用于行人重识别的水平金字塔匹配
论文题目:Horizontal Pyramid Matching for Person Re-Identification
paper是贝克曼研究所发表在AAAI2019上的工作
论文地址:链接
Abstract
尽管在行人重识别(Re-ID)方面取得了显著进展,但这种方法仍然存在识别性身体部位缺失的失败案例。为了减轻这种类型的失败,作者提出了一种简单而有效的水平金字塔匹配(HPM)方法来充分利用给定人的各部分信息,以便即使缺少一些关键部分也可以识别出正确的人选。借助 HPM,为 Re-ID 任务生成更稳健的特征表示做出了以下贡献: 1)使用不同水平金字塔尺度的部分特征表示进行分类,这成功地增强了各个人体部位的判别能力; 2)利用平均池化和最大池化以全局-局部方式说明特定于个人的判别信息。为了HPM方法的有效性,在 Market-1501、DukeMTMC-ReID 和 CUHK03 三个流行的数据集上进行了广泛的实验。在这些具有挑战性的基准上,分别取得了 83.1%、74.5% 和 59.7% 的 mAP 分数,这些都是新的最先进水平。
Introduction
行人重识别 (Re-ID) 旨在从一组图像中重新识别查询人员,这些图像由多个摄像头随时间拍摄。由于人体属性(如姿势、步态、衣服)以及环境设置(如照明、复杂背景和遮挡)的巨大变化,为每个人学习鲁棒的特征表示是一项挑战。
为了解决视觉线索的复杂性,基于深度学习的方法提供了有前景的解决方案。然而,这些方法只利用了全局人物特征,实际上这对缺失的关键部分很敏感。
为了缓解这些问题,最近的许多方法一直专注于学习部分判别特征表示。这些方法通常利用身体大小等全局特征和衣服标志等局部特征来增强 Re-ID 方法的鲁棒性。它们可以按局部区域生成方案分为三种类型。在第一种类型中,估计和提取诸如姿势或身体标志之类的先验知识以定位判别区域。然而,在这种情况下,Re-ID 的性能高度依赖于姿态或地标估计模型的鲁棒性。姿势估计错误等意外错误可能会极大地影响识别结果。第二种类型,基于注意力的方法,侧重于通过定位感兴趣的显着区域(ROI)自适应地提取深度特征图中的高激活信息。然而,所选区域缺乏语义解释。第三种类型将深度特征图裁剪为预定义的patch或条带,假设图像完全对齐,因此容易出现异常值引入的错误。
为了有效地学习部分判别特征并消除由意外的位姿变量和未对齐情况引起的负面影响,作者提出了一种简单而有效的方法,称为水平金字塔匹配 (HPM)。我们的 HPM 旨在以更强大和更有效的方式同时利用人的全局和部分信息来执行 Re-ID 任务。具体来说,本文做出以下三个贡献:
- 使用各种金字塔尺度将深度特征图水平分割成多个条带,用于以下池化操作,称为水平金字塔池化(HPP),并学习对不同金字塔尺度输出的每个空间条带特征进行独立分类。直观地说,使用多个尺度的条带将包含一个松弛距离,以减轻由未对齐引起的异常值问题。此外,独立学习多尺度信息将增强在所有特定尺度行人部分中学习到的判别信息。
