论文链接:https://arxiv.org/abs/2112.11010
代码链接:https: //git.io/MPViT
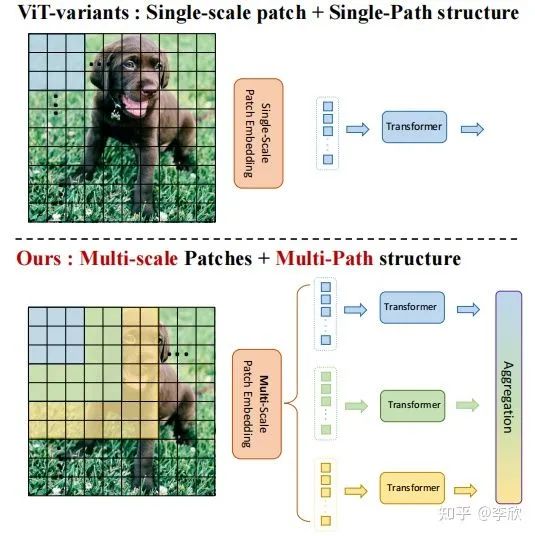
Introduction
-
在这项工作中,作者以不同于现有Transformer的视角,探索多尺度path embedding与multi-path结构,提出了Multi-path Vision Transformer(MPViT)。
-
通过使用 overlapping convolutional patch embedding,MPViT同时嵌入相同大小的patch特征。然后,将不同尺度的Token通过多条路径独立地输入Transformer encoders,并对生成的特征进行聚合,从而在同一特征级别上实现精细和粗糙的特征表示。
-
在特征聚合步骤中,引入了一个global-to-local feature interaction(GLI)过程,该过程将卷积局部特征与Transformer的全局特征连接起来,同时利用了卷积的局部连通性和Transformer的全局上下文。
Vision Transformers for dense predictions
-
密集的计算机视觉任务,如目标检测和分割,需要有效的多尺度特征表示,以检测或分类不同大小的物体或区域。Vision Transformer(ViT)构建了一个简单的多阶段结构(即精细到粗糙),用于使用单尺度patch的多尺度表示。然而ViT的变体专注于降低自注意的二次复杂度,较少关注构建有效的多尺度表示。
-
CoaT通过使用一种co-scale机制,同时表示精细和粗糙的特征,允许并行地跨层注意,从而提高了检测性能。然而,co-scale机制需要大量的计算和内存开销,因为它为基础模型增加了额外的跨层关注(例如,CoaT-Lite)。因此,对于ViT体系结构的多尺度特征表示仍有改进的空间。
Comparison to Concurrent work.
-
CrossViT利用了不同的patch大小和单级结构中的双路径,如ViT和XCiT。然而,CrossViT的分支之间的相互作用只通过[CLS]token发生,而MPViT允许所有不同规模的patch相互作用。此外,与CrossViT(仅限分类)不同的是,MPViT更普遍地探索更大的路径维度(例如,超过两个维度),并采用多阶段结构进行密集预测。
Method

Conv-stem
输入图像大小为:H×W×3,两层卷积:采用两个3×3的卷积,通道分别为C2/2,C2,stride为2,生成特征的大小为H/4×W/4×C2,其中C2为stage 2的通道大小。
-
说明:每个卷积之后都是Batch Normalization 和一个Hardswish激活函数。
-
In LeViT , a convolutional stem block shows better low-level representation (i.e., without losing salient information) than non-overlapping patch embedding.
从stage 2到stage 5,作者在每个阶段对所提出的Multi-scale Patch Embedding(MS-PatchEmbed)和Multi-path Transformer(MP-Transformer)块进行堆叠。
Multi-Scale Patch Embedding

MS-PatchEmbed:stage?

?的输入??,通过一个k×k的2D卷积,s为stride,p为 padding。输出的token map??的高度和宽度如下:

通过改变stride和padding来调整token的序列长度。也就是说,可以输出具有不同patch大小的相同大小(即分辨率)的特征。因此,作者并行地形成了几个具有不同卷积核大小的卷积patch embedding层。例如,如图1所示,可以生成相同序列长度的不同大小的vision token,patch大小分别为3×3,5×5,7×7。
由于具有相同通道和滤波器大小的连续卷积操作扩大了接受域,并且需要更少的参数,在实践中选择了连续的3×3卷积层。为了减少参数量,在实践中选择了两个连续的3×3卷积层代替5×5卷积。对于triple-path结构,使用三个连续的3×3卷积,通道大小为C',padding为1,步幅为s,其中s在降低空间分辨率时为2,否则为1。因此,给定conv-stem的输出?![]() ,通过MS-PatchEmbed可以得到相同大小为?
,通过MS-PatchEmbed可以得到相同大小为?![]() ?的特征
?的特征![]() ?。
?。
-
说明:为了减少模型参数和计算开销,采用3×3深度可分离卷积,包括3×3深度卷积和1×1点卷积。
-
每个卷积之后都是Batch Normalization 和一个Hardswish激活函数。
接着,不同大小的token embedding features 分别输入到transformer encoder中。
Multi-path Transformer

