛаЉвжбяЖйДь,ЫќдѕќNбЇЕНетМўЪТ,ВЛжЊЕР,ЫќздМКбЕСЗГіРДОЭЪЧетИібљзг
ФЧФуШУЫќНВ 3 ДЮЗЂВЦвВУЛЮЪЬт,ФЧЫќНВ 2 ДЮЗЂВЦвВУЛЮЪЬт,ШУЫќНВ 1 ДЮЗЂВЦ , ЫќВЛФюЁАЗЂЁБ
ВЛжЊЕРщЪВќNетбљзг,ОЭЪЧФуетИі Sequence-To-Sequence Model,гаЪБКђ Train ГіРДОЭЪЧ,ЛсЎaЩњФЊУћЦфУюЕФНсЙћ,вВаэдкбЕСЗзЪСЯбeУц,етжжЗЧГЃЖЬЕФОфзгКмЩй,ЫљвдЛњЦїВЛжЊЕРвЊдѕќNДІРэетжжЗЧГЃЖЬЕФОфзг,ФуНаЫќФюЗЂВЦ,ЫќАбЗЂЪЁТдЕєжЛФюВЦ,ФуОгШЛНаЫќФю 4 ДЮЕФЗЂВЦ,жиИД 4 ДЮУЛЮЪЬт,НаЫќжЛФювЛДЮ,ОгШЛЛсгаЮЪЬт,ОЭЪЧетќNЕФЦцЙж
ЕБШЛЦфЪЕетИіР§згВЂУЛгаФЧќNГЃГіЯж,ОЭетИігУ Sequence-To-Sequence,Learn ГіРД TTS,вВУЛгаФуЯыЯёЕФФЧќNВю,етИівЊеветжжВюЕФР§згвВЪЧЭІЛЈЪБМфЕФ,вЊЛЈКмЖрЪБМфВХевЕУЕНетжжВюЕФР§зг,ЕЋетбљзгЕФР§згЪЧДцдкЕФ
ЫљвддѕќNАьФи
ЮвУЧИеВХЗЂЯжЫЕЛњЦїОгШЛТЉзжСЫ,ЪфШыгавЛаЉЖЋЮїЫќОгШЛУЛгаПДЕН,ЮвУЧФмВЛФмЙЛЧПЦШЫќ,вЛЖЈвЊАбЪфШыЕФУПвЛИіЖЋЮїЭЈЭЈПДЙ§Фи
етИіЪЧгаПЩФмЕФ,етеаОЭНазі Guided Attention

ЯёгявєБцЪЖетжжШЮЮё,ФуЦфЪЕКмФбНгЪмЫЕ,ФуНВвЛОфЛА,НёЬьБцЪЖГіРД,ОгШЛгавЛЖЮЛњЦїУЛЬ§ЕН,ЛђгявєКЯГЩФуЪфШывЛЖЮЮФзж,гявєКЯГіРДОгШЛгавЛЖЮУЛгаФюЕН,етИіШЫКмФбНгЪм
ФЧШчЙћЪЧЦфЫќгІгУ,БШШчЫЕ Chat Bot,ЛђепЪЧ Summary,ПЩФмОЭУЛгаФЧќNбЯИё,вђщЖдвЛИі Chat Bot РДЫЕ,ЪфШыКѓвЛОфЛА,ЫќОЭЛивЛОфЛА,ЫќЕНЕзгаУЛгаАбећОфЛАПДЭъ,ЦфЪЕФу Somehow вВВЛдкКѕ,ФуЦфЪЕвВИуВЛЧхГў
ЕЋЪЧЖдгявєБцЪЖ гявєКЯГЩ,Guiding Attention,ПЩФмОЭЪЧвЛИіБШНЯживЊЕФММЪѕ
