ǰ��:ֻ�Ǵֶ�,������¼��,��ζ���ȫ�ķ�������,ͦ��ȷ��,�������˼�ǿ��������,�����뾫�����µ�ͬѧ�Ƽ���ԭ�ġ�
ժҪ
��ViT��Ӱ��,��������������CNN�Ĵ��ͺ����,����ָ�������������ͺ˱�ʹ�úܶ�С�ͺ˱��ָ��á����߹��������㷽��,ʹ���ٲ����� (δ֪) �Ĵ������(31*31)����˴����CNN����RepLKNet,�����ģ��:https:
//github.com/megvii-research/RepLKNet
.
����
ΪʲôViTs����ǿ��?�����ձ���Ϊ,ViTs�� �Ķ�ͷ����ע��(MHSA)�������Źؼ����á�����,֮ǰ ���о�����,��������,MHSA���и�����[50],�� ��(���ٵĹ���ƫ��)[19],��ʧ��[66,98]��³��,�� ����ģ��������[69,88],�ȵȡ�Ȼ��,��һ����,��� ��һЩ�о���ս��MHSA[115]�ı�Ҫ��,��ViTs�ĸ����� �������ʵ��Ĺ�����[32]����̬ϡ��Ȩֵ[38,110]�ȡ�
ͼ1��ResNet-101/152��RepLKNet-13/31����Ч����Ұ(ERF)�� �����ֲ�Խ��,��ʾERFԽ����IJ㡣g.)������erf������ Ч�����෴,���ǵĴ����ں�ģ��RepLKNet��Ч�ػ���˴� ��erf��
��ViTs��,MHSAͨ�������Ϊȫ��[33,75,93] ��ֲ�[33,75,93],�����нϴ�Ľ�����[59,70,87](e ��g., ��7��7),���,���Ե���MHSA���ÿ��������� ����һ����Խϴ�������ռ���Ϣ�����,Ȼ��,���� �ں���cnn�в����ձ�ʹ��(���˵�һ��[40])���෴, һ�ֵ��͵ķ�ʽ��ʹ������С�Ŀռ�����Ķ�ջ 1[40,44,47, 68, 74, 79, 108] (e.g.,3��3)�������� ����cnn�Ľ�����ֻ��һЩ��ʽ������,��AlexNet[53] �����[76�C78]��һЩ�����ṹ����[37,43,56,116] �ļܹ�,���ô�Ŀռ����(���С����5)��Ϊ��Ҫ�� �֡���һ�۲�����Ȼ�����һ������:�������Ϊ�� ͳ��cnn����һЩ���ں˶���������С�ں˻���ô��?�� ���ں����ֺ����ܲ��Ĺؼ���?
���ǵ�����һ����ѭSwin��ѹ ��[59]�ĺ�ܹ�,ֻ����һЩ��,ͬʱ�ô����Ⱦ� ��ȡ���˶�ͷ�Ծ۽���������Ҫ����Խϴ��ģ�ͽ��� ������,��ΪViTs��ȥ����Ϊ�ڴ����ݺ�ģ���ϳ��� ��cnn����ImageNet������,���ǵĻ����ṹ���ں˴�С �ߴ�31��31,����ImageNet-1K���ݼ���ѵ�����ɴﵽ 84.8%��ǰ1���ȡ�
ʹ�ô������ָ��
����Ⱦ�����ʹ�ô��
������Ϊ,�� �˾����ڼ������ǰ����,��Ϊ�˵Ĵ�С���ε������� ������FLOPs��������ͨ��Ӧ����ȼ�(DW)����[16,44] ,���Լ���ؿ˷����ȱ�㡣����,����������� RepLKNet��(�����5),�ڴ�[3,3,3,3]�� [31,29,27,13]�IJ�ͬ�������ں˴�Сֻ��ʹFLOPs�� ���������ֱ�����18.6%��10.4%,���ǿ��Խ��ܵġ�ʣ �µ�1��1����ʵ���������˴ָ��ӶȵĹ�����
