��ƪ������2014���һƪ����,����Ҫ�������������Ƴ���SRCNN�����ѧϰ�ڳ����Ͽ�ƪ֮��!SRCNN֤�������ѧϰ�ڳ��������Ӧ�ÿ��Գ�Խ��ͳ�IJ�ֵ�Ȱ취ȡ�ýϸߵı�������
�ο�Ŀ¼:
�����ѧϰͼ�ֱ��ʿ�ɽ֮��SRCNN(һ)ԭ������
�����ѧϰ�˵��˳��ֱ��ʷ�����չ����
SRCNN
1 SRCNN���
-
�����Ƴ���һ�ֻ���SISR�ij��ַ��������ַ����������ѧϰ,ּ��ʵ��һ���˶Զ�������ģ�͡���
SRCNN,�����ڽ��ͷֱ��ʵ�ͼ��ת��Ϊ�߷ֱ�ͼ������ָ��,SRCNN�ڵ�ʱ�����ݼ��´ﵽ��SOAT��ˮƽ�� -
SRCNN���нṹ���ҵ�ʧ��ȵ��ص�:
 ����ͼ��ʾ,ֻ��Ҫһ����ѵ���غ�,SRCNN�Ϳ��Գ�����ͳ�ij��ַ�����
����ͼ��ʾ,ֻ��Ҫһ����ѵ���غ�,SRCNN�Ϳ��Գ�����ͳ�ij��ַ����� -
��һ�������ľ�����ṹ��,SRCNN���Դﵽfast-training��
-
ʵ�����,��һ����Χ��,Խ������ݼ��ͽϴ������ģ�Ϳ�������SRCNN��ͼ����ؽ�Ч����
2 SRCNNģ�ͽṹ
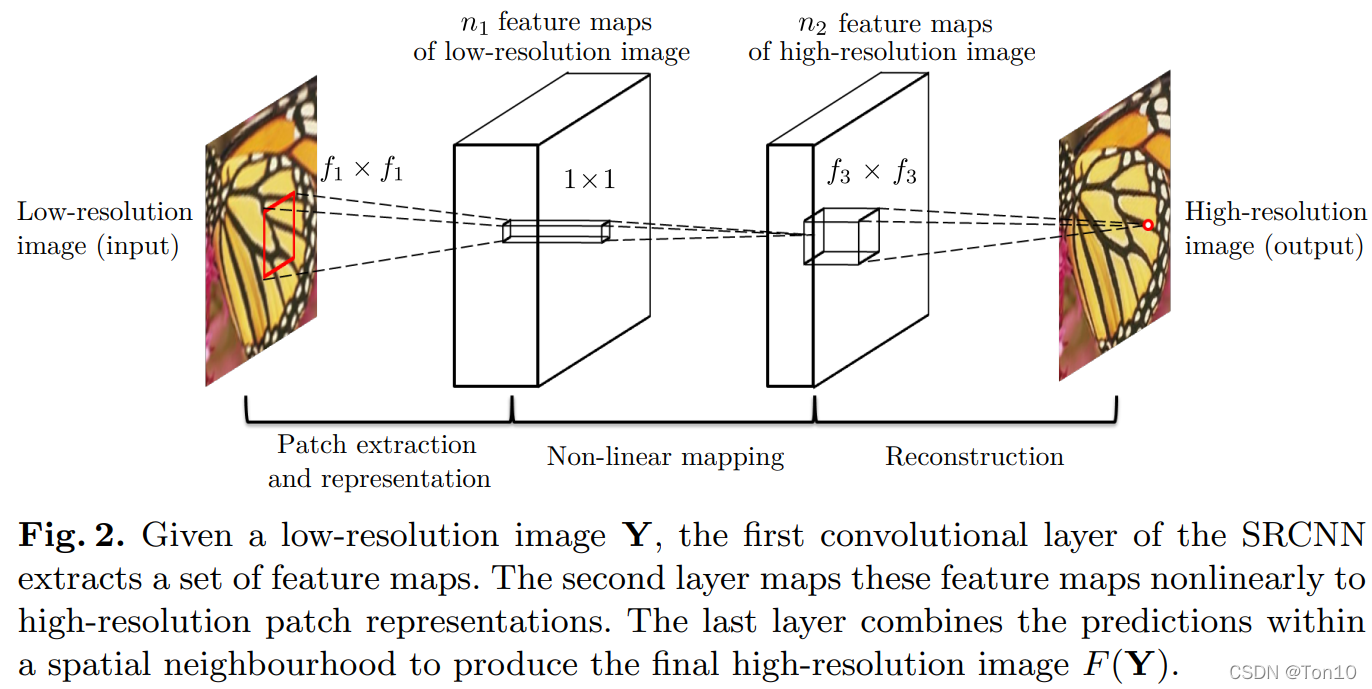
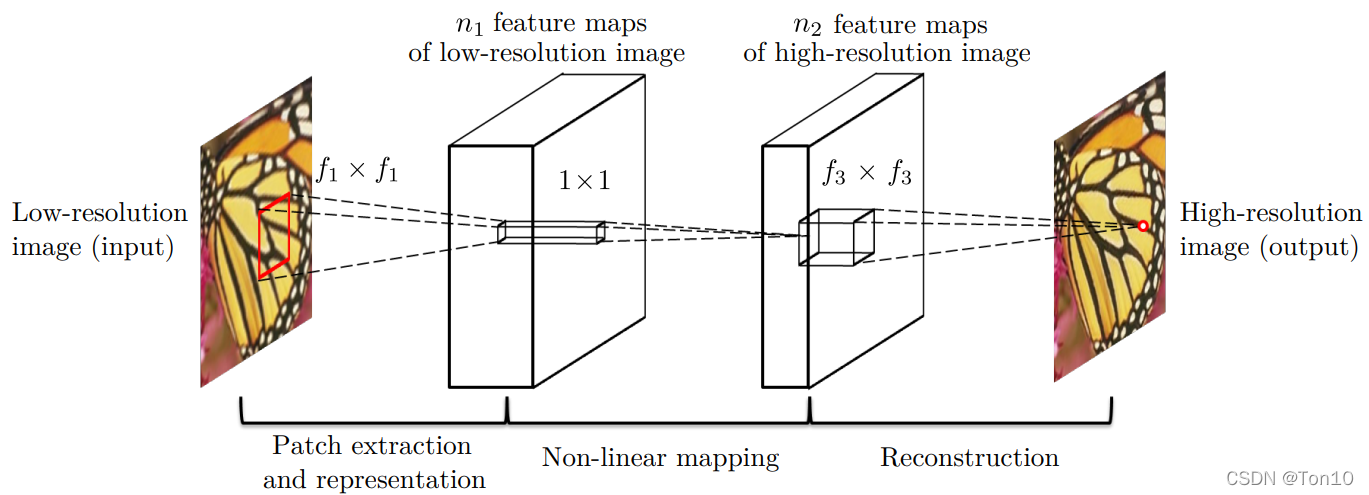
����˵�����·��ŵĺ���:
- Y Y Y:����ͼ��Ԥ����(˫���β�ֵ)�õ���ͼ��,�����Խ� Y Y Y�����ǵͷֱ���ͼ��,������sizeҪ������ͼ��Ҫ��
- F ( Y ) F(Y) F(Y):������������ͼ��,���ǵ�Ŀ�����ͨ���Ż� F ( Y ) F(Y) F(Y)��Ground-Truth֮���loss��ѧ��������� F ( ? ) F(\cdot) F(?)��
- X X X:�߷ֱ���ͼ��,��Ground-Truth,���� Y Y Y��size����ͬ�ġ�
����ͼ��ʾ��SRCNN������ģ��,���Ϊ������,�ֱ���:
��:Patch extraction and representation(��ʵ����ͼ��������ȡ��)��ͨ��CNN��ͼ��
Y
Y
Y��������ȡ�����浽������,�������������˶���feature map,��һ��ͼ������һЩ������
��:������ӳ���������һ���feature map��һ����������ӳ�䴦��,ʹ��������ȼӴ�,��������ѧ��������
��:�����ؽ������ؽ����ڽ�feature map���л�ԭ�ɸ߷ֱ���ͼ��
F
(
Y
)
F(Y)
F(Y),����
X
X
X��loss��ͨ��������ѧϰ����ģ�͵IJ�����
����ֱ���ϸչ���������������㡣
������ȡ��:
������ȡ������һ���CNN�Լ�ReLUȥ��ͼ��
Y
Y
Y���һ�Ѷ�����,��feature map:
F
1
(
Y
)
=
m
a
x
(
0
,
W
1
?