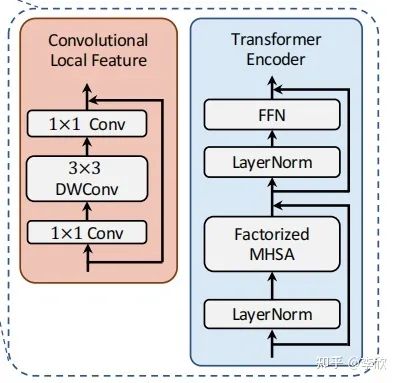
原因:Transformer中的self-attention可以捕获长期依赖关系(即全局上下文),但它很可能会忽略每个patch中的结构性信息和局部关系。相反,cnn可以利用平移不变性中的局部连通性,使得CNN在对视觉对象进行分类时,对纹理有更强的依赖性,而不是形状。
因此,MPViT以一种互补的方式将CNN与Transformer结合起来。
-
为了表示局部特征?
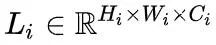
?,采用了一个 depthwise residual bottleneck block,包括1×1卷积、3×3深度卷积和1×1卷积和残差连接。
-
为了减轻多路径结构的计算负担,使用了CoaT中提出的有效的因素分解自注意:
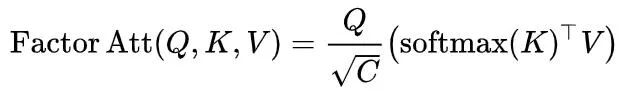
Global-to-Local Feature Interaction
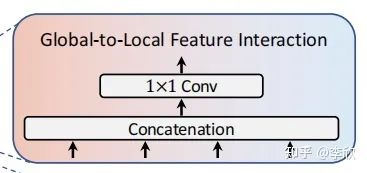
将局部特征和全局特征聚合起来:
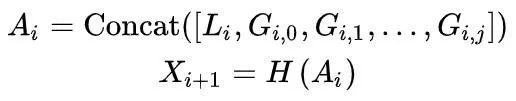
其中:j表示路径,?![]() ?为transformer encoder的输出
?为transformer encoder的输出![]() ?,?
?,?![]() 。
。
为了保持可比性的参数和FLOPs,增加路径的数量需要减少通道C或层数L(即,transformer encoder的数量)。作者通过减少C而不是L,从单路径(即CoaT-Lite baseline)扩展到triple-path。在消融研究中,验证了减少C比减少L获得更好的性能(见表5)。由于stage2的特征分辨率较高,导致计算成本较高,作者在stage2中将triple-path模型的路径数设置为2。从stage3开始,三路径模型有3条路径。
作者还发现,虽然 triple-path和双路径在ImageNet分类中产生相似的精度,但 triple-path模型在密集预测任务中表现出更好的性能。因此,建立了基于 triple-path结构的MPViT模型。MPViT的详细情况见表1。