Guiding Attention вЊзіЕФЪТЧщОЭЪЧ,вЊЧѓЛњЦїЫќдкзі Attention ЕФЪБКђ,ЪЧгаЙЬЖЈЕФЗНЪНЕФ,ОйР§РДЫЕ,ЖдгявєКЯГЩЛђепЪЧгявєБцЪЖРДЫЕ,ЮвУЧЯыЯёжаЕФ Attention,гІИУОЭЪЧгЩзѓЯђгв
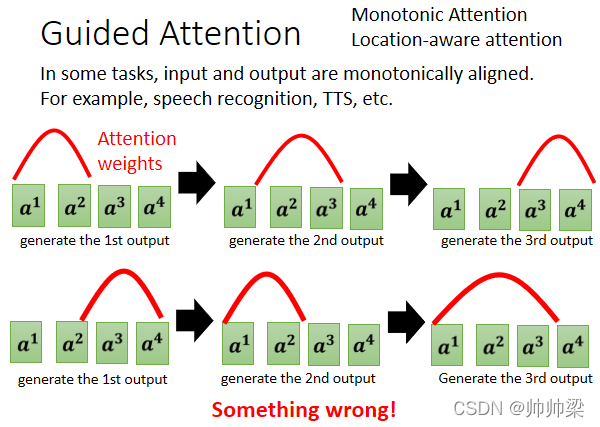
дкетИіР§згбeУц,ЮвУЧгУКьЩЋЕФетИіЧњЯп,РДДњБэ Attention ЕФЗжЪ§,етИідНИпОЭДњБэ Attention ЕФжЕдНДѓ
ЮвУЧвдгявєКЯГЩщР§,ФЧФуЕФЪфШыОЭЪЧвЛДЎЮФзж,ФЧФудкКЯГЩЩљвєЕФЪБКђ,ЯдШЛЪЧгЩзѓФюЕНгв,ЫљвдЛњЦїгІИУЪЧ,ЯШПДзюзѓБпЪфШыЕФДЪЛуЎaЩњЩљвє,дйПДжаМфЕФДЪЛуЎaЩњЩљвє,дйПДгвБпЕФДЪЛуЎaЩњЩљвє
ШчЙћФуНёЬьдкзігявєКЯГЩЕФЪБКђ,ФуЗЂЯжЛњЦїЕФ Attention,ЪЧЕпШ§ЕЙЫФЕФ,ЫќЯШПДзюКѓУц,НгЯТРДдйПДЧАУц,ФЧдйКњТвПДећИіОфзг,ФЧЯдШЛгааЉЪЧзіДэСЫ,ЯдШЛгааЉЪЧ,Something is wrong,гааЉЪЧзіДэСЫ,
Ыљвд Guiding Attention вЊзіЕФЪТЧщОЭЪЧ,ЧПЦШ Attention гавЛИіЙЬЖЈЕФбљУВ,ФЧШчЙћФуЖдетИіЮЪЬт,БОЩэОЭвбОгаРэНтжЊЕРЫЕ,гявєКЯГЩ TTS етбљЕФЮЪЬт,ФуЕФ Attention ЕФЗжЪ§,Attention ЕФЮЛжУЖМгІИУгЩзѓЯђгв,ФЧВЛШчОЭжБНгАбетИіЯожЦ,ЗХНјФуЕФ Training бeУц,вЊЧѓЛњЦїбЇЕН Attention,ОЭгІИУвЊгЩзѓЯђгв
ФЧетМўЪТдѕќNзіФи,гавЛаЉЙиМќДЪЛуЮвОЭЗХдкетБп,ШУДѓМвздМК Google СЫ,БШШчЫЕФГФГ Mnotonic Attention,Лђ Location-Aware ЕФ Attention,ФЧетИіВПЗжвВЪЧДѓПг,вВВЛЯИНВ,ФЧОЭСєИјДѓМвздМКбаОП
Beam Search