Y
+
B
1
)
.
F_1(Y) = max(0, W_1\cdot Y+B_1).
F1?(Y)=max(0,W1??Y+B1?).����
W
1
��
B
1
W_1��B_1
W1?��B1?���˲���(������)�IJ���,����һ��
f
1
��
f
1
f_1\times f_1
f1?��f1?��С�Ĵ���,ͨ����Ϊ
Y
Y
Y��ͨ��
c
c
c,һ����
n
1
n_1
n1?���˲�����
Note:
- ������һ��,ͼ�� Y Y Y�Ĵ�С�Լ�ͨ�������ᷢ���ı䡣
- m a x ( 0 , x ) max(0,x) max(0,x)��ʾReLU�㡣
������ӳ���:
��һ����ǽ���һ���feature map���þ����˹���һ���Լ�ReLU����м���,Ҳ��������ΪΪ�˼�������Ӷ����õ�ѧϰ����
F
(
?
)
F(\cdot)
F(?):
F
2
(
Y
)
=
m
a
x
(
0
,
W
2
?
F
1
(
X
)
+
B
2
)
.
F_2(Y) = max(0, W_2\cdot F_1(X)+B_2).
F2?(Y)=max(0,W2??F1?(X)+B2?).���½ṹ��������ȡ��һ��,��һ��������һ��ֻ��Ϊ����������ģ�͵ķ����Գ̶�,����ֻ�����
1
��
1
1\times 1
1��1�ľ����˾Ϳ�����,��ͨ����Ϊ
n
1
n_1
n1?,һ����
n
2
n_2
n2?���˲�������Ȼ���Լ������ӷ����Բ�,���DZ���ּ���Ƴ�һ��ͨ����SR���,���Ի�ѡ����������ģ����
ͼ���ؽ���:
����ڴ�ͳ���ֵĴ���ֵ�취������ͼ��ֲ�����ƽ������˼��,�䱾�ʾ��dz˼ӽ�ϵķ�ʽ,������߾������þ����ķ�ʽ(Ҳ�dz˼ӽ�ϵķ�ʽ)ȥ���ؽ�:
F
(
Y
)
=
W
3
?
F
2
(
Y
)
+
B
3
.
F(Y) = W_3\cdot F_2(Y) + B_3.
F(Y)=W3??F2?(Y)+B3?.��һ���Dz���ҪReLU���,�Ҿ����˵Ĵ�СΪ
n
2
��
c
��
f
3
��
f
3
n_2\times c \times f_3 \times f_3
n2?��c��f3?��f3?.
Note:
- Ҳ���Դ���һ���Ƕ�������,����ǰ��ľ���֮��,ͼ���size��С��,�����Ҫ�ϲ����������ָ�ͼ��,�Ʊ���Ҫһ�����������������,������������Ҳ�Ǿ�����һ�֡�
3 Loss function:
��batchsizeΪ
n
n
n,SRCNN���������Ϊ
��
=
{
W
1
,
W
2
,
W
3
,
B
1
,
B
2
,
B
3
}
\Theta = \{W_1, W_2, W_3, B_1, B_2, B_3\}
��={W1?,W2?,W3?,B1?,B2?,B3?},��Loss function�ɶ���Ϊ:
L
(
��
)
=
1
n
��
i
=
1
n
�O
�O
F
(
Y
i
;
��
)
?
X
i
�O
�O
2
.
L(\Theta) = \frac{1}{n}\sum^n_{i=1}||F(Y_i;\Theta) - X_i||^2.