- 将每个分区中的平均池化特征和最大池化特征结合起来。特别的,平均池化能够感知每个空间条带的全局信息,并将背景上下文考虑在内。相比之下,最大池化目标提取最具辨别力的信息并忽略那些主要来自相似服装或背景的干扰信息。将它们整合起来,从而以全局-局部的方式平衡这两种策略的有效性。
- 在三个主流行人重新识别数据集 Market1501、DukeMTMC-ReID 和 CUHK03(使用新协议)上评估本文提出的方法。实验结果表明,本文的模型在端到端方面击败了大多数最先进的方法。
用图1中所示的一个示例来说明HPM。首先提取具有多个卷积层的给定图像的特征表示,并以不同的金字塔比例对特征图进行水平切片。然后使用每个部分条带的全局平均池化和最大池化生成的特征表示来独立地进行Re-ID。通过以这种方式学习HPM,可以更有效地增强部分判别能力,从而克服当前解决方案的缺点(例如对丢失的关键部分或错位敏感)。图 2 显示了带HPM和不带HPM方案学习的最后一个卷积特征图的热力图。可以观察到,本文的 HPM 可以识别出更具辨别力的部分,从而获得更好的行人重识别结果。
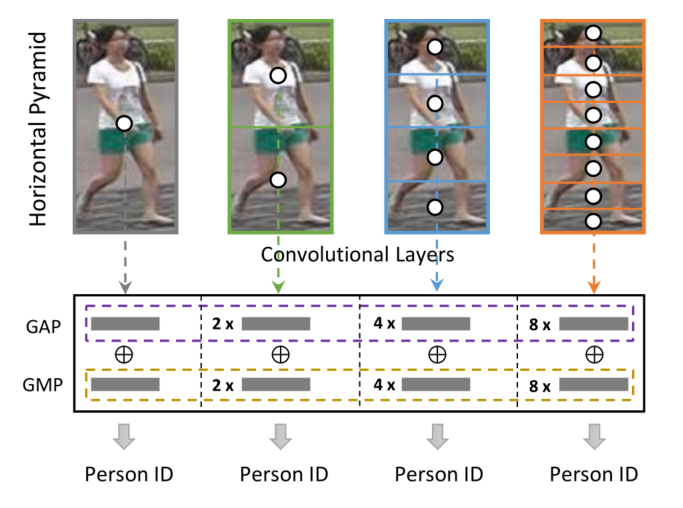
图 1:提出的水平金字塔匹配示意图。将一个人分成多个尺度的不同水平部分。然后利用每个部分的全局平均池化 (GAP) 和全局最大池化 (GMP) 生成的特征表示来独立地学习行人Re-ID。
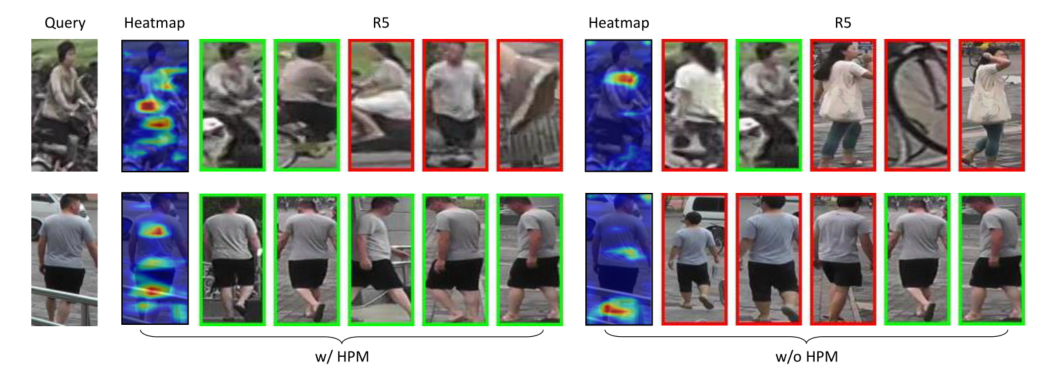
图 2:Person Re-ID 中带 HPM 和不带 HPM 的结果比较。
在 Market-1501、DukeMTMC-ReID 和 CUHK03 上进行的大量实验和消融研究证明了每种设计的有效性。特别是,在三个基准测试中的mAP得分分别为 83.1%、74.5% 和 59.7%,分别超过 state-of-hearts 1.5%、5.3% 和 2.2%。
Related Work
Deep learning for Person Re-ID
基于深度学习的方法在 Re-ID 社区中占主导地位。 Yi[1]首先使用深度神经网络来确定一对输入图像是否属于同一个 ID。一般而言,行人重识别使用两种类型的模型:验证模型和识别模型。
对于验证模型,Ahmed[2]采用孪生神经网络或三元组损失来提取具有相同身份的图像对并推开具有不同身份的图像。Hermans等人[3]提出了一种三元组损失的变体来执行端到端深度度量学习,它大大优于许多其他已发表的方法。然而,一般来说,这种模型在大型gallery上的效率会有所下降。这是因为它没有充分利用Re-ID注释。
对于识别模型,它试图学习给定输入图像的判别表示,并且与验证模型相比,它总是产生更高的准确性。Xiao[4]等人提出了一种新颖的 dropout 策略来联合训练具有多个数据集的分类模型。在[5]中,验证和分类损失结合在一起,同时学习判别嵌入和相似性度量。在[6]中,提出了一种基于部分的卷积网络来学习判别性的部分信息特征。
Part-based Model