��˵,�������IJ�����̫��ijһ������˴�С��Ӱ��
���˿��ܻᵣ��,DW��������gpu�������ִ����м��� �豸�Ͽ��ܷdz���Ч����ͳ��DW3��3�ں�Ҳ����� [44,72, ,��ΪDW���������˽ϵ͵ļ�������롣�ڴ���ʳɱ� Ϊ[64],����ִ�����ܹ������Ѻá�Ȼ��,���Ƿ��� ���ں˴�С���ʱ,�����ܶȻ�����:����,�� DW11��11�ں���,ÿ�����Ǵ�����ͼ�м���һ��ֵʱ, �������Բμ�121�γ˷�,����3��3�ں���,����ֻ�� 9�����,���ݳ�����ģ��,���ں˴�С���ʱ,ʵ���� �ٲ�Ӧ�ñ�FLOPs������������ô�ࡣ
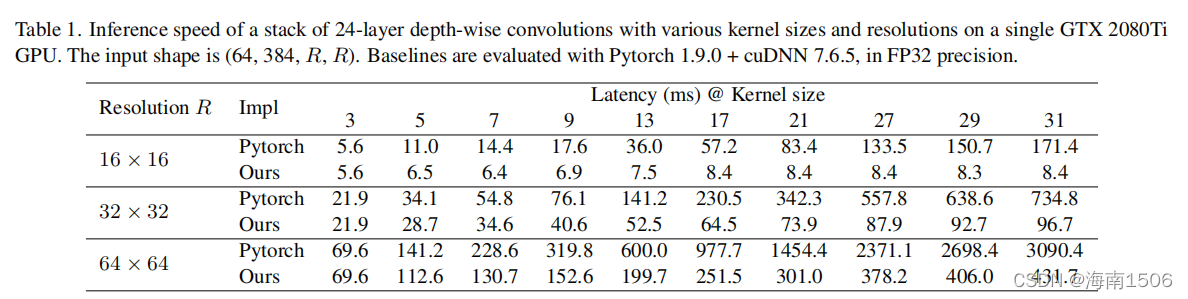
��ע1�����ҵ���,���Ƿ����ֳɵ����ѧϰ����(�� Pytorch)�Դ���DW������֧�ֺܲ�,���1��ʾ�����, ���dz����˼��ַ������Ż�CUDA�ںˡ�����FFT�ķ��� [65]��ʵ�ִ���������ƺ��Ǻ����ġ�Ȼ��,��ʵ���� ,���Ƿ��ֵ��ǿ鼶��(���)implicit gemm�㷨��һ�ֽϺõ�ѡ��ʵ���Ѿ����ɵ��� Դ���MegEngine[1]��,����������ʡ����ϸ�ڡ���1�� ʾ,��Pytorch�������,���ǵ�ʵ��Ч��Ҫ�ߵöࡣͨ �����ǵ��Ż�,RepLKNet��DW�������ӳٹ��״�49.5%�� �ٵ�12.3%,�������FLOPs��ռ�óɱ�����
shotcut��ʹ��
��ע2����ָ��Ҳ������ViTs��[32]�����һ���о����� ,���û�����ݽݾ�,ע����������ȳ�˫ָ���½�, ���¹���ƽ�����⡣��Ȼ���cnn�����Բ�ͬ��ViT�Ļ� ���˻�,������Ҳ�۲쵽,���û�нݾ�,������Ѳ� ��ֲ�ϸ�ڡ�����[89]���ƵĽǶ�����,��ݷ�ʽʹģ �ͳ�Ϊһ����������в�ͬ������(RFs)��ģ����ɵ��� ʽ����,��������ԴӸ���������Ƶ�л���,������ ʧȥ����С��ģģʽ��������
��С�ں����²�����[29]�������ֲ��Ż�����
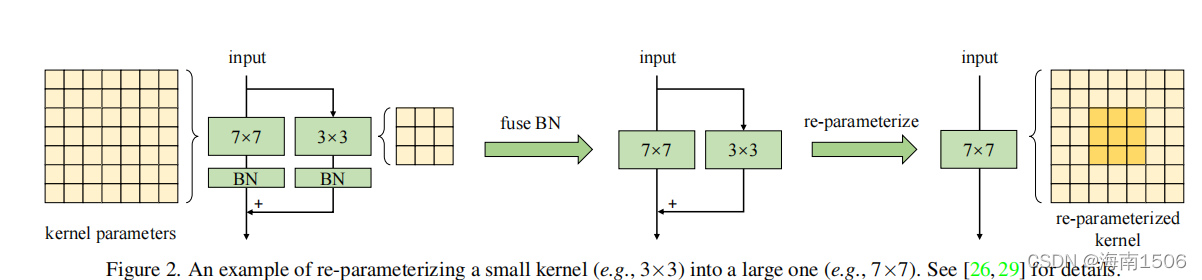
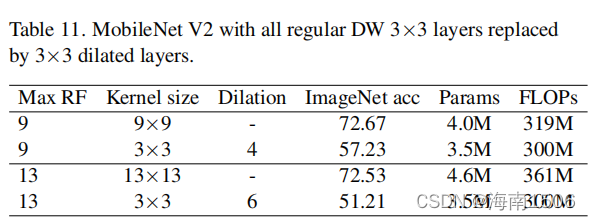
���ǽ�MobileNetV2��3��3��ֱ��滻Ϊ9��9��13��13, ����ѡ����ýṹ�ٲ�����[25,26,29]������������˵ ,���ǹ�����һ��ƽ���ڴ���3��3��,Ȼ����Batch�� һ��(BN)[49]���������ǵ����(ͼ��2).����ѵ���� ,���ǽ�С�˺�BN�����ϲ��������,��˵õ���ģ�� ��ѵ��ģ�͵ȼ�,��������С�ˡ���3��ʾ��ֱ�ӽ��ں� ��С��9���ӵ�13������ȷ��,�����²������������ �����⡣
û����!!!
