一、CQL高级
1、CQL函数
- 字符串函数
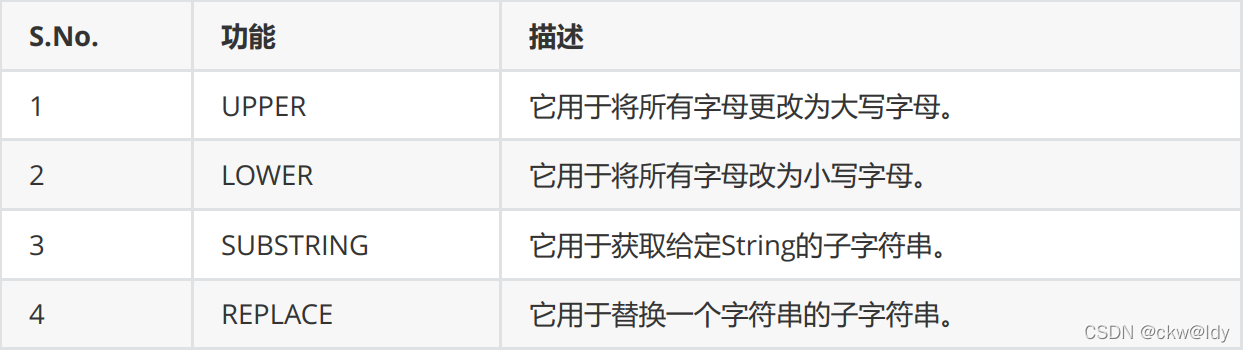
MATCH (p:Person)
RETURN ID(p),LOWER(p.character)
match(p:Person)
return p.character,lower(p.character),p.name,substring(p.name,2),replace(p.name,"子","zi")
- 聚合函数

MATCH (p:Person)
RETURN MAX(p.money),SUM(p.money)
- 关系函数
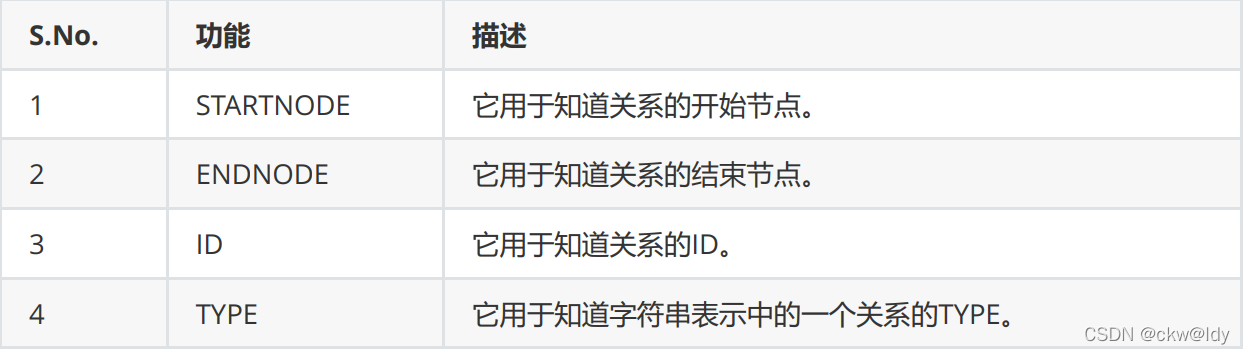
match p = (:Person {name:"林婉儿"})-[r:Couple]-(:Person)
RETURN STARTNODE(r)
- shortestPath 函数返回最短的path
MATCH p=shortestPath( (node1)-[*]-(node2) )
RETURN length(p), nodes(p)
MATCH p=shortestPath((person:Person {name:"王启年"})-[*]-(person2:Person{name:"九品射手燕小乙"}) ) RETURN length(p), nodes(p)
2、CQL多深度关系节点
- CQL多深度关系节点
查询三层级关系节点如下:with可以将前面查询结果作为后面查询条件
match (na:Person)-[re]->(nb:Person) where na.name="范闲" WITH na,re,nb match (nb:Person)-
[re2]->(nc:Person) return na,re,nb,re2,nc
match (na:Person)-[re]->(nb:Person) where na.name="林婉儿" WITH na,re,nb match (nb:Person)-
[re2]->(nc:Person) return na,re,nb,re2,nc
match (na:Person)-[re]-(nb:Person) where na.name="林婉儿" WITH na,re,nb match (nb:Person)-
[re2]->(nc:Person) return na,re,nb,re2,nc
match (na:Person)-[re]-(nb:Person) where na.name="林婉儿" WITH na,re,nb match (nb:Person)-
[re2:Friends]->(nc:Person) return na,re,nb,re2,nc
- 直接拼接关系节点查询
match (na:Person{name:"范闲"})-[re]->(nb:Person)-[re2]->(nc:Person) return na,re,nb,re2,nc
为了方便,可以将查询结果赋给变量,然后返回
match data=(na:Person{name:"范闲"})-[re]->(nb:Person)-[re2]->(nc:Person) return data
- 使用深度运算符
当实现多深度关系节点查询时,显然使用以上方式比较繁琐。
可变数量的关系->节点可以使用-[:TYPE*minHops…maxHops]-。
查询:
match data=(na:Person{name:"范闲"})-[*1..2]-(nb:Person) return data
3、事务
为了保持数据的完整性和保证良好的事务行为,Neo4j也支持ACID特性。
注意:
(1)所有对Neo4j数据库的数据修改操作都必须封装在事务里。
(2)默认的isolation level是READ_COMMITTED。
(3)死锁保护已经内置到核心事务管理 。 (Neo4j会在死锁发生之前检测死锁并抛出异常。在异常抛出之前,事务会被标志为回滚。当事务结束时,事务会释放它所持有的锁,则该事务的锁所引起的死锁也就是解除,其他事务就可以继续执行。当用户需要时,抛出异常的事务可以尝试重新执行)
(4)除特别说明,Neo4j的API的操作都是线程安全的,Neo4j数据库的操作也就没有必要使用外部的同步方法。
4、索引
-
概念
Neo4j CQL支持节点或关系属性上的索引,以提高应用程序的性能。
可以为具有相同标签名称的属性上创建索引。
可以在MATCH或WHERE等运算符上使用这些索引列来改进CQL 的执行。 -
创建单一索引
CREATE INDEX ON :Label(property)
例如:
CREATE INDEX ON :Person(name)
- 创建复合索引
CREATE INDEX ON :Person(age, gender)
- 全文模式索引
之前的常规模式索引只能对字符串进行精确匹配或者前后缀索引(startswith,endswith,contains),全文索引将标记化索引字符串值,因此它可以匹配字符串中任何位置的术语。索引字符串如何被标记化并分
解为术语,取决于配置全文模式索引的分析器。索引是通过属性来创建,便于快速查找节点或者关系。
