1. 下载Tesseract文本识别引擎
Tesseract是一个开源文本识别(OCR)引擎,可在Apache 2.0许可证下使用。
- 获取二进制文件

- 下载
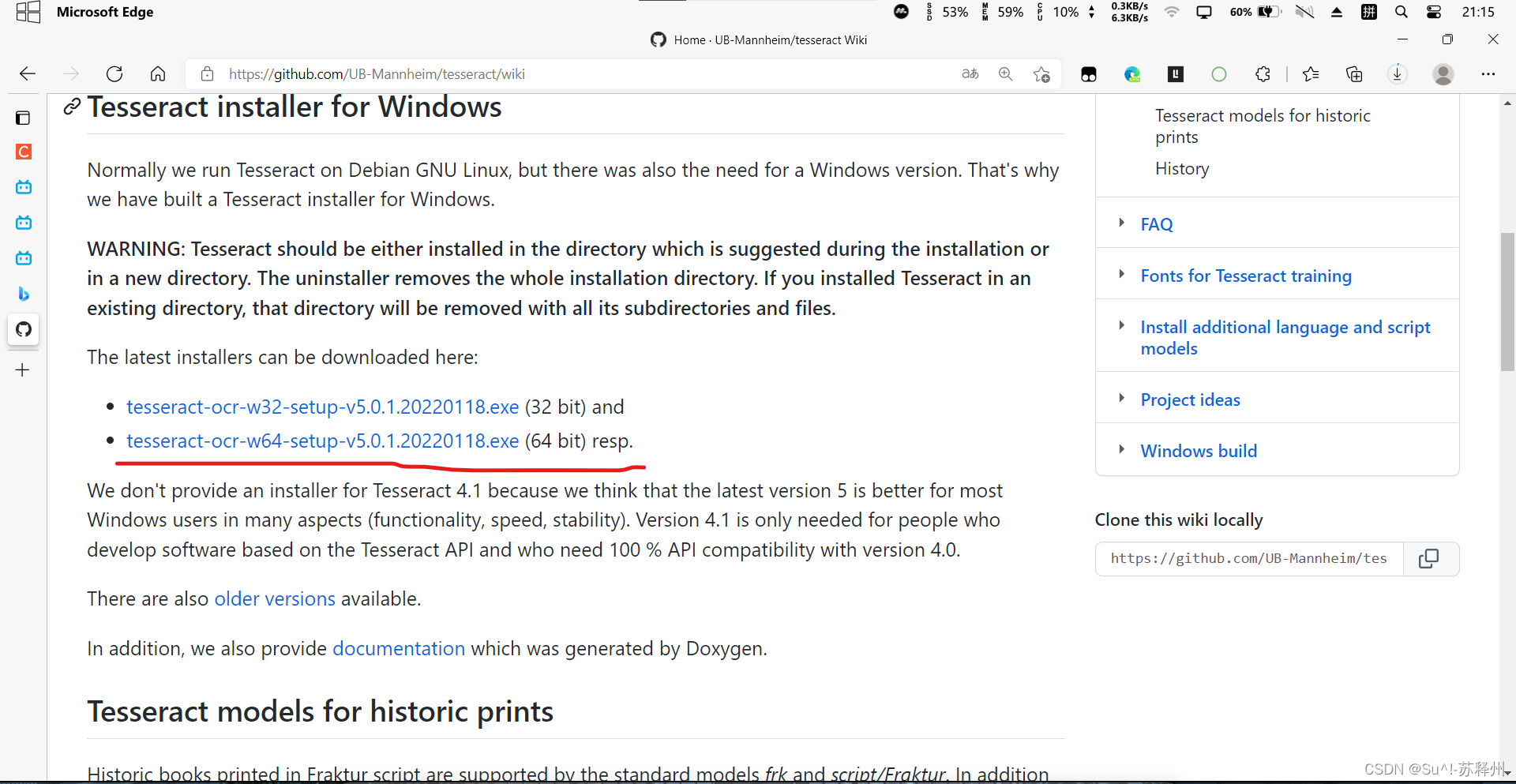
- 下载完.exe之后,安装一路next,在自己喜欢的路径即可
2. pycharm下创建工程
- 在刚刚下载tesseract的文件夹下,复制好tesseract.exe的绝对路径
- 安装对应的依赖包(pytesseract opencv-python)
3. 检测字符

由上面我们看出,通过imag_to_string给出的每个字符的信息,似乎并不是我们简单的认为x,y,w,h,x是正常的,但是y和h是相反的,所以真正的y=H-的出来的y
import cv2
import pytesseract
pytesseract.pytesseract.tesseract_cmd = 'E:\\nodeanddata\\Python\\OpenCV\\Text_Detection_OCR\\TesseractModel\\tesseract.exe' # 通过tesseract引用下载的可执行文件
img = cv2.imread('E:/nodeanddata/Python/OpenCV/Text_Detection_OCR/image/03.png')
# tesseract只接受RGB值,而imread出来的是BGR值,所以在这进行转化
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) #把BGR转换为RGB
#print(pytesseract.image_to_string(img)) #使用image_to_string接口函数,得到了图像中所有的字符串
#############################################
#### Detecting Characters ######
#############################################
hImg, wImg,_ = img.shape
boxes = pytesseract.image_to_boxes(img) # 得到的是list
for CharProperties in boxes.splitlines(): # split:分开,按照行分开给B
print(CharProperties)
CharProperties = CharProperties.split(' ') # 将字符串用' '分开,返回列表
print(CharProperties)
x, y, w, h = int(CharProperties[1]), int(CharProperties[2]), int(CharProperties[3]), int(CharProperties[4])
cv2.rectangle(img, (x,hImg- y), (w,hImg- h), (50, 50, 255), 1) # 给图片指定位置表上框
cv2.putText(img,CharProperties[0],(x,hImg- y+25),cv2.FONT_HERSHEY_SIMPLEX,1,(50,50,255),1) # 打标签
#显示图片
cv2.imshow('result', img)
cv2.waitKey(0)
通过这样查找pytesseract的函数可以看到它的接口函数的功能
4. 检测单词
同理的,读取图片,转换,显示跟上面是一样的。
主要函数接口:pytesseract.image_to_data(img)
给出来的字符串经过分割之后,所在的列表的信息为,以下代码注释所表示
##############################################
##### Detecting Words ######
##############################################
hImg, wImg,_ = img.shape
#[ 0 1 2 3 4 5 6 7 8 9 10 11 ]
#['level', 'page_num', 'block_num', 'par_num', 'line_num', 'word_num', 'left', 'top', 'width', 'height', 'conf', 'text']
boxes = pytesseract.image_to_data(img)
for a,b in enumerate(boxes.splitlines()):
print(b)
if a!=0:
b = b.split()
if len(b)==12:
x,y,w,h = int(b[6]),int(b[7]),int(b[8]),int(b[9])