Beam Search ,ЮвУЧетБпОйвЛИіР§зг,дкетИіР§згбeУцЮвУЧМйЩшЫЕ,ЮвУЧЯждкЕФетИі DecoderОЭжЛФмЎaЩњСНИізж,вЛИіНазі A вЛИіНазі B
ФЧЖд Decoder Жјбд,ЫќзіЕФЪТЧщОЭЪЧ,УПвЛДЮдкЕквЛИі Time Step,Ыќдк A B бeУцОіЖЈвЛИі,ШЛКѓОіЖЈСЫ A вдКѓ,дйАб A ЕБзіЪфШы,ШЛКѓдйОіЖЈ A B вЊбЁФФвЛИі
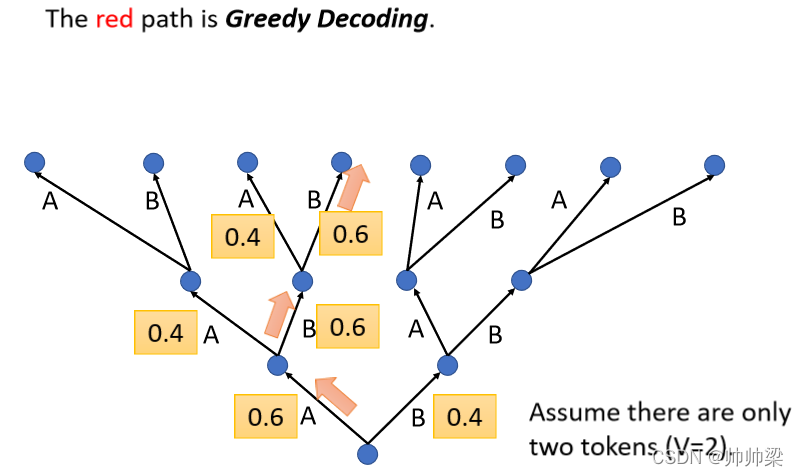
ФЧОйР§РДЫЕ,ЫќПЩФмбЁ B ЕБзїЪфШы,дйОіЖЈ A B вЊбЁФФвЛИі,ФЧдкЮвУЧИеВХНВЕФ Process бeУц,УПвЛДЮ Decoder ЖМЪЧбЁ,ЗжЪ§зюИпЕФФЧвЛИі
ЮвУЧУПДЮЖМЪЧбЁMax ЕФФЧвЛИі,ЫљвдМйЩш A ЕФЗжЪ§ 0.6,B ЕФЗжЪ§ 0.4,Decoder ЕФЕквЛДЮОЭЛсЪфГі A,ШЛКѓНгЯТРДМйЩш B ЕФЗжЪ§ 0.6,A ЕФЗжЪ§ 0.4,Decoder ОЭЛсЪфГі B,КУ,ШЛКѓдйМйЩшАб B ЕБзі Input,ОЭЯждкЪфШывбОга A га B СЫ,ШЛКѓНгЯТРД,A ЕФЗжЪ§ 0.4,B ЕФЗжЪ§ 0.6,ФЧ Decoder ОЭЛсбЁдёЪфГі B,ЫљвдЪфГіОЭЪЧ A Ињ B Ињ B
ФЧЯёетбљзгУПДЮевЗжЪ§зюИпЕФФЧИі Token,УПДЮевЗжЪ§зюИпЕФФЧИізж,РДЕБзіЪфГіетМўЪТЧщНазі,Greedy Decoding
ЕЋЪЧ Greedy Decoding,вЛЖЈЪЧИќКУЕФЗНЗЈТ№,гаУЛгаПЩФмЮвУЧдкЕквЛВНЕФЪБКђ,ЯШЩдЮЂЮЦњвЛЕуЖЋЮї
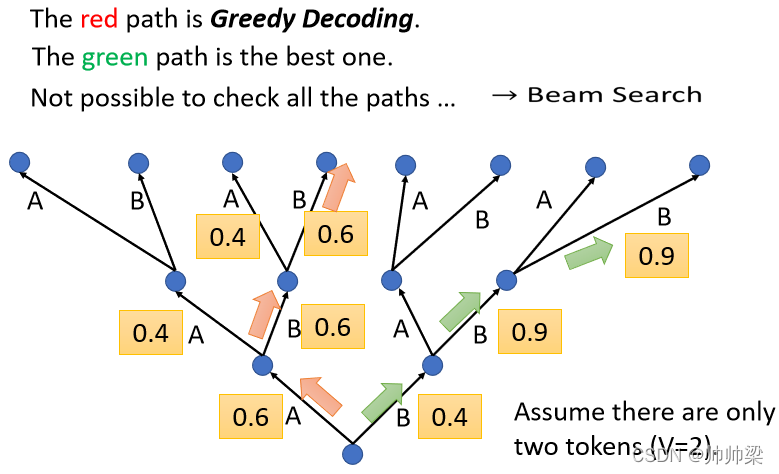
БШШчЫЕЕквЛВНЫфШЛ B ЪЧ 0.4,ЕЋЮвУЧОЭЯШбЁ 0.4 етИі B,ШЛКѓНгЯТРДЮвУЧбЁСЫ B вдКѓ,вВаэНгЯТРДЕФ B ЕФПЩФмадОЭДѓді,ОЭБфГЩ 0.9,ШЛКѓНгЯТРДЕкШ§ИіВНжш,B ЕФПЩФмадвВЪЧ 0.9
ШчЙћФуБШНЯКьЩЋЕФетвЛЬѕТЗ,ИњТЬЩЋетЬѕТЗЕФЛА,ФуЛсЗЂЯжЫЕТЬЩЋетвЛЬѕТЗ,ЫфШЛвЛПЊЪМЕквЛИіВНжш,ФубЁСЫвЛИіБШНЯВюЕФЪфГі,ЕЋЪЧНгЯТРДЕФНсЙћЪЧКУЕФ
