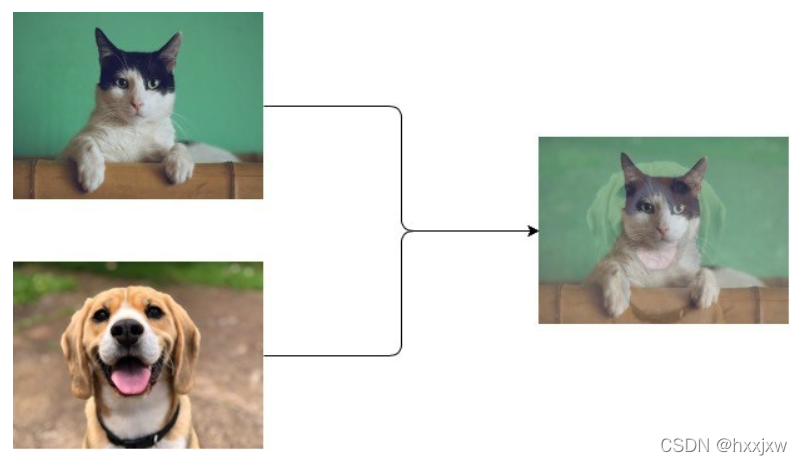
?
?这在不同类之间提供了连续的数据样本,直观地扩展了给定训练集的分布,从而使网络在测试阶段更加健壮。
Pytorch实现
在CIFAR-10数据集上
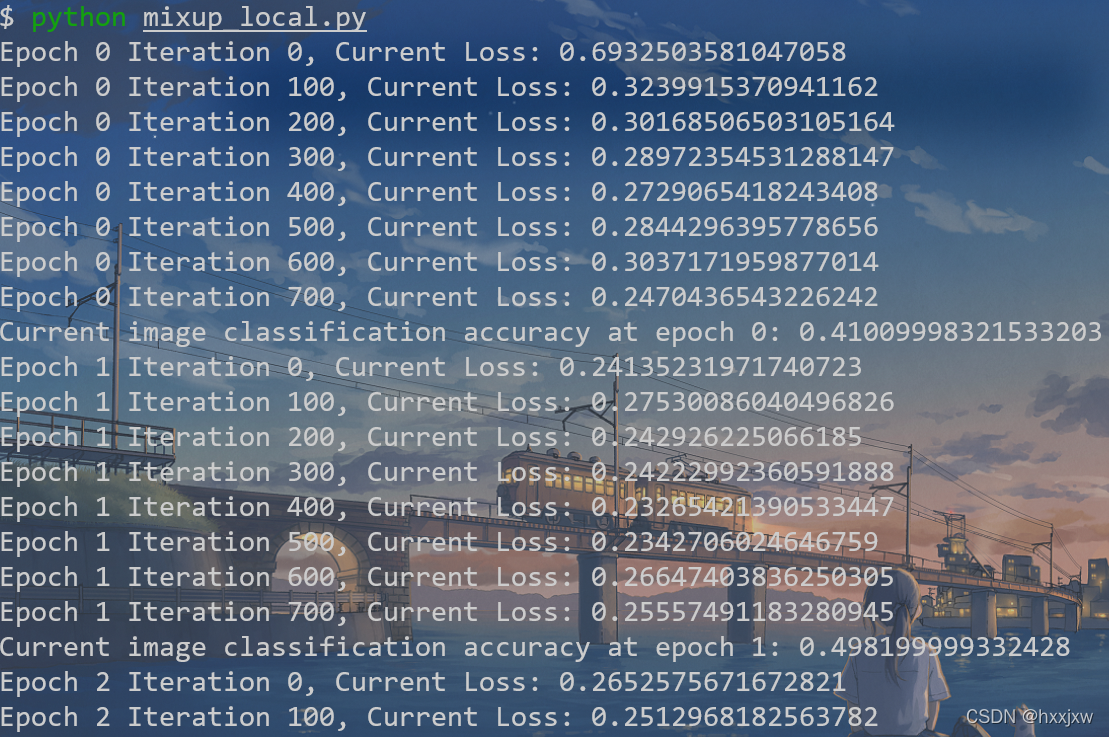
""" Import necessary libraries to train a network using mixup The code is mainly developed using the PyTorch library """ import numpy as np import pickle import random import torch import torch.nn as nn import torch.nn.functional as F import torchvision import torchvision.transforms as transforms from torch.utils.data import Dataset, DataLoader """ Determine if any GPUs are available """ device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') """ Create a simple CNN """ class CNN(nn.Module): def __init__(self): super(CNN, self).__init__() # Network consists of 4 convolutional layers followed by 2 fully-connected layers self.conv11 = nn.Conv2d(3, 64, 3) self.conv12 = nn.Conv2d(64, 64, 3) self.conv21 = nn.Conv2d(64, 128, 3) self.conv22 = nn.Conv2d(128, 128, 3) self.fc1 = nn.Linear(128 * 5 * 5, 256) self.fc2 = nn.Linear(256, 10) def forward(self, x): x = F.relu(self.conv11(x)) x = F.relu(self.conv12(x)) x = F.max_pool2d(x, (2,2)) x = F.relu(self.conv21(x)) x = F.relu(self.conv22(x)) x = F.max_pool2d(x, (2,2)) # Size is calculated based on kernel size 3 and padding 0 x = x.view(-1, 128 * 5 * 5) x = F.relu(self.fc1(x)) x = self.fc2(x) return nn.Sigmoid()(x) """ Dataset and Dataloader creation All data are downloaded found via Graviti Open Dataset which links to CIFAR-10 official page The dataset implementation is where mixup take place """ class CIFAR_Dataset(Dataset): def __init__(self, data_dir, train, transform): self.data_dir = data_dir self.train = train self.transform = transform self.data = [] self.targets = [] # Loading all the data depending on whether the dataset is training or testing if self.train: for i in range(5): with open(data_dir + 'data_batch_' + str(i+1), 'rb') as f: entry = pickle.load(f, encoding='latin1') self.data.append(entry['data']) self.targets.extend(entry['labels']) else: with open(data_dir + 'test_batch', 'rb') as f: entry = pickle.load(f, encoding='latin1') self.data.append(entry['data']) self.targets.extend(entry['labels']) # Reshape it and turn it into the HWC format which PyTorch takes in the images # Original CIFAR format can be seen via its official page self.data = np.vstack(self.data).reshape(-1, 3, 32, 32) self.data = self.data.transpose((0, 2, 3, 1)) def __len__(self): return len(self.data) def __getitem__(self, idx): # Create a one hot label label = torch.zeros(10) label[self.targets[idx]] = 1. # Transform the image by converting to tensor and normalizing it if