��ע3��������֪,ViTs�����Ż�����,�ر�����С���� ��[33,57]�ϡ�һ�������Ľ�������������������,�� ��,��ÿ����ע���[17,96]������һ��DW3��3����,�� �����ǵķ������ơ���Щ����������֮ǰ�����˶���� ƽ�Ƶȷ���;ֲ���,ʹ�ö�С���ݼ����������Ż� ����ʧȥͨ���ԡ���ViT��Ϊ��[33]����,���ǻ�����, ��Ԥѵ�����ݼ����ӵ�7300����ͼ��ʱ(�μ���һ���е� RepLKNet-XL)ʱ,���²��������Ա�ʡ�Զ����˻���
�Ա�����ImageNet����Ч��,���;��������������������Ч��
�� 3(���½�����)��ʾ,��MobileNetV2���ں˴�С�� 3��3���ӵ�9��9,ImageNet�ľ��������1��33%,���� �о��۵�mIoUΪ3.99%����5��ʾ��һ�� ���Ƶ�����:�����ں˴�С��[3,3,3,3]���ӵ� [31,29,27,13],ImageNet��ȷ�ʽ������0.96%,�� ADE20K[114]�ϵ�mIoU�����3.12%�������������simi ģ�� LarImageNet���������������п����зdz���ͬ�� ����(�����5�еײ���3��ģ��һ��)��
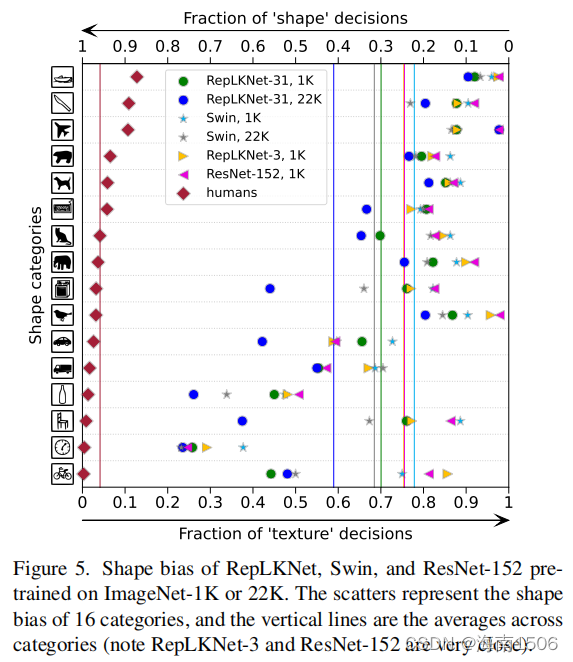
��ע4����ʲô ��������������?����,�����ں����������������Ч ������(ERFs)[63]��������Ѿ�֤���ˡ������ġ��� Ϣ,����ζ�Ŵ��erf,����������������������Ҫ,�� Ŀ����� ����ָ�[61,67,91,101,102]������ ���ڵڶ���������������⡣5.1.���,������Ϊ��һ ��ԭ������Ǵ����ں���ƶ���������˸������״ƫ ���˵,ͼ������ͼƬ���Ը��������� ��״, ����[7,34]�������������Ȼ��,����ʶ����������� ��Ҫ�ǻ�����״�������������� ���,���н�ǿ��״ ƫ���ģ�Ϳ��Ը��õ�ת�Ƶ���������[86]�����һ���о�ָ��,ViTs����ǿ�ҵ� ��״ƫ��,�ⲿ�ֽ�����ΪʲôViTs��ת�������г��� ǿ�����֮��,��ImageNet��ѵ���Ĵ�ͳcnn������ƫ ��������[7,34]�����˵���,���Ƿ��ּ�����cnn�� �˴�С������Ч�ظ�����״ƫ������Sec��5.2��ϸ ��Ϣ��
�����ں�(eg.,13��13)��ʹ����С��������ͼ(eg.,7��7)
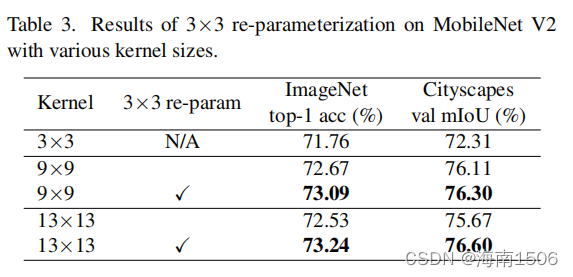
Ϊ����֤��,���ǽ�MobileNetV2���� ��ν�DW��������7��7��13��13,����ں˴�С�� ����ӳ���С(Ĭ��Ϊ7��7)�൱,�����������ǰ� ��ָ��3�Ľ���,�Դ����ں˽������²�����Ӧ�á���4 ��ʾ,��Ȼ�����һ�εľ����Ѿ��漰���dz���Ľ� ����,��һ����- �ۼ��ں˴�С��Ȼ�ᵼ�����ܸĽ�,�ر������������� ��,����о��ۡ�
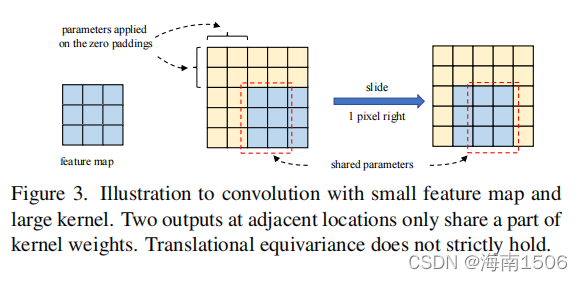
��ע5�����˴�С���ʱ,��ע��,cnn��ƽ�Ƶȷ�� ���ϸ��������ͼ3��ʾ��������������ڵĿռ��- ������ֻ������Ȩ�ص�һС����,��, ��ͨ����ͬ��ӳ�����ת���ġ�����Ҳ ����vits�ġ���ѧ��-���ɹ�����ϵ- �ڻ�ø��������֮ǰ����Ȥ����,���Ƿ����˶�ά ���λ��Ƕ��(RPE)[4,73],��Ӧ�ù㷺 �ڱ�ѹ��������ʹ�õ�,Ҳ���Ա���Ϊa �����ȼ��ں˴�С(2H?1)��(2W?1),���� �����ں˲���������ѧϰ����֮������λ��,������ �����ЧӦ[51]���Ծ���λ����Ϣ���б��롣
RepLKNet:һ�������ں���ϵ�ṹ
��������ָ������,�ڱ�����,���������RepLKNet ,����һ�����д����ں���ƵĴ�CNN�ܹ�����������֪ ,��ĿǰΪֹ,cnn��Ȼ������С���ͺŵ�[107,109], ���Ӿ���ѹ������Ϊ�ڸ����ӵ�Ԥ���±�cnn���á���� ,�ڱ�����,������Ҫ��ע��Խϴ��ģ��(�临�Ӷ��� ResNet-152[40]��Swin-B[59]��ͬ�����),����֤��� �ں�����Ƿ��������cnn��ViTs֮������ܲ�ࡣ
��ϵ�ṹ�淶
������ͼ4�л�����RepLKNet�ļܹ�����ָ������ʼ�㡣�������ǵ�Ŀ���������ܼ�Ԥ���� ��ĸ�����,�������ϣ���ڿ�ʼʱͨ������conv�㲶 �����ϸ�ڡ���ǰ3��������3��֮��,���ǰ�����һ�� DW3��3���������ˮƽģʽ,һ��1��1conv,��һ�� DW3��3����н�������
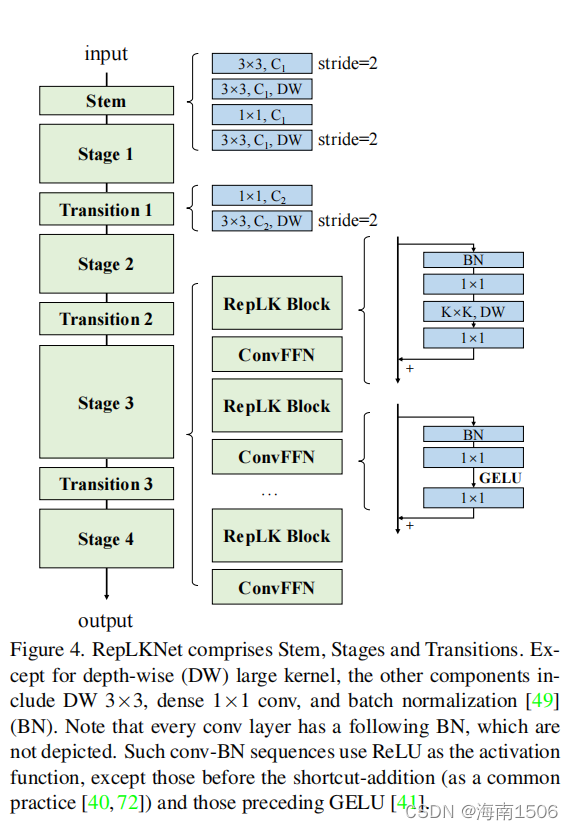
��1-4��ÿ������������RepLK��,����ʹ�ÿ�ݷ� ʽ(ָ��1)��DW�����ں�(ָ��2)������ʹ��DWconv ǰ���1��1conv��Ϊһ�ֳ�������������ע��,ÿ��DW ����convʹ��һ��5��5�ں˽������²�����(ָ��3), ����ͼ��û����ʾ��4.�����ṩ�㹻�Ľ�����;ۼ��� ����Ϣ��������,ģ�͵ı�������Ҳ�����������ء� Ϊ���ṩ����ķ����ԺͿ�ͨ������Ϣͨ��,����ϣ�� ʹ��1��1����������ȡ��ܵ��ڱ�ѹ��[33,59]�� MLPs[25,82,83]�й㷺ʹ�õ�ǰ������(FFN)������,�� ��ʹ����һ�����Ƶ�cnn���Ŀ�,�ɿ�ݷ�ʽ��BN���� ��1��1���GELU[41]���,���������ΪConvFFN�顣�� �����FFNʹ�ò��-��ȫ���Ӳ�֮ǰ,BN���ŵ��ǿ����ںϵ�conv�н����� Ч���ƶϡ�ͨ�������,ConvFFN����ڲ�ͨ������Ϊ 4����Ϊ���롣����ѭViT��Swin,���ǽ�֯��ע�� ����FFN��,������ÿ��RepLK��֮�����һ��ConvFFN�����ɿ鱻������������֮��,���� ͨ��1��1conv����ͨ���ߴ�,Ȼ��ʹ��DW3��3conv���� 2���������� ��������,ÿ���ζ��������ܹ�������:RepLK��� ����B��ͨ��ά��C���ں˴�СK�����,RepLKNet��ϵ�� ������[B]����1,B2,B3,B4], [C1,C2,C3,C4], [K1,K2,K3,K4].
