��python ��ʹ��֧��������
������python��ʹ��SVM
3.1 scikit-learn��
??Scikit-learn(sklearn)��һ����Դ��Ŀ,�������ʹ�úͷַ�,�κ��˶��������ɻ�ȡ��Դ�������鿴�䱳���ԭ����Scikit-learn��Ŀ���ڲ��ϵؿ����Ľ���,�����û������dz���Ծ������������Ŀǰ���Ƚ��Ļ���ѧϰ�㷨,ÿ���㷨������ϸ���ĵ� (http:// scikit-learn.org/stable/documentation
??scikit-learn��һ���dz����еĹ���,Ҳ���������� Python����ѧϰ�⡣���㷺Ӧ���ڹ�ҵ���ѧ����,�����д����Ľ̳̺ʹ���Ƭ�Ρ�
3.2 SVM��scikit-learn���е�ʹ��
3.2.1 svm.SVC
# Create SVM classification object
sklearn.svm.SVC(C=1.0, kernel='rbf', degree=3, gamma='auto', coef0=0.0, shrinking=True, probability=False, tol=0.001, cache_size=200, class_weight=None, verbose=False, max_iter=-1, decision_function_shape=None,random_state=None)
����:
C
??C-SVC�ijͷ�����C,Ĭ��ֵ��1.0������ͼ��CȨ��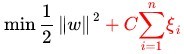
??CԽ��,�൱�ڳͷ��ɳڱ���,ϣ���ɳڱ����ӽ�0,���������ijͷ�����,�����ڶ�ѵ����ȫ�ֶԵ����,������ѵ��������ʱȷ�ʺܸ�,��������������CֵС,�������ijͷ���С,�����ݴ�,�����ǵ���������,����������ǿ��
kernel
??�˺���,Ĭ����rbf,�����ǡ�linear��, ��poly��, ��rbf��, ��sigmoid��, ��precomputed��
�C ����:u��v
�C ����ʽ:(gamma*u��v + coef0)^degree
�C RBF����:exp(-gamma|u-v|^2)
�C sigmoid:tanh(gammau��*v + coef0)
degree
??����ʽpoly������ά��,Ĭ����3,ѡ�������˺���ʱ�ᱻ���ԡ�
gamma
??��rbf��,��poly�� �͡�sigmoid���ĺ˺���������Ĭ���ǡ�auto��,���ѡ��1/n_features
coef0
??�˺����ij�������ڡ�poly���� ��sigmoid�����á�
probability
??�Ƿ���ø��ʹ��ơ�Ĭ��ΪFalse,�������Ϳ�ѡ��
??�����Ƿ����ø��ʹ��ơ���Ҫ��ѵ��fit()ģ��ʱ�����������,֮���������صķ���:predict_proba��predict_log_proba
shrinking
??�Ƿ����shrinking heuristic����(����ʽ����),Ĭ��Ϊtrue
tol
??ֹͣѵ�������ֵ��С,Ĭ��Ϊ1e-3
cache_size
??�˺���cache�����С,Ĭ��Ϊ200
class_weigh
??t����Ȩ��,�ֵ���ʽ���ݡ����õڼ���IJ���CΪweight*C(C-SVC�е�C)
verbose
??�����������
max_iter
??������������-1Ϊ�����ơ�
decision_function_shape
??��ovo��, ��ovr�� or None, default=None3
random_state
??����ϴ��ʱ������ֵ,intֵ
??��Ҫ���ڵIJ�����:C��kernel��degree��gamma��coef0��
����:
??fit(X, y):ѵ��ģ�͡�
??predict(X):��ģ�ͽ���Ԥ��,����Ԥ��ֵ��
??score(X, y[, sample_weight]):������(X, y)��Ԥ���ȷ��(accuracy)��
??predict_log_proba(X): ����һ������,�����Ԫ��������XԤ��Ϊ�������ĸ��ʵĶ���ֵ��
??predict_proba(X): ����һ������,�����Ԫ��������XԤ��Ϊ�������ĸ���ֵ��
3.2.2 datasets
??datasets�кܶ����õġ���������ѵ���㷨ģ�͵����ݿ⡣��Ҫ������:
1.��װ�õľ������ݡ��ڴ������ԡ�load����ͷ��
2.�Լ���Ʋ���,Ȼ�����ɵ����ݡ��ڴ������ԡ�make����ͷ��
(һ) ��ʿ�ٷ���
??ͳ���˲�ʿ��506�����ݵ�13�ֲ�ͬ����( �����������ʡ�һ������Ũ�ȡ�סլƽ��������������������ļ�Ȩ�����Լ���ס��ƽ�����۵� )�Լ����ݵļ۸�,�����ڻع�����
boston = datasets.load_boston() # ���벨ʿ�ٷ�������
(��) ��
??������ݼ�������150���β������,��Ӧ3���β��,��50������,�Լ����Ǹ��Զ�Ӧ��4�ֹ��ڻ����ε����� ,�����ڷ�������
iris = datasets.load_iris() # ����������
(��) ����
??��Ҫ����442��ʵ��,ÿ��ʵ��10������ֵ,�ֱ���:Age(����)���Ա�(Sex)��Body mass index(����ָ��)��Average Blood Pressure(ƽ��Ѫѹ)��S1~S6һ�������ָ��,TargetΪһ������Ķ���ָ��, �����ڻع�����
diabetes = datasets.load_diabetes() # ������������
(��) �����
??����1797������,ÿ��������64��Ԫ��,��Ӧ��һ��8x8���ص���ɵľ���,ÿһ��ֵ����Ҷ�ֵ, targetֵ��0-9,�����ڷ�������
digits = datasets.load_digits() # �������������