![]()
Experiments
Ablation study
对MPViT-XS的每个组件进行消融研究,以研究提出的多路径结构对图像分类和使用Mask R-CNN检测的有效性。
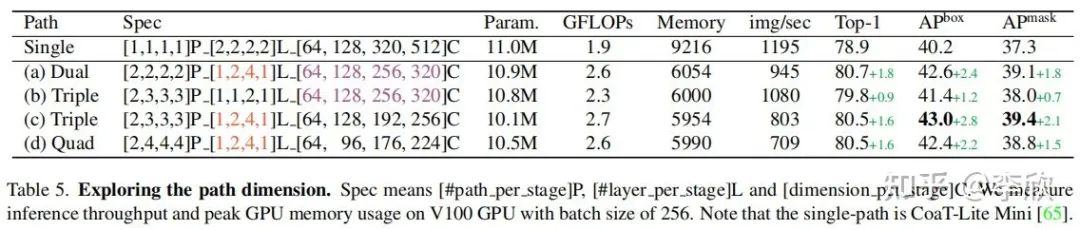
Exploring path dimension
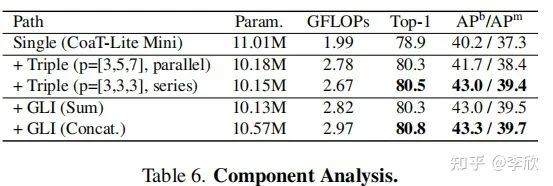
Patch size and structure
Exploring path dimension
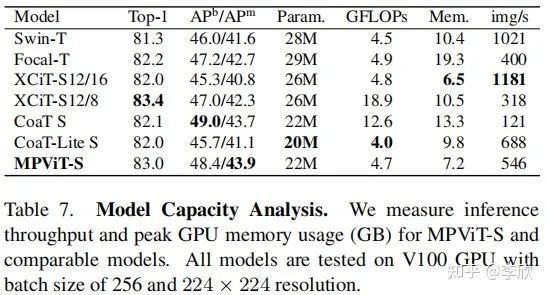
ImageNet Classifification
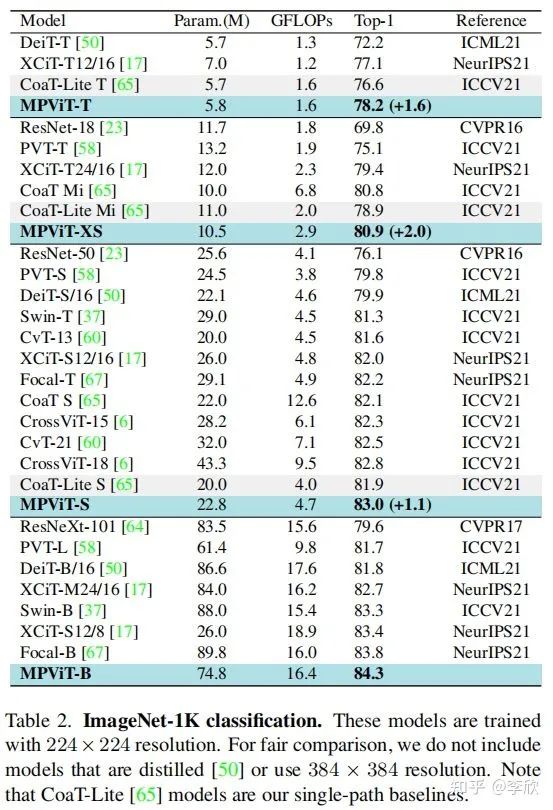
Object Detection and Instance Segmentation
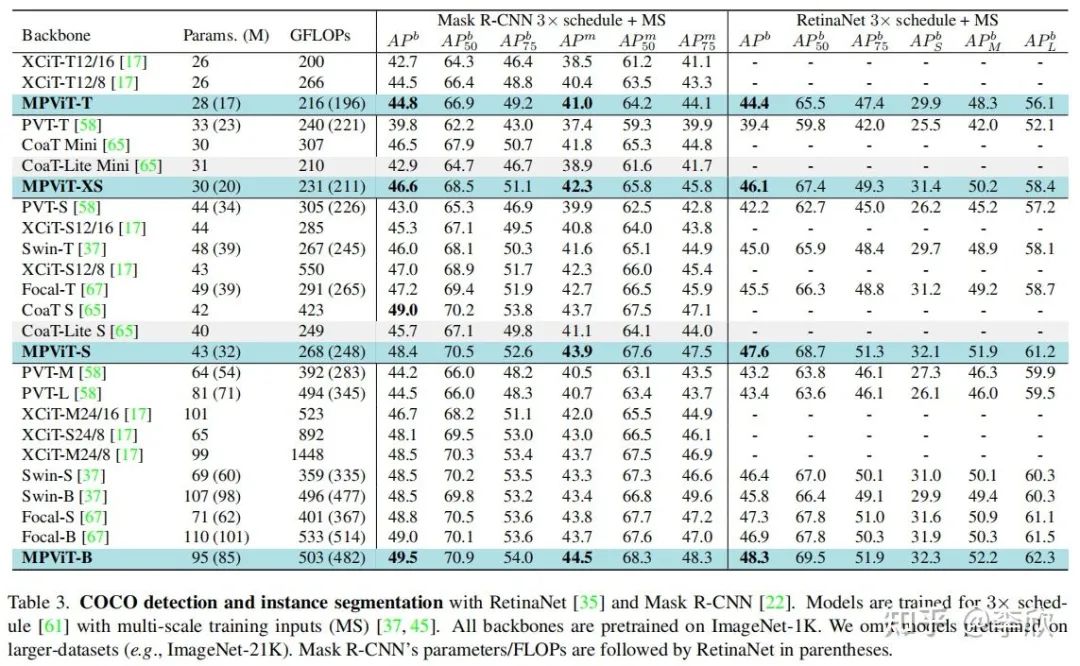
Semantic segmentation
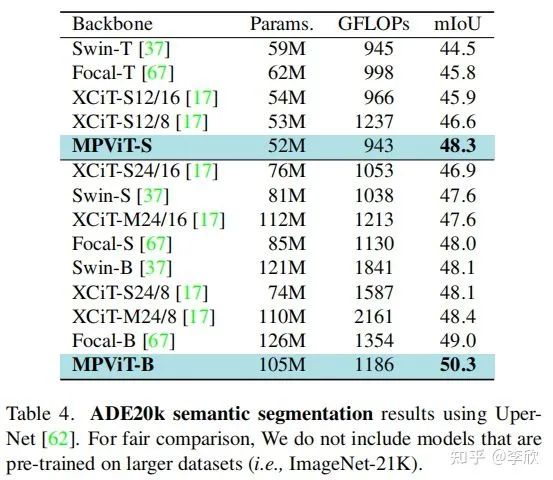
Qualitative Analysis

作者:李欣
|深延科技|

深延科技成立于2018年1月,中关村高新技术企业,是拥有全球领先人工智能技术的企业AI服务专家。以计算机视觉、自然语言处理和数据挖掘核心技术为基础,公司推出四款平台产品――深延智能数据标注平台、深延AI开发平台、深延自动化机器学习平台、深延AI开放平台,为企业提供数据处理、模型构建和训练、隐私计算、行业算法和解决方案等一站式AI平台服务。?