ʹ����ں���������
����ͨ���̶�B=[2,2,18,2],C=[128,256,512,1024] ,�ı�K,���۲���������ָ������,�������� RepLKNet�ϵĴ����ںˡ���û����ϸ��������������� ��,��������ؽ��ں˴�С�ֱ�����Ϊ[13,13,13,13]�� [25,25,25,13]��[31,29,27,13],����ģ�ͳ�Ϊ RepLKNet-13/25/31�����ǻ�����������С�ں˻��߳ߴ綼Ϊ3��7(RepLKNet-3/7)��
��ImageNet��,����ʹ��AdamW[62]�Ż����������ǿ [21]�����[106]��CutMix[105]��Rand����[112]����� ���[48]ѵ����120��ʱ��,��ѭ����Ĺ��� [3,59,60,84]����ϸ����ѵ���ü���¼A��
��������ָ�,����ʹ��ADE20K[114],����һ���㷺 ʹ�õĴ��ģ����ָ����ݼ�,����150������20Kͼ ������ѵ��,2K������֤������ʹ��imagenetѵ����ģ ����Ϊ�Ǹ�,����MMS�ָ�[18]ʵ�ֵ�UperNet[97]��80k ����ѵ������,�����Ե��߶ȵ�mIoU��
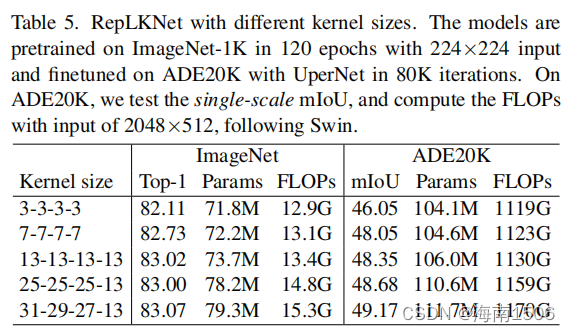
��5��ʾ�������ڲ�ͬ�ں˴�С�µĽ������ImageNet ��,��Ȼ���ں˴�С��3���ӵ�13������߾���,��ʹ�� �Ǹ����������һ���ĸĽ���.82Ȼ��,��ADE20K�� ,���ں˴�[13,13,13,13]��չ��[31,29,27,13]�����0 �����ߵ�mIoU,ֻ������5.3%�IJ�����3.5%��FLOPs,�� ͻ���˴����ں˶��������������Ҫ�ԡ�
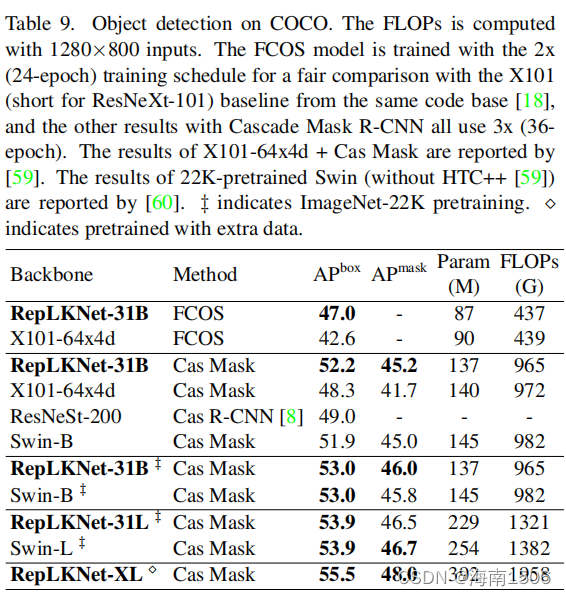
�������С����,����ʹ�þ��и�ǿѵ�����õ� RepLKNet31,��ImageNet���ࡢ���о���/ADE20K����� ���COCO[55]Ŀ������бȽϡ����ǽ�����ģ�ͳ�Ϊ RepLKNet-31B(B��ʾBase),��C=[192,384,768,1536]�� ����ģ�ͳ�ΪRepLKNet31L(Large)��������RepLK��� C=[256,512,1024,20282]��1.5������ƿ����ƹ������� һ��RepLKNet-xl��e., DW����ת�����ͨ��Ϊ1.5���� Ϊ����)��
ImageNet����
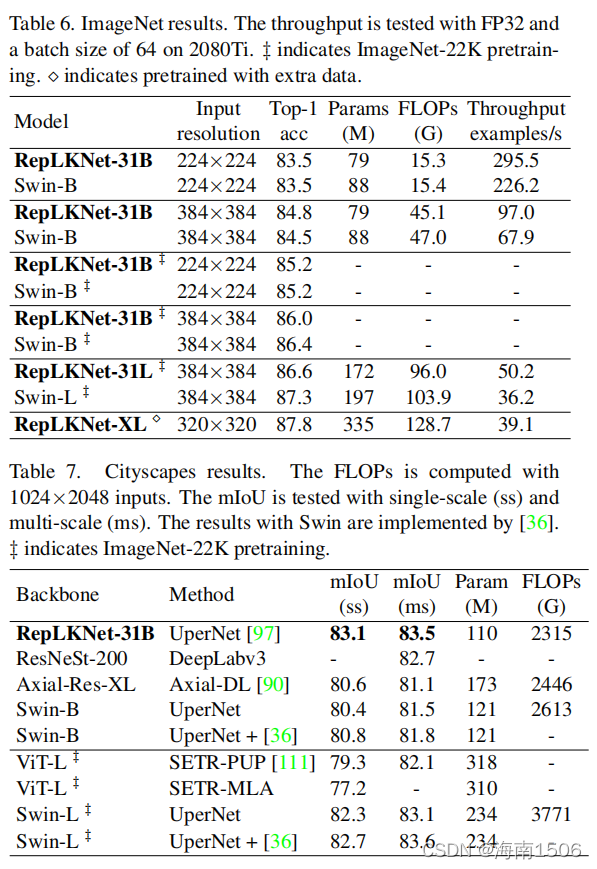
