Multiclass Optimal Classification Trees with SVM-splits(2021)
֧�����������ѵĶ������ŷ�����
V Blanco,A Jap��n,J Puerto
����Ŀ¼
ժҪ:
�ڱ�����,���������һ���µĻ�����ѧ�Ż��ķ������������ʵ�������η���������ǵķ�����������������,����,����Ҷ�ڵ�,��ǩ����ʱ����,��ͨ��SVM���볬ƽ�潫���Ϊ���ࡣ����Ϊ��������ṩ��һ��������������Թ滮��ʽ,��������һϵ����չ����ʵ��Ľ��,���������ǵĽ������������������������ܡ�
1.����
�������ǻ���ѧϰ������һ���ؼ�Ҫ��,�ڹ�ȥʮ���г����˴����ķ���[21]�������ܹ����Ԥ��������۲����Ϊ��,�����Խ���ʹ��ѵ�������Ļ���ѧϰ����ʱ������ģ�͡���ͬ�Ĺ����ѱ����������ɽ��͵Ļ���ѧϰ�������õ���ģ����õIJ���֮һ������ѡ��,�����ֲ�����,�ڲ�����Ԥ�������������ѡ��һ������ԡ�ͨ������Ҫ�����IJ�������,ģ�Ϳ��Ը���������,�������ߵ��������ȡ�����Ҳ���Կ��ǿ��Ա����Ƶ�ģ��,��ij��������˵,����Ԥ����̵ĺܴ�һ���ֿ��Զ����ؽ��͡����ǹ�������ģ�͵����[29]�������������ɽ�������Ϊ�������������ṹ�п��Ը��Ƶ�ͬ���[15,34]��
����������Ⱥ�С,��ʹ�û�����Ϥ�乹�챳��Ĺ���,Ҳ���Ժ����ض�����п��ӻ��ͽ��͡����IJ����˻������ķ�����
�ڻ���ѧϰ���ӽ����������ĸ�������,�������������ͬ����������Զ������˹㷺��ע[4,28,31,36,41]�������ּ�ڳ��Ԥ���¹۲�ֵ�����,ǰ����ʹ�ø��������������������ѧ�滮�ڹ�������ģ���е������ѵõ��㷺�Ͽ�,һЩ�����е��Ƶ��������ķ����ǻ��ڽ���Ż�����[13,17,16,11,27]������,����Ҫ�Ի�õ�ģ�ͽ��н���ʱ,��ѧ�滮Ҳ��֤����һ������ȷ�Ĺ���[5,6,12,25]��
Ȼ��,��������ڹ�����������Ż����߶�����ʵ��ֻ�������ࡣ�ڱ�����,�����ṩ��һ���µķ����,�����ַ�����,ʵ�����Ա�����Ϊ����������𡣸÷���ʹ����߽����Եķ����֮һ����������,����֧������������,�����ṩ�˸߶�Ԥ���ģ�͡�
���ǿ�����һ����ѧ�滮ģ��,����Ϊ������ѵ����������һ�����ŷ�����,����ÿ�������ͨ������SVM�ij�ƽ�����ɵġ��ڹ�����ʱ,�ڷ�֧�ڵ��к��Թ۲�ֵ�ı�ǩ,����ֻ�ڿ������������Ҷ�ڵ��п�����Щ��ǩ��������������Ϊ����С�����ĸ�����(ȷ���ɽ�����)����������(ȷ��Ԥ������)��
1.1��ع���
Ϊ�˹����߶�Ԥ��??�ķ������,�������Ѿ�����˼��ֻ���ѧϰ�����������е��ǻ������ѧϰ���� [1]��k-������� [18��42]�����ر�Ҷ˹ [35]�������� (CT) [15��23] ��֧�������� (SVM) [17] .����,CT �� SVM �������ǻ����Ż��ķ���,���˲����߶�Ԥ��ķ�������,�ѱ�֤���Ƿdz����Ĺ���,��Ϊ���Ƕ�������ϲ�ͬ��Ԫ��(ͨ���ʵ����Ż�ģ��ͨ��Լ����Ŀ�꺯��)����Ӧ��ͬ�����,������ѡ�� [27, 5, 6, 30],ȷ��Ҫ�� [7, 24] ������ƽ������ӵ�ʵ�� [22, 10, 14] �ȡ�
֧��������������� Cortes �� Vapnik [17] ��Ϊһ�ֶ�Ԫ����������,��ͨ����������֮����нϴ����ķ��볬ƽ�����������߹��������ƽ����ͨ�����һ�������Ż�����õ���,��Ŀ����ͨ��������ͬ��������������,�������֮��ı߾ಢ��С�������������Ż�����Ķ�ż����������չ������ͨ���ں����ҵ������Է������������������� Breiman ���˽��ܡ� al [15],���Ҿ��߹������һ��ڵ�֮��IJ�ι�ϵ,�ò�ι�ϵ���ڶ��彫�۲����Ӹ��ڵ�(��ι�ϵ�е���߽ڵ�)������ijЩҶ�ӵ�·��,�����౻��������ݡ���Щ·���Ǹ��ݶ�ѵ��������Ԥ������IJ�ͬ�Ż�����õġ����߹�����Ȼ��Ȼ�س���,Ϊ�¹۲�Ԥ������Ƿ�����۲����ڵ��ն˽ڵ���ࡣ��Ȼ,�� CT �����ķ�����������ͨ�������ڵ㴦����IJ��������.�� [15] ��,�����һ��̰��������ʽ����,����ν�� CART ���������� CT������ÿһ���ǰ�˳�����:�Ӹ��ڵ㿪ʼ,ʹ������ѵ������,�÷�����С�����ʲ�������,��Ϊ���,�������ֳ��������ཻ�ļ���,ȷ����������ڵ㡣�ظ��˹���,ֱ���ﵽ��������ֹ��(����Ҷ����С�۲��������������Ȼ�Ҷ��ͬһ�����С�۲�ٷֱȵ�)�������ַ�����,���������϶��µ�̰�ķ�������,��һ�뷨�� C4.5 [40] �� ID3 [39] ���������еľ�����������Ҳ�й�������Щ�������ŵ��Ǽ�ʹ���ڴ���ѵ������Ҳ�����൱��ػ�þ��߹���,��Ϊ�������������ڽ��ÿ���ڵ�Ŀɹ������⡣Ȼ��,��Щ���͵�����ʽ���������������ѷ�����,��Ϊ������ÿ���ڵ㱾��Ѱ����ѷָ�,�����������ķָ���,��Щ���ط�֧�������������ݵ���ȷ�ṹ,�Ӷ�����������۲��еĴ�����������,��Щ�����ṩ�Ľ���������ܻᵼ�·dz���(����)����,���¹������,��ʱ��ʧȥ�������Ŀɽ����ԡ��������ͨ��ͨ���������˷�,��Ϊ����ͨ���Ƚ����ʲ������ٵ����������ĸ����Գɱ��������ġ�
����ڽ�ģ�ͽ�����ѵ��Ż����ⷽ��ȡ�õĽ�չ,�Լ���Щģ�͵�����Ժ���Ӧ��,��ʹ����ʹ���Ż������������ල�����,��ȡ���˾�ɹ�[9,16])�����������,Bertsimas��Dunn[8]����������Ż���ͷ�±ƽ�����ع��������ŷ�����(OCT)�ĸ���,���������Ź���Ļ���������Թ滮��ʽ������,����֤���˸�ģ�Ͷ��ں�����С�����ݼ��ǿ�������,ͬ����Ҫ����,�������ͬ����ʵ���ݼ�,�����CART,��ģ�͵ľ��ȿ��Եõ���������ߡ����CART������ͬ,OCTͨ����������Ż�����(��Ŀ�꺯����)�������ĸ�������������,�����˺��������̡�����,ÿ�ηָ��ֱ��Ӧ�õ�,�Ա�����ȵؼ����ն˽ڵ��ϵĴ���������,���OCT���п��ܲ������ݵ�����ģʽ��
��Ȼ SVM ������Ϊ����������ʵ��,���������Ѿ������һЩ��չ���ڶ�����ࡣ�����еĻ��ڶ��� SVM �ķ����� One-Versus-All (OVA) �� One-Versus-One (OVO)��ǰ��,�� OVA,����ÿ���� r �� {1, . . . , k},һ����Ԫ SVM ������,����۲�ֵ���� r ��,�۲�ֵ���Ϊ 1,����Ϊ -1�����������ظ��ù���(k ��),Ȼ��ÿ���۲���ൽ�乹��ij�ƽ��������ռ���������Զ���ࡣ�� OVO ������,ÿ����ʹ��һ����ƽ�潫���� k/2 ����ƽ��ֿ�,���Ҿ��߹�������ͶƱ����,����ͶƱ�д����������ΪԤ����ࡣ
OV A �� OVO �̳��˶����� SVM �Ĵ��������ԡ��������,��ʹ�����Ժ�ʱ,��������ȷ�������ݼ�,���з���Ĺ۲��ƿ�������ͬһ��(��˱�������ͬ�ı�ǩ)����һ�����еķ�����������ͼ SVM,DAGSVM [1]�������ּ�����,���ܾ��߹����漰ʹ�� OVO ������������ͬ��ƽ��,����������Ψһ��ͶƱ���Ը�����,�����������������ͶƱ,��������ܵ��౻ɾ��,ֱ��ֻʣ��һ���ࡣ����,���� OV A �� OVO,����һЩ���ڽ�ԭʼ��������ֽ�Ϊ�������������ķ������ر���,�� [2] �� [20] ��,���ַֽ��ǻ��ڱ������Ĺ���,�þ���ȷ�������ڹ������볬ƽ�����ԡ�����,��������,�� CS ([19])��WW ([44]) �� LLW ([33]),���ǰ�˳������������,������Ϊһ�����忼��ͬһ�Ż�ģ���е������ࡣ��Ȼ,���ƺ�����ȷ���������ر���,�� WW ��,k ����ƽ�����ڷ��� k �����,ÿ����ƽ�潫һ��������������ֿ�,ÿ���۲�ʹ�� k-1 ������������
�� CS ��Ӧ������ͬ�ķ���˼��,����ÿ���۲�Ĵ�����������������ٵ�һ��Ψһֵ���� LLW ��,�����һ�ֲ�ͬ��������������Ҷ˹�������ת��Ϊ SVM ����,����ζ������õķ������е�����ͳ�����ԡ��� WW �� CS ����ȷ����Щ����
���ǻ������ҵ����� [26] ����� LLW �Ķ�����չ���� [43] ��,���������һ�ֻ��ڶ��� SVM �ķ��� GenSVM,����ʹ�õ����α����� (k-1) ά�ռ��л�� k ������ķ���߽硣����һЩ�����Ѿ��������,���ڻ���ѧϰ�еĴ������������ʵ��,�� e1071 [37]��scikit-learn [38] �� [32]�����,������Ĺ��� [11] ��,���������һ�ִ������������������,�÷�����չ�˶�Ԫ SVM �������ķ�ʽ,ͨ�����������ռ�Ķ�����������������������ĵ�Ԫ��,ͨ�������֮��ķ��벢��С������ֱ�۵Ĵ���������
1.2����
�ڱ�����,���������һ��ͨ����ѧ�滮ģ��Ϊ����ʵ���������������·��������ǵķ�������������Ҫ�ɷ�:
(1)�� [8] �������Ϲ�����һ�����Ŷ��������(����б��),���з��Ѻ����ڵ��Ǹ���Ҷ���Ĵ�����������ȷ���Ľڵ�;
(2) ��������֧�ķ�����ͨ�����ڶ�Ԫ֧���������ij�ƽ������鹹��(��Ҳ��ģ�;���)������,�������֮��ķ��벢��С�����ھ���Ĵ���������
���ǵľ��幱�װ���:
(1)����һ���ɽ��͵Ķ���������,������˼ල������������ǿ��Ĺ���,�� OCT �� SVM��
(2)��������ʹ�ÿ��Ա���Ϊ������������滮�������ѧ�滮ģ�����ġ��÷���������Ӧ�úͽ��͡�
(3)Ϊ��ʽ����˼�����Ч�IJ���ʽ,����������ǿģ�Ͳ��ڸ��̵� CPU ʱ���ڽ������ߴ��ʵ����
(4)�ݱ���,������ UCI ����ʵ���ݽ��еĴ�������ʵ�����,���ǵķ��������������ھ������ķ���,�� CART��OCT �� OCT-H��
1.3 ���Ľṹ
��2�ڽ�������,���ع������������ǵķ����Ĺ��ߡ��ڵ�3����,������ϸ���������ǵķ�������Ҫ�ɷ�,��ͨ��һ��ʾ����ʾ���������ܡ���4�ڸ������������ǹ�������������ѧ�滮ģ��,���а���ģ�����漰������Ԫ��:������������Ŀ�꺯����Լ�����ڵ�5����,���DZ�����ʵ��Ľ��,���������������η��������,���ǵķ��������ܡ����,��6�ڸ�����һЩ���ۺ�δ�����о�����
2. Ԥ����
����ר�Ž������о������Ⲣ��������ʹ�õķ��š����ǻ��ع�����������ķ������漰����Ҫ����,��֧�������������ŷ���������Щ������ֽ���Կ���һ���·���,��Ϊ����֧���������IJ�ֵĶ������ŷ����� (MOCTSVM)��
���ǵõ�һ��ѵ������,X = {(x1, y1), . . . , (xn, yn)} ? Rp��{1, . . . , K},������һ�� n ���۲�ֵ (x1, . . . , xn) �ϲ��� p �������Լ� {1, . . . , K} Ϊ�����е�ÿһ�� (y1, . . . . , yn)���������Ŀ���ǽ������߹���,�Ա���ݸ���ѵ������ X ����Ϊȷ�ؽ���ǩ (y) ��������� (x)��
�����ڷ�����ʹ�õĵ�һ���ɷ���֧�������������� SVM �������еĻ����Ż��ķ���֮һ,�������ֻ�漰������ķ������,ͨ����Ϊ���� (y = +1) ���� (y = -1)������֧����������Ŀ����ͨ��������ǵķ��벢ͬʱ��С���������ͱ�Υ�����������һ��������������ij�ƽ�档���� SVM ���Ա���Ϊ�����Ż�����:
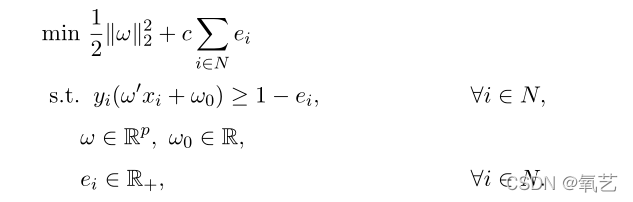
���� c ��������,��ʾѵ������ģ���Ӷ�(�߾�)֮���Ȩ��,�ء� ������ �� �� ||.|| ��ת�á��� Rp �е�ŷ����÷���(Ҳ���Կ�����������,���Ա����Ż����� [13] �����ƽṹ����)����ע��,ʹ�����ַ���,��(��)�ཫ������λ���ɳ�ƽ�� H = {z �� Rp : �ء�z +��0 = 0} �յ�����(��)��ռ��ϡ���һ����,SVM ��������Ҫ��������ν���ں˼��ɡ����������ǽ�����ͶӰ������ά�ռ�,����������ȷ�ķ�ʽִ�����Է���,����֪�������Ŀռ�,��ֻ��֪�����ڻ�����ʽ,�����ּ��㸴�Ӷ��Ż�����(����ϸ�ڲμ�[17])��
�����ڷ����н�ϵĵڶ��ַ����Ƿ������� CT ��һϵ�л���һ��ڵ�֮��IJ�ι�ϵ�ķ��������Щ������������ͨ����˳���ij�ƽ�������������ռ�ķ����� CT �Ӱ������������Ľڵ㿪ʼ,����Ϊ���ڵ�,����Ӧ���˵�һ����֡����ڽڵ���Ӧ�ò��ʱ(ͨ����ƽ�����۲�ֵ,�ᴴ�������·�֧,���������½ڵ�,��Ϊ���ӽڵ㡣�ڵ�ͨ����Ϊ����:��֧�ڵ�,����Ӧ�÷��ѵĽڵ�,��һ������Ҷ�ڵ�,�����������ն˽ڵ㡣����һ����֧�ڵ��������һ���ڵ��з��ѵij�ƽ��,���ǵķ�֧(�����)����Ϊ�ɳ�ƽ�涨���������ռ��е�ÿһ����CT ������Ŀ���ǹ����֧,�Ի�ù������Ҷ�ڵ㾡���ܴ�������,�����۲�ķ�������������������������Ҷ�������ܻ�ӭ���ࡣ
�д������� CT ������,��Ϊ�����ṩ�����ڽ��͵ķ�������� CT �������з���֮һ��Ϊ CART,�� [15] �н����˽��ܡ� CART ��һ��̰��������ʽ����,���Ӹ��ڵ㿪ʼѰ�ҵ��������еIJ��,����С�����������ʺ���,���������½ڵ㡣����Ӧ����ͬ�Ĺ���,ֱ���ﵽֹͣ��(���������ȡ��ڵ��е�����Ĺ۲������)�� CART ����Ҫ�ŵ��Ǽ���ɱ���,��Ϊ���ڿ����ڼ������ڻ�÷dz��������Ȼ��,CART �����ܱ�֤��������������,��ij��������˵,������Ǿֲ�������֧,���Dz鿴Ҷ�ڵ����������,����Ի�ø�ȷ����������,��ͼ 1(��)��,����չʾ�� CART Ϊ������Ϊ 2 �Ķ������������ CT�����ǻ��Ʒ�����,�������Ͻǻ��������ռ�ķ���(�ڱ�����Ϊ R2 )��
���Կ���,��õķ��ಢ������(��������Ҷ�ڵ㶼�ɴ������),������������¹���һ��û�з������� CT �������ѡ������������ CART ���������Ķ��ӹ��������,����ÿ���ڵ�ֻ�������ӽڵ�ĸ��÷���,������������Ҷ�ڵ�ķ���,�����ķ�֧������Ȼ��Ӱ������������״��
�� CART ����һȱ�������,�� [8] ��,���������һ��ͨ�����������ѧ�滮�������������ŷ����� (OCT) �ķ���,�ڸ�������,�������Խ��е��������,�����Խ����漰�����������б��֡����Թ���Ԥ�����(ͨ�������ռ��е�һ�㳬ƽ��)����ͼ 1(��)��,����չʾ�� OCT Ϊͬһʾ���ṩ�ľ��г�ƽ�� (OCT-H) �Ľ�����������Թ۲쵽,�ڲ�ָ��ڵ�(��ɫ��֧)ʱ,û�л�����õľֲ����(�ڵ������ͬ����е�һ��۲�ֵ),����,�����������������ʱ,���յ�Ҷ��ֻ�ж�ͬһ��,�Ӷ�Ϊѵ���������������ķ������
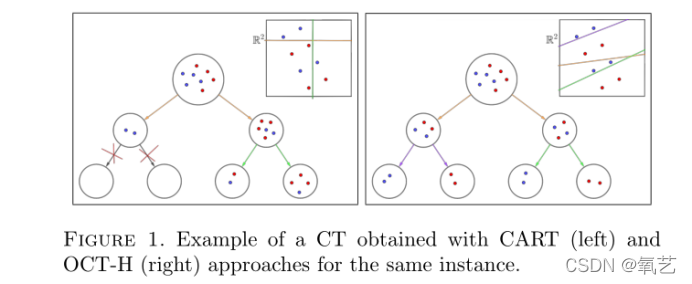
ͼ 1. ʹ�� CART(��)�� OCT-H(��)����Ϊͬһʵ����õ� CT ʾ����
�� SVM ������������,OCT �� SVM ���ַ������Խ������,�Թ���������,������ CT ��ȷ���ij�ƽ��ָ��������̶ȵط��롣����뷨��������,�����ѱ�֤�������ͬ�Ķ��������������ڱ������ž���������,����,�� [12] ������� OCTSVM ��������ͼ 2 ��,����չʾ�����ʹ�� OCTSVM �������и���������� OCT,����ѵ���������Ծ����� OCT-H ��ͬ�� 100% ȷ��,����������۲��и��ܷ�ֹ������ࡣ
Ȼ��,��������֪,OCT �� SVM �����ֻ��Զ���ʵ�������˷��������˷�����չ����������(����������)��������,��Ϊ���Թ��������ӵ�����ʹ�û��ڶ��� SVM �ķ���(�μ����� [19,44,33])��
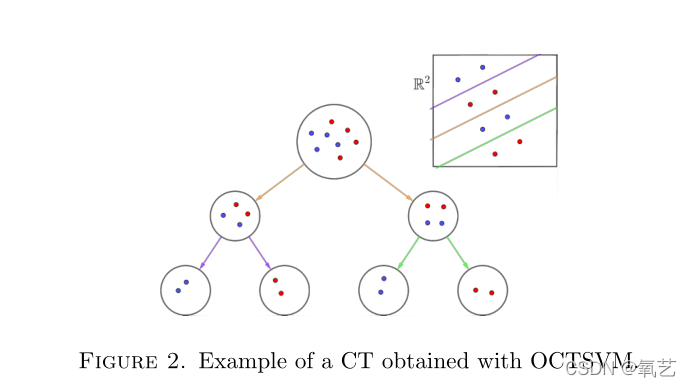
ͼ 2. ʹ�� OCTSVM ��õ� CT ʾ����
Ȼ��,���� SVM ��������Щ�ı��ѱ�֤������ʵ�����ʵ����ʧ��(�μ� [11])���ڱ��ĵ����ಿ����,����������һ�ֻ��ڲ�ͬ˼�빹����ȷ�Ķ������η��������·���:���������˫�� SVM ����������ķ��ѵ� CT,����ÿ����֧�ڵ㴦�Ĺ۲�����ģ��ȷ��,���������ѡ������Ҷ�ڵ㴦�ṩС�ķ������÷�������ϸ��Ϣ������һ���и�����
3.�� SVM ��ֵĶ��� OCT
�ڱ�����,�������������ǽ���Ϊ����ʵ�������������ķ���,�ر��ǻ��� SVM ��ʽ���ɲ�ֵķ���������ǰ����,���ǵķ�������ʹ�� SVM ��ֹ��� OCT,���۲�������ʱ������,����Ҷ�ڵ㴦���ǡ�Ϊ��˵�����Ƿ����µ��뷨,��ͼ 3 ��,����չʾ��һ�����ʵ��,���а���һ��������ֲ�ͬ���(��ɫ����ɫ����ɫ����ɫ)�ĵ㡣

ͼ 3. 4 �������ʵ��
����,�ڸ��ڵ�(�漰���й۲�Ľڵ�),���ǵķ���Ϊ�����鹹��(Ҳ����ȷ��)����һ�� SVM ���볬ƽ�档һ�ֿ��ܵķ��������ͼ 4 ����ʾ�ķ���,����ѵ�����ݼ��ѷ�Ϊ����(��ɫ�Ͱ�ɫ)�����ַ����������������ӽڵ�,����ɫ�Ͱ�ɫ�ڵ㡣��ÿ���ڵ���,Ӧ����ͬ���뷨,ֱ������Ҷ�ڵ㡣��ͼ 5 ��,���Ǹ��ݴ˹�����ʾ�������ռ�����ջ��֡�

ͼ 4. 4 ���������ĸ�����

ͼ 5. 4 ����������ϵ��ӽڵ����,�����ǵ�ģ����ȷ��Ϊ�鹹�ࡣ