创建和配置全文模式索引
使用db.index.fulltext.createNodeIndex和db.index.fulltext.createRelationshipIndex创建全文模式索
引。在创建索引时,每个索引必须为每个索引指定一个唯一的名称,用于在查询或删除索引时引用相关的特定索引。然后,全文模式索引分别应用于标签列表或关系类型列表,分别用于节点和关系索引,然后应用于属性名称列表
call db.index.fulltext.createNodeIndex("索引名",[Label,Label],[属性,属性])
call db.index.fulltext.createNodeIndex("nameAndDescription",["Person"],["name",
"description"])
call db.index.fulltext.queryNodes("nameAndDescription", "范闲") YIELD node, score
RETURN node.name, node.description, score
- 查看和删除索引
call db.indexes 或者 :schema
DROP INDEX ON :Person(name)
DROP INDEX ON :Person(age, gender)
call db.index.fulltext.drop("nameAndDescription")
5、约束
- 唯一性约束
作用
- 避免重复记录。
- 强制执行数据完整性规则
创建唯一性约束
CREATE CONSTRAINT ON (变量:<label_name>) ASSERT 变量.<property_name> IS UNIQUE
具体实例:
CREATE CONSTRAINT ON (person:Person) ASSERT person.name IS UNIQUE
删除唯一性约束
DROP CONSTRAINT ON (cc:Person) ASSERT cc.name IS UNIQUE
- 属性存在约束 (企业版中可用)
CREATE CONSTRAINT ON (p:Person) ASSERT exists(p.name)
- 查看约束
call db.constraints
:schema
二、Neo4j之Admin管理员操作
1、Neo4j - 数据库备份和恢复
在对Neo4j数据进行备份、还原、迁移的操作时,首先要关闭neo4j
./bin/neo4j stop
数据备份到文件
./bin/neo4j-admin dump --database=graph.db --to=/root/qyn.dump
还原、迁移之前 ,关闭neo4j服务。操作同上
./bin/neo4j-admin load --from=/root/qyn.dump --database=graph.db --force
重启服务
./bin/neo4j start
注意,运行数据备份可能会警告
WARNING: Max 1024 open files allowed, minimum of 40000 recommended. See the Neo4j manua
- 编辑这个文件
vi /etc/security/limits.conf
在文件最后加入下面这段 修改最大打开文件限制
* soft nofile 65535
* hard nofile 65535
- 重启服务器
再次执行上面的步骤 警告就没有了
2、调优
- 增加服务器内存 和 调整neo4j配置文件
# java heap 初始值
dbms.memory.heap.initial_size=1g
# java heap 最大值,一般不要超过可用物理内存的80%
dbms.memory.heap.max_size=16g
# pagecache大小,官方建议设为:(总内存-dbms.memory.heap.max_size)/2,
dbms.memory.pagecache.size=2g
- neo4j刚启动数据是冷的需要预热
MATCH (n)
OPTIONAL MATCH (n)-[r]->()
RETURN count(n.name) + count(r);
- 查看执行计划进行索引优化
Cypher查询计划程序将每个查询转换为执行计划。 执行计划告诉Neo4j在执行查询时要执行哪些操作。
对执行计划的生成,Neo4j使用的都是基于成本的优化器(Cost Based Optimizer,CBO),用于制订精确的执行过程。可以采用如下两种不同的方式了解其内部的工作机制:
EXPLAIN:是解释机制,加入该关键字的Cypher语句可以预览执行的过程但并不实际执行,所以也不会产生任何结果。
PROFILE:则是画像机制,查询中使用该关键字,不仅能够看到执行计划的详细内容,也可以看到查询的执行结果。
关注指标:
estimated rows: 需要被扫描行数的预估值
dbhits: 实际运行结果的命中绩效
两个值都是越小越好
使用索引和不使用索引对比
MATCH (p { name : ‘范闲’ }) RETURN p
在之前加上profile来进行查询,可以查看查询计划