����RepLKNet������ܹ�������Swin,��������ϣ�� ������һ���Ƚϡ�����ImageNet-1K�ϵ�RepLKNet-31B, ���ǽ�����ѵ���ƻ���չ��300��ch,�Խ��й�ƽ�ıȽ� ��Ȼ��,��������ֱ���Ϊ384��384,��30��ʱ������ ��,ʹ��ѵ���ɱ�Ҫ�͵ö� ������Swin-Bģ��,������384��384ѵ���Ĵ�ͷ����Ȼ��,������ImageNet-22K��Ԥѵ��RepLKNet- B/Lģ��,����ImageNet-1K�Ͻ�������RepLKNetXL�� ��������ΪMegData73M��˽�а�ල���ݼ��Ͻ���Ԥѵ ����,�����ݼ��ڸ�¼�н��ܡ����ǻ��ṩ������ͬ�� 2080TiGPU�ϵ�������СΪ64�����������ԡ���ѵ������ ��¼�н��ܡ�
��6��ʾ,��Ȼ�dz�����ں˲�������ImageNet����, �����ǵ�RepLKNetģ����ʾ��ȷ�Ժ�Ч��֮������� Ȩ�⡣ֵ��ע�����,��ͨ��ImageNet-1Kѵ��, RepLKNet-31B��ȷ�ʴﵽ84.8%,��Swin-B��0.3%,�� ���ٶȿ�43%������RepLKNet-XL��Swin-L�и��ߵ����� ,�������еø���,��ͻ���˷dz�����ں˵�Ч�ʡ�
����ָ�
Ȼ��,����ʹ��Ԥ��ѵ���õ�ģ����Ϊ���о���(��7 )��ADE20K(��8)�ϵĹǸɡ�������˵,����ʹ���� MMS�ָ�[18]ʵ�ֵ�UperNet[97],���о��۲���80K���� ѵ���ƻ�,ADE20K����160K����Ϊ�������������ֻʹ������,���Dz�ʹ���κ��Ƚ��ļ���,����,���� �����㷨�� �ڳ��о�����,ImageNet-1kԤѵ����RepLKNet31B�� ������������Swin-B(���߶�mIoUΪ2.7),�������� ImageNet22kԤѵ����Swin-L����ʹ�䱸��Ϊ�Ӿ���ѹ�� ���Ƶļ�����������[36],22kԤѵ����Swin-L�ĵ��߶� mIoU��Ȼ�������ǵ�1kԤѵ����RepLKNet-31B,����ǰ ����2���������� ��ADE20K��,RepLKNet-31B��1K��22KԤѵ��ǰ������ Swin-B,�ҵ��߶�mIoU�ı�Ե����������ʹ�����ǵİ� �ල���ݼ�MegData73M����Ԥѵ��,RepLKNet-XLʵ���� 56.0��mIoU,��ʾ�˴��ģ�Ӿ�Ӧ�õĿ������ԡ�

Ŀ����
��ģR-CNN[8,39]������,���Ƿֱ���һ�κ����� ��ⷽ���Ĵ���������ʹ��2x(24ʱ��)��3x)(36ѵ�� �ƻ���MM���[12]�е�Ĭ�����á�Ϊ�˹�ƽ�ıȽ�,�� �Dz���ResNeXt-101-64x4d[99]����,�����뾺�������� ͬ�Ĵ���⡣ͬ��,����ֻ���滻������,����ʹ���� ���Ƚ��ļ�����
����
���cnn�����С��ģ��
��ĿǰΪֹ,�����Ѿ�֤���˴����ں���ƿ������� ���cnn������(�ر���������������)������,ֵ��ע �����,��ĺ˿�����һϵ�е�С����[74]����ʾ:�� ��,һ��7��7�ľ������Էֽ������3��3�˵Ķ�ջ���� ��ʧ��Ϣ3.���ǵ���һ��ʵ,��Ȼ�ͳ�����һ������: Ϊʲô��ͳ��cnn���ܰ�����ʮ�����ٸ�С����(e��g., ResNets[40]),��Ȼ���ֵò�����������?
