�������ѧϰ��IRS����MIMOͨ��ϵͳ��CSIѹ�����ָ��о�

��Դ:������ͨ��?��?,���Ƹ�וּ�
�ؼ���:?���ܷ�����;���ѧϰ;�ŵ�״̬��Ϣ����;
ժҪ:?���ܷ�����(IRS, Intelligent Reflecting Surface)��ɱ��͡����ĵ͡�������ͨ���������ŵ㱻�㷺�о����ڲ�������Ƶ�ָ�����Ϊ���ز����Ʒ�����IRS����Ƶ��˫������������(MIMO, Multiple input Multiple Output)ͨ��ϵͳ��,Ϊ������ϵͳ��ϵͳ����,�û���(UE, User Equipment)��Ҫ������ŵ����ŵ�״̬��Ϣ(CSI, Channel State Information)ͨ��������·��������վ��(BS, Base Station)�����,����ڴ�ͳ��MIMOϵͳ,��ϵͳ��CSI���������ͷ����������ɽ����Ǹ��Ӿ�ġ���Դ�����,���������һ�ֻ���ע�������Ƶ���Ȳв�����IARNet (Inception-Attention-Residual-Net)���Դ���������CSI����ѹ���ؽ����������ڴ�ͳ��Inception����ṹ�Ͻ���˶���������ںϡ����ע���������Լ��в����ģ��,���ֻ�Ͻṹ������Ч�ؽ�����������CSI����ѹ���ؽ�������������,�����е�2�����ѧϰ�������,IARNet�ڻ�����������ģ��ѵ�������ӳ��¿���������ߴ�������CSI���ؽ�������
1. ����
����5Gͨ�����������ҵ����,Ϊ�˻�ø�����ɿ������ݴ���,6Gͨ�ż����Ѿ������о�״̬,�������ܷ�����(IRS, Intelligent Reflecting Surface)��������ɱ��͡��ײ��𡢹��ĵ͡�������ͨ���������ص㱻Ӧ�õ���������ͨ��ϵͳ��IRS��һ���д�����Դ���䵥Ԫ�ı���,�ñ���ķ��䵥Ԫ���Խ������źŽ��б�������,ͨ������IRS�ķ���ϵ�������Խ�һ����߷����źŵĴ�����������ΪIRSʮ������,�������ǿ������ؽ��䲿���ڽ�����ǽ���������¥���ȵط������źŷ���Ĺ�����,����IRS���˿��Ʒ��䵥Ԫ�����������Ķ����������ص�,���IRS��ҵ��㷺����Ϊһ����ɫ�������Լ���ǰ���ļ��������������ŵ�,IRS�����ܺõ��������ֽ����Ƕ�6G��Ը��,�����ܡ��ںϡ���ɫ [1] [2] [3] [4] [5]��
���ѧϰ��һ��ͨ��������������Զ�����ȡ�����������������ɵ��˹����ܼ������Դ�2012��Geoffrey Hinton����ʹ�����ѧϰ�������Ծ������ƻ����ImageNetͼ��ʶ������Ĺھ�����,Խ��Խ����о��߲�������ѧϰ���о���ȡ���˾��չ������о�����,���ѧϰ����������ͼ��ʶ�������нܳ�����,��������Ȼ���Դ�����ͼ��ѹ��������Ҳȡ���˲��ijɼ� [6] - [18]���������кܶ�ͨ��������о��߽����ѧϰ����Ӧ������ͨ���������,�ʹ�ͳ��ͨ���㷨���,���ѧϰ���ŵ����ơ��źż���CSI (CSI, Channel State Information)�����ȷ����ϻ�ȡ�˸��õı��֡�
���CSI�����������������,���� [15] �״������ʹ�����ѧϰ������CSI����ѹ�����ؽ�,���������ΪCsiNet�����ѧϰ���硣����ڴ�ͳѹ����֪�ķ���,CsiNet�и��õ��ؽ��������ؽ��ٶȡ����� [16] ��CsiNet�Ļ�����������Inceptionģ��,����˶�ֱ�����ϵ�ṹ������:CRNet�������CsiNet,CRNet��������������仯���������½�һ�������ؽ������������� [17] ��CsiNet�Ļ�����������Dense Blockģ��,������м��²в�ģ�������:DS-NLCsiNet�������CsiNet,DS-NLCsiNet��һ��������ؽ������ͻָ����������� [18] ��CsiNet����������������ģ��,�����QuanCsiNet�������CsiNet,QuanCsiNet���Խ�һ��ѹ��������CSI���������� [18] ��ѵ�����ѧϰ�����ʱ��ʹ���˻�����ʵ�ŵ������ݼ�,���һ�������˻������ѧϰ��CSIѹ������ȷʵ����Ч�ġ�
�������е��������������ѹ�����ؽ���������С��CSI,������һ�㶼������2048��32λ����������IRS������Ƶ��˫��(FDD, Frequency Division Duplex)ģʽ�µĶ���������(MIMO, Multiple input Multiple Output)ͨ��ϵͳ�в�������Ƶ�ָ���(OFDM, Orthogonal Frequency Division Multiplexing)��Ϊ���ز��Ĵ��䷽������ϵͳ��������·������CSI����������վ��(BS, Base Station)���û���(UE, User Equipment)��CSI,����Ҫ����BS��IRS��CSI�Լ�IRS��UE��CSI,��˸�ϵͳ�ķ������������Ǹ��Ӿ��,ͬʱʹ�����ѧϰ��CSI����ѹ�����ؽ���ʱ��������Ҳ�������ӡ��ڱ�ϵͳ��ѹ�����ؽ���������������һ�㹤���о���4��,��8704��32λ�����������е������ڱ�ϵͳ�ж������������CSI����ѹ���ؽ���ʱ�������ؽ��������µ����⡣�����Ҫ��������������CSI��Ƴ�һ���µ����ѧϰ��������CSIѹ�����ؽ�,������ϵͳ���ؽ�������
�������IRS������ͨ��ϵͳ�з����������Ӿ�����������һ���µ����ѧ����IARNet�Լ�������������ģ��ѵ������ [7]��IARNet�ڴ�ͳ��������������ϲ����˶���������ںϡ����ע���������Լ��в��ģ�顣ͨ�����淢��:�����е����ѧϰ�������,IARNet�ڻ�����������ģ��ѵ�������ӳ��¿����������CSI�ؽ�����,��ʹ���ڽϵ�ѹ������IARNet���ܺܺõؽ�CSI�ָ����������ĵĹ����ܽ�����:
1) �о�����IRS�����µ�MIMOͨ��ϵͳ��CSIѹ�����ؽ�����,����������ϵͳģ�͡�
2) ���һ�����ѧϰ�����ڴ�������CSIѹ���ؽ������г����ؽ��������µ�����,�����ڴ�ͳ��������Ļ����ϼ����˶���������ںϡ����ע���������Լ��в��ģ��,��������ѧϰ����IARNet,ʵ�����,�ڻ�����������ģ��ѵ�������ӳ��¿����������CSI�ؽ�������
3) ��һ���о��˻�����������ѧϰ�ʵ������������ִ�ͳ��ѧϰ�ʵ���������1/8ѹ�����¶����������Ӱ��,ʵ�����:����ڴ�ͳ����������������ѧϰ�ʵ������Կ��Խ�һ�����CSI���ؽ�����,�ؽ�������������24.9%��
2. ϵͳģ��
�����о�IRS�����µ�MIMO FDDͨ��ϵͳ,������OFDM��Ϊ���ز��Ĵ��䷽��,ϵͳģ����ͼ1��ʾ��
�ڸ�ϵͳ��,������?NiNi?�����䵥Ԫ��IRS������?NtNt?�����ߵ�BS����?NrNr?�����ߵ�UE����ͨ��,��OFDM�����ز�����������Ϊ?NcNc����ôUE����?mm?�������ڵ�?cc?�����ز����յ����ź�?ym,cym,c?���Ա���Ϊ:

Figure 1. A IRS-assisted MIMO FDD communication system model
ͼ1. IRS�����µ�MIMO FDDͨ��ϵͳģ��
BS��Ҫ��ƺ�����Ԥ��������?vcvc?���������û�����Ž�������ͨ��������Ȼ����FDDģʽ��,BS��Ҫ��þ�ȷ��������·CSI���ܶ�·Ԥ�����������к�����ơ��ڸ�ϵͳ��,����ά�ȵ�������·��CSI?H��H��?����BS��UE�ŵ���CSI?H1��CNt��Ni��NcH1��CNt��Ni��Nc?��BS��IRS�ŵ���CSI?H2��CNi��Nr��NcH2��CNi��Nr��Nc?��IRS��UE�ŵ���CSI?H3��CNt��Nr��NcH3��CNt��Nr��Nc,��?H��=[H1,H2,H3]H��=[H1,H2,H3]��������CSI������ͼ2��ʾ��

Figure 2. Schematic of the complete CSI data
ͼ2. ������CSI����ʾ��ͼ
��Ϊʱ����չ��������,CSI�л��д�����0ֵ,���Է���IARNet��CSI������Խ�CSI�ضϲ�ֻ����ǰ?N?cN?c?�е���Ч����,�κ��CSI���Ա�ʾΪ?

