论文地址:??https://openreview.net/pdf?id=KmykpuSrjcq
开源代码:Prototypical Contrastive Learning of Unsupervised Representations
摘要
原型对比学习(PCL),一种连接对比学习和聚类的无监督表示学习方法。PCL不仅学习了实例识别任务中的低级特征,更重要的是,它将通过聚类发现的语义结构编码到学习到的嵌入空间中。引入原型作为潜在变量,以帮助在期望最大化框架中找到网络参数的最大似然估计。通过E-step聚类寻找原型的分布,并执行M-step,通过对比学习优化网络。提出了ProtoNCE损失,一个关于对比学习的InfoNCE损失的广义版本,它鼓励表示更接近其分配的原型。
介绍
无监督视觉表示学习旨在不依赖标签而从像素本身学习图像表示,最近的进展很大程度上来自实例对比任务。这些方法通常由两个关键的组成部分组成:图像变换和对比损失。图像转换的目标是通过数据增强、斑块扰动或使用动量特征生成代表同一图像的多个嵌入。对比损失,以噪声对比估计器的形式,旨在使来自同一实例的更接近的样本,并从不同实例中分离样本。
尽管实例识别方法的性能得到了改进,但它们也有一个共同的缺点:不鼓励表示来编码数据的语义结构。这个问题的出现是因为实例级对比学习将两个样本视为负对,只要它们来自不同的实例,而不管它们的语义相似性如何。由于产生了成千上万的负样本来形成对比损失,导致许多负对共享相似的语义,但在嵌入空间中被不希望地分开,这一事实被放大了。
本文作者提出了原型的对比学习(PCL),这是一种新的无监督表示学习框架,它隐式地将数据的语义结构编码到嵌入空间中。图1显示了PCL的说明。原型被定义为“一组语义上相似的实例的代表性嵌入”。我们为每个实例分配了几个不同粒度的原型,并构造了一个对比损失,从而使样本的嵌入更类似于相应的原型。在实践中,我们可以通过对嵌入进行聚类来找到原型。

典型的对比学习的说明。每个实例都被分配给多个具有不同粒度的原型。PCL学习一个编码数据语义结构的嵌入空间。
将典型的对比学习制定为一种期望最大化(EM)算法,其目标是找到最能描述数据的深度神经网络(DNN)的参数分分布,通过迭代逼近和最大化对数似然函数。具体地说,我们引入原型作为额外的潜在变量,并通过执行k-means聚类来估计它们在e步中的概率。在m步中,我们通过最小化我们提出的对比损失来更新网络参数,即ProtoNCE。在假设每个原型周围的数据分布是各向同性高斯分布的情况下,最小化ProtoNCE等价于最大化估计的对数似然。在EM框架下,广泛使用的实例识别任务可以解释为原型对比学习的一种特殊情况,其中每个实例的原型都是其增广特征,每个原型周围的高斯分布具有相同的固定方差。本文的贡献可以总结如下:
1.我们提出了原型的对比学习,一个新的框架的无监督表示学习,桥梁对比学习和聚类。我们鼓励学习到的表示来捕获数据集的层次语义结构。
2.我们给出了一个理论框架,将PCL作为一个基于期望最大化(EM)的算法。聚类和表示学习的迭代步骤可以解释为近似和最大化对数似然函数。以往基于实例识别的方法在所提出的EM框架中形成了一个特例。
3.我们提出了一种新的对比损失方法,它通过动态估计每个原型周围特征分布的浓度来改进广泛使用的InfoNCE。ProtoNCE还包括一个InfoNCE术语,其中的实例嵌入可以被解释为基于实例的原型。我们从信息理论的角度对PCL提供了解释,通过显示学习到的原型包含了更多关于图像类的信息。
4.PCL在多个基准测试上优于实例级对比学习,在低资源迁移学习方面有了显著的改进。PCL还可以导致更好的聚类结果。
原型对比学习
准备工作
给定n个图像的训练集X={x1,x2,...,xn},无监督视觉表示学习旨在学习一个嵌入函数fθ(通过DNN实现),该函数用vi=fθ(xi)将X映射到V={v1,v2,...,vn},这样vi最好地描述xi。实例式对比学习通过优化对比损失函数来实现这一目标,如InfoNCE,其定义为:

?在典型的对比学习中,我们使用原型c代替v,用每个原型浓度估计φ代替固定温度τ。我们的训练框架的概述如图2所示,其中聚类和表示学习在每个时代迭代执行。

?原型对比学习的训练框架
PCL期望最大化
?在E-step中与MoCo类似,我们发现来自动量编码器的特征产生了更一致的簇。
在M-step最大对数似然估计为,(原文里有详细的推导过程):

?其中,![]() 表示原型周围特征分布的浓度水平,将在后面介绍。请注意,最大对数似然估计形式与InfoNCE损失相似。因此,InfoNCE可以解释为最大对数似然估计的特殊情况,其中特征vi的原型是来自同一实例的增强特征
表示原型周围特征分布的浓度水平,将在后面介绍。请注意,最大对数似然估计形式与InfoNCE损失相似。因此,InfoNCE可以解释为最大对数似然估计的特殊情况,其中特征vi的原型是来自同一实例的增强特征![]() (即c=
(即c=![]() ),并且在每个实例周围的特征分布的集中程度是固定的(即φ=τ)。
),并且在每个实例周围的特征分布的集中程度是固定的(即φ=τ)。
在实践中,我们采用与NCE和样本r负原型样本相同的方法来计算归一化项。我们还将不同数量的簇![]() 聚类,对编码层次结构的原型具有更稳健的概率估计。此外,我们还增加了InfoNCE损失,以保持局部平滑性,并帮助引导聚类。我们的总体目标,即ProtoNCE,被定义为
聚类,对编码层次结构的原型具有更稳健的概率估计。此外,我们还增加了InfoNCE损失,以保持局部平滑性,并帮助引导聚类。我们的总体目标,即ProtoNCE,被定义为

?浓度估计
每个原型周围的嵌入物的分布有不同的浓度水平。我们使用![]() 来表示浓度估计,其中
来表示浓度估计,其中![]() 越小表示浓度越大。
越小表示浓度越大。![]() 定义为:
定义为:
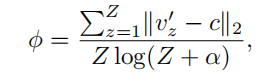
?互信息
研究表明,最小化InfoNCE是为了最大化表示V和![]() 之间的互信息(MI)的下界。同样地,最小化所提出的原型可以看作是同时最大化V和所有原型{V0,C1,...,CM}之间的互信息。
之间的互信息(MI)的下界。同样地,最小化所提出的原型可以看作是同时最大化V和所有原型{V0,C1,...,CM}之间的互信息。
首先,编码器将学习原型之间共享的信息,并忽略每个原型中存在的单个噪声。共享的信息更有可能捕获更高层次的语义知识。其次,我们表明,与实例特征相比,原型与类标签有更大的互信息。我们比较了我们的方法(ProtoNCE)和MoCo(InfoNCE)获得的MI。如图3(b)所示,与实例特征相比,由于聚类的影响,原型具有类标签的MI。此外,与InfoNCE相比,在ProtoNCE上的训练可以随着训练的进行而增加原型的MI,这表明可以学习到更好的表示来形成更有语义意义的集群。

?原型作为线性分类器
?PCL的另一种解释可以为学习原型的本质提供更多的见解。最大对数似然估计类似于使用交叉熵损失来优化聚类分配概率,其中,原型c表示一个线性分类器的权重。通过k-means聚类,线性分类器有一组固定的权值作为每个聚类中表示的平均向量,![]() 。
。
实验略。
?结论
本文提出了原型对比学习,一种通用的无监督表示学习框架,通过寻找网络参数来最大化观测数据的对数似然。我们引入原型作为潜在变量,并在一个基于EM的框架中执行迭代聚类和表示学习。PCL通过对原型损失的训练来学习编码数据语义结构的嵌入空间。我们在多个基准测试上的广泛实验证明了PCL在无监督表示学习方面的优势。
论文中有详细的公式的推导过程,可以在原论文中查看公式的出处。