��Ȼ,�����������к���ѵ��������ԭʼ��������������,������Ҷ�ڵ㴦���ǵ�ѵ�������з��������ŵ㡣���,�����յ�Ҷ�ڵ㴦,ԭʼ��ǩ���ָ�,���������ɵij�ƽ����з��ࡣ����������ս����ͼ 6 ��ʾ,���п��Լ�鹹�������Ƿ�ʵ���˶�ѵ���������������ࡣ
һ��ʹ�����ֲ��Թ�����,���߹���ͻ���Ȼ��Ȼ�س���,�����ھ�����������ͨ������������,��������Ĺ۲�ֵ�����ݲ����ѭ���ϵ�·��,�������Ƿ�����������ڵ�Ҷ�ӵ���(ѵ��������ߴ����Ե�Ҷ����)������ڹ�����ʱ����һ����֧,��۲콫������������Ľڵ����ߴ����Ե��ࡣ

ͼ 6. ����ԭʼ��ǩ(��ɫ)�� 4 �����������ӽڵ���ѡ�
4.MOCTSVM ����ѧ�滮��ʽ
�ڱ�����,����Ϊ��һ���������� MOCTSVM �����Ƶ���������������Թ滮��ʽ�����Ǽ������һ��ѵ������ X = {(x1, y1), . . . , (xn, yn)} ? Rp �� {1, . . . , ?}�������� N = {1, . . . , n} ѵ�������й۲�ֵ�������������ǻ�����ǩ y �Ķ����Ʊ�ʾ��Ϊ:
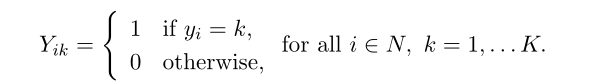
����,�ڲ�ʧһ���Ե������,���ǽ�����Ҫ��һ��������,�� x1, �� . . , xn �� [0, 1]p��
���ǽ��������й̶������� D �ľ����������,����������� T = 2D+1 - 1 ���ڵ���ɡ������� �� = {1, . . . , T } Ϊ���ڵ����õ�����,���нڵ� 1 �Ǹ��ڵ�,�ڵ� 2D,. . . , 2D+1 - 1 ��Ҷ�ڵ㡣
�����κνڵ� t �� ��{1},������ p(t) ��ʾ����(Ψһ��)���ڵ㡣���ڵ���Է�Ϊ����:��֧�ڵ��Ҷ�ڵ㡣������ Tb ��ʾ�ķ�֧�ڵ㽫��Ӧ�ò�ֵĽڵ㡣�෴,���� T1 ��ʾ��Ҷ�ڵ���,û��Ӧ�÷���,���Ƿ���Ԥ��ĵط�����֧�ڵ�Ҳ���Է�Ϊ����:Tbl �� Tbr,��ȡ�������Ƿֱ���丸�ڵ���·���ϵ����֧�����ҷ�֧�� ��bl �ڵ���ż������,ͬʱ ��br �ڵ�������������
���ǽ�������Ϊ�����о�����ͬ��ȵ�һ��ڵ㡣���ڸ��ڵ㱻�ٶ�Ϊ�㼶,���Ҫ���������еļ�����Ϊ D + 1���� U = {u0, . . . , uD} �����IJ㼯,����ÿ�� us �� U �Dz� s �Ľڵ㼯,���� s = 0, . . . , D. ʹ�����ֱ�ʾ��,���ڵ��� u0 �� uD ��ʾҶ�ڵ�ļ��ϡ�
ͼ����,������3���������ʾ������Ԫ�ء�
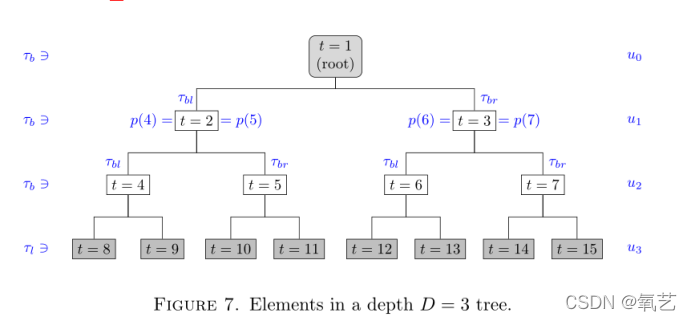
ͼ 7. ��� D = 3 ���е�Ԫ��
���˹����������˽ṹ����Ϣ��,���ǻ�������������������֤������У��������,����ʹ�����ܹ���ģ���н�ϵIJ�ͬĿ��֮���ҵ�Ȩ��:��Υ��ͷ�����ѳ�ƽ��ķ�����Ҷ�ڵ����ȷ��������ĸ��Ӷȡ���Щ��������:
c1:Ҷ�ڵ�ĵ�λ�������ɱ���
c2:���ڵ�λ����� SVM ��ִ���������
c3:���������ÿ�����ѳ�ƽ��ĵ�λ�ɱ���
�� 1 �ܽ�������ģ����ʹ�õ��������Ͳ����������б���
4.1����
���ǵ�ģ��ʹ�ñ� 2 ��������һ����ߺ�������������ʹ�ö�Ԫ���������߱�����ģ�� MOCTSVM����Ԫ�����������Ǿ������۲���������������ڵ�,���߾���һ���ڵ��Ƿ������б��ָ����������������ȷ�����ѳ�ƽ���ϵ�������������(�� SVM �����л���Ҷ�ڵ㴦)�����ǻ�ʹ�������ڳ�ֽ�ģ����ĸ��������ƺ�����������
��ͼ 8 ��,����˵������Щ�����ھ����������(��ɫ����ɫ����ɫ)�����ʵ���Ŀ��н�������е�ʹ�á�


�ڸ��ڵ�(�ڵ� t = 1)����������ѵ���۲졣������,ԭʼ��ǩ������,����Ϊ��ȷ��ÿ���۲���鹹��,������һ������ SVM �ij�ƽ�档
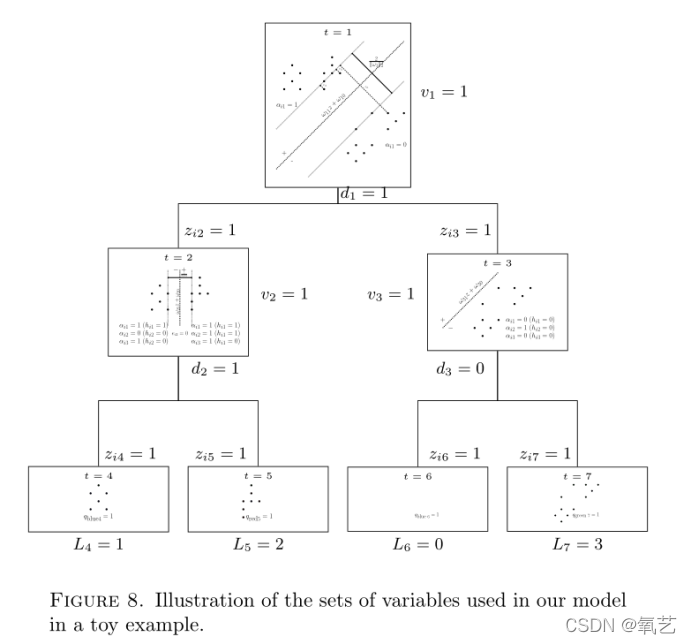
�����ij�ƽ����ϵ�� ��1 �� Rp �� ��10 �� R ����(��ƽ��/ͼ���������Ƶ���),���ᵼ�±�Ե����(2/||w1||2)�ʹ��������� ei1����ͼ�л��ƵĿ��н���,ֻ�������۲�ֵ�ᵼ�������(��Щ�������ڱ�Ե�����ƽ���������)�������ij�ƽ��Ҳ�����˸ýڵ���ӽڵ㶨��ķ��ѹ������ڽڵ��Ƿ��ѵ�(d1 = 1),���ڳ�ƽ������Ĺ۲챻�������ڵ�(�ڵ� t = 2),������Ĺ۲챻������ҽڵ�(�ڵ� t = 3) ͨ�� z ������
�ڽڵ� t = 2,Ӧ����ͬ�ķ���,�������� ��2 ����ij�ƽ��,������� SVM �����������,�������� d2 = 1,�ָ����Ҳ�����ڶ���ڵ� t = 4 �� t = 5. �ڽڵ� t = 2 ��,������Ƹýڵ��еĹ۲�,�����������Ŀ�꺯���е���Щ�۲���������� ei2��������˵,����ֻ�������ڽڵ� (zi2 = 1) �������ڳ�ƽ������� (��i2 = 1) �� (��i2 = 0) �Ĺ۲�ֵ����Щ������,Ϊ�˿������ĸ�����,ʹ�� h �������˽�۲��Ƿ����ڽڵ�� SVM ��ƽ������ࡣ
���һ���ڵ��е����й۲�ֵ�����ڳ�ƽ�������,����� v ȡֵΪ 0������,��� v ȡֵΪ 1,����ܳ����������:1)�ڳ�ƽ�������й۲�ֵ(���ڽڵ� t = 2) ���յ��µķ��� (d2 = 1),�Լ� 2) ���й۲춼���ڸ���(���ڽڵ� t = 3 ��),ȷ�����ڸýڵ㴦����(d3 = 0)��
����Ҷ�ӽڵ�,�ڵ� t = 2 ������Ϊ�ڵ� t = 4 �� t = 5,���Ҿ������ٷ��ѵĽڵ� t = 3 ���������Ϊ����Ҷ�ӽڵ�,��������һ���ǿյIJ�����һ�����ո��ڵ�(�ڵ� t = 3)�����й۲��������κ�Ҷ�ڵ� ��l �����һ������ͨ�� q ������ɵ�(������ڵ��������е���,�����ڽڵ�û�й۲�ֵ��������������),���Ҵ������Ĺ۲�ֵ�������� L ��������.
