我的代码在kaggle上跑的
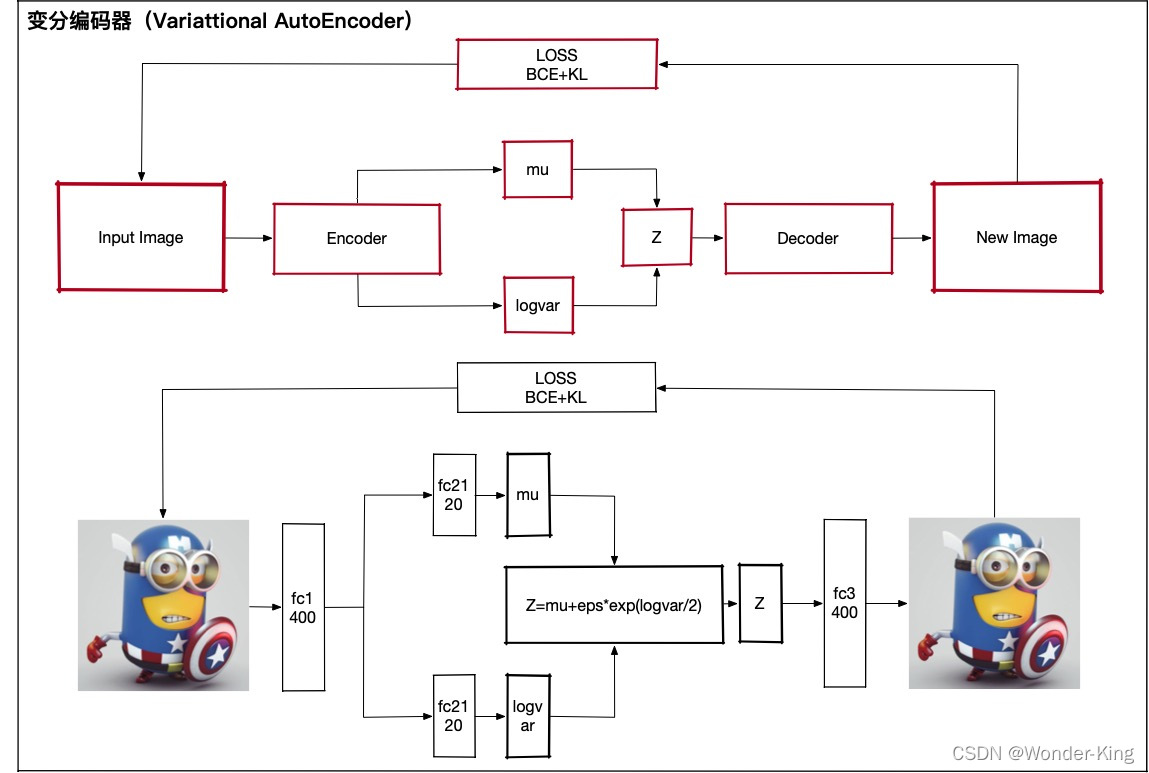
VAE
import torch
import torchvision
from torch import nn
from torch import optim
import torch.nn.functional as F
from torch.autograd import Variable
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision.utils import save_image
from torchvision.datasets import MNIST
import os
import numpy as np
if not os.path.exists('./vae_img'):
os.mkdir('./vae_img')
def to_img(x):
x = x.clamp(0, 1)
x = x.view(x.size(0), 1, 28, 28)
return x
reconstruction_function = nn.MSELoss(size_average=False)
def loss_function(recon_x, x, mu, logvar):
"""
recon_x: generating images
x: origin images
mu: latent mean
logvar: latent log variance
"""
BCE = reconstruction_function(recon_x, x) # mse loss
# loss = 0.5 * sum(1 + log(sigma^2) - mu^2 - sigma^2)
KLD_element = mu.pow(2).add_(logvar.exp()).mul_(-1).add_(1).add_(logvar)
KLD = torch.sum(KLD_element).mul_(-0.5)
# KL divergence
return BCE + KLD
class VAE(nn.Module):
def __init__(self):
super(VAE, self).__init__()
self.fc1 = nn.Linear(784, 400)
self.fc21 = nn.Linear(400, 20)
self.fc22 = nn.Linear(400, 20)
self.fc3 = nn.Linear(20, 400)
self.fc4 = nn.Linear(400, 784)
def encode(self, x):
h1 = F.relu(self.fc1(x))
return self.fc21(h1), self.fc22(h1)
def reparametrize(self, mu, logvar):
std = logvar.mul(0.5).exp_()
if torch.cuda.is_available():
eps = torch.cuda.FloatTensor(std.size()).normal_()
else:
eps = torch.FloatTensor(std.size()).normal_()
eps = Variable(eps)
return eps.mul(std).add_(mu)
def decode(self, z):
h3 = F.relu(self.fc3(z))
return F.sigmoid(self.fc4(h3))
def forward(self, x):
mu, logvar = self.encode(x)
z = self.reparametrize(mu, logvar)
return self.decode(z), mu, logvar
model = VAE()
print(model)
# 查看网络流程
class net(nn.Module):
def __init__(self):
super(net, self).__init__()
self.fc1 = nn.Linear(784, 400)
self.fc21 = nn.Linear(400, 20)
self.fc22 = nn.Linear(400, 20)
self.fc3 = nn.Linear(20, 400)
self.fc4 = nn.Linear(400, 784)
def encode(self, x):
h1 = F.relu(self.fc1(x))
print("Linear shape",self.fc1(x).shape)
print("Relu shape",h1.shape)
return self.fc21(h1), self.fc22(h1)
def reparametrize(self, mu, logvar):
std = logvar.mul(0.5).exp_()
eps = torch.FloatTensor(std.size()).normal_()
eps = Variable(eps)
return eps.mul(std).add_(mu)
def decode(self, z):
h3 = F.relu(self.fc3(z))
print("h3 shape",self.fc3(z).shape)
print("Relu shape",h3.shape)
print("Linear shape",self.fc4(h3).shape)
return F.sigmoid(self.fc4(h3))
def forward(self, x):
print("input shape",x.shape)
mu, logvar = self.encode(x)
print("mu shape",mu.shape)
print("logvar shape",logvar.shape)
z = self.reparametrize(mu, logvar)
print("z shape",z.shape)
return self.decode(z), mu, logvar
net = net()