етИіОЭИњФЧИіЬьСњАЫВПЕФецСњЦхОжвЛбљ,ЖдВЛЖд,ЯШЖТЫРздМКвЛПщ,НсЙћНгЯТРДЗДЖјгЎСЫ
ФЧЫљвдЮв,ШчЙћЮвУЧвЊдѕќNевЕН,етИізюКУЕФТЬЩЋетвЛЬѕТЗФи,вВаэвЛИіПЩФмЪЧ,БЌЫбЫљгаПЩФмЕФТЗОЖ,ЕЋЮЪЬтЪЧЮвУЧЪЕМЪЩЯ,ВЂУЛгаАьЗЈБЌЫбЫљгаПЩФмЕФТЗОЖ,вђщЪЕМЪЩЯУПвЛИізЊоцЕуПЩвдЕФбЁдёЬЋЖрСЫ,ШчЙћЪЧдкЖджаЮФЖјбд,ЮвУЧжаЮФга 4000 Иізж,ЫљвдетИіЪїУПвЛИіЕиЗНЗжВц,ЖМЪЧ 4000 ИіПЩФмЕФТЗОЖ,ФузпСНШ§ВНвдКѓ,ФуОЭЮоЗЈЧюОй
ЫљвддѕќNАьФи,гавЛИібнЫуЗЈНазі Beam Search,ЫќгУБШНЯгааЇЕФЗНЗЈ,еввЛИі Approximate,еввЛИіЙРВтЕФ Solution,еввЛИіВЛЪЧКмОЋЪЕФ,ВЛЪЧЭъШЋОЋЪЕФ Solution,етИіММЪѕНазі Beam Search,ФЧетИівВСєИјДѓМвздМК Google,КУ
ФЧетИі Beam Search етИіММЪѕ,ЕНЕзгаУЛгагУФи,гаШЄЕФЪТОЭЪЧ,ЫќгаЪБКђгагУ,гаЪБКђУЛгагУ,ФуЛсПДЕНгааЉЮФЯзИцЫпФуЫЕ,Beam Search ЪЧвЛИіКмРУЕФЖЋЮї
ОйР§РДЫЕетЦЊ Paper Назі,The Curious Case Of Neural Text Degeneration,ФЧетИіШЮЮёвЊзіЕФЪТЧщЪЧ,Sentence Completion,вВОЭЪЧЛњЦїЯШЖСвЛЖЮОфзг,НгЯТРДЫќвЊАбетИіОфзгЕФКѓАыЖЮ,АбЫќЭъГЩ,ФуИјЫќвЛдђаТЮХ,ЛђепЪЧвЛИіЙЪЪТЕФЧААыВП,Эл ЫќздМКЗЂЛгЫќЕФЯыЯёДДдьСІ,АбетИіЮФеТ,АбЙЪЪТЕФКѓАыВПАбЫќаДЭъ

ФЧФуЛсЗЂЯжЫЕ,Beam Search дкетЦЊЮФеТбeУц,вЛПЊЭЗОЭИцЫпФуЫЕ,Beam Search здМКгаЮЪЬт:ШчЙћФугУ Beam Search ЕФЛА,ЛсЗЂЯжЫЕЛњЦїВЛЖЯНВжиИДЕФЛА,ЫќВЛЖЯПЊЪМЯнШыЙэДђЧН ЮоЧюоШІ,ВЛЖЯЫЕжиИДЕФЛА