4.2 Ŀ�꺯��
��ǰ����,���ǵķ���ּ�ڹ�����Ҷ�ڵ㴦����С����������ķ�����,��ͬʱ���л��� SVM �ij�ƽ��ͻ��ھ������С������֮��������롣ʹ����һ���������ı���,Ŀ�꺯���а������ĸ�������:

���ѳ�ƽ��ı߾�:: ��֧�ڵ� t �� Tb �ķ��볬ƽ��ı߾�Ϊ 2/||wt||2�����,���ǵķ���ּ�������Щ�߾����Сֵ�����൱����С���ɸ������� �� ��ʾ����� { 1 2k��tk22 : t �� ��b} �е����ֵ��Ҷ�ڵ㴦����������::���� Lt ˵��Ҷ�ڵ� t �������۲������,�������ڸ�Ҷ�ڵ��д���������Ĺ۲���������Щ����ʹ�����ܹ�����ѵ�������д������۲�����������,ģ��Ҫ��С���������������ܺ���:
��֧�ڵ㴦���ھ���Ĵ���:ÿ���������Ӳ��ʱ,����ϲ�һ������ SVM �ij�ƽ��,���л���ȫ�ֱ�����Ϊ�����������ǩ�����,������ Tb �е�ÿ����֧�ڵ㴦���� SVM �������ڸ÷ָ�����Ļ��ھ�������������� eit ��������,��ͨ���ܺͺϲ���ģ����:

���ĸ�����:���ɵ����ļ�����ͨ�����乹������ɵIJ�������������ġ����� dt �����������ǽڵ� t �Ƿ��,��˸����������ǵ�ģ���б�����Ϊ:
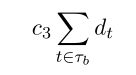
�ܶ���֮,����ģ�͵�����Ŀ�꺯����:
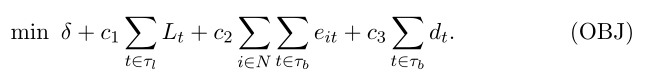
��ע��,ϵ�� c1��c2 �� c3 �ֱ�Ȩ����ѵ�������Ĵ�����ࡢ��֮��ķ�������ĸ����ԡ�Ӧ����ϸУ��Щ����,�Ա㹹�����и�Ԥ�������ļ�����,�����ǵļ���ʵ����ʾ��
4.3 Լ��
ͨ��������ѧ�滮ģ�͵�����Լ���������Ա���֮���ϵ��Ҫ�������ģ�͵Ļ���ԭ��������,Ϊ�˳�ֱ�ʾ���ѳ�ƽ�����߾��е����ֵ,������Ҫ:

������,����ǿ�����������ִ�в�֡�Ϊ��,������Ҫ֪����Щ�۲�ֵ����ij���ڵ� t(z ����),�Լ���Щ�۲�ֵ����������Ҫ����������鹹��(�� ����)�ֲ��ġ���������ЩԪ�ؾۼ���һ��,����ʹ������Լ��������������IJ��:
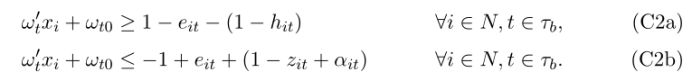
�ݴ�,ֻ���ڹ۲� i ���ڲο��ಢ����λ�ڽڵ� t ��(hit = 1)�������,�Żἤ��Լ��(C2a)����һ����,��� i ��������ڵ� t (zit = 1) ���������ڲο��� (��it = 0),�� (C2b) ��������,�ο���λ�ڳ�ƽ�� Ht ������ռ�,����һ����λ�ڸ���ռ�,ͬʱ,��ԵΥ���� eit �������ڡ�
Ϊ��ȷ������Լ������ȷ��Ϊ,���DZ�����ȷ���� zit ����������,Ҫ��ÿ���۲�ֵǡ����������ÿһ���һ���ڵ㡣�����ͨ��������ÿ������ u �� U ������������ͨ���ķ���Լ�����������:
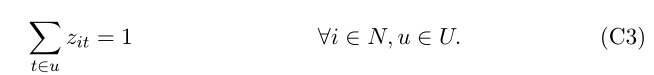
����,����Ӧ��ǿ������۲� i �ڽڵ� t (zit = 1) ��,��ô�۲� i Ҳ������ t �ĸ��ڵ���,p(t) (zip(t) = 1),���ҹ۲� i Ҳ��������������丸�ڵ���,���ڽڵ� t �� (zip(t) = 0 ? zit = 0)����Щ�������ͨ������Լ�����:
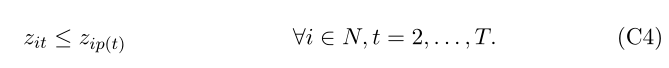
Ȼ��,�۲�ͨ�����½��ķ�ʽ��Ҫ��һ������,��Ϊ��ʱ���ǿ�������������е�·����ÿ���۲� i �ڽڵ� t, Ht ���ķ��ѳ�ƽ�������ռ���ʱ,�ù۲�Ӧ����ѭ���ӵ� t ���ӽڵ���ҷ�֧������,��� i �ڸ���ռ���,��Ӧ�ø������֧���۲������ķ��ѳ�ƽ��һ���֪ʶ�������ڦ������С�Ȼ��,��� i λ�� Ht ������ռ�,�� ��it ��Զ������� 0,��Ϊ���ᵼ�� eit ��ֵ���� 1,���� ��it = 1 ������±�֤ eit < 1��
ͨ�������۲�,ȷ�����ѳ�ƽ������ڹ۲�������һ����ȷ�����Լ������:


Լ�� (C5a) ȷ������۲� i λ��ż���ڵ� t (zip(t) = 1) �ĸ��ڵ���,���� i λ�� Hp(t) �ĸ���ռ��� (��ip(t) = 0),Ȼ�� zit ��ǿ�Ƶ���һ�����,��ip(t) = 0 ��ʹ�۲� i ��ȡ�ڵ� t �е����֧��ע��,��� zip(t) = 1,ͬʱ�۲� i ���� t �����ӽڵ���(zit = 0 for i �� ��bl),�� ��ip(t) = 1,����ζ�Ź۲� iλ�� Hp(t) ������ռ䡣Լ�� (C5b) ������ (C5a) ��������ֱ�ʾ�ҷ�֧�ڵ㡣

����,��Ҫ��������������ҪԪ����������ǵ�ģ��:���ĸ����Ժʹ������۲����ȷ���塣��ע��,��ͨ����ʹ�û��� SVM �IJ�ֵ���ѷ�������,ֻ�������з�֧�ڵ���ǿ�� k��tk22 �� M dt (�����㹻��� M ����),�Ϳ������ɵ��ڸ�����,��Ϊ���һ���ڵ㲻�ǽ�һ����֧(dt = 0),���ѳ�ƽ���ϵ������Ϊ�㡣Ȼ��,�����ǵ�������,���ѳ�ƽ���ǻ��� SVM �ij�ƽ��,��ЩԼ����Լ�� (C2a) �� (C2b) ��ͻ,��Ϊ�� dt = 0(��� ��t = 0)�������,��������ζ��ϵ�� ��t ���� 0,���һ��ھ����������Ϊ���ֵ 1,�����ڽڵ��е�ÿ���۲�ֵ i,eit = 1,��ʹ��Щ���û���κ�����,��Ϊ�۲�ֵ�����ڽڵ㴦���롣Ϊ�˿˷��������,���ǿ��Ǹ�����Ԫ���� hit = zit��it(����۲� i ���ڽڵ� t ����λ��Ӧ���ڽڵ� t �ķ��ѳ�ƽ�������ռ���,������ȡֵΪ 1)�� vt(ȡֵΪ������ڵ��е����е㶼��������ռ�,����һ��)�����������Լ���ϲ���ģ����,����Գ�ֶ������: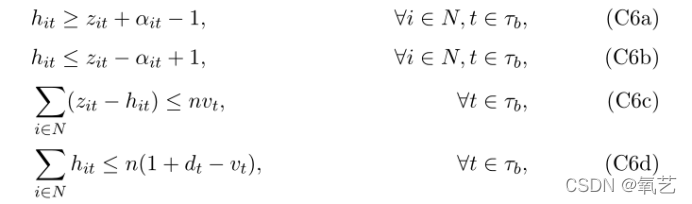
����Լ�� (C6a) �� (C6b) ��˫����Լ�� hit = zit��it �����Ի�����һ����,Լ�� (C6c) ȷ���� vt = 0 �������,�ڵ� t �е����й۲�ֵ������ Ht ������ռ�,����Լ�� (C6d) ȷ����� vt = 1 �������ڽڵ� t ������(dt = 0),��ô������ڵ� t ����Щ�۲�ֵ���������ɷ��ѳ�ƽ�涨��ĸ���ռ��С����,����ζ�ŵ��ҽ����ڵ� t �еĹ۲챻 Ht �ָ�ʱ,dt ȡֵ 1,����ڽڵ㴦������Ч�ָ