L(��)=n1?i=1��n?�O�OF(Yi?;��)?Xi?�O�O2.Note:
- ѡ��MSE��Ϊ��ʧ������һ����Ҫԭ����MSE�ĸ�ʽ������ͼ��ʧ������ָ��PSNR����,��˿�������ΪSRCNN��ֱ�ӳ�������PSNRȥ��,�Ӷ��ø߷ֱ��ʵ�ͼ���н�С��ʧ��ȡ�
4 ʵ��
4.1 setup
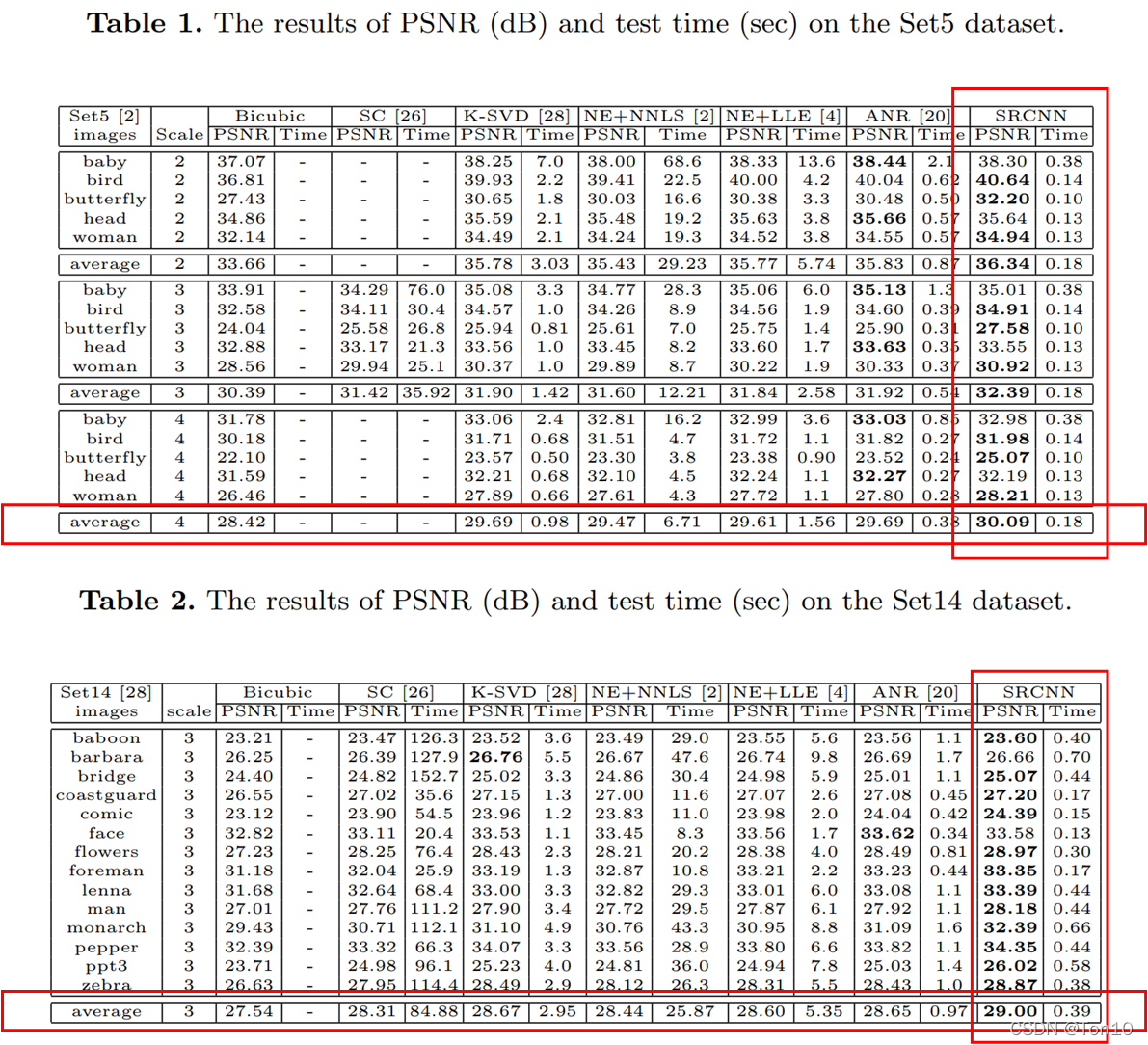
ʵ���һЩ�Ƚ���Ҫ����������:
- Training-data�漰91��ͼƬ��Set5���ݼ��漰5��ͼƬ����
up-scale-factor={2,3,4}����֤�����;Set14���ݼ��漰14��ͼƬ����up-scale-factor=3����֤����ԡ� - ʵ���һЩ��������: f 1 = 9 , f 3 = 5 , n 1 = 64 , n 2 = 32 f_1=9,f_3=5,n_1=64,n_2=32 f1?=9,f3?=5,n1?=64,n2?=32.
