video_feature_extractor1
在复现video-extractor中,我需要的是一个统一尺寸的特征图,但是它的输出大小不一样。后来整了很长时间,一直以为是sampler中存在的问题,改了很多,一点用没有,最后发现是video-loader中存在的问题。
1、之前提取的特征尺寸老是不一样,特征shape和视频长短相关。经过仔细阅读源码,发现是是ffmpeg中关于提取视频帧设置有一定的问题。
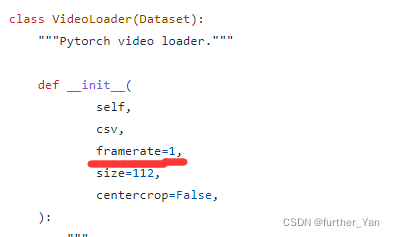
在videoLoader中ffmpeg默认参数抽取频率为1fps
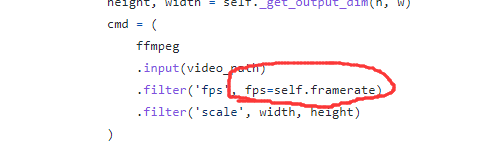
为了将不同长度的视频提取相同数目的帧,将提取视频的帧率保存到input.csv中
将每段视频的视频地址 ,保存特征地址、帧率
video-path,feature-path,framerate
import csv
import os
import numpy as np
import cv2
video_path = "../cnn-lstm-master/data/video_data/WritingOnBoard/"
# n = [["/home/t123/projects/cnn-lstm-master/data/video_data/WritingOnBoard/v_WritingOnBoard_g25_c07.avi", "/home/t123/projects/video_feature_extractor-master/tools/A.npy"]]
b = ["video_path", "feature_path", "framerate"]
feature_path = "../video_feature_extractor-master/tools/feature1/"
n1 = []
videos = os.listdir(video_path)
for v in videos:
v_path = os.path.join(video_path, v)
# print(v[:-4])
f_path = os.path.join(feature_path, v[:-4]+".npy")
try:
cap = cv2.VideoCapture(v_path)
fps = int(round(cap.get(cv2.CAP_PROP_FPS)))
except:
print('Can not open %s.' % video_path)
pass
frames = []
frame_count = 0
while True:
ret, frame = cap.read()
if ret is False:
break
frame = frame[:, :, ::-1]
frames.append(frame)
frame_count += 1
num_features = 16
framerate = float(num_features* fps/ frame_count)
print(framerate)
# np.save(f_path,[])
n1.append([v_path, f_path, framerate])
with open("input.csv", 'w', newline='') as t: # numline是来控制空的行数的
writer = csv.writer(t) # 这一步是创建一个csv的写入器
writer.writerow(b) # 写入标签
writer.writerows(n1) # 写入样本数据
其中farmerate = num_features[提取多少帧的特征]*fps[帧率] / frame_count[视频的总帧数]
video-loder.py修改之后的代码
import torch as th
from torch.utils.data import Dataset
import pandas as pd
import os
import numpy as np
import ffmpeg
import cv2
class VideoLoader(Dataset):
"""Pytorch video loader."""
def __init__(
self,
csv,
size=112,
centercrop=False,
):
"""
Args:
"""
self.csv = pd.read_csv(csv)
self.centercrop = centercrop
self.size = size
def __len__(self):
return len(self.csv)
def _get_video_dim(self, video_path): # 解析视频信息,讲视频分解成图片流 #这里好像提取的是每秒一帧
probe = ffmpeg.probe(video_path)
video_stream = next((stream for stream in probe['streams']
if stream['codec_type'] == 'video'), None)
width = int(video_stream['width'])
height = int(video_stream['height'])
return height, width
def _get_output_dim(self, h, w): #讲视频转换成项目需要的大小
if isinstance(self.size, tuple) and len(self.size) == 2:
return self.size
elif h >= w:
return int(h * self.size / w), self.size
else:
return self.size, int(w * self.size / h)
def __getitem__(self, idx):
video_path = self.csv['video_path'].values[idx]
output_file = self.csv['feature_path'].values[idx]
framerate = self.csv['framerate'].values[idx]
if not(os.path.isfile(output_file)) and os.path.isfile(video_path):
print('Decoding video: {}'.format(video_path))
try:
h, w = self._get_video_dim(video_path)
except:
print('ffprobe failed at: {}'.format(video_path))
return {'video': th.zeros(1), 'input': video_path,
'output': output_file}
height, width = self._get_output_dim(h, w)
cmd = (
ffmpeg
.input(video_path)
.filter('fps', fps=framerate)
.filter('scale', width, height)
)
out,_ = (
cmd.output('pipe:', format='rawvideo', pix_fmt='rgb24')
.run(capture_stdout=True)#quiet=True
)
if self.centercrop:
x = int((width - self.size) / 2.0)
y = int((height - self.size) / 2.0)
cmd = cmd.crop(x, y, self.size, self.size)
if self.centercrop and isinstance(self.size, int):
height, width = self.size, self.size
video = np.frombuffer(out, np.uint8).reshape([-1, height, width, 3])
video = th.from_numpy(video.astype('float32'))
video = video.permute(0, 3, 1, 2)
else:
video = th.zeros(1)
return {'video': video, 'input': video_path, 'output': output_file}
其中将videoloader文件默认的self.framerate删掉了,将帧率用预先处理的数据作为输入。
这样处理的原因,我不知道ffmpeg有没有自带的方法。
最后将extract.py中VideoLoader()中framerate删掉就可以用了。
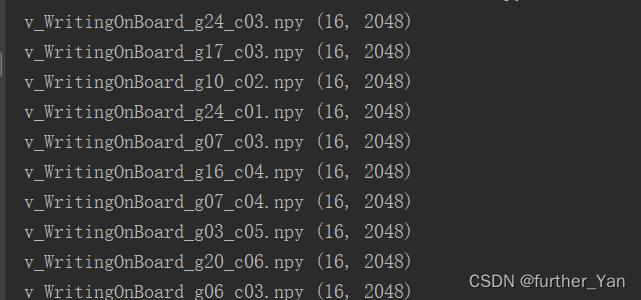
最后得到了我想要的结果了。
希望对大家有用!欢迎大家一起交流opencv和ffmpeg的用法!