���,Ϊ�˳�ֱ�ʾ Lt ����(����Ҷ�ڵ��ϴ������۲�����ı���),����ʹ�� [8] �е� OCT-H ģ�����Ѿ�������Լ����һ����,���ǽ�ÿ��Ҷ�ڵ�����һ����(���ڸýڵ�������еĹ۲���)������ʹ�ö����Ʊ��� qkt �����Ҷ�ڵ� t �� ��l �Ƿ������� k = 1, �� . . , K. ͨ���ķ���Լ������Ϊ��Ϊ��ȷ��ÿ���ڵ㶼�������һ����:
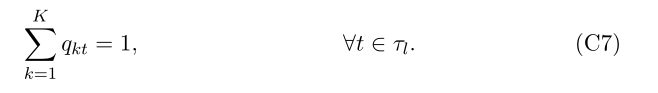
Ȼ��ͨ������һ��Լ������֤���� Lt ����ȷ����:
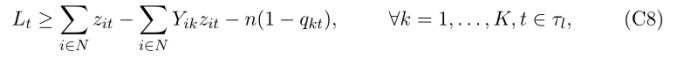
���ҽ��� qkt = 1 ʱ,��ЩԼ���ű�����,��,����ڵ� t �еĹ۲�ֵ��������� k�������������,���� Lt ��Ŀ�꺯���б���С��,Lt ���ɽڵ� t �г���ǩΪ k ��ѵ���۲�ֵ���ѵ���۲���ȷ��,���ڵ� t �еĴ������۲������� k-������ҵ��
�۲쵽 (C8) �еij��� n ���Լ�С���̶�Ϊѵ�������д������۲�ֵ��������������������ѵ�������еĹ۲��� (n) ����������ߴ����Ե�����еĹ۲���֮��һ�¡�
�ܽ����϶���,MOCTSVM ���Ա���Ϊ���� MINLP ����: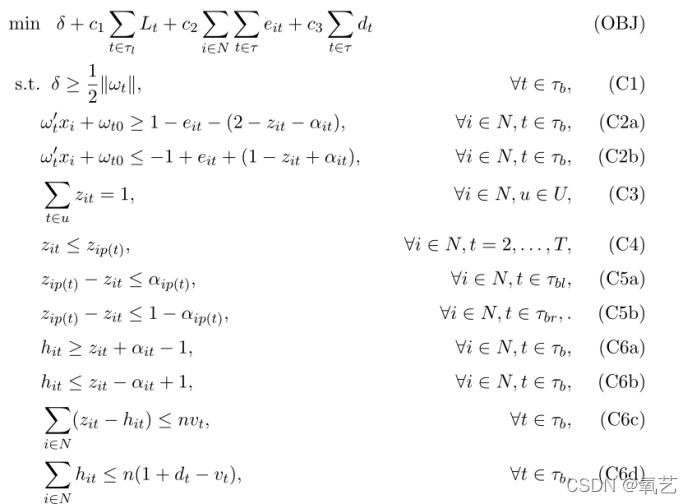
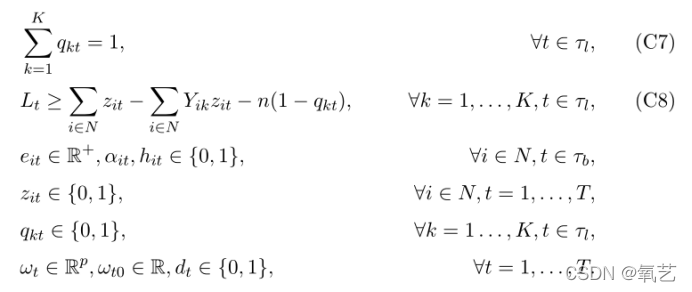
4.4 ǿ��ʾ��
������ܵ� MINLP ��ʽ�����ǵ� MOCTSVM ģ����Ч��Ȼ��,����һ������ɱ��ܸߵ�����,��Ȼ������ͨ��������ֳɵ��Ż������(�� Gurobi��CPLEX �� XPRESS)�����,����ֻ������ѷ�ʽ�����С��ʵ����Ϊ�����������,����ͨ����Ч����ʽ����ǿ����,���������Ǽ�������������ɳ��������������֮��IJ��,Ȼ���ܹ��ڸ��̵� CPU ʱ���ڽ�������ʵ������������,���ǽ��������������� MINLP ��ʽ������һЩ����ʽ:
����۲� i �� i�� ���ڲ�ͬ�Ľڵ�,�����Dz��ܷ�����������༶���ͬһ�ڵ�:
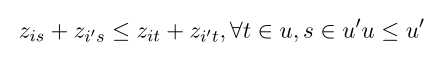
���Ҷ�ڵ� t �� s ���ʵ����ѳ�ƽ��Ľ��,���ܽ������ڵ�����ͬһ��:
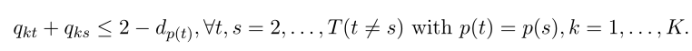
�� zit = 0 �������,���� ��it ǿ��ȡֵΪ 0:
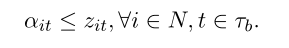
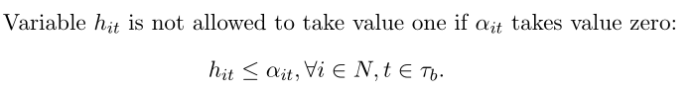
��� ��it ȡֵΪ��,����� hit ������ȡֵ 1:
ÿ���Ӧ��������һ��Ҷ�ڵ�(����ÿ�����ѵ�������б�ʾ)����Ҳ��ζ��һ���౻���䵽�Ľڵ�������н�Ϊ:
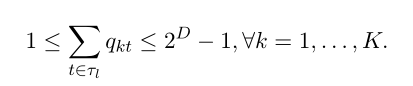

Ϊ�˽���ά�Ȳ����� MINLP ����ĶԳ���,������Ӧ��һЩ����ʽ��������Ԥ�����ι̶�һЩ�����Ʊ�����ֵ������,����ѡ�� i0 �� arg maxi��N | {i0 �� N : kai ? ai0k �� �� and yi = yi0} | ,����ͬһ���о������۲����Ĺ۲�ֵ�����㹻�ӽ���Ȼ��,���ǽ� i �� {i0 �� N : kai?ai0k �� �� �� yi = yi0} �����б��� zit0 �̶�Ϊһ��,�� t0 ��Ϊ���ĵ�һ����Ҷ�ڵ�(������Щ��ķ���̶�Ϊ��)�����Ҷ�ڵ�)�����Ƶ�,����Ҳ������ z �����̶�Ϊһ��,���۲������������һ����Ҷ�ڵ�,����ͬһ���о��� i0 �㹻Զ�Ĺ۲��Ӽ�,���������� i �� {i0,zitf = 1 �� N : kaif ? ai0k �� �� and yif = yi0} ���� if = arg maxi��N kai0 ? aik (������Щ����������Ҷ�ڵ�Ĺ̶�Ϊ��)��
5.ʵ��
Ϊ�˷��������·���������,���������� UCI ����ѧϰ�洢�� [3] �IJ�ͬ��ʵ���ݼ�֮�������һϵ��ʵ�顣����ѡ���� 12 �����ݼ�,������� 2 �� 7 ֮�䡣��Щ�����ά���ڱ� 3 ����Ԫ�鱨��(n:�۲���,p:������,K:����)��
���ǽ� MOCTSVM ģ�����������ֻ��ڷ������ķ��������˱Ƚ�,�� CART��OC??T �� OCT-H������ģ�͵��������� D ���� 3,CART��OC??T �� OCT-H ��ÿ���ڵ����С�۲�������ѵ����ģ�� 5%
���Ƕ�ÿ��ʵ��ִ���� 5 �۽�����֤����,�����ݼ����ֳ�������ѵ�����Է���,����һ���۵����ڹ���ģ��,�������ڲ���ģ�͵�ȷ��Ԥ�⡣����,Ϊ�˱�����������ij�ʼ����,���Ƕ��������ݼ��ظ�����ν�����֤������
CART ������ʹ�� rpart ���� R �б���ġ���һ����,MOCTSVM��OCT �� OCT-H �� Python ����,��ʹ���Ż������ Gurobi 8.1.1 ��⡣����ʵ����� PC Intel Xeon E-2146G ������������,Ƶ��Ϊ 3.50GHz,�ڴ�Ϊ 64GB��ѵ���۵���ѵ��ʱ������Ϊ 300 �롣���ܲ����������ⶼ��ʱ���ڵõ���ѽ��,����� 3 ��ʾ,ʹ�����ǵ�ģ�ͻ�õĽ���Ѿ���������������
Ϊ��У�����������ԵIJ�ͬģ�͵IJ���,����ʹ���˲�ͬ�ķ�����

һ����,���� CART �� OCT,����������ȵ����ڵ����� 2D - 1 = 7,��˿���ͨ��������������������������Ѹ��Ӷȵ��� ?1,���� . . , 2D - 1?���ܵĻ�ڵ㡣���� OCT-H,���������� ?10i ��������������������:i = -5, . . . , 5?�����,�� MOCTSVM ��,����ʹ������ͬ������ ?10i:i = -5, �� . . , 5?���� c1 �� c2,�Լ�?10i:i = -2,. . . , 2?���� c3��
�ڱ� 3 ��,���DZ�����������ģ�͵�ʵ���л�õĽ�������ĵ�һ�б�ʾ���ݼ��ı�ʶ(��ͬ����ά��)�����,�������Dz��Թ���ÿ�ַ���,���Ƕ��ᱨ���õ�ƽ������ȷ�Ⱥͱ�ƫ������Դ���ͻ����ʾΪÿ�����ݼ���õ����ƽ�����Ծ��ȡ�
���Կ���,�ڴ���������,���ǵķ�����ȷ�Է�����������������������Ȼ,���ǵ�ģ��ּ�ڹ������и�����������ŷ�����,�Ӷ���߲���������ȷ�ԡ����ݼ� Australian �� BalanceScale ʹ�� OCT-H ����˸��õĽ��,���ǿ��Թ۲쵽,�����������IJ����С(�����ڲ�����������ȷ����Ľ��,ֻ�DZ������)�������������,���ǵķ�����õ�ȷ�ȼ����� OCT-H һ���á����������ݼ���,���ǵķ���ʼ�ջ�ø��õķ�����,�������Ƥ����ѧ,��������ѷ������IJ����� [4%, 19%] ��Χ��,��������ɭ,����ģ�͵�ȷ������Ϊ 6������ģ�ͺ� %,���� Wine,���ǵ�ȷ�ȱ� OCTH �� 5%,�� CART �� 10%,���� Zoo,����ģ�͵�ȷ�ȱ� CART �� 17% ���ϡ�
�������Ƿ����Ŀɱ���,�� 3 �б���ı�ƫ�����,ƽ������,���ǵĽ��������������ȶ�,ƽ������ƫ���С��������Ϊ��ͬ���� CART �� OCT �й۲쵽����Ϊ,�����ø����ƫ��,����ζ��ȷ�ȸ߶�ȡ����Ӧ�ø÷����IJ����ļ��С�
6. ���ۺͽ�һ���о�
�����ڱ����������һ��ͨ����ѧ�滮ģ��Ϊ����ʵ���������������·�����������ķ�������������ǻ���֧���������ij�ƽ��ķ��ѡ�������ÿ����֧�ڵ�,����һ����Ԫ SVM ��ƽ��,���й۲챻����Ϊ�����鹹����(�����з��ѽڵ��к���ԭʼ��),����������ȫ���Ŷ���Ҷ�ڵ㴦,������������С��������,��ģ�ͽ����ĸ������� SVM �����г��ֵ�����Ԫ��һ����С��:��Ե����ͻ��ھ���Ĵ������������ǽ����˴����ļ���ʵ��,�������ǵķ�����ȷ�Ժ��ȶ��Է��涼���ڴ�������ھ������ķ�����
�����ڱ����������һ��ͨ����ѧ�滮ģ��Ϊ����ʵ���������������·�����������ķ�������������ǻ���֧���������ij�ƽ��ķ��ѡ�������ÿ����֧�ڵ�,����һ����Ԫ SVM ��ƽ��,���й۲챻����Ϊ�����鹹����(�����з��ѽڵ��к���ԭʼ��),����������ȫ���Ŷ���Ҷ�ڵ㴦,������������С��������,��ģ�ͽ����ĸ������� SVM �����г��ֵ�����Ԫ��һ����С��:��Ե����ͻ��ھ���Ĵ������������ǽ����˴����ļ���ʵ��,�������ǵķ�����ȷ�Ժ��ȶ��Է��涼���ڴ�������ھ������ķ�����
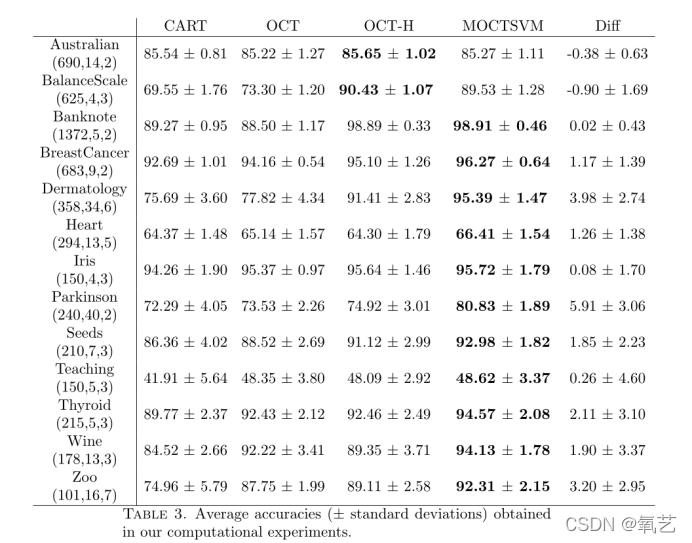
��3�����ǵļ���ʵ���л�õ�ƽ��ȷ��(����ƫ��)��
������������δ���о���������� MOCTSVM �з�֧ʱ�ķ����Է��ѷ���,���߶�ʹ�ô� SVM ���������ض������Է�����ϵ���������ں˹��ߡ����ַ��������������ķ�����,�ܹ���������ʵ�������ݼ��ķ��������ơ�����,���ǻ��ƻ������ǵķ����м�������ѡ��,�Թ������и߶�Ԥ���Ե�Ҳ���߿ɽ����Եķ���ߡ�
��л
�����
[1] Agarwal, N., Balasubramanian, V. N., and Jawahar, C. Improving multiclass classification by deep networks using dagsvm and triplet loss. Pattern Recognition Letters 112(2018), 184�C190.
ͨ��ʹ�� dagsvm ����Ԫ����ʧ���������Ľ��������
[2] Allwein, E. L., Schapire, R. E., and Singer, Y. Reducing multiclass to binary: A unifying approach for margin classifiers. Journal of machine learning research 1, Dec (2000), 113�C141.
��Ե��������ͳһ����
[3] Asuncion, A., and Newman, D. Uci machine learning repository, 2007.
����ѧϰ�洢��
[4] Bahlmann, C., Haasdonk, B., and Burkhardt, H. Online handwriting recognition with support vector machines-a kernel approach. In Proceedings Eighth International Workshop on Frontiers in Handwriting Recognition (2002), IEEE, pp. 49�C54.
֧����������������дʶ�𡪡�һ���ں˷���
[5] Baldomero-Naranjo, M., Mart��?nez-Merino, L. I., and Rodr��?guez-Ch��?a, A. M. Tightening big ms in integer programming formulations for support vector machines with ramp loss. European Journal of Operational Research 286, 1 (2020), 84�C100.
�ھ���б����ʧ��֧���������������滮��ʽ�н�����ms
[6] Baldomero-Naranjo, M., Mart��?nez-Merino, L. I., and Rodr��?guez-Ch��?a, A. M. A robust svm-based approach with feature selection and outliers detection for classification problems. Expert Systems with Applications 178 (2021), 115017.
����svm�ķ�����������ѡ����쳣ֵ��ⷽ��
[7] Ben��?tez-Pe?na, S., Blanquero, R., Carrizosa, E., and Ram��?rez-Cobo, P. Costsensitive feature selection for support vector machines. Computers & Operations Research 106 (2019), 169�C178.
֧��������������������ѡ��
[8]Bertsimas, D., and Dunn, J. Optimal classification trees. Machine Learning 106, 7 (2017), 1039�C1082.