- Ground-Truth�Ĵ�С�� 32 �� 32 32\times 32 32��32��
- �����˵IJ�����ʼ��������: w i 0 �� N ( 0 , 0.001 ) w_i^0\sim\mathcal{N}(0, 0.001) wi0?��N(0,0.001)��
- SRCNNһ��3������,ǰ�������õ�ѧϰ��Ϊ 1 0 ? 4 10^{-4} 10?4,���һ���ѧϰ������Ϊ 1 0 ? 5 10^{-5} 10?5,����ָ�����������һ���С��ѧϰ������������������
4.2 ʵ����
4.2.1 performance
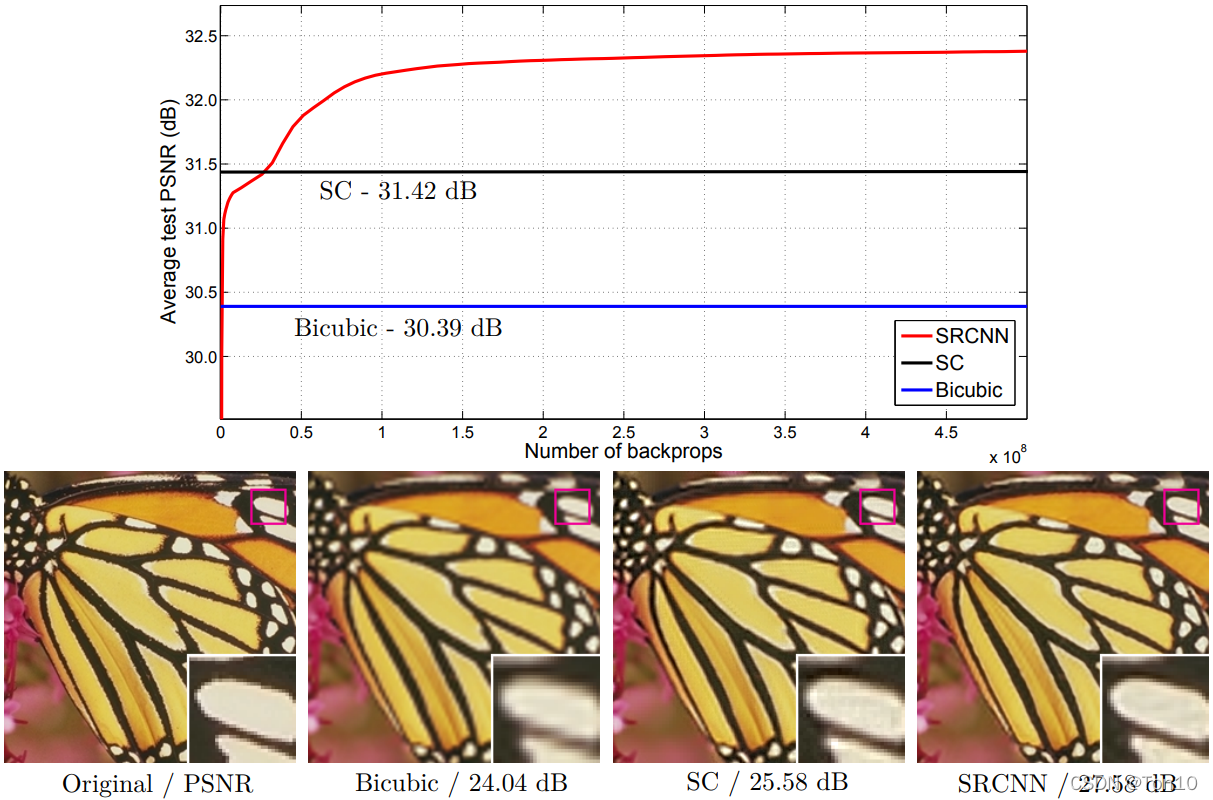
 ����ͼ����SRCNN��PSNR�ڴ�ͼƬ�ж�ȡ������ѵ�ֵ!����,�����ĵ�ʱ��Ҳ�����ٵġ�
����ͼ����SRCNN��PSNR�ڴ�ͼƬ�ж�ȡ������ѵ�ֵ!����,�����ĵ�ʱ��Ҳ�����ٵġ�
4.2.2 runtime
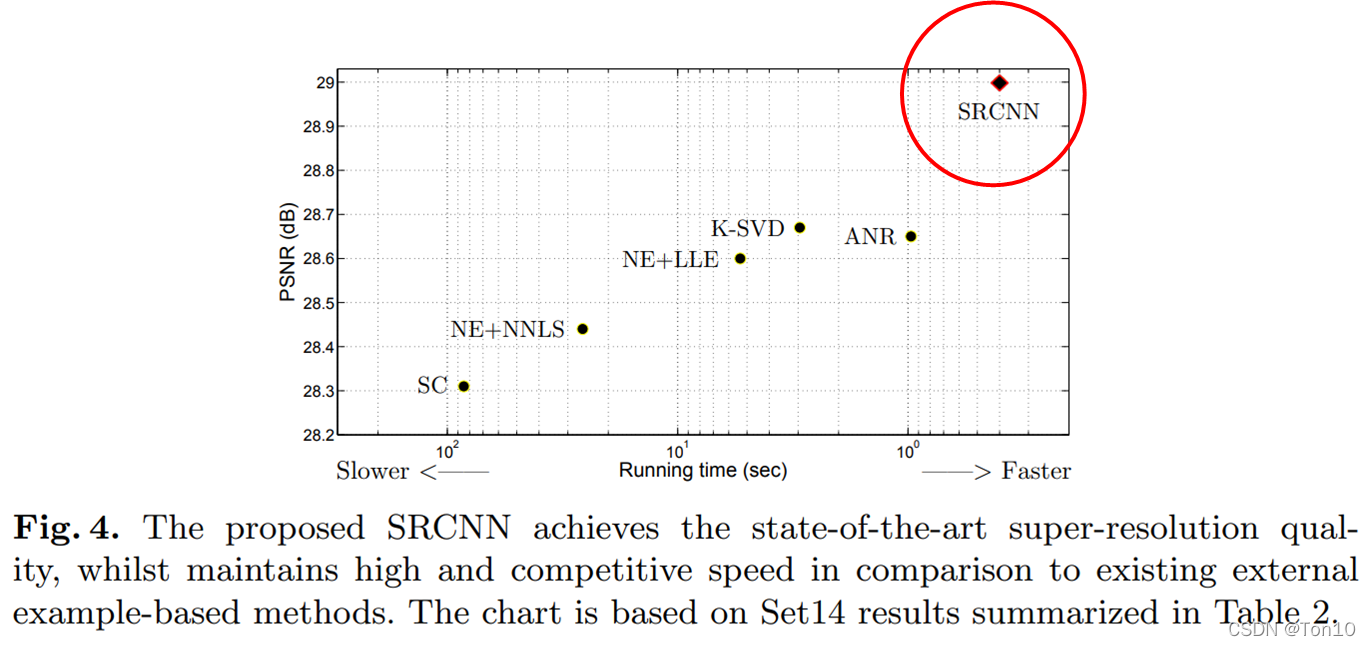 ����ͼ���Կ���SRCNN�����ٵ�runtime!
����ͼ���Կ���SRCNN�����ٵ�runtime!
