--neozng1@hnu.edu.cn
-
Partcle Filter(СЃзгТЫВЈЦї,ЪБгђ)
PFПЩвдПДзїЪЧUKFЕФНјЛЏАцЁЃUKFвЊЧѓгУЗўДгИпЫЙЗжВМЕФвЛзщЕуОЙ§зЊЛЛжЎКѓШЅЭЈЙ§ВЩбљРДЕУЕНаТЕФИпЫЙЗжВМНјЖјНќЫЦецЪЕЕФзДЬЌЗжВМ;ЖјPFдђЪЧВЛдйзЗЧѓгУИпЫЙЗжВМШЅНќЫЦецЪЕЗжВМ,жБНггУвЛзщЕуОЙ§ФЃаЭзЊЛЛКѓдйВЩбљ,гУДЫКѓбщЪ§ОнРДНќЫЦШЮвтЗжВМЁЃЫќУЧЕФЧјБ№дкгкUKFЪЧЭЈЙ§вЛзщМйЩшдкЭЈЙ§ЯЕЭГЕФзЊЛЛКѓШдШЛЗўДгИпЫЙЗжВМЕФВЩбљЕуРДЧѓЦфВЮЪ§ІЬКЭІв,ЪЧвЛжжВЮЪ§ЙРМЦЗНЗЈ;PFЪЧгУвбжЊЕФВЩбљЕуЪ§ОнШЅЧѓЮДжЊЕФШЮвтЗжВМ,ЛђепДгСэвЛИіНЧЖШРДЫЕ,ОЭЪЧИЩДрВЛИјГіКѓбщЗжВМКЏЪ§(ВЛгУЗжВМРДУшЪі,ОЭЪЧвЛЖбРыЩЂЛЏЕФЕу),жБНгИљОнСЃзгЕФШЈжиНјааШкКЯЕУЕНзДЬЌЕФвЛжжПЩФмМйЩшЁЃИљОнДѓЪ§ЖЈТЩ(гжЪЧЫќ!),ЯывЊЭЈЙ§ВЩбљНќЫЦвЛИіЗжВМ,бљБОдНЖрдђНсЙћдННгНќецЪЕЗжВМ,вђДЫPFдкЁАШіЖЙзгЁБЪБЛсЪЙгУБШUKFЖрЕУЖрЕФбљБОЕу,ЫљвдЫќБОжЪЩЯЪЧвЛжжЗЧВЮЪ§ЛЏЕФУЩЬиПЈТхЗНЗЈЁЃ
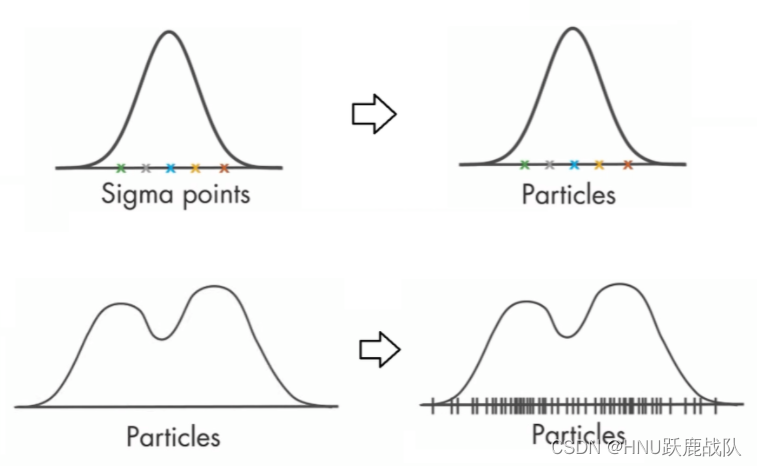
UKF(ЩЯ)КЭPF(ЯТ)зюжБЙлЕФЧјБ№:UKFгУИљОнвЛзщЕуЕФШЈжиНјааМЋДѓЫЦШЛЙРМЦ,жиНЈИпЫЙЗжВМ;PFжБНгИјВЩбљЕуЗжХфШЈжи,МДЭМжаЪњЯпЕФУмЖШ,жЎКѓдНУмМЏЕФЕуИННќБЛжиаТВЩбљЕНЕФИХТЪЛсдНДѓ