ШчЙћФуНёЬьВЛЪЧгУ Beam Search,гаМгвЛаЉЫцЛњад,ЫфШЛНсЙћВЛвЛЖЈЭъШЋКУ,ЕЋЪЧПДЦ№РДжСЩйЪЧБШНЯе§ГЃЕФОфзг,ЫљвдгаШЄЕФЪТЧщЪЧ,гаЪБКђЖд Decorder РДЫЕ,УЛгаевГіЗжЪ§зюИпЕФТЗ,ЗДЖјНсЙћЪЧБШНЯКУЕФ
етИіЪБКђФугжОѕЕУТвТвЕФ ЖдВЛЖд,ОЭЪЧИеВХЧАвЛвГЭЖгАЦЌВХЫЕ,вЊевГіЗжЪ§зюИпЕФТЗ,ЯждкгжвЊНВЫЕевГіЗжЪ§зюИпЕФТЗВЛМћЕУБШНЯКУ,ЕНЕзЪЧдѕќNЛиЪТФи
ФЧЦфЪЕетИіОЭЪЧвЊ,ПДФуЕФШЮЮёЕФБОЩэЕФЬиад
- ОЭМйЩшвЛИіШЮЮё,ЫќЕФД№АИЗЧГЃЕиУїШЗ
ОйР§РДЫЕ,ЪВќNНаД№АИЗЧГЃУїШЗФи,БШШчЫЕгявєБцЪЖ,ЫЕвЛОфЛАБцЪЖЕФНсЙћОЭжЛгавЛИіПЩФм,ОЭФЧвЛДЎЮФзжОЭЪЧФуЮЈвЛПЩФмЕФе§ШЗД№АИ,ВЂУЛгаЪВќNФЃК§ЕФЕиДј
ЖдетжжШЮЮёЖјбд,ЭЈГЃ Beam Search ОЭЛсБШНЯгаАяжњ,ФЧЪВќNбљЕФШЮЮё
- ФуашвЊЛњЦїЗЂЛгвЛЕуДДдьСІЕФЪБКђ,етЪБКђ Beam Search ОЭБШНЯУЛгаАяжњ,
ОйР§РДЫЕдкетБпЕФ Sentence Completion,ИјФувЛИіОфзг,ИјФуЙЪЪТЕФЧААыВП,КѓАыВПгаЮоЧюЖрПЩФмЕФЗЂеЙЗНЪН,ФЧетжжашвЊгавЛаЉДДдьСІЕФ,гаВЛЪЧжЛгавЛИіД№АИЕФШЮЮё,ЭљЭљЛсБШНЯашвЊдк Decoder бeУц,МгШыЫцЛњад,ЛЙгаСэЭтвЛИі Decoder,вВЗЧГЃашвЊЫцЛњадЕФШЮЮё,НазігявєКЯГЩ,TTS ОЭЪЧгявєКЯГЩЕФЫѕаД
етвВаэОЭКєгІСЫвЛИігЂЮФЕФбшгя,ОЭЪЧвЊНгЪмУЛгаЪТЧщЪЧЭъУРЕФ,ФЧеце§ЕФУРвВаэОЭдкВЛЭъУРжЎжа,ЖдьЖ TTS Лђ Sentence Completion РДЫЕ,Decoder евГізюКУЕФНсЙћ,ВЛМћЕУЪЧШЫРрОѕЕУзюКУЕФНсЙћ,ЗДЖјЪЧЦцЙжЕФНсЙћ,ФЧФуМгШывЛаЉЫцЛњад,НсЙћЗДЖјЛсЪЧБШНЯКУЕФ
Optimizing Evaluation Metrics?
