Vit:
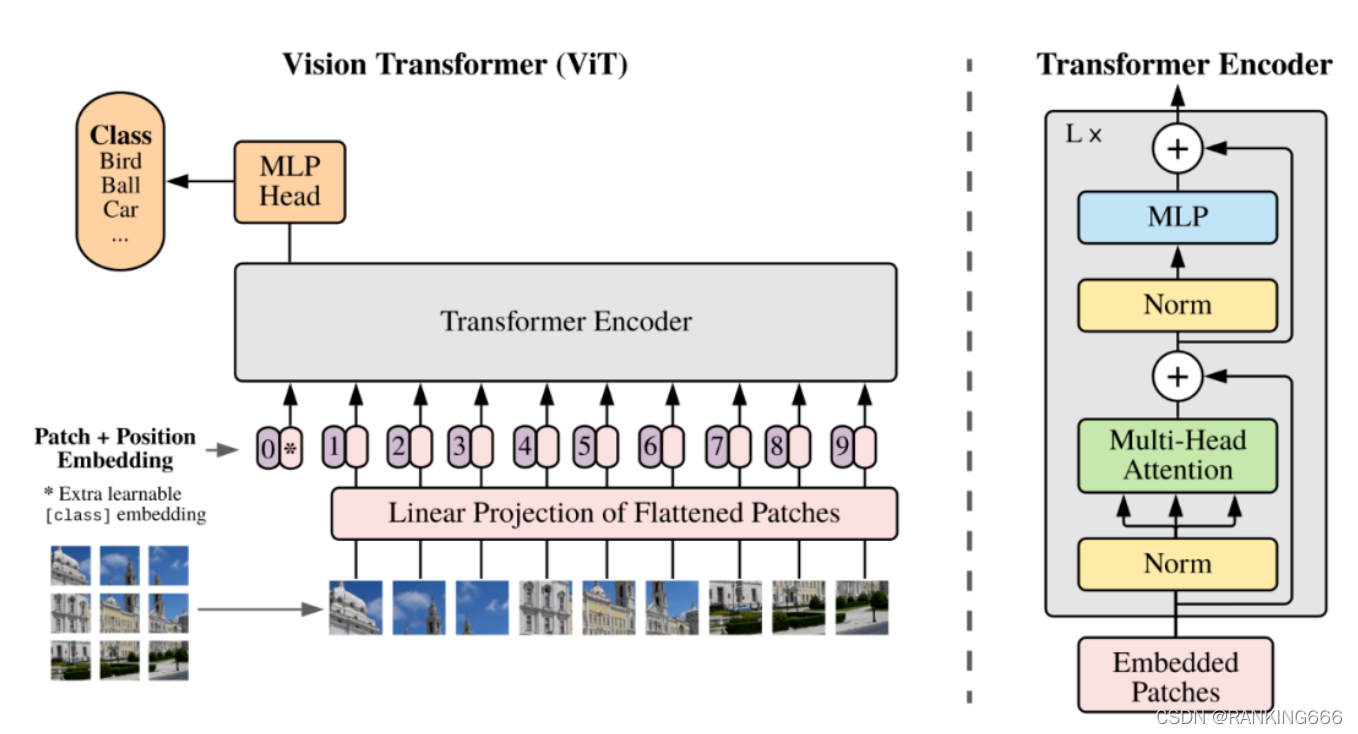
?????? �������,���ǽ�transformer��encoderȡ������
����ͼ���Сά��(B,C,H,W),��ͼƬ���ص��ػ���ΪH/patch_height * w/patch_weight��patch,ÿ��patchΪpatch_height * patch_weight * c��
֮��,concat���ڷ����cls token,ά��+1,ͬʱ�����ѧϰ�ľ���λ�ñ���,����transformer�����塣
?????? ֮�����tansformer�ļ�����ͬ,���ﲻ��������
���Ҫ����mask����,Ӧ����δsoftmaxǰ��attention weights�������Ρ�
�����������ͷʱ,����ѡ�������patch���ֵ��ֻ����cls token��
Deit:
?????? DeiT����ViT�Ļ�����,�������һ��distill token��������ѧϰ��
?????? ��ƪ�����������������:
������:
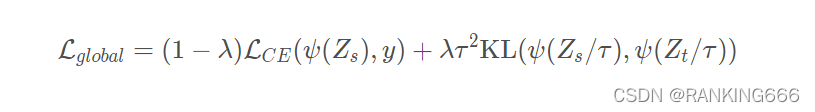
