����Ŀ¼
�����
������ѧϰ��������־��
1. ��������
(1)Ŀ��
������ͼ����������Ϊ����ͨ�����ཻ���Ӽ���
(2)��������
- �ٶ������� D = { x 1 , x 2 , ? ? , x m } D=\{x_1,x_2,\cdots,x_m\} D={x1?,x2?,?,xm?}����m��������
- ÿ������ x i = { x i 1 , x i , 2 , ? ? , x i , n } x_i=\{x_{i1},x_{i,2},\cdots,x_{i,n}\} xi?={xi1?,xi,2?,?,xi,n?}��һ��nά����������
- ����������Ϊk�����ཻ�Ĵ�
{
C
l
�O
l
=
1
,
2
,
?
?
,
k
}
\{C_l|l=1,2,\cdots,k\}
{Cl?�Ol=1,2,?,k}��������
��
j
��
{
1
,
2
,
?
?
,
k
}
\lambda_j \in \{1,2,\cdots,k\}
��j?��{1,2,?,k}��ʾ����
x
j
x_j
xj?�Ĵر�ǡ�
���: x j �� C �� j x_j \in C_{\lambda_j} xj?��C��j?? - ������������m��Ԫ�صĴر������ �� = { �� 1 , �� 2 , ? ? , �� m } \lambda = \{\lambda_1,\lambda_2,\cdots,\lambda_m\} ��={��1?,��2?,?,��m?}��ʾ
2. ���ܶ���
(1)Ŀ��
- ��������,���ܶ����ܹ���������Ч���ĺû����������ƶȸߡ��ؼ����ƶȵ͡�
- ���Խ�ʹ�õ����ܶ�����Ϊ������̵��Ż�Ŀ�ꡣ
�����Ƿ���Ҫ�ο�ģ��,���Խ�ָ���Ϊ�ⲿָ��(external index)���ڲ�ָ��(internal index)��
2.1 �ⲿָ��
��: ȷ��(�������)
�����ݼ�
D
=
{
x
1
,
x
2
,
?
?
,
x
m
}
D=\{x_1,x_2,\cdots,x_m\}
D={x1?,x2?,?,xm?}ͨ��������صĴػ���Ϊ
C
=
{
C
1
,
C
2
,
?
?
,
C
k
}
C=\{C_1,C_2,\cdots,C_k\}
C={C1?,C2?,?,Ck?},�ο�ģ�����Ĵ�����Ϊ
C
?
=
{
C
1
?
,
C
2
?
,
?
?
,
C
s
?
}
C^*=\{C^*_1,C^*_2,\cdots,C^*_s\}
C?={C1??,C2??,?,Cs??}����
��
,
��
?
\lambda,\lambda^*
��,��?Ϊ��Ӧ�������ر��������

����:
- a �� d ��ʾ�������������� C C C��õĴر�ǩ��ͬ(����ͬ),�� C ? C^* C?��õĴر�ǩҲ��ͬ(����ͬ)��������
- b �� c ��ʾ�������������� C C C��õĴر�ǩ��ͬ(����ͬ),�� C ? C^* C?��õĴر�ǩ����ͬ(��ͬ)��������
- a + b + c + d = C 2 m = m ( m ? 1 ) 2 a+b+c+d=C_2^m=\frac{m(m-1)}{2} a+b+c+d=C2m?=2m(m?1)?
(1)Jaccardϵ��
J
C
=
a
a
+
b
+
c
JC= \frac{a}{a+b+c}
JC=a+b+ca?
(2)FMָ��
F
M
I
=
a
a
+
b
��
a
a
+
c
FMI=\sqrt{\frac{a}{a+b} \times \frac{a}{a+c}}
FMI=a+ba?��a+ca??
(3)Randָ��
R
I
=
2
(
a
+
d
)
m
(
m
?
1
)
RI=\frac{2(a+d)}{m(m-1)}
RI=m(m?1)2(a+d)?
- ��������ָ�����Ա�ʾ�� C , C ? C,C^* C,C?������Ϊ��ͬ�ص������Ե�����������ռ�ȡ�
- ȡֵ��ΧΪ [ 0 , 1 ] [0,1] [0,1],ֵԽ��Խ�á�ֵԽ���ʾ����Խ����ʵ�����,������ȷ��Խ�ߡ�
2.2 �ڲ�ָ��
��: �������ƶȸߡ��ؼ����ƶȵ�
�����ĸ��ػ���ָ��,������ָ������ڲ�ָ�ꡣ
-
����������ƽ������
a v g ( C ) = 2 �O C �O ( �O C ? 1 �O ) �� 1 �� i �� j �� �O C �O d i s t ( x i , x j ) avg(C) = \frac{2}{|C|(|C-1|)} \sum_{1 \leq i \leq j \leq |C|}dist(x_i,x_j) avg(C)=�OC�O(�OC?1�O)2?1��i��j���OC�O��?dist(xi?,xj?) -
������������Զ����
d i a m ( C ) = max ? 1 �� i �� j �� �O C �O d i s t ( x i , x j ) diam(C) = \max_{1 \leq i \leq j \leq |C|} dist(x_i,x_j) diam(C)=1��i��j���OC�Omax?dist(xi?,xj?) -
�ؼ���������̾���
d m i n ( C i , C j ) = min ? x i �� C i , x j �� C j d i s t ( x i , x j ) d_{min}(C_i,C_j) = \min_{x_i \in C_i,x_j \in C_j} dist(x_i,x_j) dmin?(Ci?,Cj?)=xi?��Ci?,xj?��Cj?min?dist(xi?,xj?) -
�ؼ����ĵ�ľ���
d c e n ( C i , C j ) = d i s t ( �� i , �� j ) d_{cen}(C_i,C_j) = dist(\mu_i,\mu_j) dcen?(Ci?,Cj?)=dist(��i?,��j?)
(1)DBָ��(DBI)
D
B
I
=
1
k
��
i
=
1
k
max
?
j
��
i
a
v
g
(
C
i
)
+
a
v
g
(
C
j
)
d
c
e
n
(
C
i
,
C
j
)
DBI=\frac{1}{k} \sum_{i=1}^k \max_{j \neq i} \frac{avg(C_i)+avg(C_j)}{d_{cen}(C_i,C_j)}
DBI=k1?i=1��k?j��?=imax?dcen?(Ci?,Cj?)avg(Ci?)+avg(Cj?)?
- DBIֵԽС,��ʾ����Խ����,�ؼ�Խ��ɢ��
(2)Dunnָ��(DI)
D
I
=
min
?
1
��
i
��
k
{
min
?
j
��
i
(
d
m
i
n
(
C
i
,
C
j
)
max
?
1
��
l
��
k
d
i
a
m
(
C
l
)
)
}
DI = \min_{1 \leq i \leq k} \{\min_{j \neq i}(\frac{d_{min}(C_i,C_j)}{\max_{1 \leq l \leq k}diam(C_l)}) \}
DI=1��i��kmin?{j��?=imin?(max1��l��k?diam(Cl?)dmin?(Ci?,Cj?)?)}
- DIֵԽ��,��ʾ����Խ����,�ؼ�Խ��ɢ��
3. �������
����ͨ���������������ƶȶ�����
(1)��������

3.1 ��������
����:{1, 2, 3}��1��2��1��3�ӽ������Ը��ݴ�����о������
(1)�ɿɷ�˹������

-
��P=1ʱ,��������پ���
d i s t ( x i , x j ) = �� u = 1 n �O x i u ? x j u �O dist(x_i,x_j) = \sum_{u=1}^n |x_{iu}-x_{ju}| dist(xi?,xj?)=u=1��n?�Oxiu??xju?�O -
��P=2ʱ,���ŷ�Ͼ���
d i s t ( x i , x j ) = �� u = 1 n �O x i u ? x j u �O 2 dist(x_i,x_j) =\sqrt{ \sum_{u=1}^n |x_{iu}-x_{ju}|^2} dist(xi?,xj?)=u=1��n?�Oxiu??xju?�O2?
3.2 ��������
����:{�ɻ�,��,�ִ�}��û�취���մ�����о��������
(1)VDM
��
m
u
,
a
m_{u,a}
mu,a?��ʾ����u��ȡֵΪa��������,
m
u
,
a
,
i
m_{u,a,i}
mu,a,i?��ʾ�ڵ�i����������u��ȡֵΪa������������a,b������ɢ���Ե�VDM����Ϊ:
V
D
M
p
(
a
,
b
)
=
��
i
=
1
k
�O
m
u
,
a
,
i
m
u
,
a
?
m
u
,
b
,
i
m
u
,
b
�O
p
VDM_p(a,b) = \sum_{i=1}^k |\frac{m_{u,a,i}}{m_{u,a}}-\frac{m_{u,b,i}}{m_{u,b}}|^p
VDMp?(a,b)=i=1��k?�Omu,a?mu,a,i???mu,b?mu,b,i??�Op
����:�������Ծ���ļ�����Ҫ��ǰ֪���ػ�����?
3.3 �������
����ǰ
n
c
n_c
nc?��Ϊ��������,����Ϊ�������ԡ�

4. ԭ�;���
4.1 k-means
- δ֪��ǩ���͵ľ���֡�
- ��ֵ��������������
(1)�Ż�Ŀ��

�������Ŀ��ΪNP������,���ͨ�������Ż�������⡣
(2)�㷨

- ���ѡ��k��������Ϊ����
- ����������ѡ�����ĵ�ľ���,�������������
- ������ھ�ֵ����,�������ı�ʱ���µľ�ֵ������Ϊ�´ص����ġ������ڸ��»������������С������ֵʱ�˳�ѭ����
����: ͨ����С�����ھ�ֵѡ��ۺ�����λ�á�
4.2 ѧϰ��������(LVQ)
- ��ҪԤ֪��ǩ����,�üල��Ϣ�������ࡣ
- ԭ������������Զ��
(1)�Ż�Ŀ��
������������x,������������������ԭ�������������Ĵ��С���Ҫʹ�����ͬ�Ŀ�£,��Dz�ͬ��Զ�롣
p
��
=
p
i
?
+
��
��
(
x
j
?
p
i
?
)
?
��
��
p
��
=
p
i
?
?
��
��
(
x
j
?
p
i
?
)
?
Զ
��
p
i
?
=
p
��
p'=p_{i^*} + \eta \times (x_j-p_{i^*}) \ ���� \\ p'=p_{i^*} - \eta \times (x_j-p_{i^*}) \ Զ�� \\ p_{i^*} = p'
p��=pi??+����(xj??pi??)?����p��=pi???����(xj??pi??)?Զ��pi??=p��
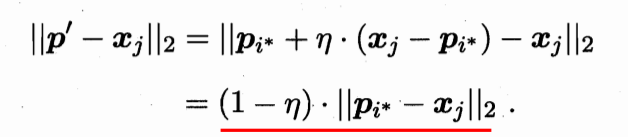
(2)�㷨

-
��ʼ��ԭ�����������ǩ
-
ѡȡ��������õ���֮���������ԭ��������
-
���ݱ�ǩ�Ƿ���ͬ,ʹԭ��������������Զ��������ֱ���ﵽ������������
����: ʹԭ��������£��ͬ�������,ԭ����ͬ�������,ʵ�־��ࡣ
4.3 �ܶȾ���(DBSCAN)
�����㷨�������ṹ��ͨ�������ֲ��Ľ��̶ܳ�ȷ����
(1)����
DBSCAN����һ���������
(
?
,
M
i
n
P
t
s
)
(\epsilon,MinPts)
(?,MinPts)�̻������ֲ��Ľ��̶ܳȡ��������ݼ�����һ�¸���:

- ��:�ܶȿɴ��ϵ�����������ܶ������������ϡ�
(2)�㷨
- ��ѡһ�����Ķ�����Ϊ����
- �Ըú��Ķ�����Ϊ������,�ҳ����ܶȿɴ���������ɾ���ء����º��Ķ����δ���ʶ���
- ѭ��1��2����֪�����к��Ķ������ʡ�

4.4 ����(AGNES)
AGNES��һ���Ե����Ͼۺϲ��ԵIJ�ξ����㷨�����ĺ���˼�����ҵ���������������غϲ�,֪���ﵽԤ��ľ�����Ŀ��
(1)���
������μ��������ؼ�ľ���(���ϼ�ľ���),���Ի���Ϊ�������:
- ������(single-linkage):����������
- ȫ����(complete-linkage):����������
- ������(average-linkage):����ƽ������

(2)�㷨
- ��ÿ��������ʼ��Ϊһ����
- ����ؼ�� M k �� k M_{k \times k} Mk��k?
- ѡ���������������غϲ�Ϊ�µĴ�,������������ǩ�ʹؼ�ࡣ
- ѭ��2��3����ֱ���ﵽԤ��ľ�����Ŀ��

4.5 ��˹��Ͼ���
����֪ʶ: ��Ҷ˹����,�������¡