������Ҫ�о����ѧϰ��IRS������ͨ��ϵͳCSIѹ����ָ�,��˼���UE�Ѿ�����˷���������CSI,�������ŵ��������,ͬʱ����BSҲ�������ؽ��յ�UE������������Ϣ��
��ϵͳ��UE��BS�ֱ������˱�������������,UE���ı��������Խ�ԭʼ��?JJ?ά��CSI?HH?ѹ����?KK?ά����?cc,ѹ���ȿ��Ա�ʾΪ:?��=K/J��=K/J,����?(K<J)(K<J)��������̿��Ա�ʾΪ:

ʽ��:?H?H^?��ʾ�ؽ����CSI����;?fdefde?��ʾ������;?��de��de?��ʾ�����������ѧϰ���������
Ϊ��������ϵͳ���ؽ�����,��ϵͳʹ�ù�һ���������(NMSE, Normalized Mean Squared Error)��Ϊ�жϱ�,NMSE��������ԭʼCSI���ؽ����CSI֮������,���ֵԽС��ʾϵͳ�ؽ�����Խ��,��˱�����Ҫ��Ŀ����ͨ���Ż�ϵͳģ����С����ֵ������NMSE����Ϊ:
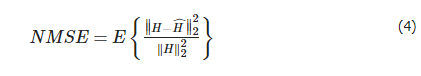
ʽ��:?��?��2��?��2?��ʾL2������
3. IARNet�Ľṹ
�����������IARNet���ѧϰ����ṹ��ͼ3��ʾ,����UE���ı�������BS���Ľ��������ɡ�IARNet���������ŵ�CSI?HH,?HH?�ľ���ߴ�Ϊ?128��16��6128��16��6,����128��ʾ�Ƕ�,16��ʾ�ضϺ�����ز���,6��ʾ����CSI��������ʵ����IARNet��������ؽ����CSI?H?H^,�ߴ��?HH?һ�¡�

Figure 3. Architecture of IARNet
ͼ3. IARNet�ļܹ�
�ڱ������ࡣģ�����Ƚ�?HH?������ע����ģ�����������ȡ����ģ��ͬʱ��ȡ��CSI�ڿռ��ͨ���ϵ�����,������ģ������ѧϰ������Ը�רע����Ϣ���������,��������Ȩ��,��֮������Ϣ��С������Ȩ��,��ǿ����������������Ȼ��,�����ݷ������������ģ�鴦������ģ����Ҫ�ǽ����Inception�����˼��,������ߴ������Ľ��ֱ�ӽ���ƴ�Ӵ���,�������ƴ�Ӻ�Ľ�����ж�ά��������Ϣ���ص㡣�����ģ�黹�����˷�������Ĵ��������Խ���ѵ�����������������û��ע����ģ�����������ȡ,��һ����ǿ��������������������,������Reshape�ɳ���Ϊ?128��16��6=12288128��16��6=12288?��һά�������������뵽��Ԫ����Ϊ?8704����8704����?��ȫ���Ӳ��������н���ѹ��,����8704��ʾ?HH?����Ч����,Ϊ�˶���6��ͨ���ijߴ�,?H��3H��3?��Ҫ��0����,����������·��沿�֡����,ͨ��������·��ѹ��������ݷ���BS�˵Ľ�������
�ڽ������ࡣģ�����Ƚ�����Ϊ?8704����8704����?��һά����Reshape��?HH?�ߴ��С�ľ���Ȼ��,�ý���������ģ�齫���ݽ��д�������ģ�������������ģ������,���Ǹ������������и�ģ�������˱����в�����,���һ��IJв�����,�������ܸ��ѡ����,����������ؽ����CSI����?H?H^��
���ע����ģ����Ҫ��ͨ��ע����ģ��Ϳռ�ע����ģ����������ɡ�ͨ��ע����ģ����,����ͨ�����ֲ��е�ƽ��ƽ���ػ���ƽ�����ػ��Ĵ���,�����ٽ����Ƿֱ�����MLP������֮��,���ͨ��Sigmoid������������ͨ��ͨ��ע����ģ�鴦����ģ��ע��ͨ��֮��Ĺ�ϵ���Զ�ѧϰ����ͬͨ����������Ҫ�̶ȡ��ռ�ע����ģ����,��ͨ��ע����ģ�������������Ϊ����,����ͨ���������е�ͨ��ƽ���ػ���ͨ�����ػ������������������������ͨ��ƴ��,Ȼ��ͨ������������ͨ����Ϊһά,������Sigmoid��������Ͳв����ͨ��ͨ��ע����ģ�鴦��,ģ�ͻ��ע��ͬһͨ���ϲ�ͬ����λ�õĹ�ϵ���Զ�ѧϰ����ͬ�ռ���������Ҫ�̶ȡ����ע����ģ��Ľṹ��ͼ4��ʾ�����ע����ģ�������Ϊ?128��16��6128��16��6?������,����6��ʾΪ��������ͨ����;16��ʾ�����ĸ߶ȼ����ز���;128��ʾ�����Ŀ��ȼ��Ƕ�;?1��61��6?��ʾMLP���������Ԫ����;????��ʾ����˷�;?����?��ʾ����ӷ�;
���ע����ģ��ͬʱ��ע����ͨ����Ϣ�Ϳռ���Ϣ����Ҫ��ϵ,��������Чͨ���Ϳռ��Ȩ��,��������Чͨ���Ϳռ��Ȩ��,�����������������ܡ�ͬʱ���ע����ģ�黹���Ժ����ؼ��ɵ����е����ѧϰ����ܹ���ȥ,����������������ߴ���ȫһ��,������������ø��Ӽͱ�ݡ�

Figure 4. Architecture of hybrid attention module
ͼ4. ���ע����ģ��ļܹ�
��������ģ��Ľṹ
����������ģ�鼰����������ģ����ͼ5��ʾ,����ÿ��������С���ֱ�ʾ�˲���ͨ����(�����˸���),�����ݴ����Ĺ�����CSI�ij�������,������Ϊ?128��16128��16?�ߴ������,ͨ�������ž����˱仯��
����?[15] ���Ѿ�֤������?3��33��3?�����Ͳв������CsiNet���ŵ�ѹ���е�Ӧ������Ч�ġ���CsiNet��һ�̶ֹ������ߴ������,�̶��ߴ���������µ����粢���ܺܺõ�ͬʱ��ȡϡ�������ܼ�����������������Ϻõ�ͬʱ��ȡϡ�������ܼ����������,����Ҫ����ͬʱ�ò�ͬ�ߴ��������CSI��С�ߴ�ľ�������(��?3��33��3?����)������ȡCSI���Ӿ�ϸ������,�ڴ����ܼ�CSI��ʱ��С�ߴ�ľ����и��õ�Ч������ߴ�ľ�������(��?9��99��9?����)�����ṩ����ĸ�����Ұ,�ڴ���ϡ��CSI��ʱ�����־����и��õ�Ч��������ڱ���������ģ��ͽ���������ģ���д���ʹ���˶�֧·���еĶ�ߴ��������,Ȼ��֧ͬ·�ϵĽ����ͨ����ֱ��ƴ������,�������Խ���ͬ�ߴ���������µĽ�����ж���������ں�,�����ӵ�и��ӷḻ���������ر����ڱ���������ģ����,Ϊ�˸�����ȡԭʼCSI������,����������ģ������ͬʱʹ����?3��33��3?������?5��55��5?������?7��77��7?�����Ͳв�IJ��д���,�⽫����طḻ���������������,ÿ������ģ����о�������ǰ��������һ������һ��������

Figure 5. Composite module of encoder (left) and decoder (right)
ͼ5. ����������ģ��(��)������������ģ��(��)
Ϊ���ٸ�������ģ���еIJ������������㸴�Ӷ�,ģ�ͻ������˷�������Ĵ����������ڷ��������ͨ�����²������ֽ�?M��MM��M?����������,��������?gg?����ԭ��������ͨ����ƽ���ֽ��?gg?��,ÿ��С�������ͨ����Ϊԭ����?1/g1/g,ÿһ��С��ľ����˸���ҲΪԭ����?1/g1/g,���ֳ������䡣Ȼ��,ÿ��С�����?M��MM��M?�ľ������㡣���,��ÿ��С��Ľ������ͨ��ƴ��,��������������ߴ粻�䡣�������ڽ�����?M��MM��M?������ֳ��˸�С��ģ��������,����Դ���Ƚ������㸴�Ӷ�,�����豸������Ҫ��
����,Ϊ�˽���ݶ���ʧ������,���ϵͳ������,��������ģ�黹�����˴����IJв����硣�ر����ڽ���������ģ���ĩ�˻������˱����в������,�������ɵ��������һ��С��1��ϵ��(���������0.7),�������ɵ�����������������,IARNet�������н�һ����������
4. ѧϰ�ʼ����������
�����ѧϰģ�͵�ѵ��������,ģ��ѵ��������ģ�͵����ճ���Ч�����ž����Ե�Ӱ�졣��һЩ�������ѧϰ���ŵ�ѹ�������о���,��ģ��ѵ����������Լ�Ҫ��,û������ض���ϵͳģ�ͽ�һ���Ż�ģ��ѵ������������CsiNet��DS-NLCsiNet��������,ģ�͵�batch size��epochs�ͳ�ʼѧϰ�ʷֱ�ֱ������Ϊ200��1000��0.001,Ҳû������ѧϰ�ʵ������ԡ���Щ���¶�ʡ���˶�ģ��ѵ�������Ľ���,�ر���ѧϰ�ʼ������������,����ǡǡ��ʮ����Ҫ�ġ�
���ѧϰ�����ù���,��Ȼϵͳѵ����ӿ�,�����ڲ����ݶ��½��㷨��Ѱ��ȫ�����Ž�Ĺ�����,��ʧ����������������ȫ����Сֵ���������ѧϰ�����ù�С,��Ȼ�������Ѱ�ҵ�ȫ�����Ž�,������Ứ�Ѵ�����ѵ��ʱ�䲢�Һ���������ֲ����Ž⡣����ѧϰ�ʵ������Զ�ϵͳѵ��Ҳ�кܴ��Ӱ��,һ����õIJ����й̶�������˥����(Step Decay)���Լ�����˥����(Cosine Decay)�ȡ��̶�����Ҫ�����������ҵ��Ϻõ�ѧϰ��,��������Ҳ����������ֲ����Ž⡣˥����ķ��������ڽϸߵ�ѧϰ���ϼ�������ѵ��,Ȼ���ڵ�ѧϰ����Ѱ�ҵ�ȫ�����Ž� [19]����IARNet��ģ��ѵ�������ϲ��û���������������˥��ѧϰ�ʵ������ԡ��������ѧϰ�����ڸտ�ʼѵ����ʱ��dz����ȶ�,����������Ҫ����ʼ��ѧϰ�����õúܵ�,����������ѧϰ���绺�����������ȶ��������������ȶ���ʱ��������ѧϰ��,�������������Կ��ٵ�����,������̾ͳ�֮Ϊ����,������֮��������˥���ķ�������ѧϰ�ʡ������Ϳ���������ѵ�����̱��ƽ�ȡ�����,ͬʱҲ������������ܡ���������ѧϰ�ʵ������Կ��Ա���Ϊ:
![]()
Figure 6. Learning rate adjustment strategy of cosine decay based on the warm-up method
ͼ6. ����������������˥��ѧϰ�ʵ�������
5. ������
���������BS������������Ϊ4,IRS�ķ��䵥Ԫ������Ϊ32,UE������������Ϊ4,���ز�������Ϊ128���������COST 2100�ŵ�ģ�� [20] ������Ƶ��Ϊ5.3GHz��Ƶ�������ڳ������������ݼ�������BS��IRS֮���ŵ��÷���������Ϊ4����������Ϊ32���ŵ����,IRS��UE֮���ŵ��÷���������Ϊ32����������Ϊ4���ŵ�ģ�������Ȼ��BS��IRS��IRS��UE�Լ�BS��UE��CSI��ͨ����ƴ����������Ϊʱ����չ��������,CSI�л��д�����0ֵ,���Խ�CSI�ضϲ�ֻ����ǰ16�е���Ч���ݡ�Ȼ�ضϺ�CSI�е�6��ͨ���������ߴ粹��,��BS��UE��CSI��?16��1616��16?��0ֵ��չ��?128��16128��16��6��ͨ������?128��16128��16?�ijߴ�,������Ч����Ϊ8704,��������Ϊ����CSI����0ֵ,ѹ�����ǰ�����Ч����8704��ѹ��������������㡣�����CSI�ijߴ�Ϊ:?128��16��6128��16��6������128��ʾΪ�Ƕ�;16Ϊ���ز�;6�ֱ�ΪBS��IRS��CSI��IRS��UE��CSI�Լ�BS��UE��CSI��������ʵ����
ʹ��COST 2100ģ������10������ݼ�,Ȼ����4:1�ı��������ݼ��ֳ�ѵ�����Ͳ��Լ���ģ��ѵ��ʱ,���þ������(MSE, Mean Squared Error)��Ϊϵͳ����ʧ����,ʹ��Adam�㷨 [21] ���²�����batch size����Ϊ150,epoch����Ϊ100,��ʼѧϰ������Ϊ0.0045��ʹ�û�����������ģ��ѵ������,?epoch��epoch��?����Ϊ20��
���ıȽ���IARNet��CRNet��CsiNet�ڲ�ͬѹ�����µ����ܱ���,������1��ʾ,�Ӵֱ�ʾΪ��ѹ�����µ�������ܱ��֡�����������,IARNet�ڴ�������CSIѹ�������¶Ա������������ѧϰ��CSI�ؽ��㷨�и��õ����ܱ���,��ʹ����1/32��ѹ������IARNet���ܽ�CSI�Ϻõ��ؽ�����,����Ҫ������IARNet�����˶���������ںϡ����ע���������Լ������в�ȷ����������������Ż�,���Ż������о��������˲���Ҫ�ļ��㿪��,�������籣�����ܵ�ͬʱҲ����������
| ѹ���� | ���ѧϰ���� | NMSE |
| 1/2 | CsiNet CRNet IARNet | 1.0889 0.5529 0.0273 |
| 1/4 | CsiNet CRNet IARNet | 1.0894 0.5537 0.0281 |
| 1/8 | CsiNet CRNet IARNet | 1.0902 0.5625 0.0680 |
| 1/16 | CsiNet CRNet IARNet | 1.0910 0.6172 0.1740 |
| 1/32 | CsiNet CRNet IARNet | 1.0919 0.6578 0.3841 |
| 1/64 | CsiNet CRNet IARNet | 1.2300 0.8266 0.6076 |
Table 1. Comparison of NMSE performance of IARNet with CRNet and CsiNet
��1. IARNet��CRNet��CsiNet�㷨��NMSE���ܱȽ�
ͼ7��IARNet��CRNet��CsiNet��ѹ����Ϊ1/8��ϵͳ��NMSE����epoch�仯�����ߡ���ͼ7��ʾ,��ѵ��������,CsiNet��NMSEʼ�ձ��ֽϸߵ�ˮƽ,NMSE�������25.112������1.0902,��������ݼ�������ϵͳ��ѧϰ����,CsiNet��ѧϰ���ؽ�����������CSI��CRNet��NMSE�������3.11����������0.5625,����33��epoch��ϵͳ��NMSE��������,�����CRNet����ѧϰ���ؽ�����CSI������,�����ؽ��������ѡ�IARNet��NMSE�������0.9912����������0.0680,NMSE����������ѵ�������ж������½�,��90��epoch����ƽ��,�����IARNet���Ժܺõ�ѧϰ���ؽ��ֵ�CSI����,�ؽ������ѡ�
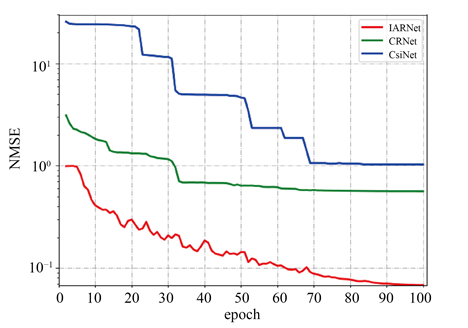
Figure 7. NMSE variation curves of three networks at 1/8 compression ratio during the training process
ͼ7. ѵ������������������1/8ѹ�����µ�NMSE�仯����
ͼ8��IARNet��ѹ����Ϊ1/8��ϵͳ�IJ��Լ���ʧ������ѵ��������ʧ��������epoch�仯�����ߡ���ͼ7�ɼ�,���Լ���ʧ������ѵ��������ʧ��������epoch���Ӷ�����,���Լ���ʧ������ѵ������ʧ��������������ѵ��������,ѵ��������ʧ��������������0.03����,ѵ��������ʧ��������������0.05����,��˵��IARNet�����Ĺ����,���������Ͽ��Ժ��Բ��ơ�
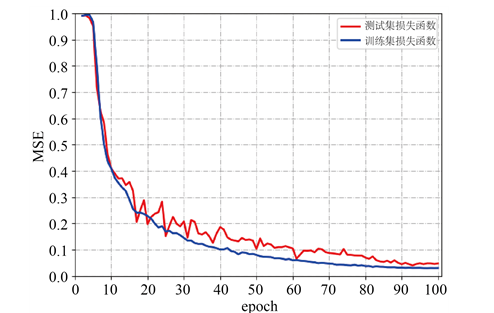
Figure 8. Comparison of the loss functions of the training and test sets
ͼ8. ѵ�����Ͳ��Լ�����ʧ�����Ա�
���Ȿ�Ļ��Ƚ�������ѧϰ�ʵ��������������ѳ�ʼѧϰ����ѹ����Ϊ1/8����¶�IARNet���ܵ�Ӱ�졣��һ���DZ��������û���������������˥������,��ѳ�ʼѧϰ��Ϊ0.0045���ڶ��ַ����ǹ̶���,��ѳ�ʼѧϰ��Ϊ:0.0002�������ַ����Dz�˥����,��ѳ�ʼѧϰ��Ϊ:0.001�������ַ���������˥����,��ѳ�ʼѧϰ��Ϊ0.0003��NMSE����ѵ�������ƽ��ķ���仯������ͼ9��ʾ����ͼ9����������,����ڴ�ͳ��ѧϰ�ʵ�������,���������õķ���������ϵͳ�и��õ��ؽ�����,NMSE���������͵�ˮƽ,�ɴ�0.0683�����̶�������˥����������˥����ѵ�����ϵͳ�ֱ�������0.1572��0.0903��0.1822����ȴ�ͳ�ķ�������������ѧϰ�ʵ������Ե��ؽ�������������24.9%��
Figure 9. NMSE variation curves of four learning rate adjustment strategies during training
ͼ9. ѵ������������ѧϰ�ʵ������Ե�NMSE�仯����
�����2�Ƚ���IARNet��CRNet��CsiNet�ڲ�ͬѹ�����µIJ�����,M��ʾ����IARNet������1/64ѹ�����²���������CRNet��CsiNe����,����ѹ�����µIJ�������С��IARNet��CRNet,���IARNet���Խ��ر������ڸ����豸����,��ʡ�豸�洢�ռ䡣
| ѹ���� | 1/2 | 1/4 | 1/8 | 1/16 | 1/32 | 1/64 | |
| ������ | CsiNet | 67.22M | 33.63M | 16.82M | 16.82M | 4.26M | 2.21M |
| CRNet | 67.13M | 33.57M | 16.79M | 16.79M | 4.21M | 2.11M | |
| IARNet | 40.95M | 24.17M | 15.78M | 15.78M | 3.91M | 2.86M |
Table 2. Comparison of the number of parameters of IARNet with CRNet and CsiNet at different compression ratios
��2. IARNet��CRNet��CsiNet�ڲ�ͬѹ�����µIJ������Ƚ�
6. ����
�������IRS������ͨ��ϵͳ�з����������Ӿ�����������һ���µ����ѧ����IARNet���������ڴ�ͳ��Inception����ṹ�Ͻ���˶���������ںϡ����ע���������Լ��в����ģ��,���ֻ�Ͻṹ������Ч�ؽ�����������CSI����ѹ���ؽ����������������ʾIARNet��IRSͨ��ϵͳ�жԴ���������CSI����ѹ���ؽ��и��õı���,���һ�����������ģ��ѵ���������ڴ�ͳ�Ĺ̶�����˥���෨��

���ǵķ�������
�����γ�
�˹����ܡ������ݡ�Ƕ��ʽ? ? ? ? ? ? ??? ?? ?
��ѵ�γ�
��ͨ��ѵ��������ѵ? ? ? ? ? ? ? ?? ??? ? ??
��Ŀ��ѯ
����·����ơ��㷨�����ʵ��(ͼ��������Ȼ���Դ���������ʶ��)


?