дкзївЕбeУц,ЮвУЧЦРЙРЕФБъЪгУЕФЪЧ,BLEU Score,BLEU Score ЪЧФуЕФ Decoder,ЯШЎaЩњвЛИіЭъећЕФОфзгвдКѓ,дйШЅИње§ШЗЕФД№АИвЛећОфзіБШНЯ,ЮвУЧЪЧФУСНИіОфзгжЎМфзіБШНЯ,ВХЫуГі BLEU Score
ЕЋЮвУЧдкбЕСЗЕФЪБКђЯдШЛВЛЪЧетбљ,бЕСЗЕФЪБКђ,УПвЛИіДЪЛуЪЧЗжПЊПМТЧЕФ,бЕСЗЕФЪБКђ,ЮвУЧ Minimize ЕФЪЧ Cross Entropy,Minimize Cross Entropy,ецЕФПЩвд Maximize BLEU Score Т№
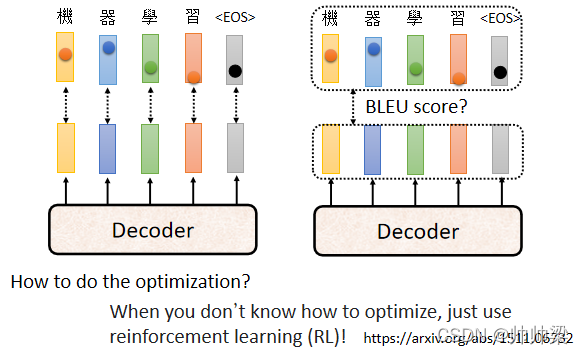
ВЛвЛЖЈ,вђщетСНИіИљБООЭЪЧ,ЫќУЧПЩФмгавЛЕуЕуЕФЙиСЊ,ЕЋЫќУЧгжУЛгаФЧќNжБНгЯрЙи,ЫќУЧИљБООЭЪЧСНИіВЛЭЌЕФЪ§жЕ,ЫљвдЮвУЧ Minimize Cross Entropy,ВЛМћЕУПЩвдШУ BLEU Score БШНЯДѓ
ЫљвдФуЗЂЯжЫЕдкжњНЬЕФГЬЪНбeУц,жњНЬдкзі Validation ЕФЪБКђ,ВЂВЛЪЧФУ Cross Entropy РДЬєзюКУЕФ Model,ЖјЪЧЬє BLEU Score зюИпЕФФЧвЛИі Model,ЫљвдЮвУЧбЕСЗЕФЪБКђ,ЪЧПД Cross Entropy,ЕЋЪЧЮвУЧЪЕМЪЩЯФузївЕеце§ЦРЙРЕФЪБКђ,ПДЕФЪЧ BLEU Score,ЫљвдФу Validation Set,ЦфЪЕгІИУПМТЧгУ BLEU Score
ФЧНгЯТРДгаШЫОЭЛсЯыЫЕ,ФЧЮвУЧФмВЛФмдк Training ЕФЪБКђ,ОЭПМТЧ BLEU Score Фи,ЮвУЧФмВЛФмЙЛбЕСЗЕФЪБКђОЭЫЕ,ЮвЕФ Loss ОЭЪЧ,BLEU Score ГЫвЛИіИККХ,ФЧЮвУЧвЊ Minimize ФЧИі Loss,МйЩшФуЕФ Loss ЪЧ,BLEU ScoreГЫвЛИіИККХ,ЫќвВЕШьЖОЭЪЧ Maximize BLEU Score