���ŷ�����
[9] Bertsimas, D., and Dunn, J. W. Machine learning under a modern optimization lens, 2019.
�ִ��Ż���ͷ�µĻ���ѧϰ
[9]Blanco, V., Jap��n, A., and Puerto, J. A mathematical programming approach to binary supervised classification with label noise. arXiv preprint arXiv:2004.10170 (2020).
�ִ��Ż��ӽ��µĻ���ѧϰ
[11] Blanco, V., Jap��n, A., and Puerto, J. Optimal arrangements of hyperplanes for svmbased multiclass classification. Advances in Data Analysis and Classification 14, 1 (2020), 175�C199.
���ݷ���������չ
[12]Blanco, V., Jap��n, A., and Puerto, J. Robust optimal classification trees under noisy labels. Advances in Data Analysis and Classification (2021).
���ݷ����ͷ���Ľ�չ
[13]Blanco, V., Puerto, J., and Rodriguez-Chia, A. M. On lp-support vector machines and multidimensional kernels. J. Mach. Learn. Res. 21 (2020), 14�C1.
����֧���������Ͷ�ά�˵��о�
[14] Blanquero, R., Carrizosa, E., Molero-R��?o, C., and Morales, D. R. Optimal randomized classification trees. Computers & Operations Research 132 (2021), 105281.
�������������
[15] Breiman, L., Friedman, J., Olshen, R., and Stone, C. Classification and regression trees, 1984.
����ͻع���
[16] Carrizosa, E., Molero-R��?o, C., and Morales, D. R. Mathematical optimization in classification and regression trees. Top 29, 1 (2021), 5�C33.
�ڷ���ͻع����е���ѧ�Ż�
[17] Cortes, C., and V apnik, V. Support-vector networks. Machine learning 20, 3 (1995), 273�C297.
֧����������
[18] Cover, T., and Hart, P. Nearest neighbor pattern classification. IEEE transactions on information theory 13, 1 (1967), 21�C27.
�����ģʽ����
[19] Crammer, K., and Singer, Y. On the algorithmic implementation of multiclass kernelbased vector machines. Journal of machine learning research 2, Dec (2001), 265�C292.
���ڻ��ڶ���˵����������㷨ʵ��
[20] Dietterich, T. G., and Bakiri, G. Solving multiclass learning problems via errorcorrecting output codes. Journal of artificial intelligence research 2 (1994), 263�C286.
ͨ�����������������ѧϰ����
[21] Du, M., Liu, N., and Hu, X. Techniques for interpretable machine learning. Communications of the ACM 63, 1 (2019), 68�C77.
һ�ֿɽ��͵Ļ���ѧϰ����
[22] Eitrich, T., and Lang, B. Efficient optimization of support vector machine learning parameters for unbalanced datasets. Journal of computational and applied mathematics 196, 2 (2006), 425�C436.
��ƽ�����ݼ�֧��������ѧϰ��������Ч�Ż�
[23] Friedman, J., Hastie, T., and Tibshirani, R. The elements of statistical learning, 2001.
ͳ��ѧϰ��Ҫ��
[24] Gan, J., Li, J., and Xie, Y. Robust svm for cost-sensitive learning. Neural Processing Letters (2021), 1�C22.
��������ѧϰ��³��֧��������
[25] Gaudioso, M., Gorgone, E., Labb��, M., and Rodr��?guez-Ch��?a, A. M. Lagrangian relaxation for svm feature selection. Computers & Operations Research 87 (2017), 137�C145.
�������������ɳڵ�svm����ѡ��
[26] Guermeur, Y., and Monfrini, E. A quadratic loss multi-class svm for which a radius�C margin bound applies. Informatica 22, 1 (2011), 73�C96.
һ��Ӧ�ð뾶�߽�Ķ�����ʧ����֧��������
[27] G��nl��k, O., Kalagnanam, J., Menickelly, M., and Scheinberg, K. Optimal decision trees for categorical data via integer programming. arXiv preprint arXiv:1612.03225 (2018).
ͨ�������滮�ķ������ݵ����ž�����
[28] Harris, T. Quantitative credit risk assessment using support vector machines: Broad versus narrow default definitions. Expert Systems with Applications 40, 11 (2013), 4404�C 4413.
ʹ��֧�����������������÷�������:����������ΥԼ����
[29] Hastie, T. J., and Tibshirani, R. J. Generalized additive models, 2017.
����ɼ�ģ��
[30] Jim��nez-Cordero, A., Morales, J. M., and Pineda, S. A novel embedded min-max approach for feature selection in nonlinear support vector machine classification. European Journal of Operational Research 293, 1 (2021), 24�C35.
һ���µ�Ƕ����С-������ڷ�����֧������������
[31] Ka��s��celan, V., Ka��s��celan, L., and Novovi��c Buri��c, M. A nonparametric data mining approach for risk prediction in car insurance: a case study from the montenegrin market. Economic research-Ekonomska istra�� zivanja 29, 1 (2016), 545�C558.
�������շ���Ԥ��ķDz��������ھ�:�Ժ�ɽ�г�Ϊ��
[32] Lauer, F., and Guermeur, Y. Msvmpack: a multi-class support vector machine package. The Journal of Machine Learning Research 12 (2011), 2293�C2296.
Msvmpack:һ������֧����������
[33] Lee, Y., Lin, Y., and W ahba, G. Multicategory support vector machines: Theory and application to the classification of microarray data and satellite radiance data. Journal of the American Statistical Association 99, 465 (2004), 67�C81.
���ڶ����֧�������������Ƿ������ݷ�����о�
[34] Letham, B., Rudin, C., McCormick, T. H., and Madigan, D. Interpretable classifiers using rules and bayesian analysis: Building a better stroke prediction model. The Annals of Applied Statistics 9, 3 (2015), 1350�C1371
ʹ�ù���ͱ�Ҷ˹�����Ŀɽ��ͷ�����:����һ�����õ��з�Ԥ��ģ��
[35] Lewis, D. D. Naive (bayes) at forty: The independence assumption in information retrieval. In European conference on machine learning (1998), Springer, pp. 4�C15.
��Ҷ˹:��Ϣ�����еĶ����Լ���
[36] Majid, A., Ali, S., Iqbal, M., and Kausar, N. Prediction of human breast and colon cancers from imbalanced data using nearest neighbor and support vector machines. Computer methods and programs in biomedicine 113, 3 (2014), 792�C808.
ʹ������ں�֧���������Ӳ�ƽ������Ԥ���������ٰ��ͽ᳦��
[37] Meyer, D., Dimitriadou, E., Hornik, K., Weingessel, A., Leisch, F., Chang, C., and Lin, C. Misc functions of the department of statistics, probability theory group (formerly: E1071). Package e1071. TU Wien (2015).
ͳ��ѧϵ��Misc����,������Ⱥ
[38] Pedregosa, F., V aroquaux, G., Gramfort, A., Michel, V., Thirion, B., Grisel, O., Blondel, M., Prettenhofer, P., Weiss, R., Dubourg, V., et al. Scikit-learn: Machine learning in python. the Journal of machine Learning research 12 (2011), 2825�C 2830.
Scikit-learn: python�еĻ���ѧϰ
[39] Quinlan, J. Machine learning and id3. Los Altos: Morgan Kauffman (1996).
����ѧϰ��id3
[40] Quinlan, R. C4. 5. Programs for machine learning (1993).
����ѧϰ����
[41] Radhimeenakshi, S. Classification and prediction of heart disease risk using data mining techniques of support vector machine and artificial neural network. In 2016 3rd International Conference on Computing for Sustainable Global Development (INDIACom) (2016), IEEE, pp. 3107�C3111.
����֧�����������˹������������ھ��������ಡ���շ����Ԥ��
[42] Tang, X., and Xu, A. Multi-class classification using kernel density estimation on knearest neighbours. Electronics Letters 52, 8 (2016), 600�C602.
��������ں��ܶȹ��ƵĶ�������
[43] van den Burg, G., and Groenen, P. Gensvm: A generalized multiclass support vector machine. Journal of Machine Learning Research 17 (2016), 1�C42.
�������֧��������
[44] Weston, J., and W atkins, C. Support vector machines for multi-class pattern recognition. In Esann (1999), vol. 99, pp. 219�C224.
����֧���������Ķ����ģʽʶ��
[1] Blanco V , A Jap��n, Puerto J . Multiclass Optimal Classification Trees with SVM-splits[J]. 2021.