5 ��һ���о�
5.1 �˲���ѧϰ���
 ��ͼ��
��ͼ��������ȡ���˲�����ѧϰ���ӻ�ͼ,��91��ͼƬ��ѵ�����,����up-scale-factor=2��
ͼ��a��f:�����ڸ�˹�ֲ���
ͼ��b��c��d:�����ڱ�Ե��⡣
ͼ��e:������������⡣
����:һЩ�����ľ����˲�����
5.2 ImageNetѧϰ
������һ��ּ��̽�����ݼ��Ĵ�С��performance��Ӱ�졣
- ����ILSVRC 2013��ImageNet���ݼ���91��ͼƬ������ѵ�������Ա�ѵ����
- ��Set5������������,up-scale-factor=3��
ʵ��������:
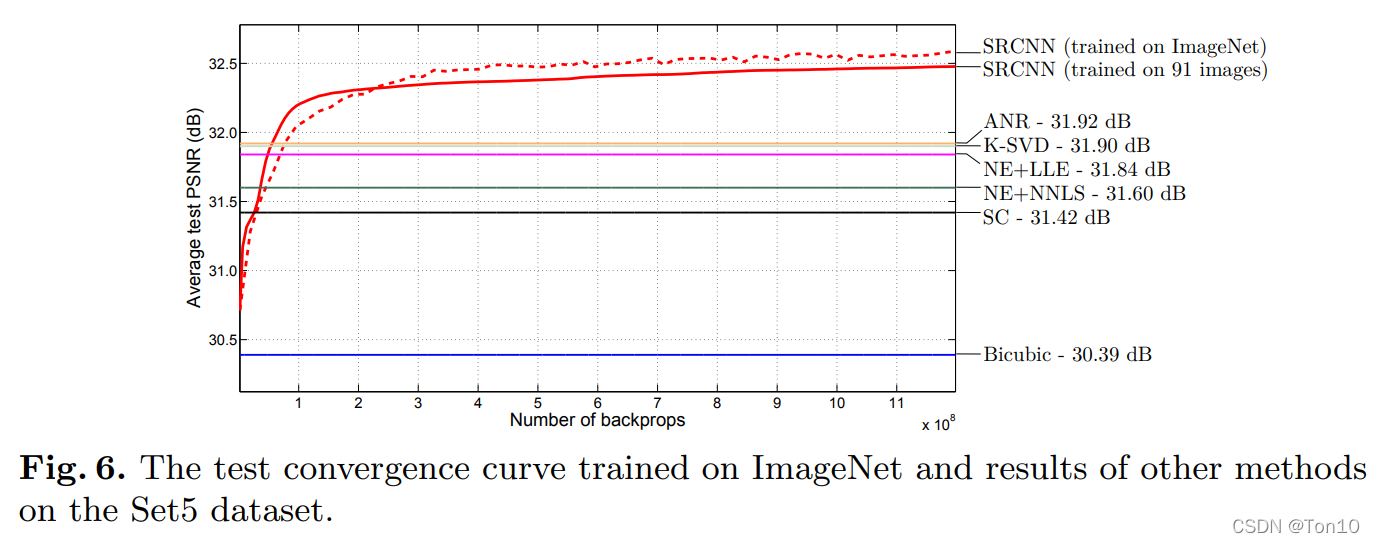 ��ͼ�п�֪,������ݼ��Ա��������������а�����(��Ȼ���Ƕ�֪��,��������������ʵ����֤����)��
��ͼ�п�֪,������ݼ��Ա��������������а�����(��Ȼ���Ƕ�֪��,��������������ʵ����֤����)��
5.3 �˲�������
�����о��˲���������PSNR������Ӱ��,������3��ʵ��,�������:

ʵ�������������˵������Ա���������������,��������������Ҳ������runtime������,��������ȡ���ٵ��ؽ�Ч��,���黹��ȡС�����ľ����˸��á�
5.4 �˲�����С
�����о��˲���size��PSNR������Ӱ��,������2��ʵ��,�ֱ���:
f
1
=
9
,
f
3
=
5
f_1=9,f_3=5
f1?=9,f3?=5��
f
1
=
11
,
f
3
=
7
f_1=11,f_3=7
f1?=11,f3?=7��
��ʵ��������,�ϴ�ľ����˿�����ȡ���õ�������Ϣ,����Ҳ������runtime������,���ʵ����������Ҫ����ʵ���������trade-off��
6 Ч��չʾ

7 �ܽ�
- ������ΪSR�����ѧϰ����Ŀ�ƪ֮��,�����һ��ͨ���Կ��SRCNN,������ͼ�����Bicubic��ֵԤ����,Ȼ��������ȡ,������ӳ��,�������ؽ�;�ؽ����ͼ����Ground-Truth��loss����ʹ����ѧϰ����δ� L R �� H R LR \to HR LR��HR��֪ʶ��
- ѡ�����ѧϰ���õ�MSE��ΪLoss function,��ΪMSE��PSNR�������Ƶı���ʽ��
- SRCNN��PSNR��runtime�϶����ֲ���,��Խ�˵�ʱ��SOAT,���������ֿ�ܵ�ʵ���ԡ�
- ��������һϵ��ʵ��,���а������ӻ���������ȡ������������ô����;������ݼ��Ա��������������а�����;�����˵����������ӶԱ���������������,��������������Ҳ������runtime������;�ϴ�ľ����˿�����ȡ���õ�������Ϣ,����Ҳ������runtime��������