��,���dz�����,y ��ground truth,����softmax����,Zs��Zt�ֱ���ѧ��ģ�͡���ʦģ�͵����, LCE�ǽ�������ʧ,K L��KLɢ�ȡ�
KLɢ��Ҳ���������,Ҳ�����������������ʷֲ���һ�ֲ���
Ӳ����:
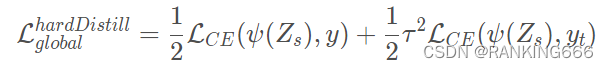
?????? Ҳ���Ǽ���ѧ��������ֱ�������ʵ��ǩ,yt��ʦ�������ʧ��
DeepViT:
????? ��Ҫ����VIT���,����ע�������ѧϰ����Ч�ı���ѧϰ����,�谭��ģ�ͻ��Ԥ�ڵ��������档Ҳ���dz�����ע����̮�������⡣
?????? ������һ�۲�,Ϊ�˽��ע��������������,����Ч�ؽ��Ӿ�ת����չ������IJ���,�����һ�ּ���Ч������ע������C��ע��(re-attention)����ViTs�С�
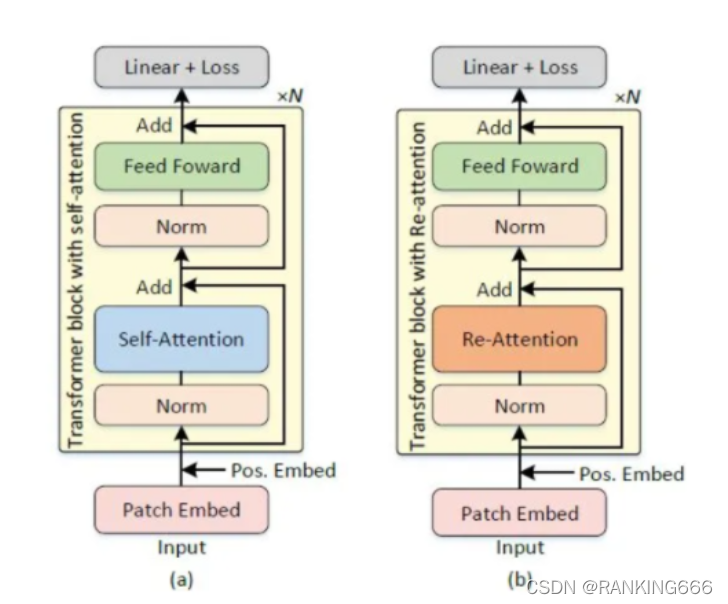
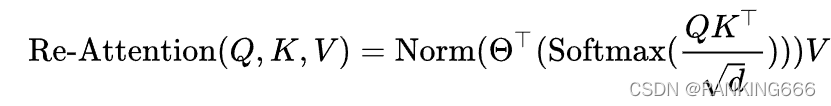