最近,许多工作从局部部分生成深度表征,以获得细粒度的人的判别特征。这种基于部分的模型可以分为三类。第一类是基于一些先验知识,如姿势估计和目标检测[7]。这些方法都有一个共同的缺点,就是姿势估计和人物检索的数据集之间存在差距。第二,放弃分割的语义线索。例如,Yao等人[8]采用了部分损失网络,该网络强迫深度网络学习不同部分的表征,并获得对未见过的人的判别能力。第三,分区被裁剪成预定义的patch。Sun等人[9]提出了基于部分卷积Baseline(PCB)来学习判别性的分区特征。然而,PCB可能会遭受一些离群值,这使得每个分区的不一致,因此他们提出了Refined Part Pooling (RPP)来加强部分内的一致性。
Spatial Pyramid Pooling
由于具有全连接层的卷积神经网络总是需要固定的输入大小。为了消除这种约束,He等人[10]提出了 Spatial Pyramid Pooling 网络,无论输入大小如何,它都能生成固定长度的输出,并通过在局部空间 bin 中进行池化来维护空间信息。多级空间池化也被证明对目标变形具有鲁棒性。它可以提高分类和目标检测任务的性能。类似地,金字塔池化模块也用于[11],金字塔层级池化将特征图分成不同的子区域,形成不同位置的池化表示。
Proposed Method
本节描述了水平金字塔匹配(HPM)框架的结构,如图 3 所示。输入图像被送到backbone网络以提取特征图。之后,使用水平空间金字塔池化模块来获取每个局部和全局空间bin中的空间信息。对于每个水平空间bin,同时使用全局平均池化操作和最大池化操作来获得全局和人体最具辨别力的部分的特征。然后,使用卷积层将列特征图的维度从 2048 减少到 256,并将每个列特征输入到独立全连接层,然后使用 softmax 函数来预测每个输入图像的 ID。在测试期间,将所有这些特征连接在一起以获得最终的 Re-ID 特征表示。更多细节将在下文中给出。
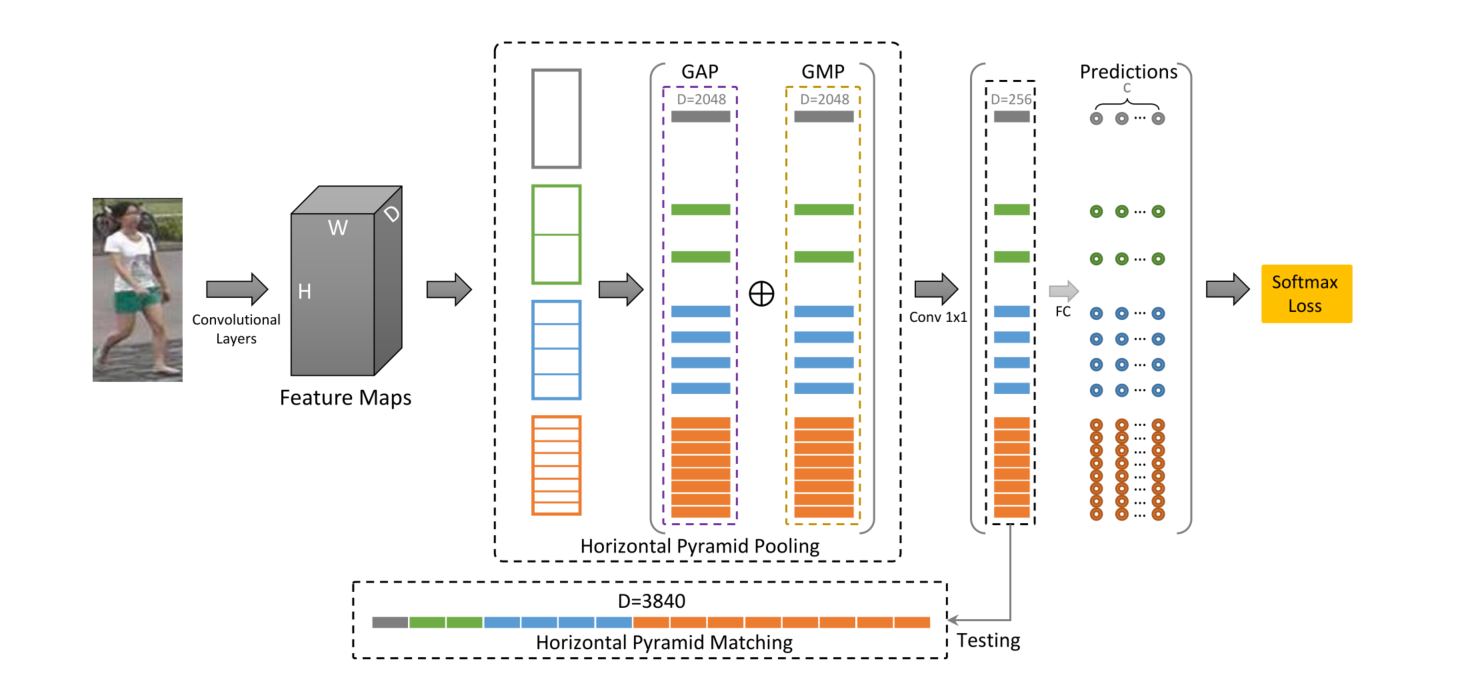
图3:提出的水平金字塔匹配(HPM)方法概述。输入图像首先通过卷积神经网络来提取其特征图。然后,利用水平金字塔汇集来使用全局平均池化和全局最大池化生成每个部分的特征表示。最后,将每个部分的预测送到分类器中以进行部分级别的行人Re-ID。在测试阶段,将不同金字塔尺度的部分特征连接起来,形成每张图像的最终特征表示。
Horizontal Pyramid Matching
Backbone Network
HPM可以采用各种网络架构,如VGG、Resnet和Google Inception作为backbone网络。本文选择Resnet50作为backbone网络,并按照之前的最先进的技术[12]进行了一些修改。首先,移除平均池化层和全连接层。另外,conv4_1的步长设置为1。因此,提取的特征图的大小将是输入图像大小的 1 16 \frac{1}{16} 161?。
Horizontal Pyramid Pooling (HPP) module