ЕЋЪЧетМўЪТЪЕМЪЩЯУЛгаФЧќNШнвз,ФуЕБШЛПЩвдАб BLEU Score,ЕБзіФубЕСЗЕФЪБКђ,ФувЊзюДѓЛЏЕФвЛИіФПБъ,ЕЋЪЧ BLEU Score БОЩэКмИДдг,ЫќЪЧВЛФмЮЂЗжЕФ,
етБпжЎЫљвдёгУ Cross Entropy,ЖјЧвЪЧУПвЛИіжаЮФЕФзжЗжПЊРДЫу,ОЭЪЧвђщетбљЮвУЧВХгаАьЗЈДІРэ,ШчЙћФуЪЧвЊМЦЫу,СНИіОфзгжЎМфЕФ BLEU Score,етвЛИі Loss,ИљБООЭУЛгаАьЗЈзіЮЂЗж,ФЧдѕќNАьФи
етБпОЭНЬДѓМввЛИіПкОї,гіЕНФудк Optimization ЮоЗЈНтОіЕФЮЪЬт,гУ RL гВ Train вЛЗЂОЭЖдСЫетбљ,гіЕНФуЮоЗЈ Optimize ЕФ Loss Function,АбЫќЕБзіЪЧ RL ЕФ Reward,АбФуЕФ Decoder ЕБзіЪЧ Agent,ЫќЕБзїЪЧ RL,Reinforcement Learning ЕФЮЪЬтгВзі
ЦфЪЕвВЪЧгаПЩФмПЩвдзіЕФ,гаШЫецЕФетбљЪдЙ§,ЮвАб Reference СадкетБпИјДѓМвВЮПМ,ЕБШЛетЪЧвЛИіБШНЯФбЕФзіЗЈ,ФЧВЂУЛгаЬиБ№ЭЦМіФудкзївЕбeУцгУетвЛеа
Scheduled Sampling
ФЧЮвУЧвЊНВЕН,ЮвУЧИеВХЗДИВЬсЕНЕФЮЪЬтСЫ,ОЭЪЧбЕСЗИњВтЪдОгШЛЪЧВЛвЛжТЕФ
ВтЪдЕФЪБКђ,Decoder ПДЕНЕФЪЧздМКЕФЪфГі,ЫљвдВтЪдЕФЪБКђ,Decoder ЛсПДЕНвЛаЉДэЮѓЕФЖЋЮї,ЕЋЪЧдкбЕСЗЕФЪБКђ,Decoder ПДЕНЕФЪЧЭъШЋе§ШЗЕФ,ФЧетИіВЛвЛжТЕФЯжЯѓНазі,Exposure Bias
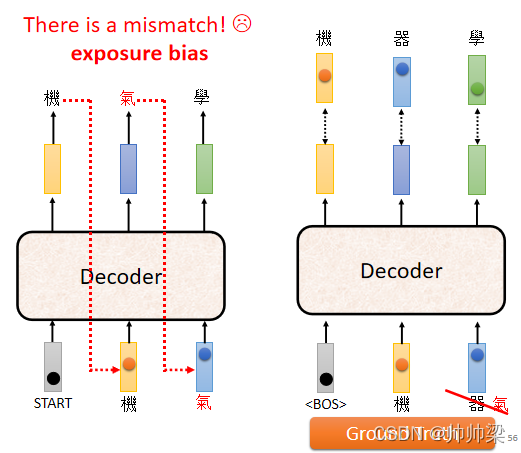
МйЩш Decoder дкбЕСЗЕФЪБКђ,гРдЖжЛПДЙ§е§ШЗЕФЖЋЮї,ФЧдкВтЪдЕФЪБКђ,ФужЛвЊгавЛИіДэ,ФЧОЭЛсвЛВНДэ ВНВНДэ,вђщЖд Decoder РДЫЕ,ЫќДгРДУЛгаПДЙ§ДэЕФЖЋЮї,ЫќПДЕНДэЕФЖЋЮїЛсЗЧГЃЕФОЊЦц,ШЛКѓНгЯТРДЫќЎaЩњЕФНсЙћПЩФмЖМЛсДэЕє