������һ���˵��˿�ѧϰ�ı任����,�任��������ͷ��ά�ȳ�����ע����ӳ��ͼ,����ͷע����ӳ��ͼ��ϵ��������ɵ��µ�ע����ӳ��ͼ��,����Normȡ����BatchNorm�����Ǵ�ͳ��LayerNorm,Ȼ����Value��ˡ�ʵ��ʱ,�任������һ��(heads,head,1,1)�Ķ�ά������
Cait:
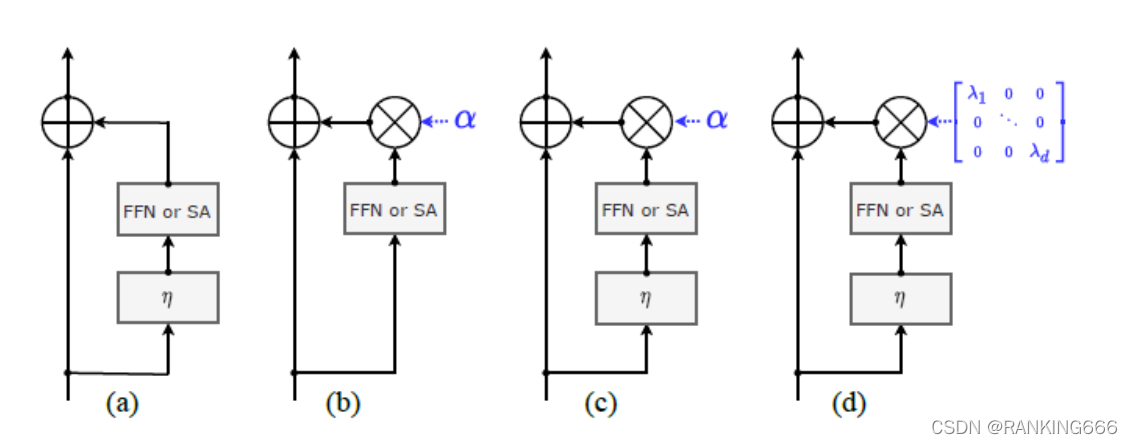
?????? (b)(c)�е� �� ��һ��ʵ��,��,FFN��SA�����������ͳһ������;��ͼ(d)��,FFN��SA��������IJ�ͬchannel���ϲ�ͬ����ֵ,��һ���̶��ϻ�ʹ��������ϸ��,������
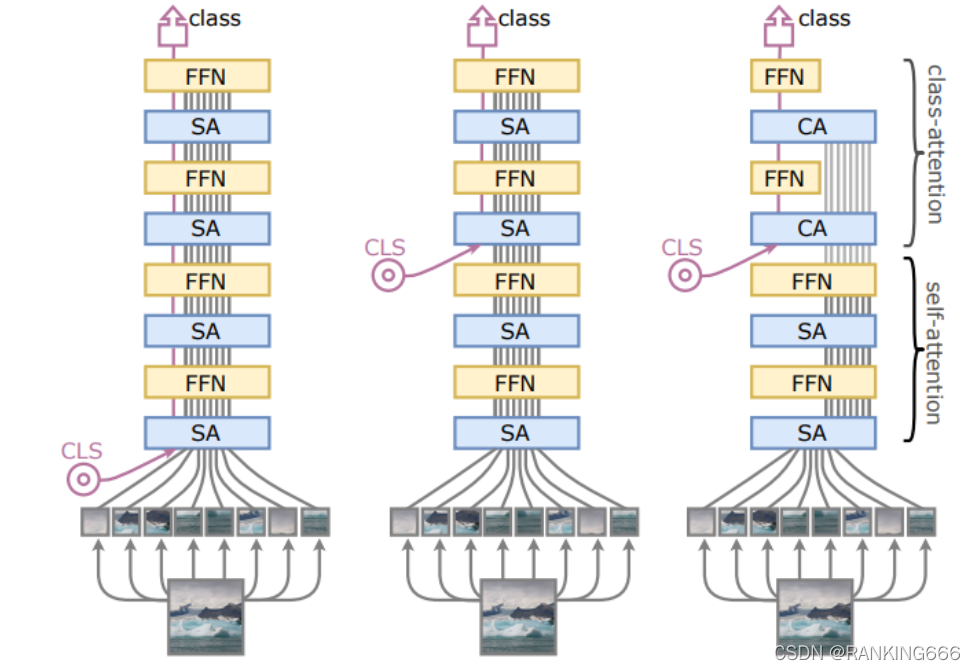
?????? ��������Ϊ,��Ȼ���ڷ����cls tokenֻ��Ϊ�˻��ͼƬ��ȫ����Ϣ,��ô��ȫ������һ��ʼ���������������Ϣ����,ֻ���������transformer���������Ϣ������
CPVT:
?????? ��ƪ������Ҫ�IJ��ص�����,λ�õı��롣������position encoding��ʽ��������λ�ñ�������λ�ñ���ȡ�
Ŀǰ���õ�һ���Ǿ���λ�ñ���,������Transformer�������sinusoidal���뷽ʽ,�Լ���GPT,ViT������ʹ�õĿ�ѵ����λ�ñ���ȡ�����һ��ľ���λ�ñ�������ض��ֱ��ʵ�����,��ѵ��ʱ�ͻ����ɹ̶��ߴ�ı���,��������ͬ�ֱ��ʴ�С��ͼƬ,�⼫��ط�����Transformer������Ժ����Ӧ�ÿռ䡣�����Ĵ�����ʽ���ڴ�����ͬ�ֱ��ʵ�ͼ��ʱ,��ѵ���õ�position encoding���в�ֵ����,����Ҫfine-tune���ָ�,��Ȼ����ɽϴ�ľ����½���
����,������������һ���ܹ����ݲ�ͬ�ߴ�����ı䳤�ȵ�position encoding ��ʽ
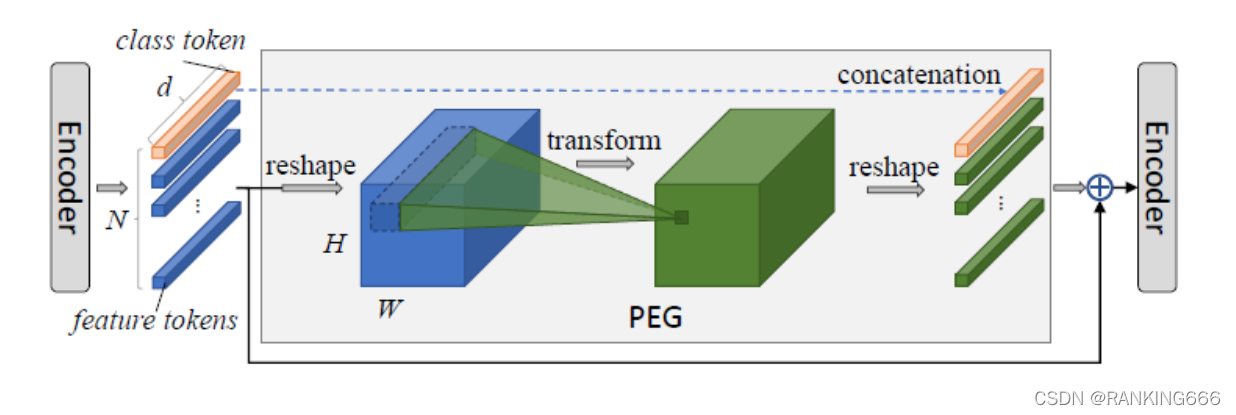
���ȶ���һ��transformer encoder���������reshape,����Ϊ2D��ͼ����ʽ;
Ȼ��Ը�2D��Ϣ����һ��2D�ɷ�������������оֲ���Ϣ����ȡ;
���������ɵ�tensor����reshape�����л���Ϣ��ʽ��Ϊ�����
����class token�в�����λ�������Ϣ,��˽�����벻����PEG�IJ�����
CVT:
?????? ��������transformer�����������,Ѱ�������Ϸ�ʽ,�Ӷ�������Ӿ�Transformer(ViT)�����ܺ�Ч�ʡ�
CvT������������ͼ��ʾ����ViT�ܹ���������2�ֻ��ھ����IJ���,������TokenǶ��;���ӳ�䡣
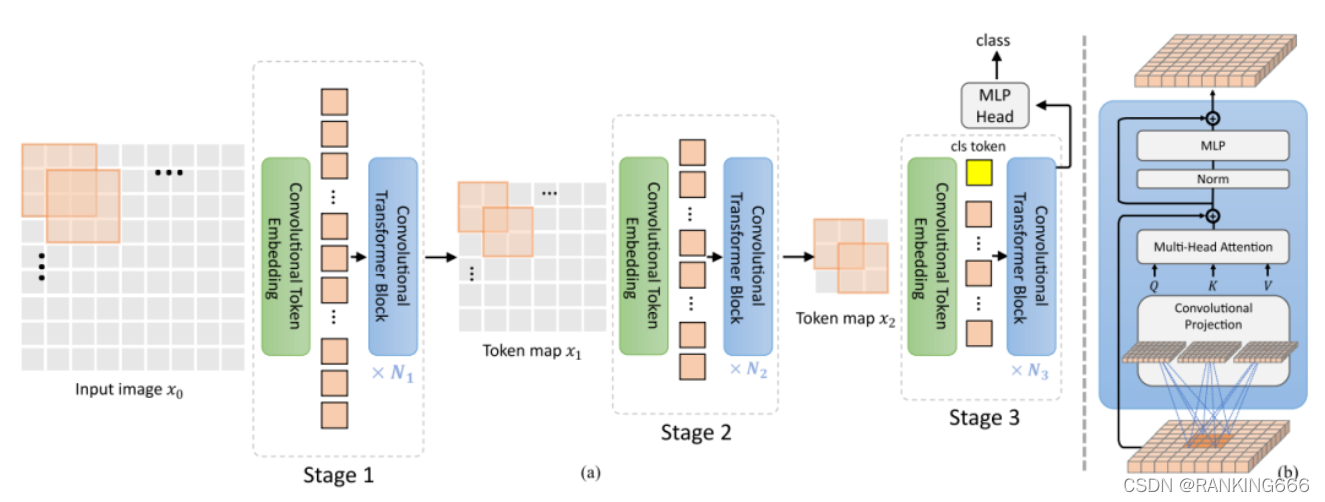
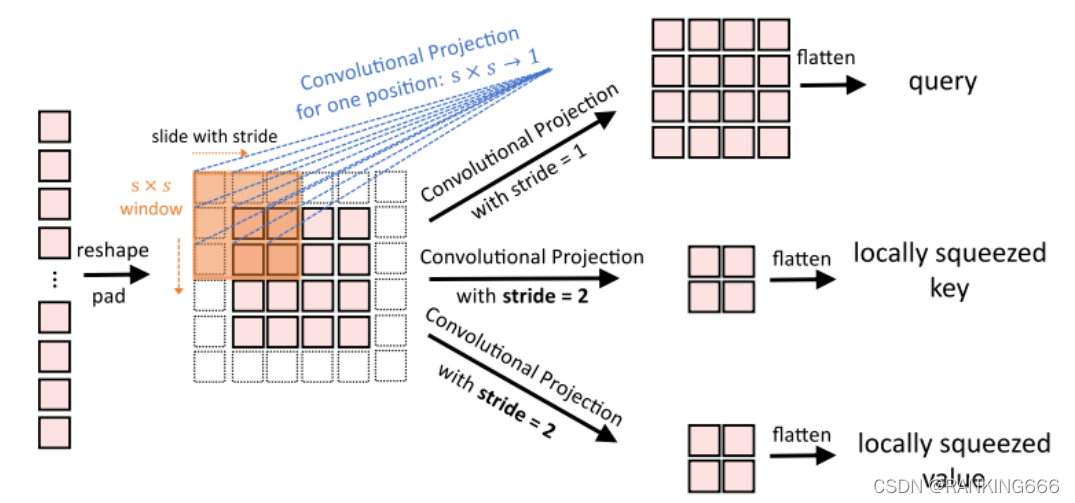
����TokenҲ����,��VIT��ʹ��linearʵ��patch_embedding��pos_embedding,��������ʹ�þ������������ÿһ��stage,������о���+LN��token embedding��������ÿ��������Token������(�������ֱ���),ͬʱ����Token�Ŀ���(������ά��),�Ӷ�ʵ�ֿռ��²��������ӷḻ�ȡ�
��Q,K,V�ļ�����ʹ����ȿɷ���ľ�������,��Ϊ����ӳ��,�ֱ����ڲ�ѯ������ֵ��Ƕ��,������ViT�б���λ������ӳ�䡣����,����Tokenֻ���������ӡ�
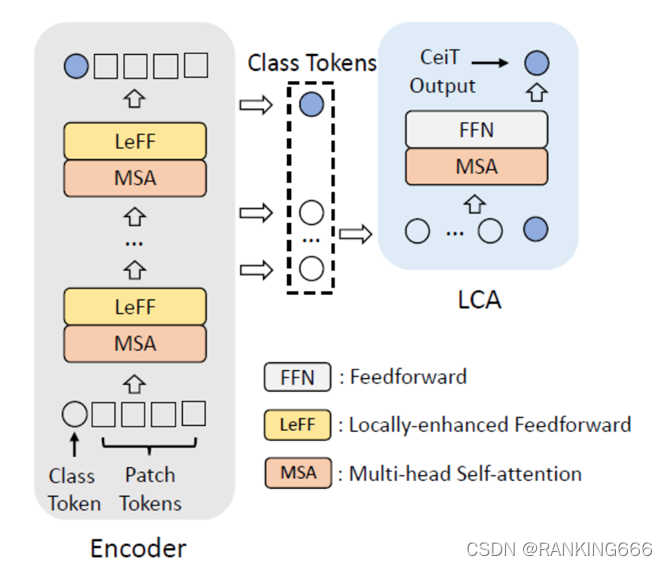
CeiT:
????? ������ͬ��,Ҳ��ϣ����CNN��transformer���ϡ�
?????? ��Ҫ�Ĵ��µ�������:
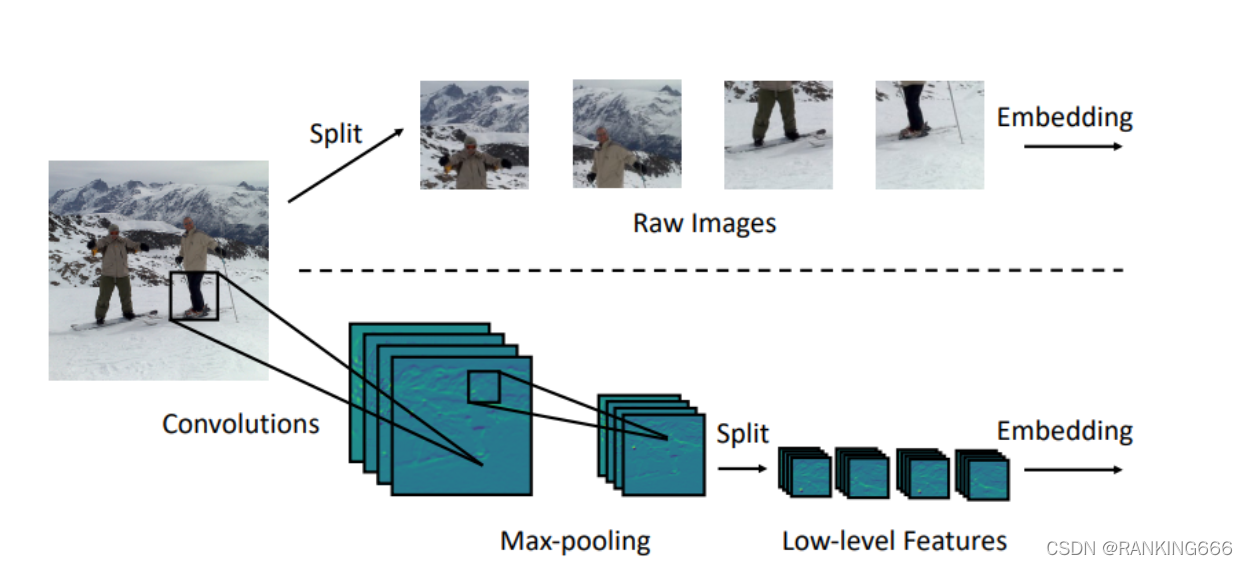
?????? �������Image-to-Tokensģ������low-level�����еõ�embedding��
?????? �������Transformer�е�Feed Forwardģ���滻ΪLocally-enhanced Feed-Forward(LeFF)ģ��,����������token֮�������ԡ�
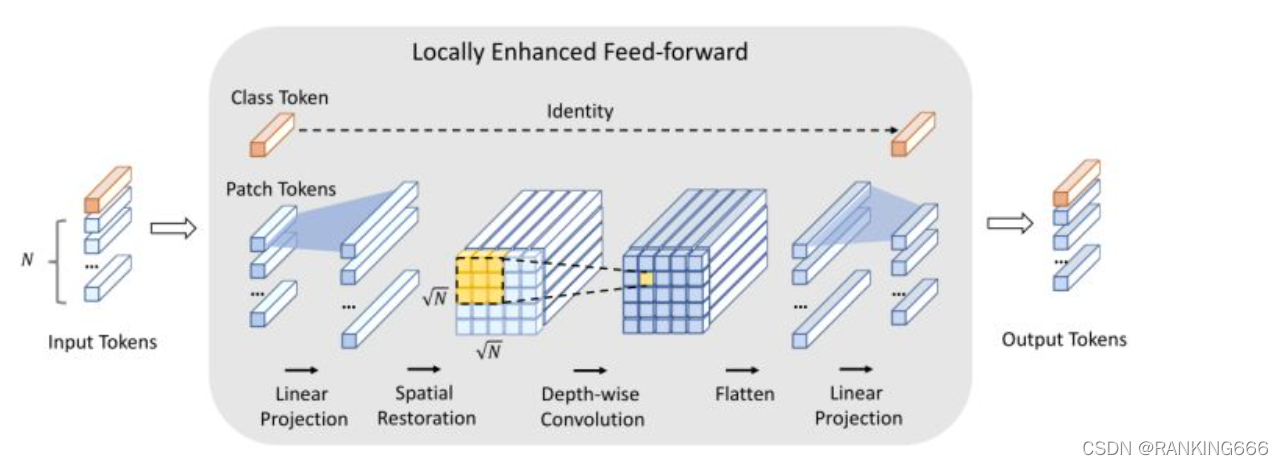
?????? Ҳ������mlp�м��˾������ںϲ�ͬͨ����������
?????? ����DZ�����Ϊͻ����һ���ص�ʹ��Layer-wise Class Token Attention(LCA)�������������ʾ��Ҳ���ǽ�ǰ������stage��class tokenȡ����,�����е�class token�������ǰ��,�������Ϣ������
?
????????
���д���,��ӭ�������ָ��!