HPP受到Special Pyramid Pooling(SPP)[13]的启发,SPP是为了消除因图像输入尺寸不同而导致的特征向量长度不确定而提出的。本文的HPP模块与SPP的区别主要包括两个方面。1)动机。HPP的目的是通过学习来增强不同尺度下部分人物身体的判别信息,而SPP是为了解决图像特征向量长度不一致的问题。2)操作。由于人的区分分区的分布是从头到脚,HPP以水平方式将特征图切成多个条带,这与SPP采用二维空间的方式不同。通过HPP,可以在不同的水平金字塔尺度上获得固定长度的人物部分的向量。这些向量被进一步送入一个卷积层和一个全连接层以学习分类。通过这种方式,可以从全局到局部,从粗到细地捕捉到行人部分的判别能力。
公式上,将backbone网络提取的特征图表示为
F
F
F。在HPP模块中采用了4个金字塔尺度,并根据不同的尺度将F水平平均分割成几个空间bin。具体来说,假设每个空间bin为
F
i
,
j
F_{i, j}
Fi,j?。
i
,
j
i, j
i,j代表尺度索引和每个尺度下的bin索引。例如,
F
3
,
4
F_{3,4}
F3,4?表示第三个池化尺度中的第四个bin。然后,通过全局平均池化和最大池化池化每个空间bin
F
i
,
j
F_{i, j}
Fi,j?以生成列特征向量
G
i
,
j
G_{i, j}
Gi,j?。
G
i
,
j
=
avgpool
?
(
F
i
,
j
)
+
maxpool
?
(
F
i
,
j
)
G_{i, j}=\operatorname{avgpool}\left(F_{i, j}\right)+\operatorname{maxpool}\left(F_{i, j}\right)
Gi,j?=avgpool(Fi,j?)+maxpool(Fi,j?)
之后,每个
G
i
,
j
G_{i, j}
Gi,j?被送入一个卷积层以将维度从 2048 减少到 256,表示为
H
i
,
j
H_{i, j}
Hi,j?。这些具有相同
i
\mathrm{i}
i的
H
i
,
j
H_{i, j}
Hi,j?可以被认为是对人的描述。随着金字塔尺度的增加,这种描述涵盖了更详细的部分特征。
Loss Function
利用基于分类的模型来处理行人重识别任务。因此,目标是预测每个人的 ID,然后可以通过优化的分类模型学习每人特定的特征表示。使用全连接层的一个分支作为分类器,每个特征列向量
H
i
,
j
H_{i, j}
Hi,j?被送入相应的分类器
F
C
i
,
j
F C_{i, j}
FCi,j?并使用 softmax 函数来预测其 ID。在训练期间,给定图像
I
I
I的输出是一组预测值
y
^
i
,
j
\hat{y}_{i, j}
y^?i,j?。每个
y
^
i
,
j
\hat{y}_{i, j}
y^?i,j?可以表示为
y
^
i
,
j
=
argmax
?
c
∈
P
exp
?
(
(
W
i
,
j
c
)
T
H
i
,
j
(
I
)
)
∑
p
=
1
P
exp
?
