ЛьЯ§Оиеѓ
ЛьЯ§Оиеѓ
| ЪЕМЪ | дЄВт 1 | дЄВт 0 |
|---|---|---|
| ецЪЕжЕ 1 | TP | FN |
| ецЪЕжЕ 0 | FP | TN |
TP = True Postive = ецбєад; FP = False Positive = Мйбєад
FN = False Negative = Мйвѕад; TN = True Negative = ецвѕад
в§ГіTrue Positive Rate(ецбєТЪ)ЁЂFalse Positive(ЮБбєТЪ)СНИіИХФю:
TPR = TP / (TP + FN)
FPR = FP / (FP + TN)
TPRЕФвтвхЪЧЫљгаецЪЕРрБ№ЮЊ1ЕФбљБОжа,дЄВтРрБ№ЮЊ1ЕФБШР§ЁЃ
FPRЕФвтвхЪЧЫљгаецЪЧРрБ№ЮЊ0ЕФбљБОжа,дЄВтРрБ№ЮЊ1ЕФБШР§ЁЃ
AUC
AUCЪЧвЛИіФЃаЭЦРМлжИБъ,жЛФмгУгкЖўЗжРрФЃаЭЕФЦРМл
AUCЕФБОжЪКЌвхЗДгГЕФЪЧЖдгкШЮвтвЛЖде§ИКР§бљБО,ФЃаЭНЋе§бљБОдЄВтЮЊе§Р§ЕФПЩФмад Дѓгк НЋИКР§дЄВтЮЊе§Р§ЕФПЩФмадЕФ ИХТЪ
?МЦЫуЗНЗЈ: гаTPRКЭFPRЙЙГЩЕФROCЧњЯпЯТЕФУцЛ§ДѓаЁОЭЪЧauc
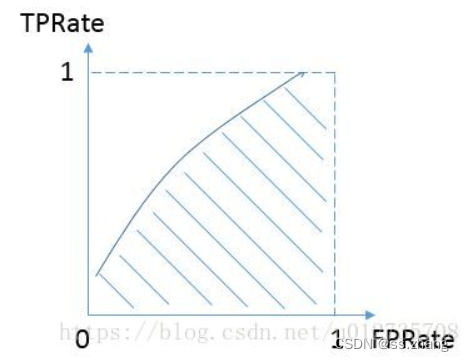
ШчЙћЯЃЭћaucИќДѓ,ФЧУДдкИјЖЈTPRЕФЧщПіЯТ,ЮвУЧЪЧЯЃЭћFPRдНаЁдНКУЕФ,ЭЌбљИјЖЈFPR,ЯЃЭћTPRдНДѓдНКУ,
етбљВХФмИјЧњЯпРЯђЖдНЧЯпЩЯЗНЁЃЫљвдЮвУЧПЩвдШЯЮЊ:гХЛЏaucОЭЪЧЯЃЭћЭЌЪБгХЛЏTPRКЭ(1-FPR)ЁЃ
F1-Score
ОЋЖШ(precision) = TP / (TP + FP)
ейЛи(recall) = TP / (TP + FN)
F1ОЭЪЧЯЃЭћЭЌЪБгХЛЏrecallКЭprecision
F1score = 2?recall?precision / (recall + precision)
ЧјБ№
F1КЭAUC
етРяСНИіжИБъдкrecallжЎЭт,ЦфЪЕЪЧДцдкФкдкУЌЖмЕФЁЃШчЙћЫЕейЛиТЪКтСПЮвУЧбЕСЗЕФФЃаЭ(жЦдьЕФвЛИіМьбщ)ЖдМШгажЊЪЖЕФМЧвфФмСІ(ейЛиТЪ),
ФЧУДСНИіжИБъЖМЪЧЯЃЭћбЕСЗвЛИіФмЙЛКмКУФтКЯбљБОЪ§ОнЕФФЃаЭ,етвЛЕуЩЯСНепФПБъЯрЭЌЁЃЕЋЪЧaucдкДЫжЎЭт,ЯЃЭћбЕСЗвЛИіОЁСПВЛЮѓБЈЕФФЃаЭ,
вВОЭЪЧжЊЪЖЭтЭЦЕФЪБКђЧуЯђБЃЪиЙРМЦ,Жјf1ЯЃЭћбЕСЗвЛИіВЛЗХЙ§ШЮКЮПЩФмЕФФЃаЭ,МДжЊЪЖЭтЭЦЕФЪБКђЧуЯђМЄНј,етОЭЪЧетСНИіжИБъЕФКЫаФЧјБ№ЁЃ
aucВЛШнвзЪмбљБОВЛЦНКтЕФгАЯь,ЫљвдЖдгкimbalanceЕФЧщПігХЯШЪЙгУauc