ЫљвдвЊдѕќNНтОіетИіЮЪЬтФи
гавЛИіПЩвдЕФЫМПМЕФЗНЯђЪЧ,Иј Decoder ЕФЪфШыМгвЛаЉДэЮѓЕФЖЋЮї,ОЭетќNжБОѕ,ФуВЛвЊИј Decoder ЖМЪЧе§ШЗЕФД№АИ,ХМЖћИјЫќвЛаЉДэЕФЖЋЮї,ЫќЗДЖјЛсбЇЕУИќКУ,етвЛеаНазі,Scheduled Sampling,ЫќВЛЪЧФЧИі Schedule Learning Rate,ИеВХжњНЬгаНВ Schedule Learning Rate,ФЧЪЧСэЭтвЛМўЪТ,ВЛЯрИЩЕФЪТЧщ,етИіЪЧ Scheduled Sampling
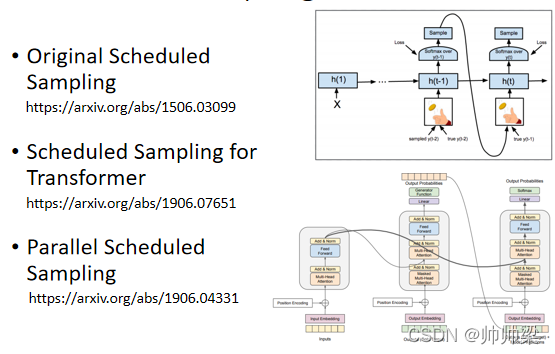
Scheduled Sampling ЦфЪЕКмдчОЭгаСЫ,етИіЪЧ 15 ФъЕФ Paper,КмдчОЭга Scheduled Sampling,дкЛЙУЛга Transformer,жЛга LSTM ЕФЪБКђ,ОЭвбОга Scheduled Sampling,ЕЋЪЧ Scheduled Sampling етвЛеа,ЫќЦфЪЕЛсЩЫКІЕН,Transformer ЕФЦНааЛЏЕФФмСІ,ФЧЯИНкПЩвддйздМКШЅСЫНтвЛЯТ,ЫљвдЖд Transformer РДЫЕ,ЫќЕФ Scheduled Sampling,СэгаеаЪ§ИњДЋЭГЕФеаЪ§,ИњдРДзюдчЬсдк,етИі LSTMЩЯБЛЬсГіРДЕФеаЪ§,вВВЛЬЋвЛбљ,ФЧЮвАбвЛаЉ Reference ЕФ,СадкетБпИјДѓМвВЮПМ
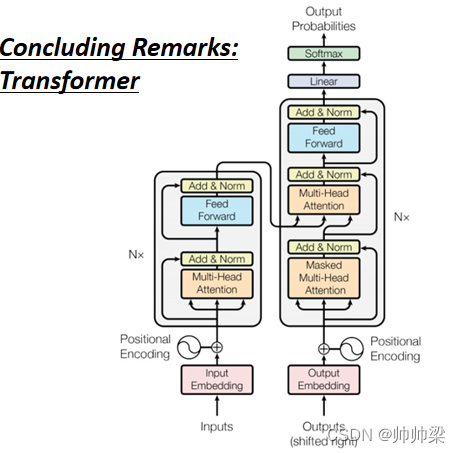
КУ ФЧвдЩЯЮвУЧОЭНВЭъСЫ,Transformer КЭжжжжЕФбЕСЗММЧЩ,етИіЮвУЧвбОНВЭъСЫ Encoder,НВЭъСЫ Decoder,вВНВЭъСЫЫќУЧжаМфЕФЙиS,вВНВСЫдѕќNбЕСЗ,вВНВСЫжжжжЕФ Tip