cv2.putText(img,b[11],(x,y-5),cv2.FONT_HERSHEY_SIMPLEX,1,(50,50,255),2)
cv2.rectangle(img, (x,y), (x+w, y+h), (50, 50, 255), 2)
在for循环boxes.splitlines() 中由于第一行是标题,我们不想使用第一行的信息,那么我们就一边遍历一边索引即可;
就是说索引出来的第一个0我们不用他,这相当于在for循环前面加了一个标志变量,自动把第一行的列表给忽略;
而python中的枚举可以很好的帮我们把索引的值给a。(enumerate()函数)
5. 只检查数字
##############################################
##### Detecting ONLY Digits ######
##############################################
hImg, wImg,_ = img.shape
conf = r'--oem 3 --psm 6 outputbase digits'
boxes = pytesseract.image_to_boxes(img,config=conf)
for b in boxes.splitlines():
print(b)
b = b.split(' ')
print(b)
x, y, w, h = int(b[1]), int(b[2]), int(b[3]), int(b[4])
cv2.rectangle(img, (x,hImg- y), (w,hImg- h), (50, 50, 255), 2)
cv2.putText(img,b[0],(x,hImg- y+25),cv2.FONT_HERSHEY_SIMPLEX,1,(50,50,255),2)
conf = r'--oem 3 --psm 6 outputbase digits',通过编写配置的搜索引擎来配置pytesseract要检测的是什么
- OEM:配置引擎的模式
| Member name | Value | Description |
|---|---|---|
| OEM_TESSERACT_ONLY | 0 | Run Tesseract only - fastest |
| OEM_CUBE_ONLY | 1 | Run Cube only-better accuracy, but slower |
| OEM_TESSERACT_CUBE_COMBINED | 2 | Run both and combine results - best accuracy |
| OEM_DEFAULT | 3 | Specify this mode when calling init_*0, to indicat that any of the abovemodes should be automatically inferred from the variables in the language-specific config, |
- PSM:页面分割:
0 Orientation and script detection (OSD) only.
1 Automatic page segmentation with OSD.
2 Automatic page segmentation, but no OSD, or OCR.
3 Fully automatic page segmentation, but no OSD. (Default)
4 Assume a single column of text of variable sizes.
5 Assume a single uniform block of vertically aligned text.
6 Assume a single uniform block of text.
7 Treat the image as a single text line.
8 Treat the image as a single word.
9 Treat the image as a single word in a circle.
10 Treat the image as a single character.
11 Sparse text. Find as much text as possible in no particular order.
12 Sparse text with OSD.
13 Raw line. Treat the image as a single text line,
bypassing hacks that are Tesseract-specific.
参考资料
https://www.bilibili.com/video/BV18B4y1c7r4?p=1
python的tesseract库几个重要的命令
Python――enumerate()函数用法总结