(
(
W
i
,
j
p
)
T
H
i
,
j
(
I
)
)
\hat{y}_{i, j}=\underset{c \in P}{\operatorname{argmax}} \frac{\exp \left(\left(W_{i, j}^{c}\right)^{T} H_{i, j}(I)\right)}{\sum_{p=1}^{P} \exp \left(\left(W_{i, j}^{p}\right)^{T} H_{i, j}(I)\right)}
y^?i,j?=c∈Pargmax?∑p=1P?exp((Wi,jp?)THi,j?(I))exp((Wi,jc?)THi,j?(I))?
其中
P
\mathrm{P}
P是行人 ID 的总数,
W
i
,
j
W_{i, j}
Wi,j?是
F
C
i
,
j
F C_{i, j}
FCi,j?的学习权重,
y
y
y是输入图像
I
I
I的ground truth。损失函数是每个输出
y
^
i
,
j
\hat{y}_{i, j}
y^?i,j?的交叉熵损失之和。
?Loss?
=
∑
n
=
1
N
∑
i
,
j
C
E
(
y
^
i
,
j
n
,
y
n
)
\text { Loss }=\sum_{n=1}^{N} \sum_{i, j} C E\left(\hat{y}_{i, j}^{n}, y^{n}\right)
?Loss?=n=1∑N?i,j∑?CE(y^?i,jn?,yn)
其中
N
\mathrm{N}
N是 mini-batch 的大小,
C
E
\mathrm{CE}
CE是交叉熵损失。
Variant of HPM(HPM的变体)
HPM 可能有一些不同于上述基本框架的变体,例如不同的金字塔尺度和池化策略。
Number of pyramid scales
HPM 可以有几种不同数量的尺度。除了4个尺度,它可以是最大为 log ? 2 ( h ) \log _{2}(h) log2?(h)的任何数字,其中 h h h是特征图的高度。不同金字塔尺度的HPM结构如表1所示。随着金字塔尺度的增加,模型关注给定人的更详细和精细的划分。由于本文的损失函数是每个金字塔尺度的线性组合,如果金字塔尺度过多,可能会低估人的全局信息。另一方面,如果金字塔尺度太少,局部判别分区的特征可能难以提取。因此,选择能够平衡全局和局部特征的适当金字塔尺度对于 HPM 的性能至关重要。
Pooling strategies
HPM 同时使用平均池化和最大池化。全局平均池化是许多分类框架中的传统操作,因为它强制特征图和类别之间的对应关系。但是,全局平均池化可能会通过平均操作丢失一些非常具有判别性的信息。例如,如果人的一个分区判别力很强,但被背景包围,这种情况下,全局平均池化会得到判别部分和背景区域的平均值,这可能会导致响应低而错过它。为了解决这个问题,作者同时使用平均池化和最大池化,这样可以保持识别的全局关系,并保留判别部分。
参考文献
[1] Dong Yi et al. “Deep Metric Learning for Person Re-identification” International Conference on Pattern Recognition (2014).
[2] Ejaz Ahmed et al. “An improved deep learning architecture for person re-identification” Computer Vision and Pattern Recognition (2015).
[3] Alexander Hermans et al. “In Defense of the Triplet Loss for Person Re-Identification” arXiv: Computer Vision and Pattern Recognition (2017): n. pag.
[4] Tong Xiao et al. “Learning Deep Feature Representations with Domain Guided Dropout for Person Re-identification” Computer Vision and Pattern Recognition (2016).
[5] Zhedong Zheng et al. “A Discriminatively Learned CNN Embedding for Person Reidentification” ACM Transactions on Multimedia Computing, Communications, and Applications 14 (2017): 13.
[6] Yifan Sun et al. “Beyond Part Models: Person Retrieval with Refined Part Pooling…” (2017).
[7] Liang Zheng et al. “Pose Invariant Embedding for Deep Person Re-identification” arXiv: Computer Vision and Pattern Recognition (2017): n. pag.
[8] Hantao Yao et al. “Deep Representation Learning with Part Loss for Person Re-Identification” arXiv: Computer Vision and Pattern Recognition (2017): n. pag.
[9] Yifan Sun et al. “Beyond Part Models: Person Retrieval with Refined Part Pooling…” (2017).
[10] Kaiming He et al. “Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition” European Conference on Computer Vision (2014).
[11] Hengshuang Zhao et al. “Pyramid Scene Parsing Network” Computer Vision and Pattern Recognition (2017).
[12] Yifan Sun et al. “Beyond Part Models: Person Retrieval with Refined Part Pooling…” (2017).
[13] Kaiming He et al. “Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition” European Conference on Computer Vision (2014).