self.transform: image = transform(self.data[idx]) # If data is for training, perform mixup, only perform mixup roughly on 1 for every 5 images if self.train and idx > 0 and idx%5 == 0: # Choose another image/label randomly mixup_idx = random.randint(0, len(self.data)-1) mixup_label = torch.zeros(10) label[self.targets[mixup_idx]] = 1. if self.transform: mixup_image = transform(self.data[mixup_idx]) # Select a random number from the given beta distribution # Mixup the images accordingly alpha = 0.2 lam = np.random.beta(alpha, alpha) image = lam * image + (1 - lam) * mixup_image label = lam * label + (1 - lam) * mixup_label return image, label """ Define the hyperparameters, image transform components, and the dataset/dataloaders """ transform = transforms.Compose( [transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]) BATCH_SIZE = 64 NUM_WORKERS = 4 LEARNING_RATE = 0.0001 NUM_EPOCHS = 30 train_dataset = CIFAR_Dataset('../lian/dataset/cifar-10-batches-py/', 1, transform) train_dataloader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True, num_workers=NUM_WORKERS) test_dataset = CIFAR_Dataset('../lian/dataset/cifar-10-batches-py/', 0, transform) test_dataloader = DataLoader(test_dataset, batch_size=BATCH_SIZE, shuffle=False, num_workers=NUM_WORKERS) """ Initialize the network, loss Adam optimizer Torch BCE Loss does not support mixup labels (not 1 or 0), so we implement our own """ net = CNN().to(device) optimizer = torch.optim.Adam(net.parameters(), lr=LEARNING_RATE) def bceloss(x, y): eps = 1e-6 return -torch.mean(y * torch.log(x + eps) + (1 - y) * torch.log(1 - x + eps)) best_Acc = 0 """ Training Procedure """ for epoch in range(NUM_EPOCHS): net.train() # We train and visualize the loss every 100 iterations for idx, (imgs, labels) in enumerate(train_dataloader): imgs = imgs.to(device) labels = labels.to(device) preds = net(imgs) loss = bceloss(preds, labels) optimizer.zero_grad() loss.backward() optimizer.step() if idx%100 == 0: print("Epoch {} Iteration {}, Current Loss: {}".format(epoch, idx, loss)) # We evaluate the network after every epoch based on test set accuracy net.eval() with torch.no_grad(): total = 0 numCorrect = 0 for (imgs, labels) in test_dataloader: imgs = imgs.to(device) labels = labels.to(device) preds = net(imgs) numCorrect += (torch.argmax(preds, dim=1) == torch.argmax(labels, dim=1)).float().sum() total += len(imgs) acc = numCorrect/total print("Current image classification accuracy at epoch {}: {}".format(epoch, acc)) if acc > best_Acc: best_Acc = acc """ Printing out overall best result """ print("Best Result: {}".format(best_Acc))
?