?дкPFЕФГѕЪМЛЏЙ§ГЬжаЩњГЩЕФетаЉбљБОЕуОЙ§ЙлВтОиеѓЁЂзДЬЌзЊвЦОиеѓБфЛЛКѓ,ЪфГівЛзщОЙ§ЗЧЯпадБфЛЛЕУЕНЕФЁАЛћаЮЁБЕФЗжВМЕуЁЃЯждк,ЮвУЧвЊЖдетаЉЁАЛћаЮЁБЕФЗжВМЕуНјаажиаТВЩбљвдЙРМЦЯЕЭГЕФзДЬЌ,ВЛЙ§,ЮвУЧВЛдйЯёEKFЁЂUKFвЛбљШЅгУетаЉВЩбљЕУЕНЕФЕуРДЛЙдЗжВМСЫ,ЮвУЧжБНгАбетаЉВЩбљЕУЕНЕФЕузїЮЊКѓбщаХЯЂ(ЭЈЙ§ЖдетаЉЕуНјааМгШЈ,ЕУЕНЙигкЯЕЭГЕФзДЬЌаХЯЂ,етЪБКђВЛдйЬжТлЁАЗжВМЁБ,ЩЯУцЬсЕНгУКѓбщЪ§ОнРДНќЫЦШЮвтЗжВМ,МШШЛЪЧШЮвтЕФЗжВМ,ФЧУДвВВЛДцдквЛИіМШЖЈЕФФЃаЭашвЊЭЈЙ§етаЉЕуРДМЦЫуЦфВЮЪ§МДНјааВЮЪ§ЙРМЦ,етаЉЕуЕФаХЯЂБОЩэОЭДњБэзХвЛжжЗжВМ)ЁЃ
ФЧУДгІИУШчКЮИГгшШЈжиВЂжиаТВЩбљ?етвЛВНОЭЖдгІзХKFжаЕФЙлВт,ЮвУЧЛсИљОнЙлВтЕУЕНЕФЪ§ОнЮЊЩЯУцЕФСЃзгИГгшШЈжи(ЭЈЙ§ЙлВтРДЕУЕНИїИіСЃзгЫљДІЖдгІзДЬЌЕФИХТЪ),НгзХАбФЧаЉИХТЪаЁЕФСЃзгХХçóؽ(етаЉИХТЪаЁЕФСЃзгИННќЮЛжУБЛжиаТВЩбљЕФИХТЪИќаЁ),дкШЈжиИпЕФСЃзгИННќИљОнШЈжижиаТВЩбљЁЃетбљОЭЭъГЩСЫPFЕФвЛДЮЕќДњИќаТ,pipelineздШЛОЭжиаТЛиЕНЕквЛВНЁЃШчДЫЭљИДбЛЗ,ТЫВЈЦїЪфГіОЭФмЪеСВЕНзюЁАЬљНќЁБЪЕМЪзДЬЌЕФЗжВМСЫЁЃ
етРягавЛИіЙигкСЃзгТЫВЈЦїЕФМђЖЬЪгЦЕ,ФмЙЛАяжњФуДгжБЙлЩЯРэНтPF:Uppsala University:Particle Filter CourseЁЃЩЯУцЕФНщЩмЖМЪЧЧуЯђгкЭЈЙ§жБЙлЕФНтЪЭАяжњФуРэНт,ШчЙћашвЊВЩгУбЯНїЕФЪ§бЇЭЦЕМДгИХТЪЭГМЦЁЂБДвЖЫЙЙРМЦЕФЪгНЧШыЪж,вВЧыВЮдФЯрЙиЕФНЬВФЁЃБЪепЛЙУЛгаМћЕНДгПижЦКЭЙлВтЦїЕФНЧЖШНтЪЭетбљЕФЗЧЯпадТЫВЈЦї(жївЊЪЧБЪепЕФЖдетЗНУцЕФжЊжЎЩѕЩй),ШєФужЊЕРвЛаЉЯрЙиЕФВФСЯ,ЧыСЊЯЕЮв!