X = torch.rand(size=(1,1,28,28), dtype=torch.float32)
X = X.view(X.size(0), -1)
recon_batch, mu, logvar = net(X)
print("sigmoid shape",recon_batch.shape)
if torch.cuda.is_available():
model.cuda()
num_epochs = 50
batch_size = 128
learning_rate = 1e-3
img_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.5], [0.5])
])
dataset = MNIST('./data', transform=img_transform, download=True)
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
for epoch in range(num_epochs):
model.train()
train_loss = 0
for batch_idx, data in enumerate(dataloader):
img, _ = data
img = img.view(img.size(0), -1)
img = Variable(img)
if torch.cuda.is_available():
img = img.cuda()
optimizer.zero_grad()
recon_batch, mu, logvar = model(img)
loss = loss_function(recon_batch, img, mu, logvar)
loss.backward()
train_loss += loss.data.item()
optimizer.step()
if batch_idx % 100 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch,
batch_idx * len(img),
len(dataloader.dataset), 100. * batch_idx / len(dataloader),
loss.data.item() / len(img)))
print('====> Epoch: {} Average loss: {:.4f}'.format(
epoch, train_loss / len(dataloader.dataset)))
if epoch % 10 == 0:
save = to_img(recon_batch.cpu().data)
save_image(save, './vae_img/image_{}.png'.format(epoch))
torch.save(model.state_dict(), './vae.pth')
n = 20 #15*15 225个数字图片
digit_size = 28
figure = np.zeros((digit_size*n,digit_size*n))#最终图片
start = 0
end = 0.3
cnt = (end-start)/(n-1)
for i in range(n):
for j in range(n):
z_sample = np.array([[[[start+i*cnt,start+j*cnt]]]],dtype=np.float32)#重复z_sample多次,形成一个完整的batch
z_sample = np.tile(z_sample, batch_size*392).reshape(batch_size,784)
z_sample = torch.from_numpy(z_sample) # 转tensor
z_sample = z_sample.cuda()# 放到cuda上
output, _, _ = model(z_sample)
digit=output[0].reshape(digit_size, digit_size)#128*784->28*28
digit = digit.cpu().detach().numpy() # 转numpy
figure[i*digit_size:(i+1)*digit_size,j*digit_size:(j+1)*digit_size] = digit
plt.figure(figsize=(10, 10))
plt.imshow(figure, cmap='Greys_r')
plt.show()AE代码实现和可视化:
参考:
PyTorch 实现 VAE 变分自编码器 含代码_赵继超的笔记-CSDN博客_vae代码pytorchimport torchimport torchvisionfrom torch import nnfrom torch import optimimport torch.nn.functional as Ffrom torch.autograd import Variablefrom torch.utils.data import DataLoaderfrom torchvision import transformsfrom torchvision.utils import save_ihttps://blog.csdn.net/weixin_36815313/article/details/107728274pytorch-beginner/08-AutoEncoder at master ・ L1aoXingyu/pytorch-beginner ・ GitHubpytorch tutorial for beginners. Contribute to L1aoXingyu/pytorch-beginner development by creating an account on GitHub.
 https://github.com/L1aoXingyu/pytorch-beginner/tree/master/08-AutoEncoder
https://github.com/L1aoXingyu/pytorch-beginner/tree/master/08-AutoEncoder