������Ϊ,�ڻ�ô�Ľ�������,�������ں˱��� ��С�ں˸���Ч������,������Ч�����Ե����� �ֶ� (ERF)[63],ERF�Ĵ�С��O(K^L)������,����KΪ�˴�С ,LΪ���,i��e., �������仰˵,ERF��˴�С������ ��,��������������������,��ȵ������������Ż� ���Ѷ�

����ResNets�ƺ��˷����������,�ɹ���ѵ���� һ�����ٲ������,��һϵ���о�����ResNets���ܲ��� �����������ǿ������������,[89]��ΪResNets����Ϊ�� ��dz������ļ���,����ζ�ż�ʹ�����������, ResNets��ERFs��Ȼ���ܷdz����ޡ�������������ǰ���� ����Ҳ�о���۲쵽��g., [52].��������,�����ں��� ����Ҫ���ٵIJ�����ô��erf,Ҳ��������ȵ����Ӵ� �����Ż����⡣
Ϊ��֧�����ǵĹ۵�,����ѡ��ResNet101/152������ RepLKNet-13/31��ΪС�˺ʹ��ģ�͵Ĵ���,��Щģ�� ����ImageNet���ܹ����õ�ѵ��,��ʹ������ImageNet ��֤���е�50��ͼ����в���,������СΪ1024��1024 ��Ϊ�˿��ӻ�ERF,������[52]֮��ʹ����һ�ּ��� Ч�ķ���,�總¼B�������������֮,��������һ���� �Ϲ���������A(1024��1024),����ÿ����Ŀ A(0��a��1)��������ͼ���϶�Ӧ�����ض����һ����� ������ͼ�����ĵ�Ĺ��ס�ͼ1��ʾ��ResNet-101�ĸ߹� �����ؾۼ������ĵ���Χ,���ⲿ��Ĺ��ܵ�,���� ERF���ޡ�ResNet-152Ҳ���ֳ����Ƶ�ģʽ,��������� 3����3�㲢û����������ERF����һ����,ͼ�еĸ߹��� ���ء�1?�ֲ�������,����RepLKNet-13��ע������� �����ء����ڽϴ���ں�,RepLKNet-31ʹ�߹������ص� ��ɢ���Ӿ���,����ERF����
��10�ṩ��һ����������,�������DZ�����һ����С ���εĸ߹����������T,�������˸�����ֵt�ϵĹ��� ����������,ResNet-101��20%�����ع���(Aֵ)λ���� �ĵ�103��103������,��������Ϊ(103/1024) 2=1.0%,t=Ϊ20%�� �������˼�����Ȥ�Ĺ۲졣1)ResNet��erf��RepLKNetС �öࡣ����,ResNet-101��99%���ϵĹ�����λ��һ�� С������,����ֻռ�������23.4%,��RepLKNet-31�� �����Ϊ98.6%,����ζ�Ŵ����ض����յ�Ԥ���кܴ�Ĺ��ס�2)��ResNet-101������ ����IJ㲢������Ч������ERF,�������ں˿������ ERF��
���ģ���������������״ƫ��
[86]�����һ���о������,�Ӿ�ת�������������� ����Ӿ�ϵͳ,���ǵ�Ԥ�������������������״, ��cnn�����ع�ע�ֲ����������Dz�֪�� �����䷽��,��ʹ���乤����[5]�������IMageNet-1K ��22K��Ԥѵ����RepLKNet-31B��Swin-B����״ƫ��(�� ��,������״,������������Ԥ��IJ���),�Լ����� С�˻���RepLKNet-3��ResNet-152��ͼ5����RepLKNet�� Swin���и��ߵ���״ƫ����ǵ�RepLKNet��Swin���� ���Ƶ�����ܹ�,������Ϊ��״ƫ������Ч���ܳ����� ���,����������ע��ľ��幫ʽ(����ѯ-��-ֵ��� )����Ҳ������1)����״ƫ�����[33]��[86]����( ��Ϊ[33]����ȫ���ע),2)����״ƫ���˫��̥(�� ע���ش���),��3)����״ƫ��С�˻���RepLKNet-3, �dz��ӽ�ResNet-152(����ģ�Ͷ�����3��3����)��
�ܼ��ľ���vsϡ�͵ľ���
��Ϊʵ�ִ��������һ���������,���ž���[13,101] �����ӽ���Ұ(RF)�Ĺ�ͬ��ɲ��֡�Ȼ��,��11��ʾ, ������ȵ����ž�������������ܼ�����������ͬ���� ����Ƶ,�����ʾ����Ҫ�͵ö�,��������֮�е�,�� Ϊ������ѧ�ϵ�ͬ��ϡ��Ĵ����������(��[92,98]) ��һ������,��չ�ľ������ܻ�����������⡣������ Ϊ���;�����ȱ�����ͨ����ϲ�ͬ���͵ľ������˷� ,�⽫��δ�������о���
����
���ܴ����ں���Ƽ���ظĽ���ImageNet���������� �ϵ�cnn,Ȼ��,���ݱ�6,�������ݺ�ģ��ģ������ ,RepLKNet��ʼ�����Swin���ν��,e��g., RepLKNet -31L��ImageNetǰ1λ����Ϊ0����ʹ��ImageNet-22KԤ ѵ��ʱ��Swin-L��7%(�����εķ�����Ȼ���пɱ���) ��Ŀǰ�в�������ֲ�������ڴ��ų�����������ɵ� ,������������/ģ����չʱcnn����������ȱ����ɵ� �����������о��������,����,�о�һ����ǿ���CNN ����(����,ConNvNeXt[60])�Ƿ�������ͨ�������ں��� �Ƴ���ViT���Ͻ硣
����
���Ļع�����CNN�ܹ�����г������������ӵĴ��;� ���ˡ�����֤��,ʹ��һЩ���ں˶���������С�ں˿� �Ը���Ч�ػ�ø������Ч�Ľ�����,���CNN������, �ر���������������,�����ݺ�ģ������ʱ,�����С ��CNN��vit֮������ܲ�ࡣ����ϣ�����ǵĹ����ܹ� �ٽ�cnn��ViTs���о���һ����,����CNN������˵,�� �ǵ��о������������Ӧ���ر��עERFs,�������ʵ �ָ�Ч�Ĺؼ�����һ����,����ViT����,���ڴ������Ϊ����������Ϊ�Ķ�ͷ����ע������Ʒ,������ ��������������ע������ڻ��ơ